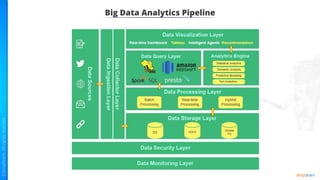
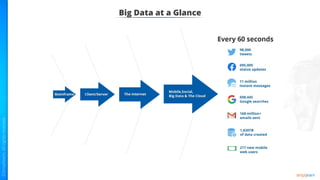
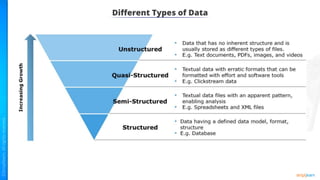
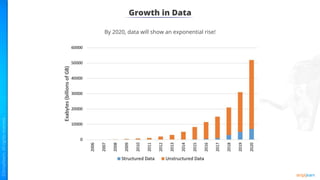
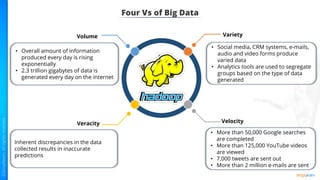
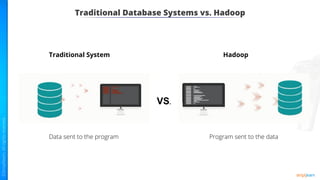
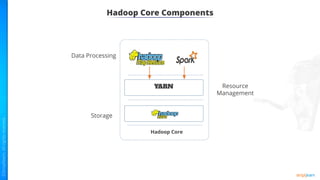
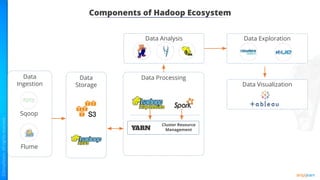
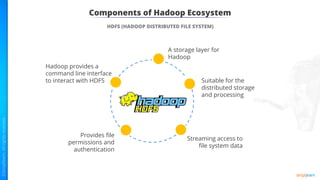
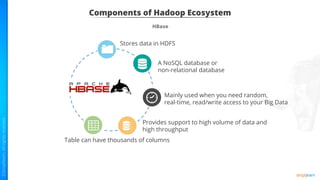
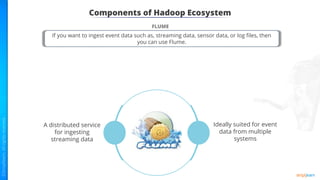
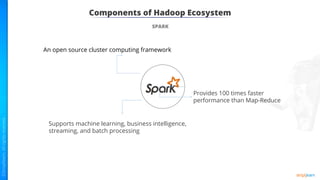
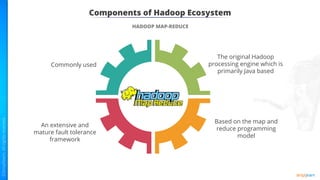
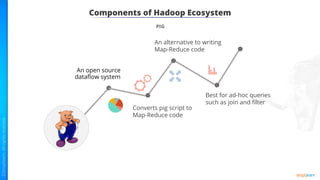
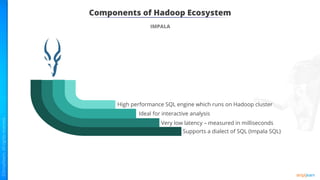
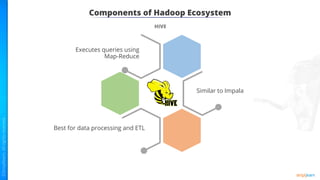
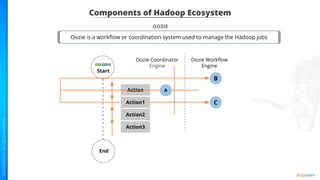
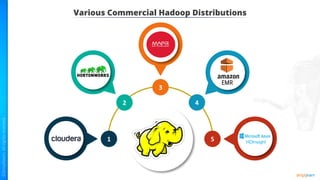
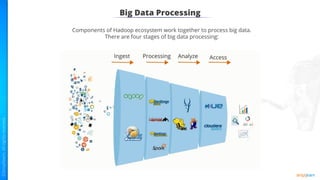
The document provides an introduction to big data and Hadoop. It describes the concepts of big data, including the four V's of big data: volume, variety, velocity and veracity. It then explains Hadoop and how it addresses big data challenges through its core components. Finally, it describes the various components that make up the Hadoop ecosystem, such as HDFS, HBase, Sqoop, Flume, Spark, MapReduce, Pig and Hive. The key takeaways are that the reader will now be able to describe big data concepts, explain how Hadoop addresses big data challenges, and describe the components of the Hadoop ecosystem.





























































































![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)




