Download as PDF, PPTX




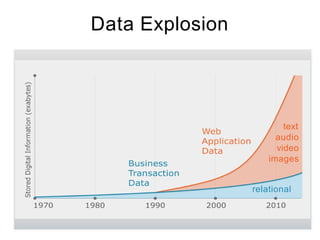


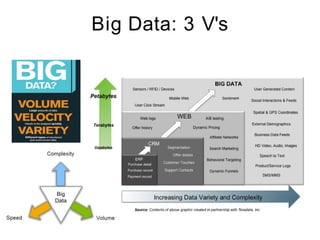
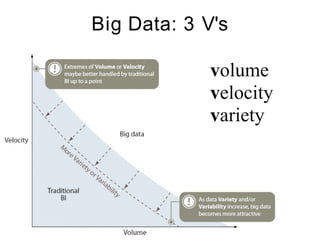
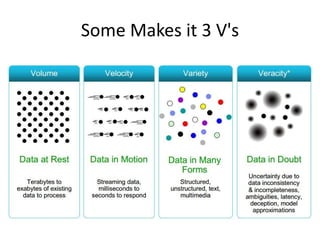
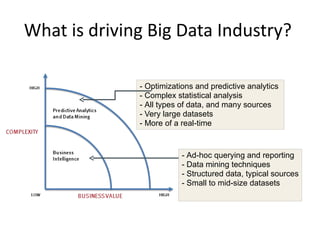
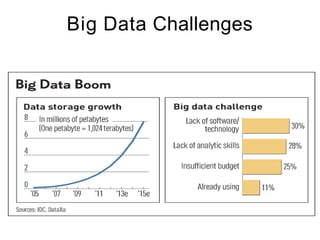




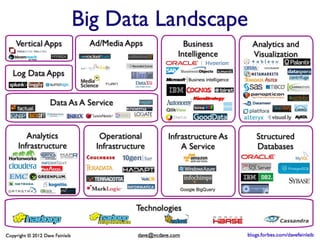


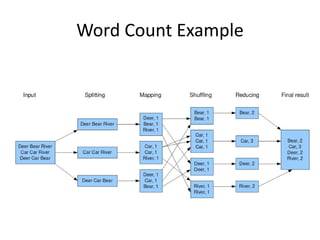
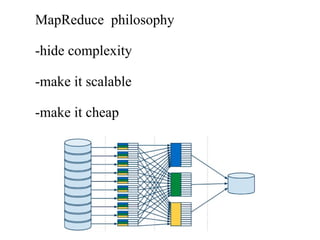


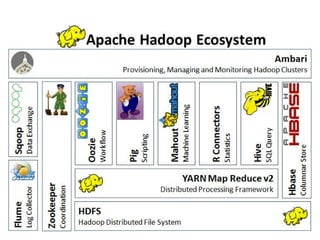







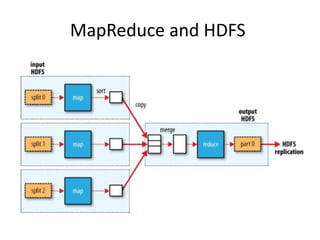
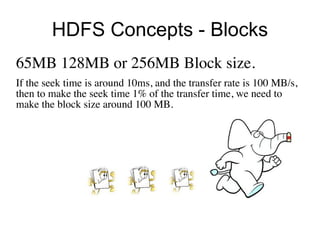
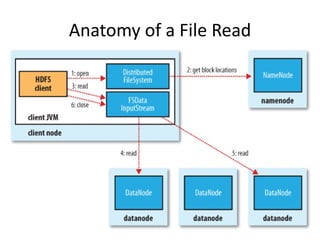
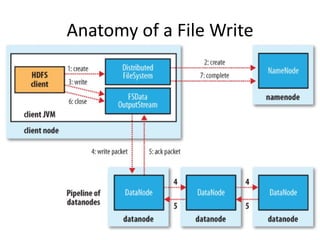
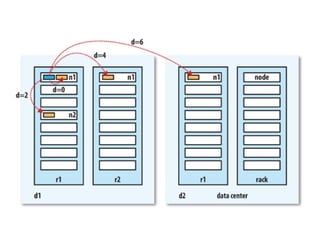
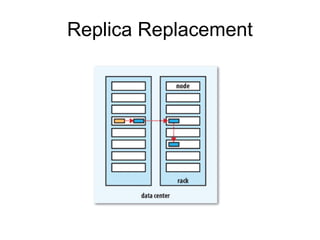




The document discusses the concept of big data, defining it by its volume, velocity, and variety, and highlights the need for new architectures to process such data. It focuses on Hadoop and MapReduce as key technologies for handling big data challenges, such as the management of large datasets and cost-effective data processing. Additionally, it addresses the use of Hadoop's ecosystem for various applications including machine learning, ad recommendations, and fraud detection.



























































































