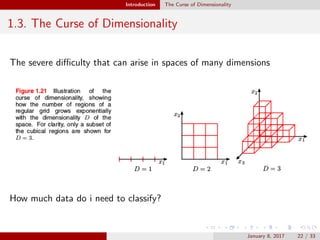
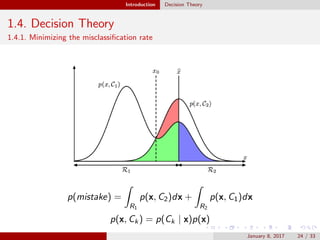
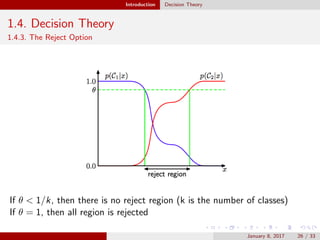
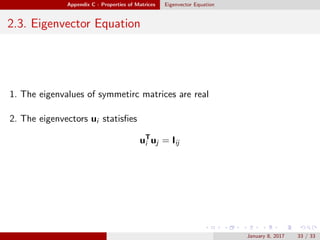
This document provides an outline and introduction to the topics of pattern recognition and machine learning. It begins with an overview of key concepts like probability theory, decision theory, and the curse of dimensionality. It then covers specific techniques like polynomial curve fitting, the Gaussian distribution, and Bayesian curve fitting. The document also includes an appendix on properties of matrices such as determinants, matrix derivatives, and the eigenvector equation.








![Introduction Probability Theory
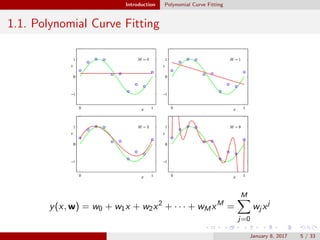
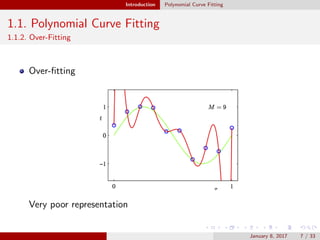
1.2. Probability Theory
Expectation
E[f ] =
x
p(x)f (x)
1
N
N
n=1
f (xn)
Variance
var[f ] = E[(f (x) − E[f (x)])2
]
January 8, 2017 10 / 33](https://image.slidesharecdn.com/prml1-170108142524/85/Pattern-Recognition-10-320.jpg)



![Introduction Probability Theory
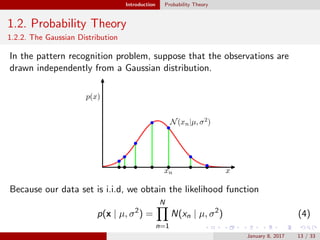
1.2. Probability Theory
1.2.2. The Gaussian Distribution
Therefore,
E[µML] = µ
E[σ2
ML] = (N−1
N )σ2
The figure shows that how variance is biased
January 8, 2017 15 / 33](https://image.slidesharecdn.com/prml1-170108142524/85/Pattern-Recognition-15-320.jpg)
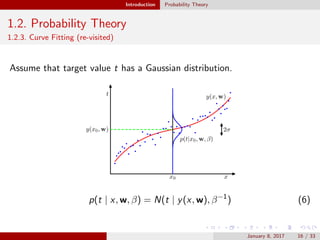






![Introduction Decision Theory
1.4. Decision Theory
1.4.2. Minimizing the expected loss
Dicision’s value is different each other
Minimize the expected loss by using the loss matrix L
E[L] =
k j Rj
Lkj p(x, Ck)dx
January 8, 2017 25 / 33](https://image.slidesharecdn.com/prml1-170108142524/85/Pattern-Recognition-25-320.jpg)
![Introduction Information Theory
1.5. Infomation Theory
Entropy of the event x (the quantity of information)
h(x) = −log2p(x)
Entropy of the random variable x
H[x] = −
x
p(x)log2p(x)
The distribution that maximizes the differential entropy is the
Gaussian
January 8, 2017 27 / 33](https://image.slidesharecdn.com/prml1-170108142524/85/Pattern-Recognition-27-320.jpg)







































![[PRML 3.1~3.2] Linear Regression / Bias-Variance Decomposition](https://cdn.slidesharecdn.com/ss_thumbnails/bayesianlinearregressionpart1-170117134816-thumbnail.jpg?width=640&height=640&fit=bounds)








































