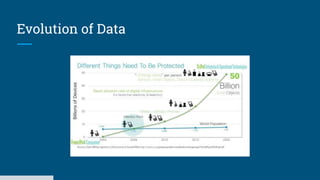
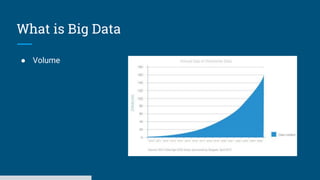
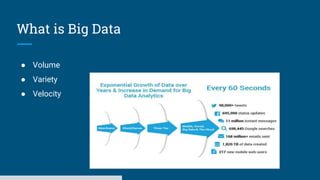
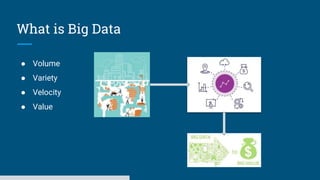
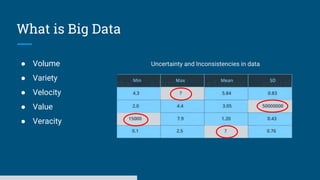
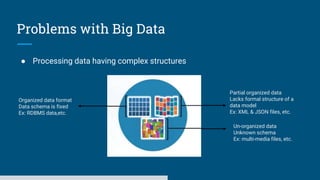
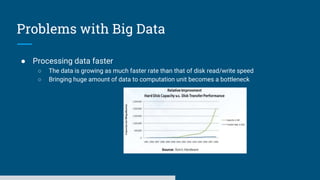
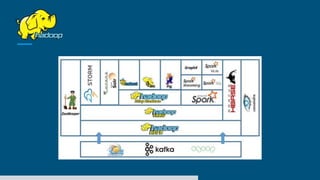
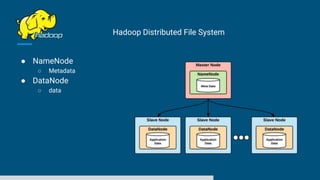
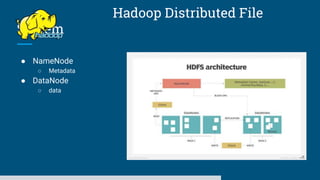
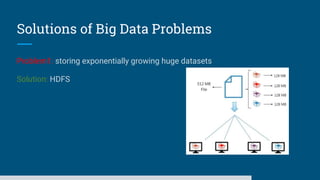
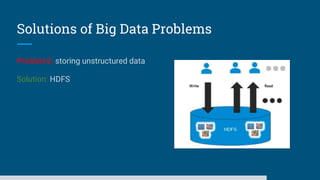
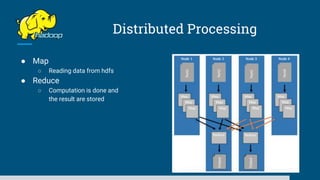
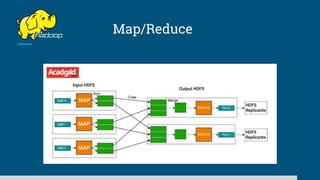
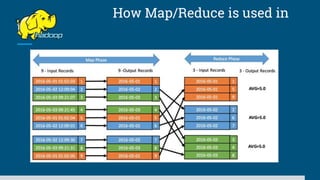
The document discusses big data processing systems. It begins with an overview of big data and its evolution due to technologies like IoT, social media, and smart cars. This has led to an exponential increase in data volume and variety, including structured, semi-structured and unstructured data. Traditional databases cannot handle this type and size of data. The document then introduces Hadoop as an open source framework to process large, diverse datasets across clusters. It uses HDFS for storage and MapReduce for parallel processing of data stored in HDFS. Hadoop provides scalable solutions to the problems of storing huge, growing datasets and processing complex, diverse data faster.

































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







