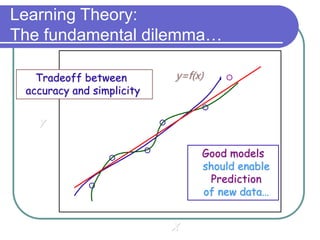
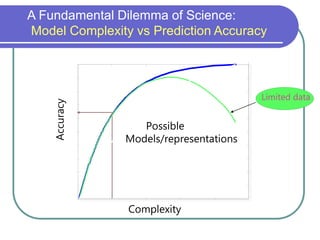
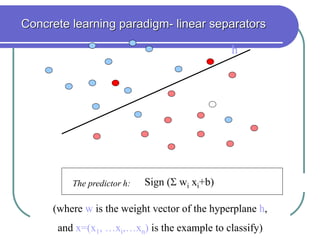
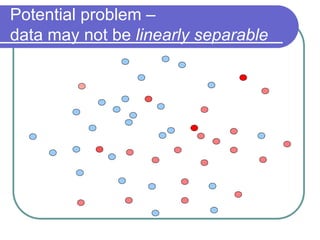
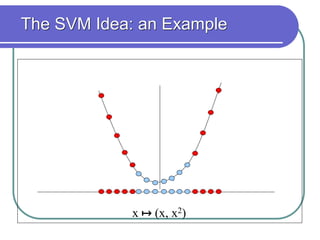
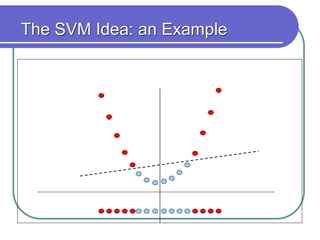
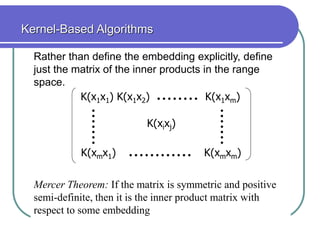
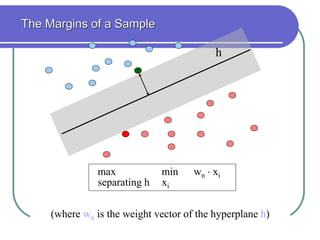
Statistical machine learning aims to develop algorithms that can detect meaningful patterns in large, complex datasets. It focuses on tasks like classification, clustering, and prediction. Support vector machines (SVMs) are a common approach that learns by finding a hyperplane that maximizes the margin between examples of separate classes. SVMs map data into a high-dimensional feature space to allow for linear separation. The kernel trick allows efficient learning without explicitly computing the mapping, by defining a kernel function measuring similarity. SVMs balance expressiveness, statistical soundness, and computational feasibility.