Download as PDF, PPTX
















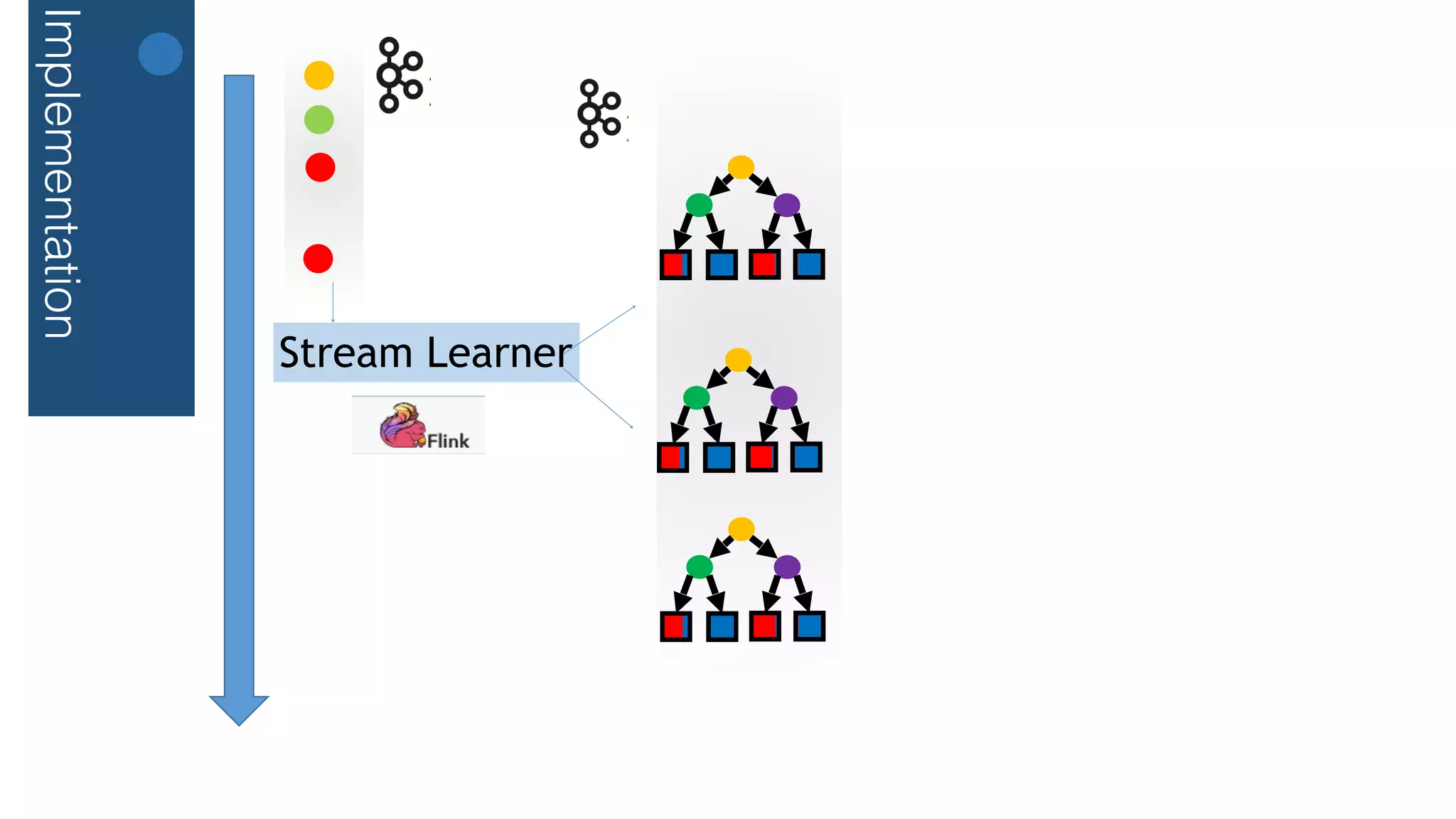

![Implementation
Code Outlines
val kafkaDataStream: DataStream[Point]=
val kafkaTreeStream: DataStream[Node] =
// annotate each message with the latest tree
val annotatedDataStream: DataStream[AnnotatedPoint] =
(kafkaDataStream connect kafkaTreeStream) flatMap (new
AnnotateMessageCoFlatMap(…))
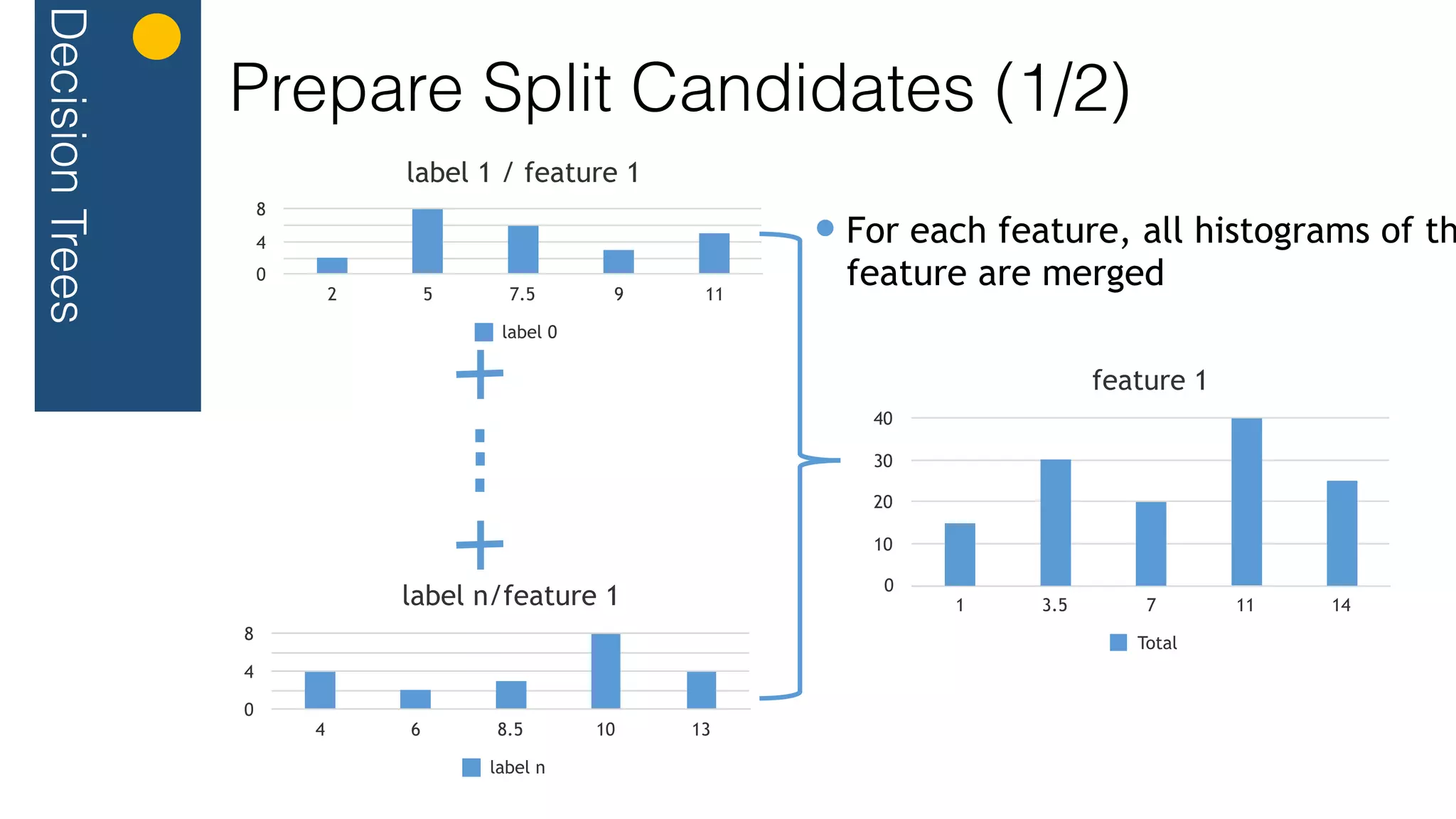
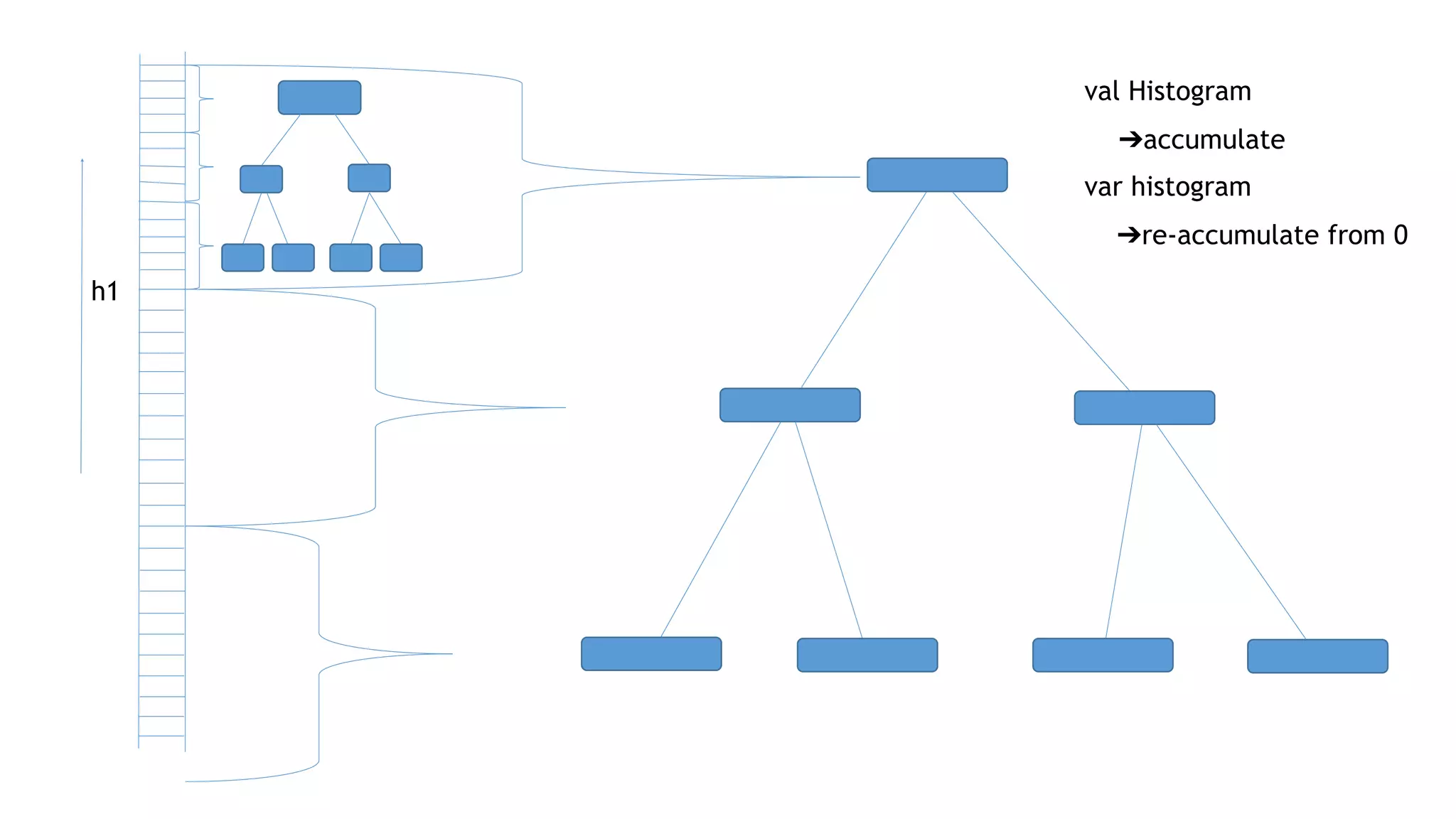
// create histogram per feature / node
val histograms = annotatedDataStream.map{ p => toSingletonHistograms(p) }
.timeWindowAll(Time.of(1, TimeUnit.MINUTES))
.reduce{ (n1, n2) => mergeHistogram(n1, n2) }
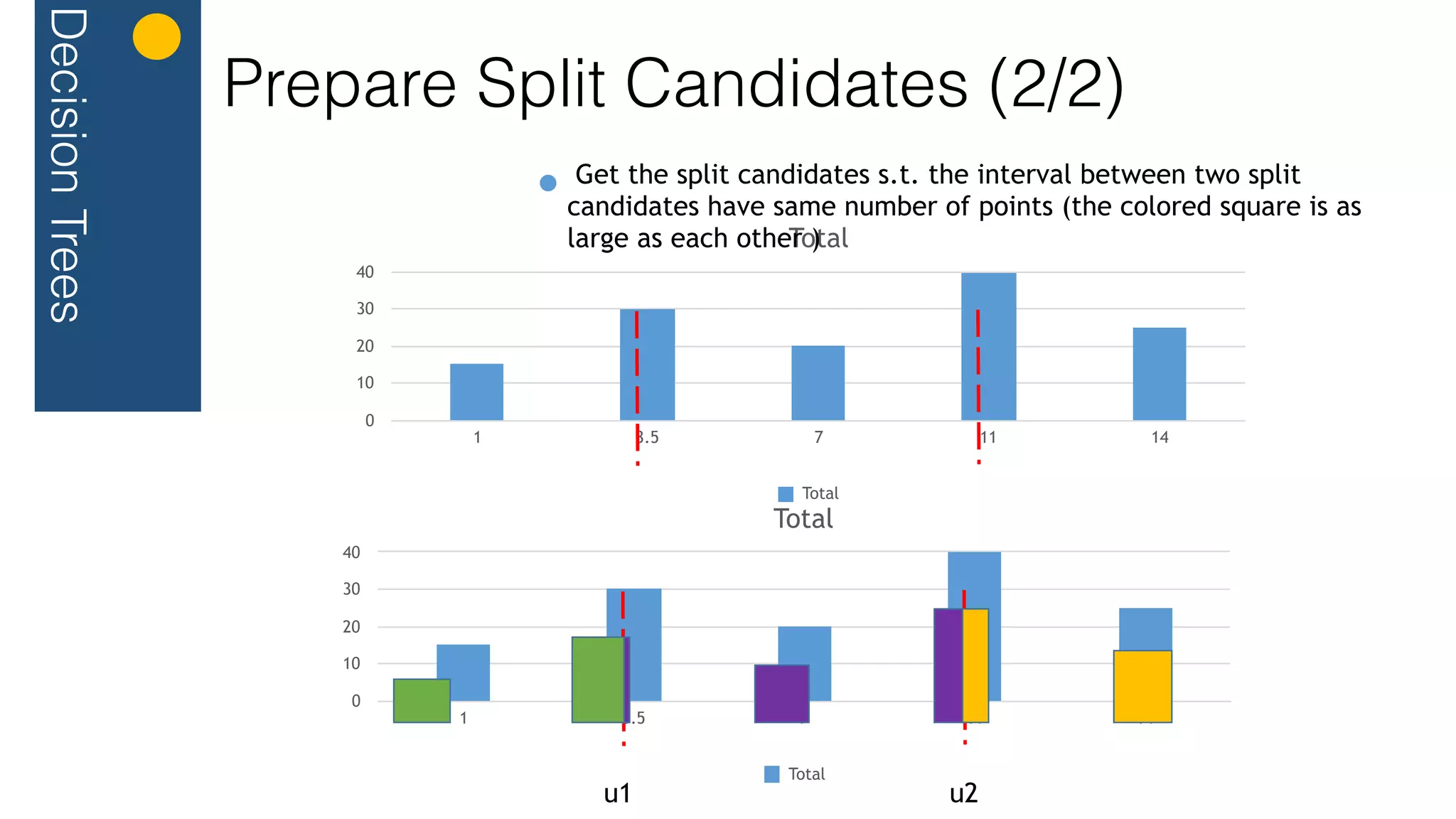
// merge histogram
val mergedHistogram = histograms.keyBy(_.id).reduce{ (n1, n2) => mergeHistogram(n1, n2)
}
val newTree = mergedHistograms
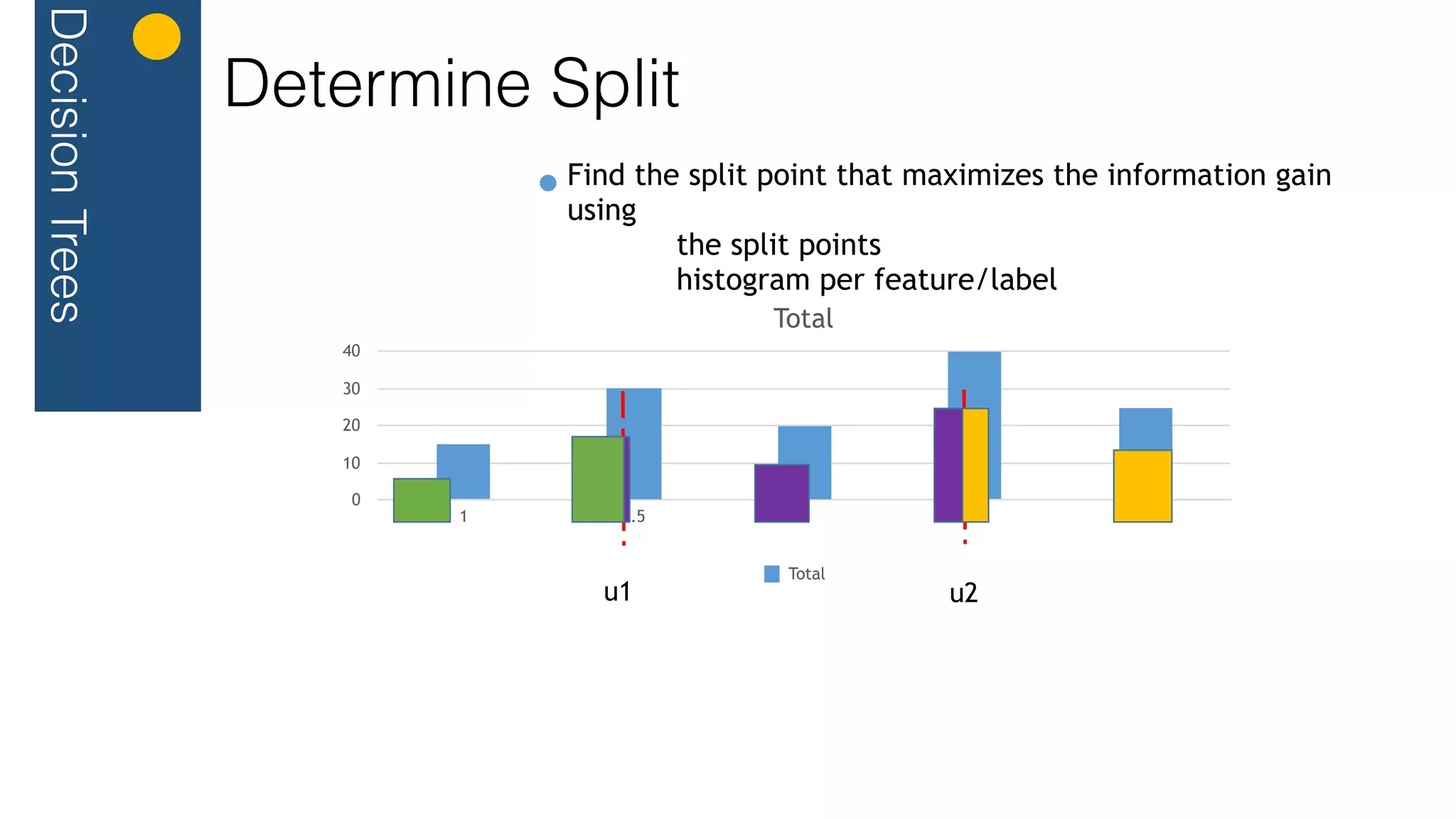
.filter(hs => haveEnoughPoints(hs) && toSplit(hs))
.map{ n => val splitPoint =
maxInformationGain( calculateSplitCandidates(n))](https://image.slidesharecdn.com/flink-streaming-decision-trees-151019132635-lva1-app6892/75/Anwar-Rizal-Streaming-Parallel-Decision-Tree-in-Flink-33-2048.jpg)





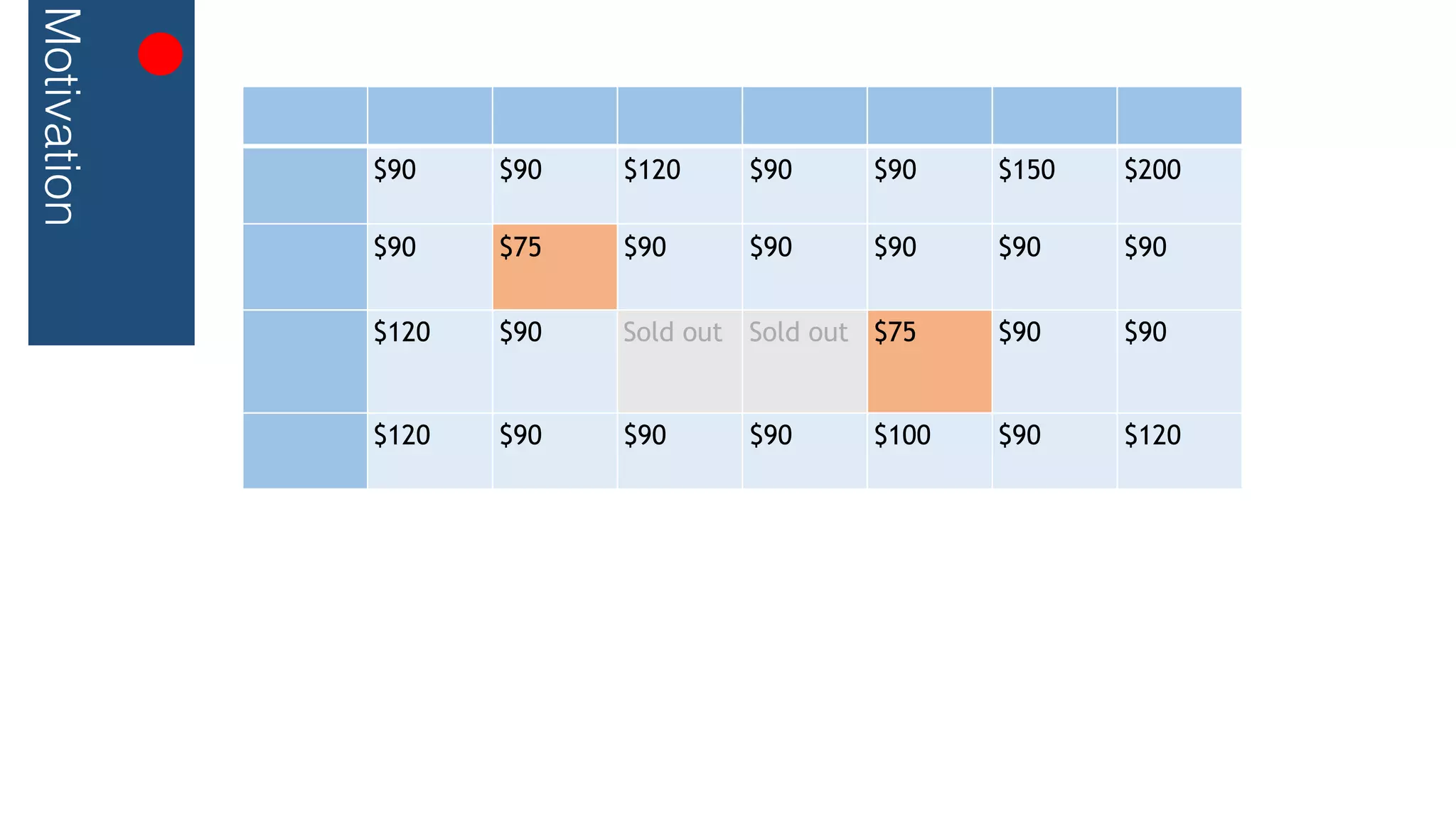
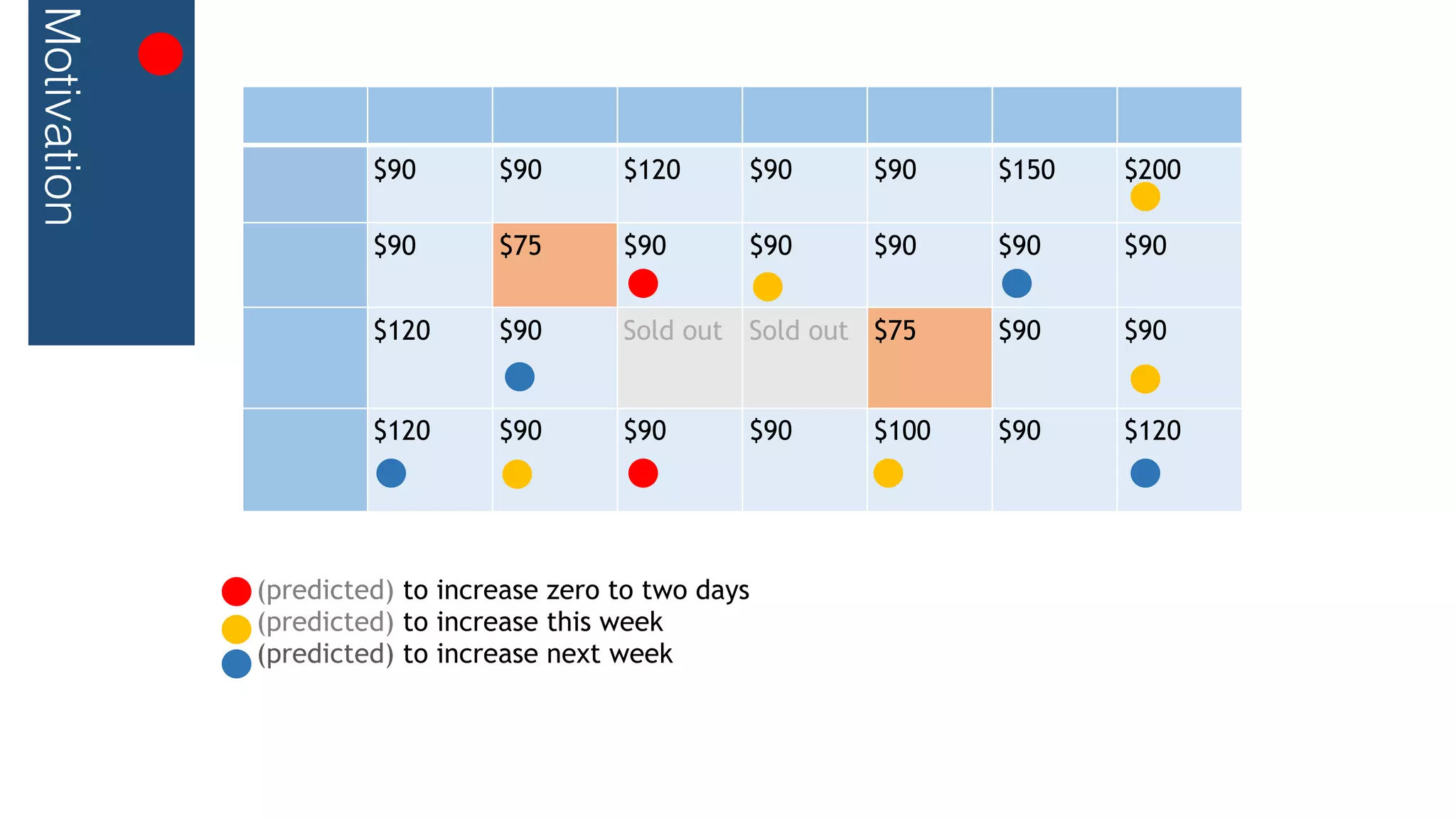
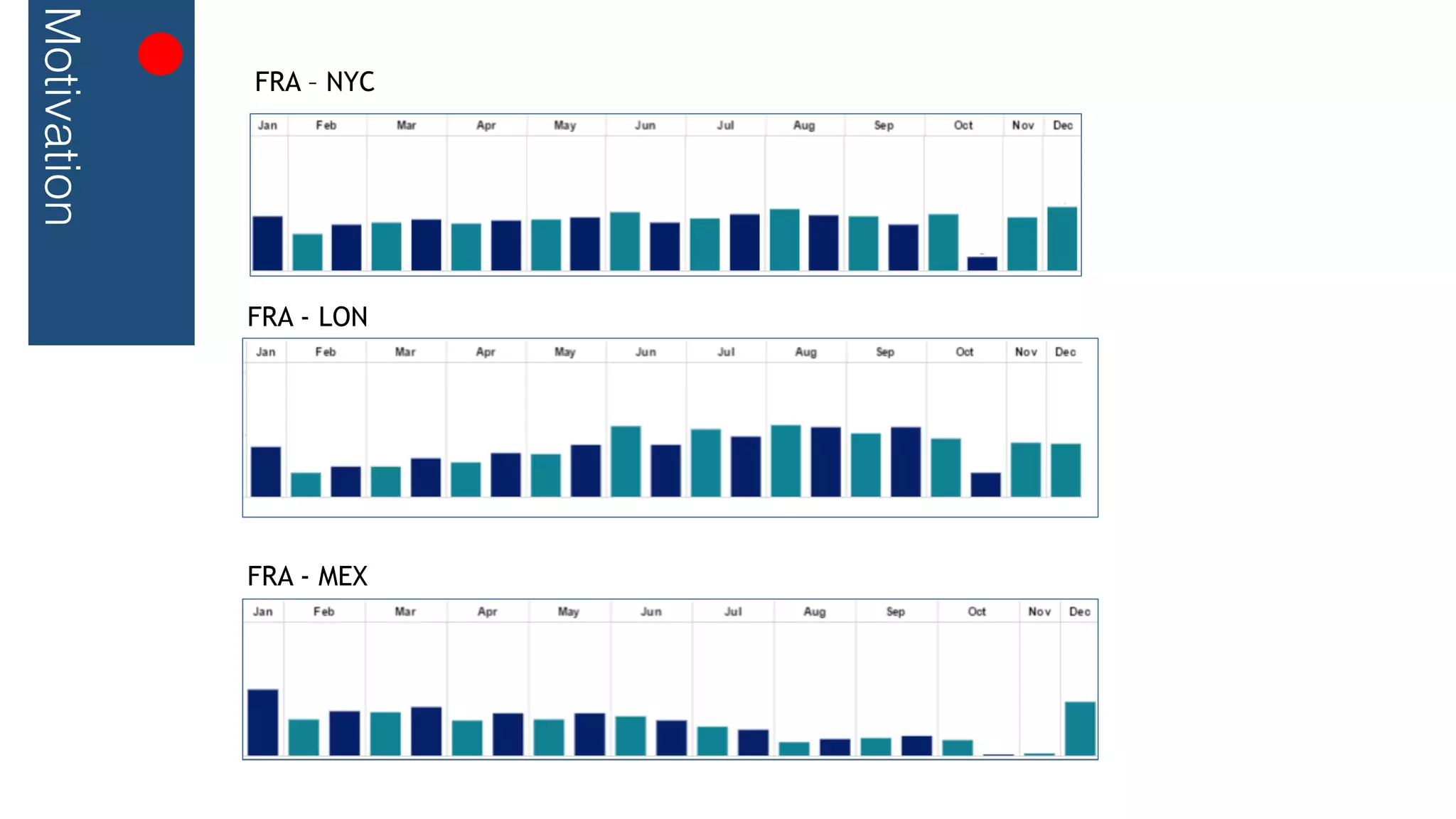
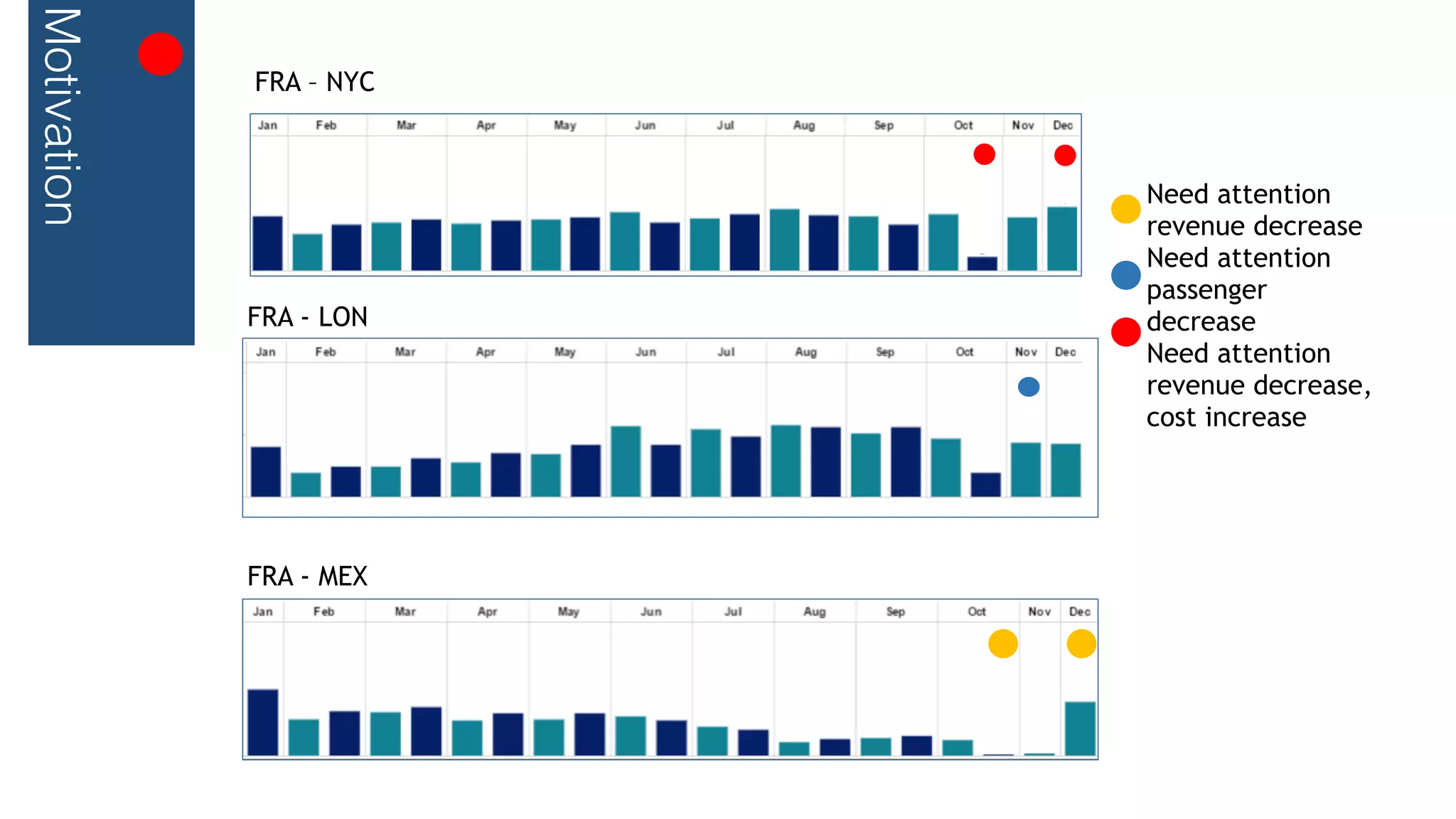
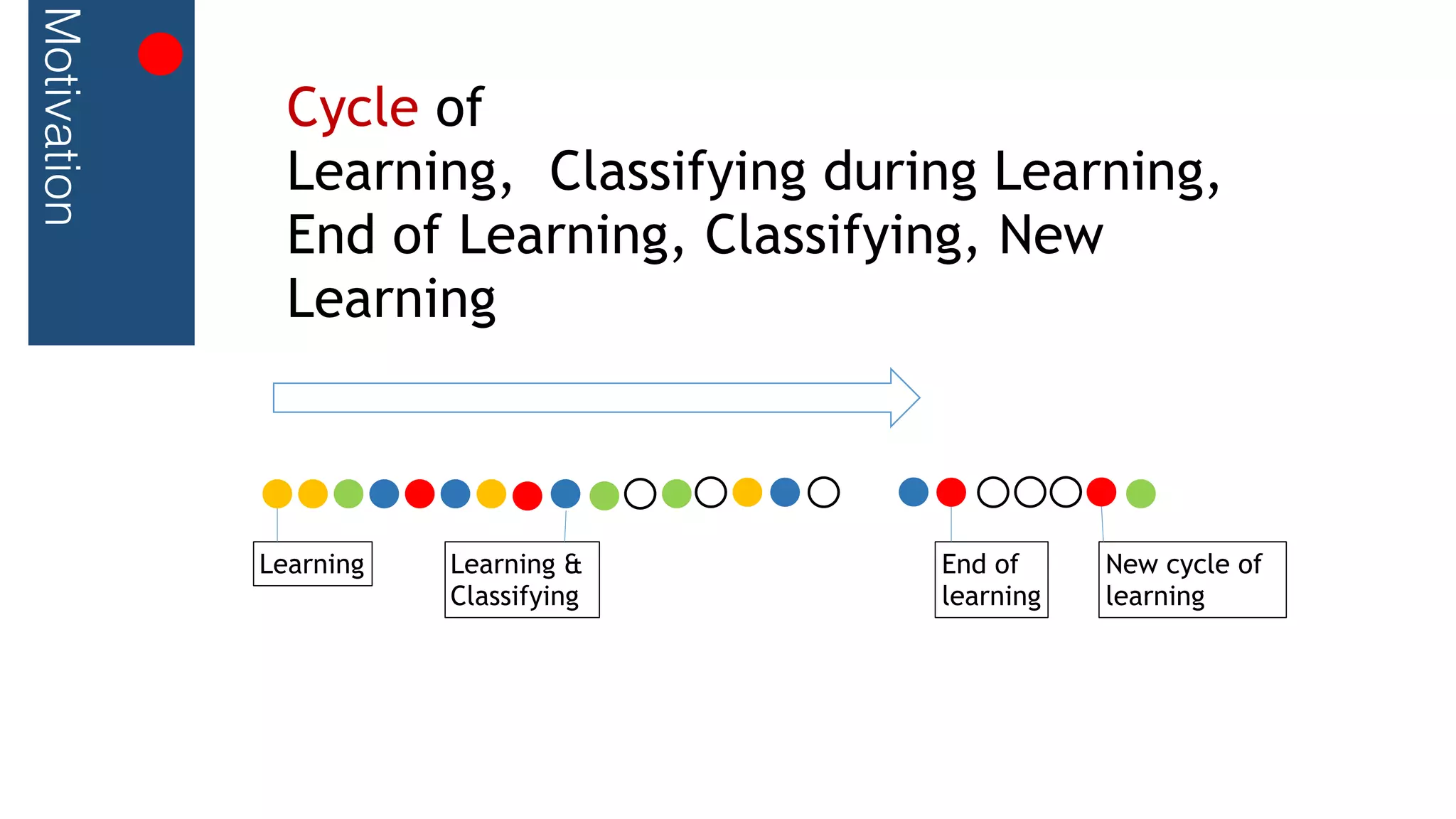
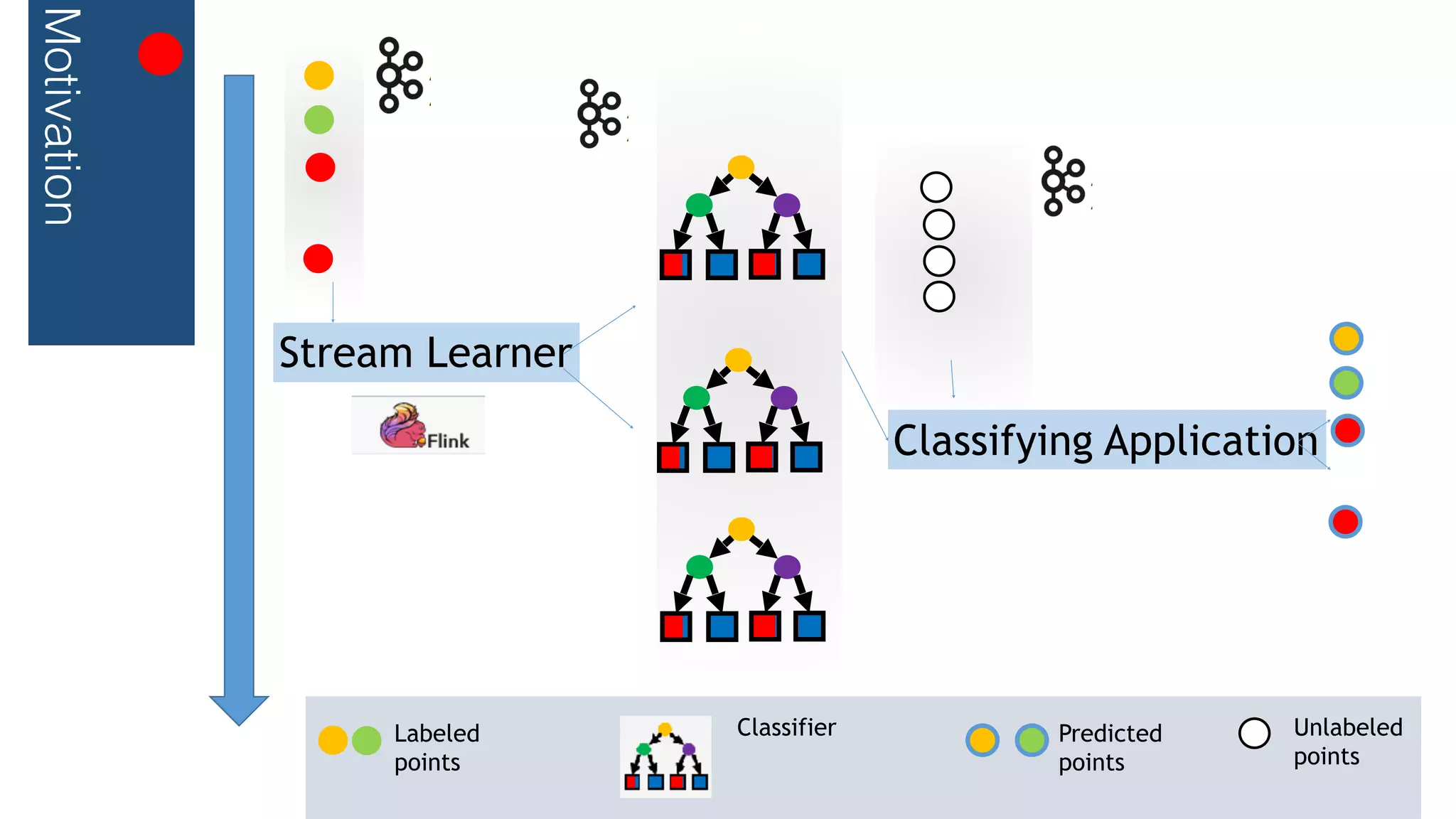
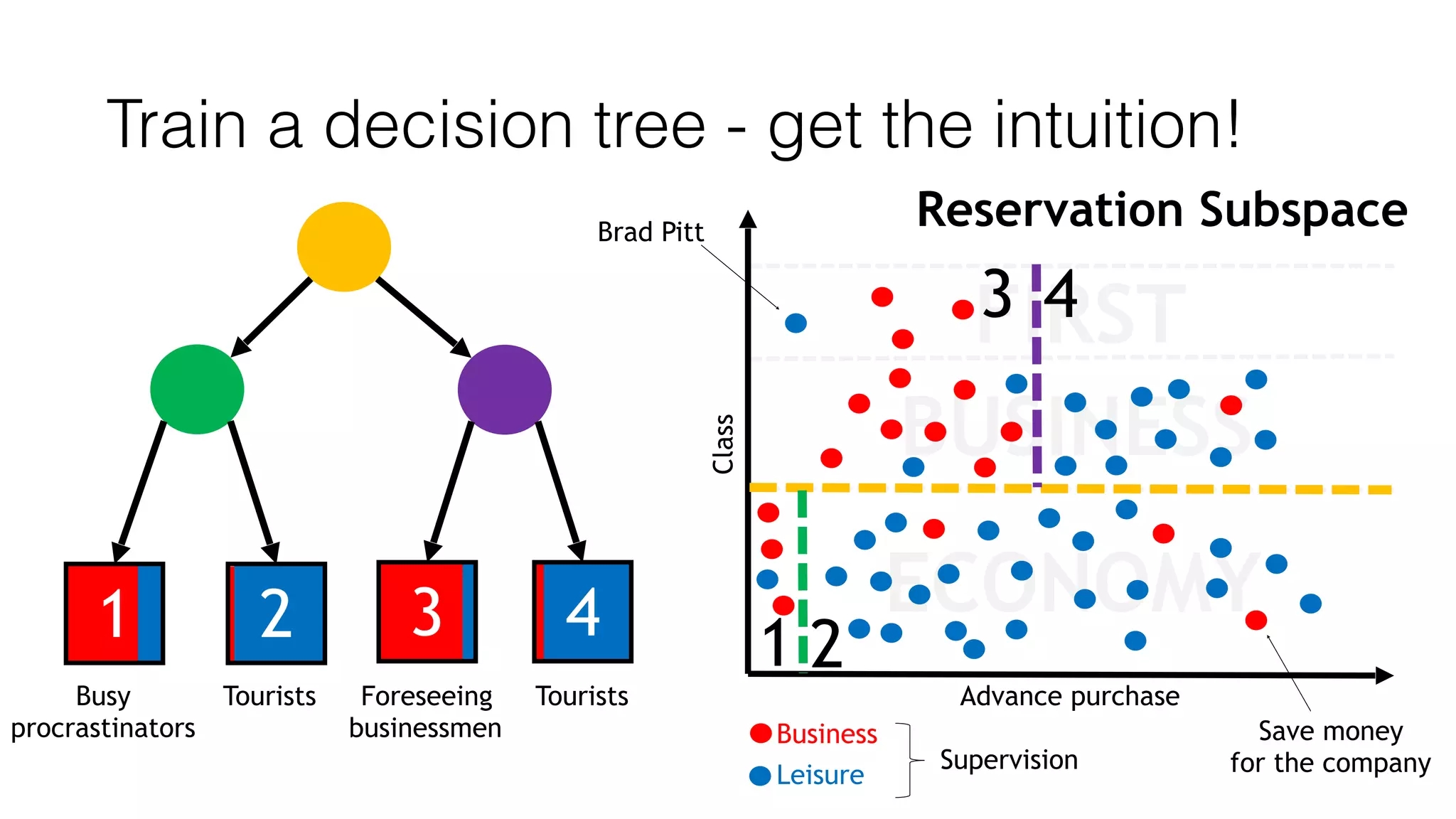
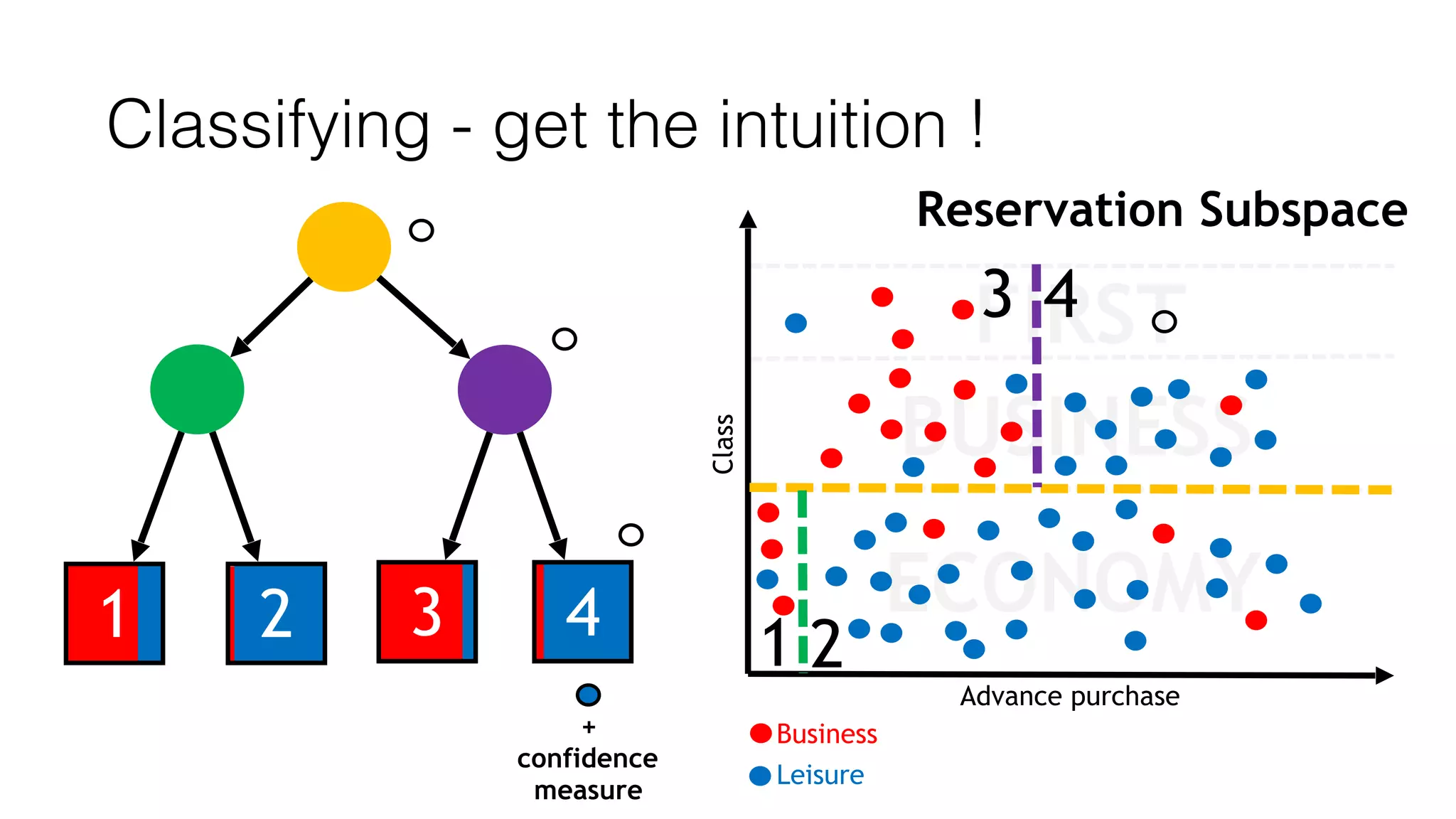
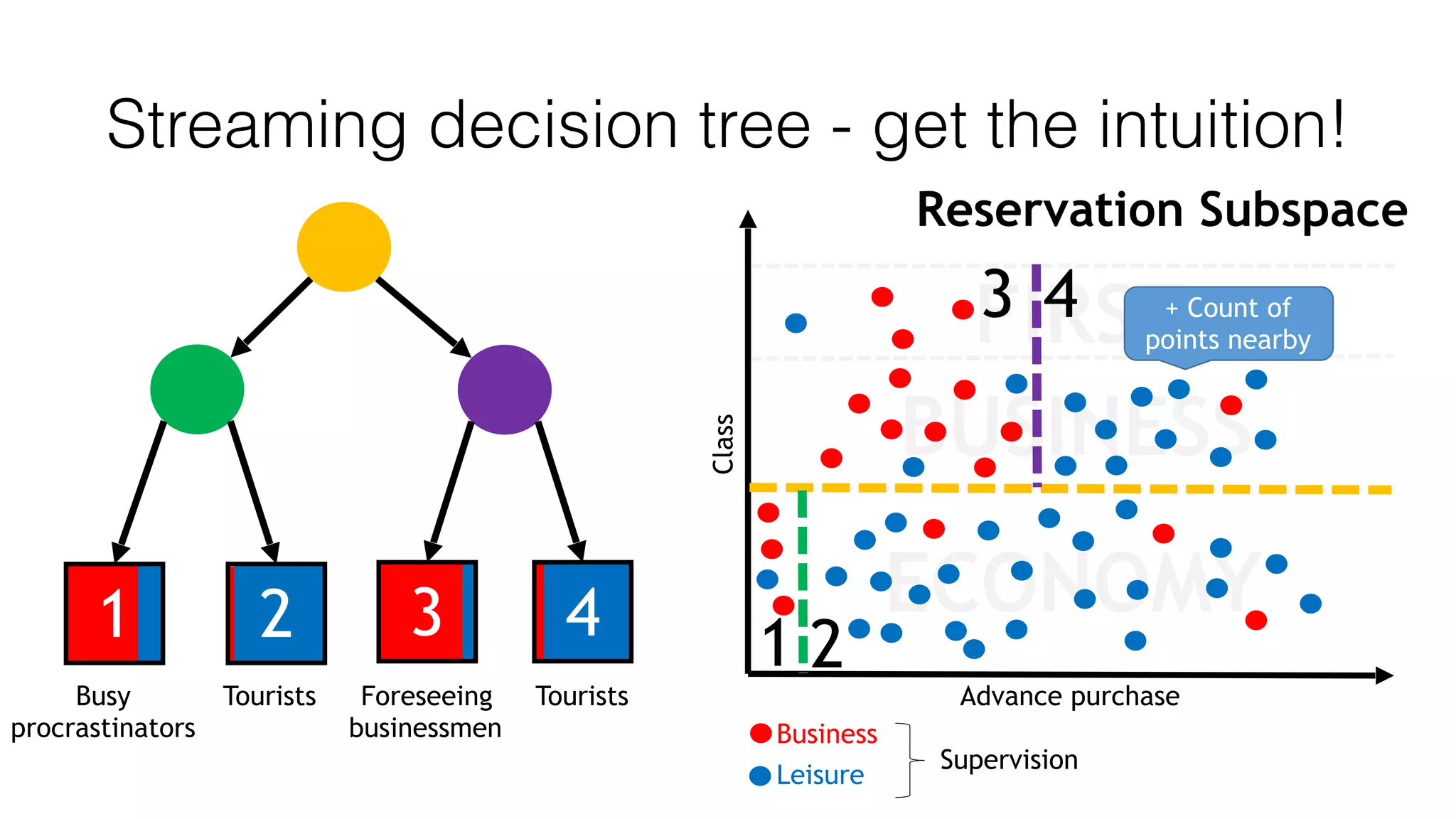
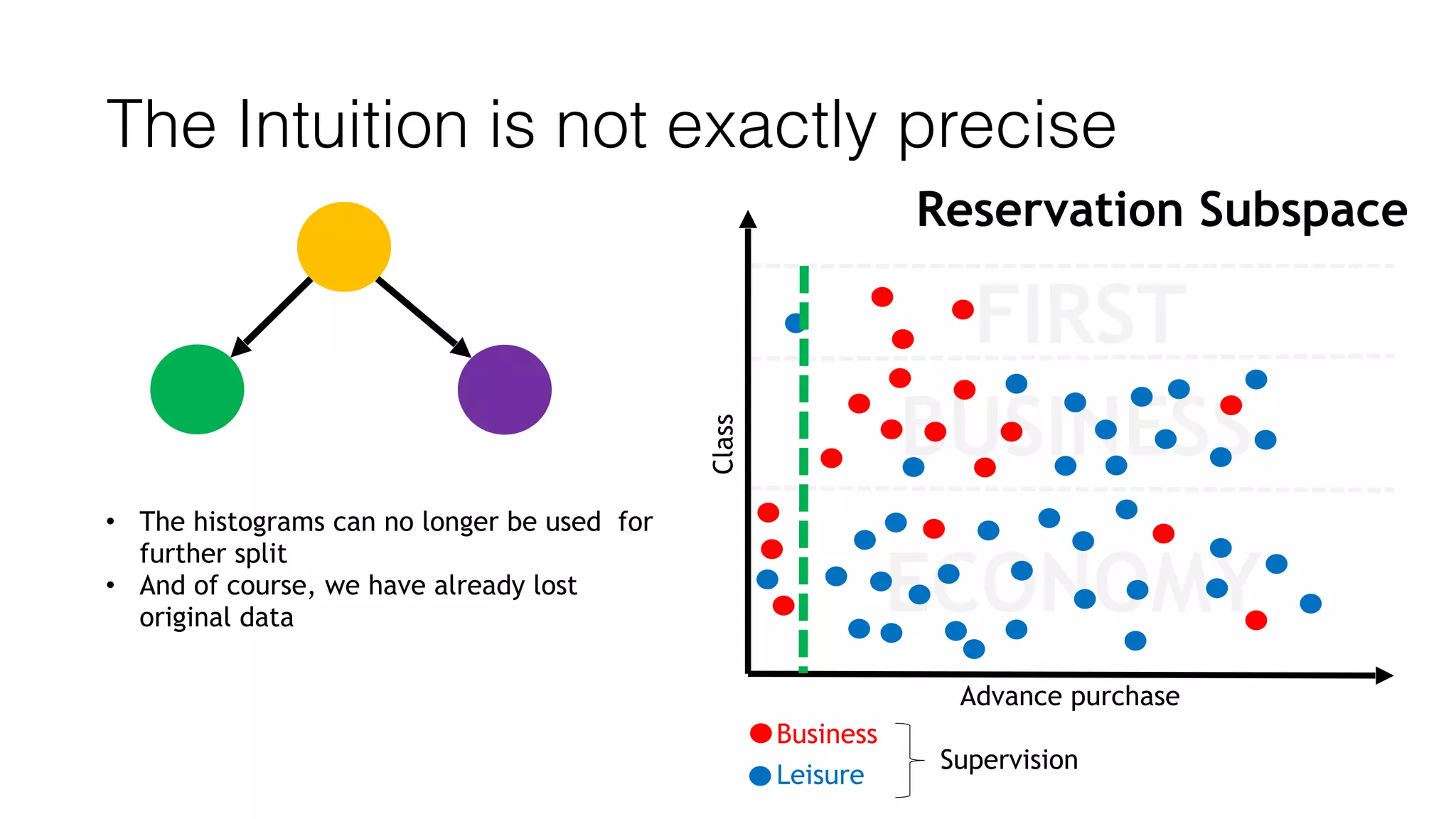
This document outlines a streaming decision tree classifier for classifying data streams using Apache Flink. It discusses the need for a classifier that can learn from streaming data. The architecture uses Kafka streams to ingest a stream of labeled data points and broadcast the evolving decision tree model. The algorithm builds approximate histograms over data features to determine split points for the decision tree in a streaming fashion without needing to store all data. This allows the classifier to continuously learn and make predictions on streaming data.























































![[Women in Data Science Meetup ATX] Decision Trees](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontrees-161118165341-thumbnail.jpg?width=640&height=640&fit=bounds)



















































