Downloaded 48 times




















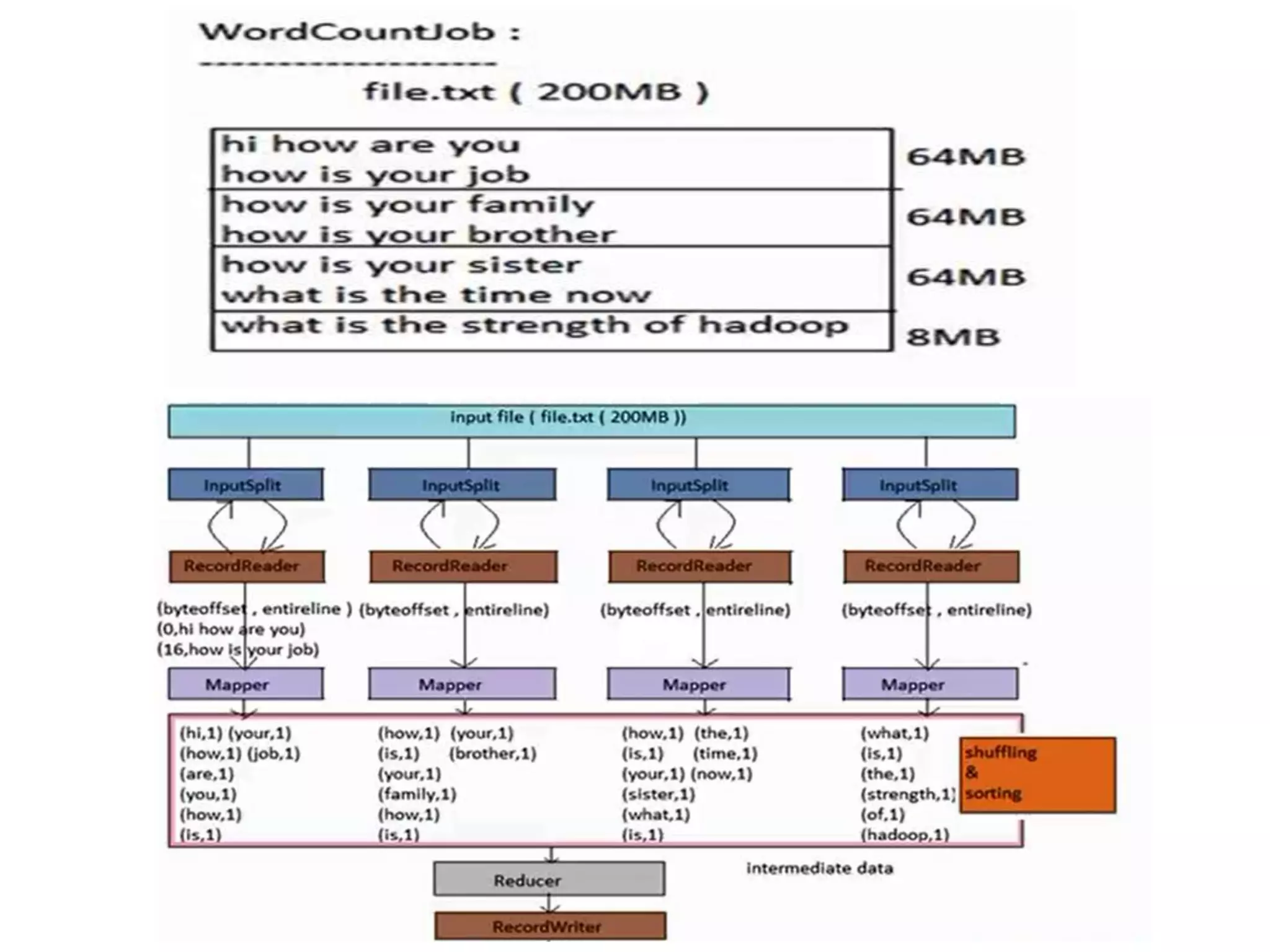
![• Shuffling:
– It is a phase on intermediate data to combine all
key values pairs into a collection associated to
same key.
• (how[11111])
• (is[11111])
• Sorting :
– It is also an another phase on intermediate data to
sort all key values pairs.](https://image.slidesharecdn.com/seminarppt-141206092356-conversion-gate02/75/Big-Data-24-2048.jpg)




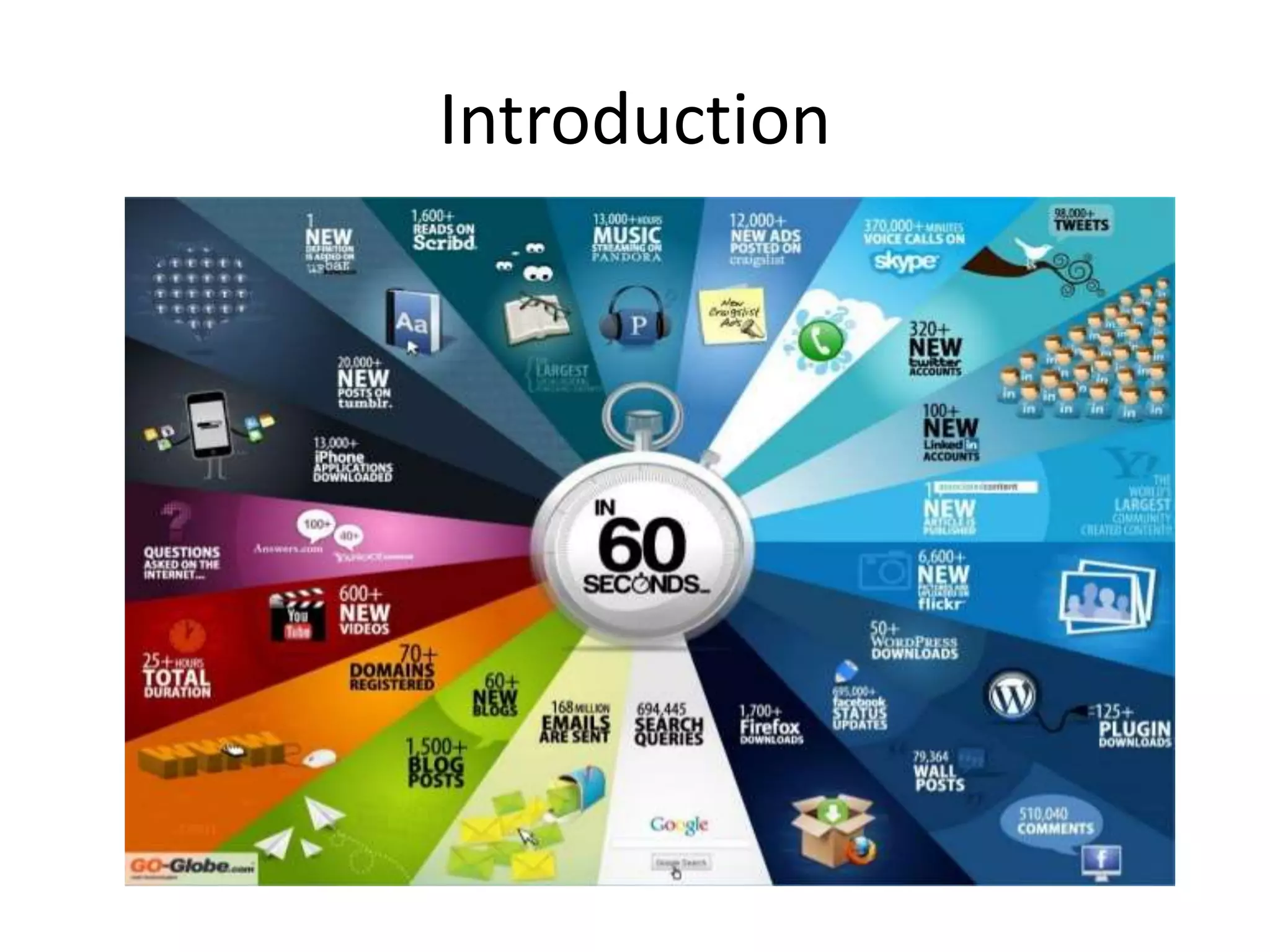
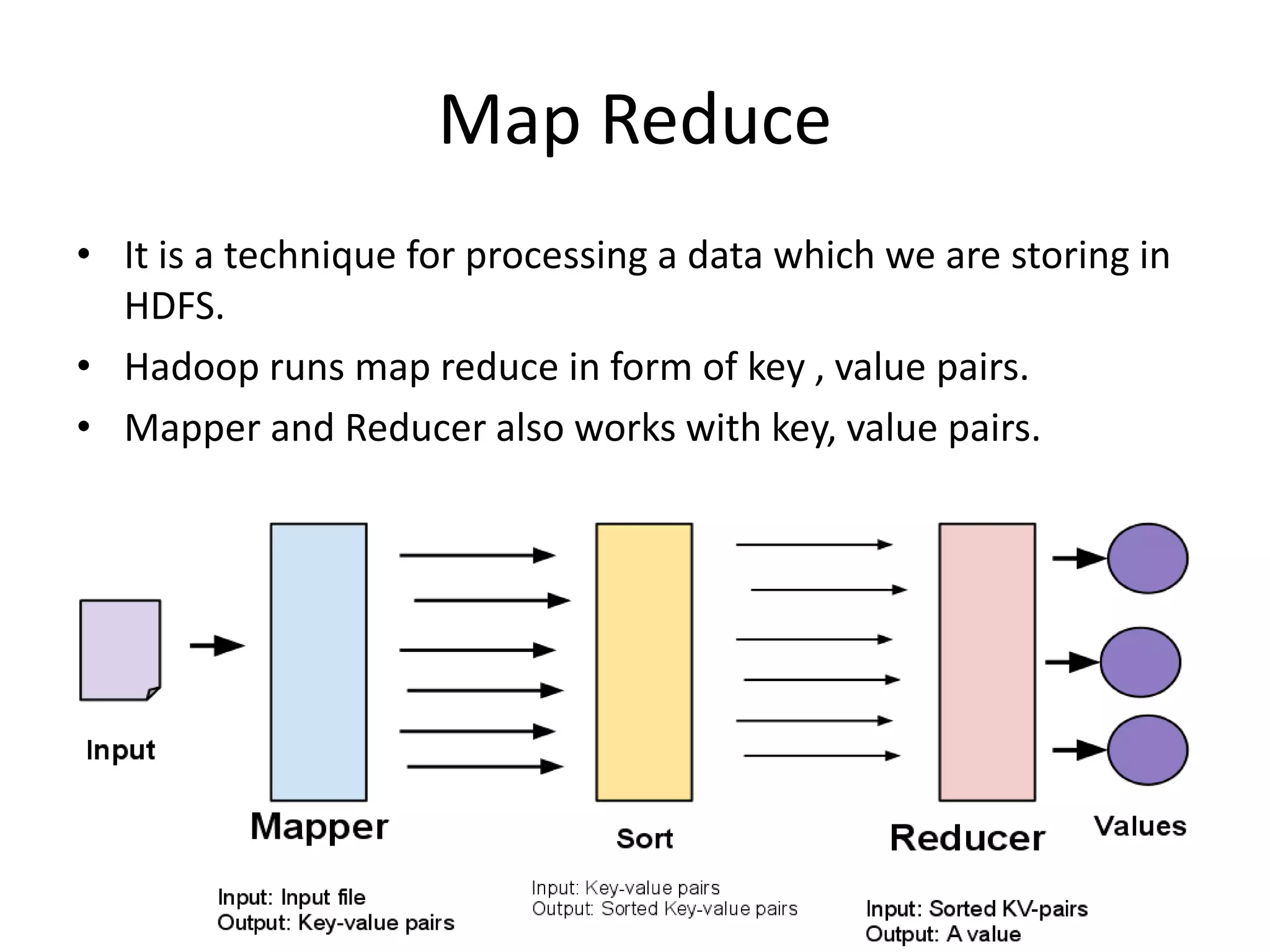
This document discusses big data, including what it is, common data sources, its volume, velocity and variety characteristics, solutions like Hadoop and its HDFS and MapReduce components, and the impact and future of big data. It explains that big data refers to large and complex datasets that are difficult to process using traditional tools. Hadoop provides a framework to store and process big data across clusters of commodity hardware.








































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

