Download to read offline

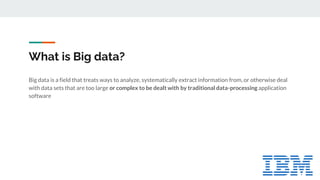






















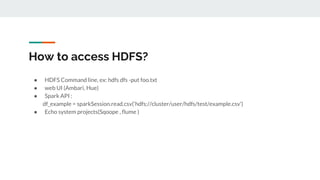





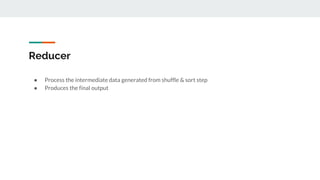
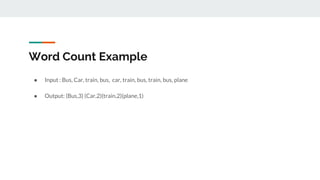












This document provides an introduction to big data and related technologies. It defines big data as datasets that are too large to be processed by traditional methods. The motivation for big data is the massive growth in data volume and variety. Technologies like Hadoop and Spark were developed to process this data across clusters of commodity servers. Hadoop uses HDFS for storage and MapReduce for processing. Spark improves on MapReduce with its use of resilient distributed datasets (RDDs) and lazy evaluation. The document outlines several big data use cases and projects involving areas like radio astronomy, particle physics, and engine sensor data. It also discusses when Hadoop and Spark are suitable technologies.











![[KCC oral] 정준영](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-181213110358-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)



