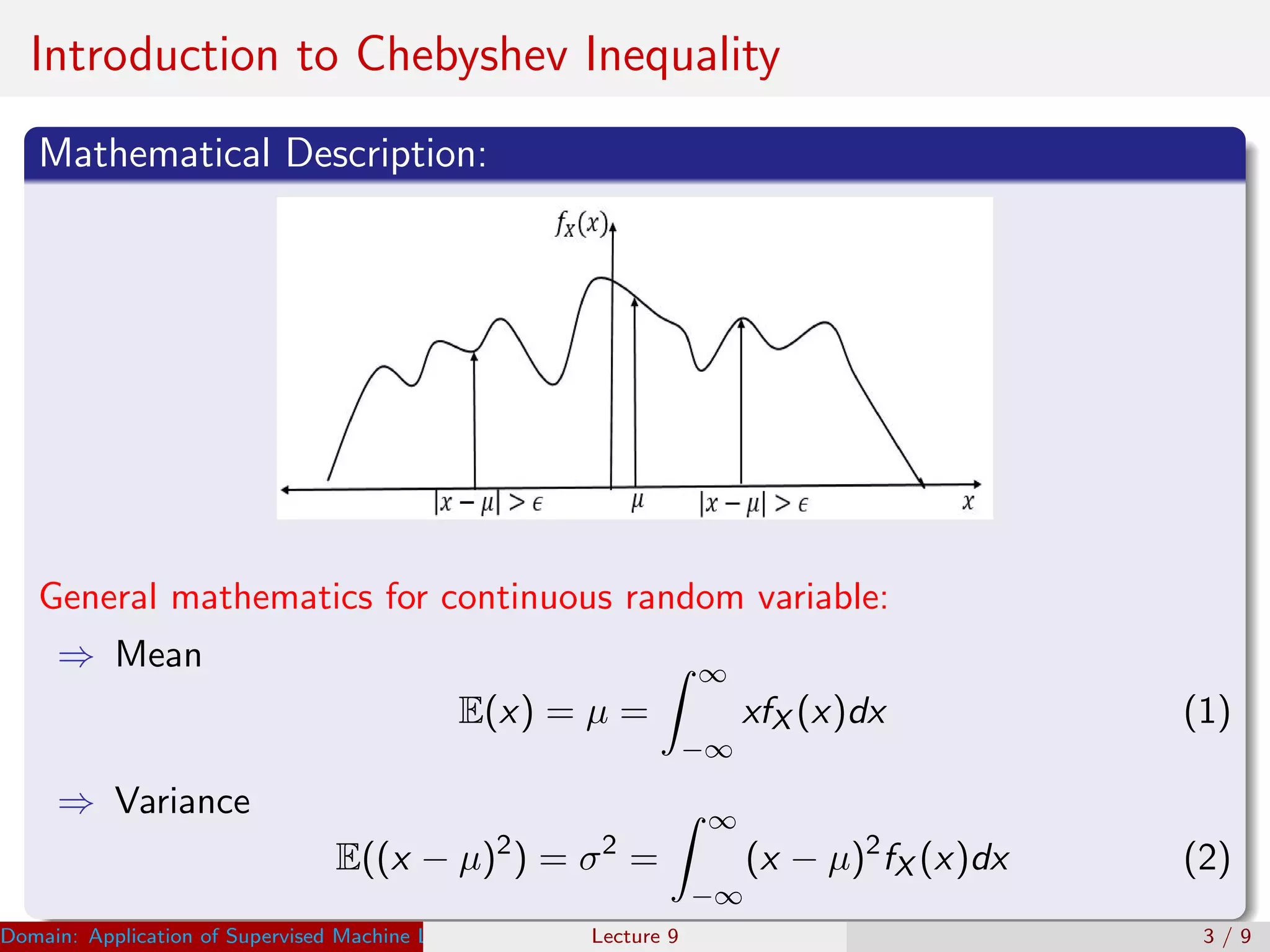
This document discusses the application of Chebyshev and Markov inequalities in supervised machine learning. It introduces the mathematical descriptions of Chebyshev and Markov inequalities and how they can be used to find the probability of new data falling within or outside a threshold value. Supervised learning is also introduced as learning from predefined training data to develop a model that can then be used to classify new data. The inequalities help in making decisions by defining favorable and non-favorable regions and allowing the probability of new data to be predicted based on the variance or mean of the training data.