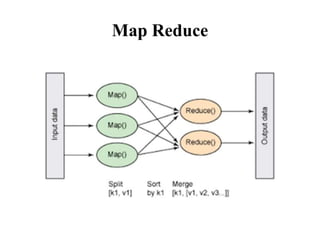
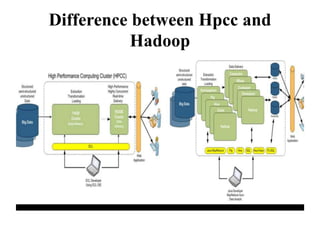
This document provides an overview of big data, including its components of variety, volume, and velocity. It discusses frameworks for managing big data like Hadoop and HPCC, describing how Hadoop uses HDFS for storage and MapReduce for processing, while HPCC uses its own data refinery and delivery engine. Examples are given of big data sources and applications. Privacy and security issues are also addressed.