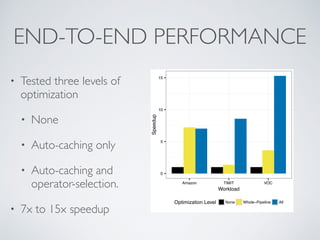
Download as PDF, PPTX













![TRANSFORMERS
TransformerInput Output
abstract classTransformer[In, Out] {
def apply(in: In): Out
def apply(in: RDD[In]): RDD[Out] = in.map(apply)
…
}
TYPE SAFETY HELPS ENSURE ROBUSTNESS](https://image.slidesharecdn.com/2ievanchan-160614230807/85/Optimizing-Terascale-Machine-Learning-Pipelines-with-Keystone-ML-26-320.jpg)
![ESTIMATORS
EstimatorRDD[Input]
abstract class Estimator[In, Out] {
def fit(in: RDD[In]):Transformer[In,Out]
…
}
Transformer
.fit()](https://image.slidesharecdn.com/2ievanchan-160614230807/85/Optimizing-Terascale-Machine-Learning-Pipelines-with-Keystone-ML-27-320.jpg)
![CHAINING
NGrams(2)String Vectorizer VectorBigrams
val featurizer:Transformer[String,Vector] = NGrams(2) thenVectorizer
featurizerString Vector
=](https://image.slidesharecdn.com/2ievanchan-160614230807/85/Optimizing-Terascale-Machine-Learning-Pipelines-with-Keystone-ML-28-320.jpg)
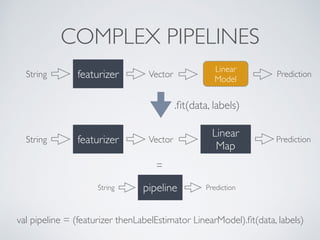

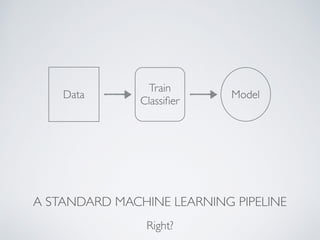
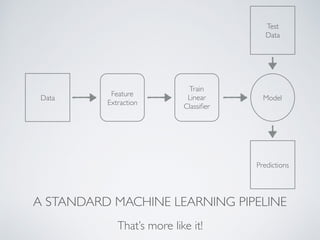
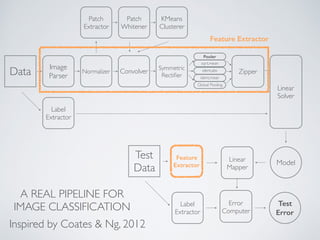
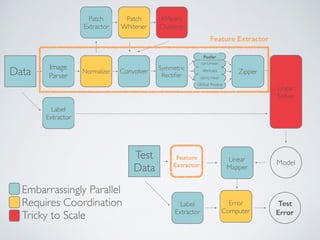
The document describes KeystoneML, an open source software framework for building scalable machine learning pipelines on Apache Spark. It discusses standard machine learning pipelines and examples of more complex pipelines for image classification, text classification, and recommender systems. It covers features of KeystoneML like transformers, estimators, and chaining estimators and transformers. It also discusses optimizing pipelines by choosing solvers, caching intermediate data, and operator selection. Benchmark results show KeystoneML achieves state-of-the-art accuracy on large datasets faster than other systems through end-to-end pipeline optimizations.











































































































