Download to read offline








The document discusses the challenges of achieving in-order processing in stream processing frameworks like Flink and Beam, particularly in financial services which require precise event ordering. It explains the concept of 'sequenced streams' and outlines the differences between traditional event processing and the proposed sequencer architecture to ensure global event order. It calls for improvements in stream processing frameworks to explicitly maintain order from the source during processing, highlighting the importance of preserving order for applications in the financial industry.
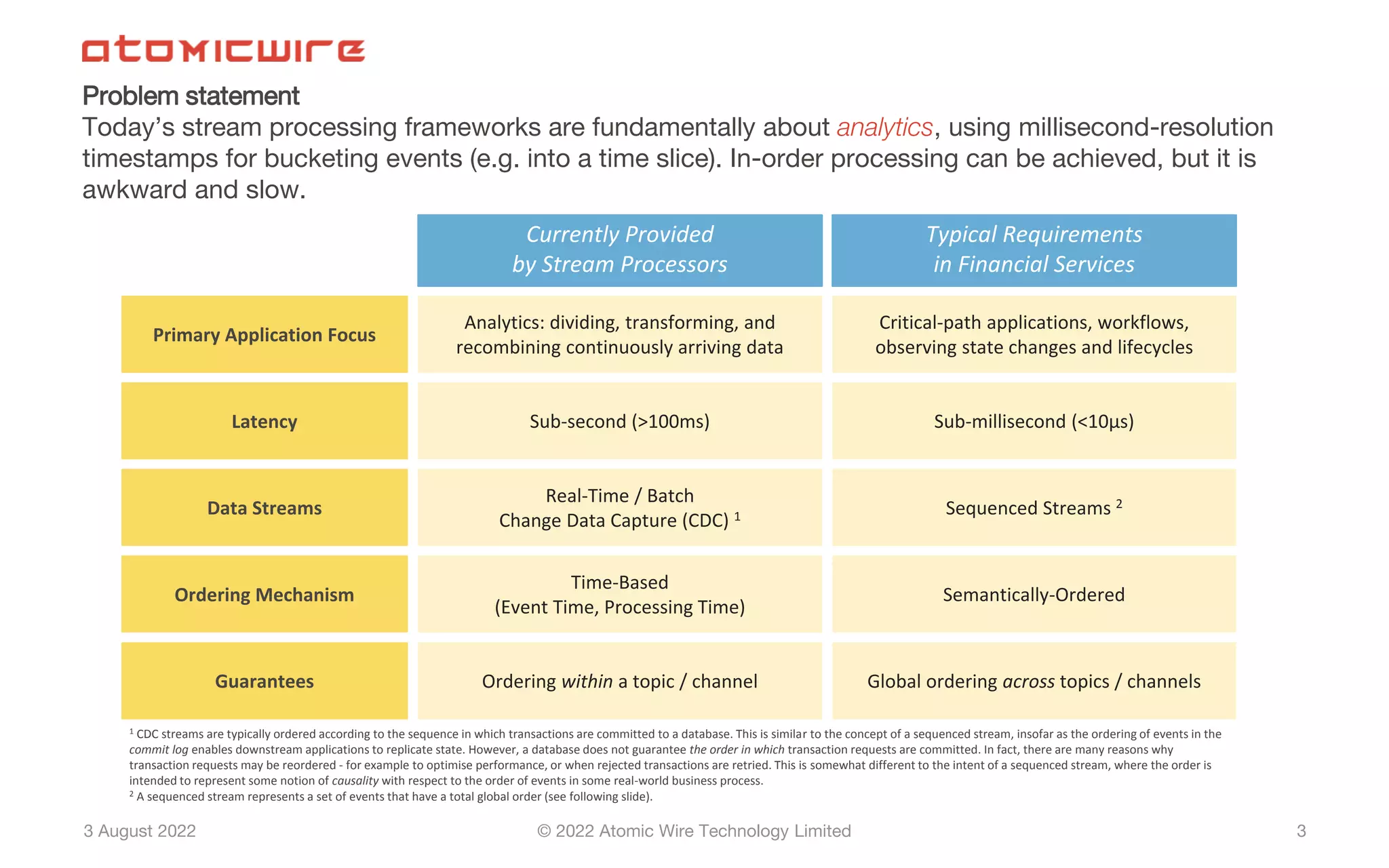
Overview of stream processing, focus on financial services, achieving in-order processing.
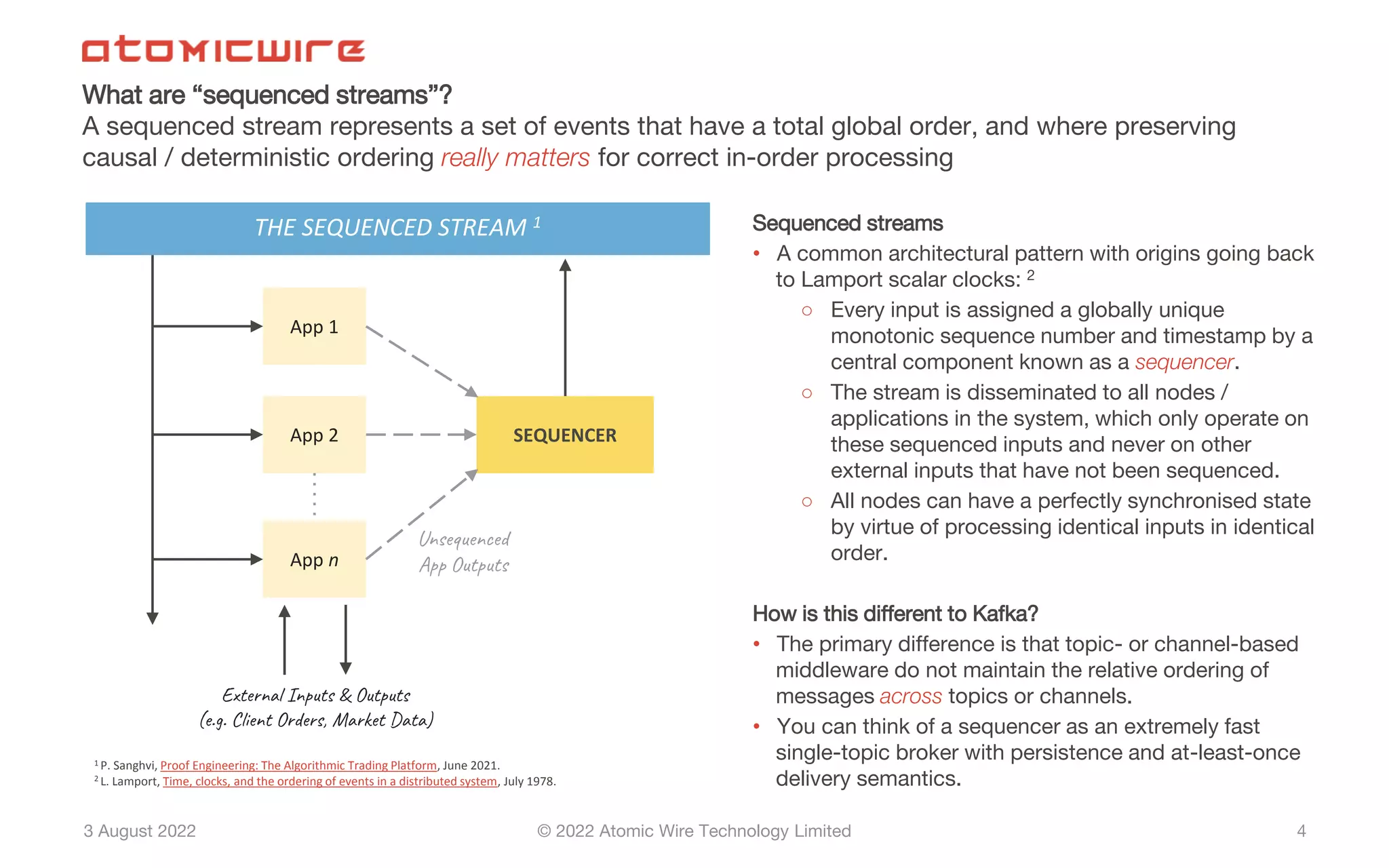
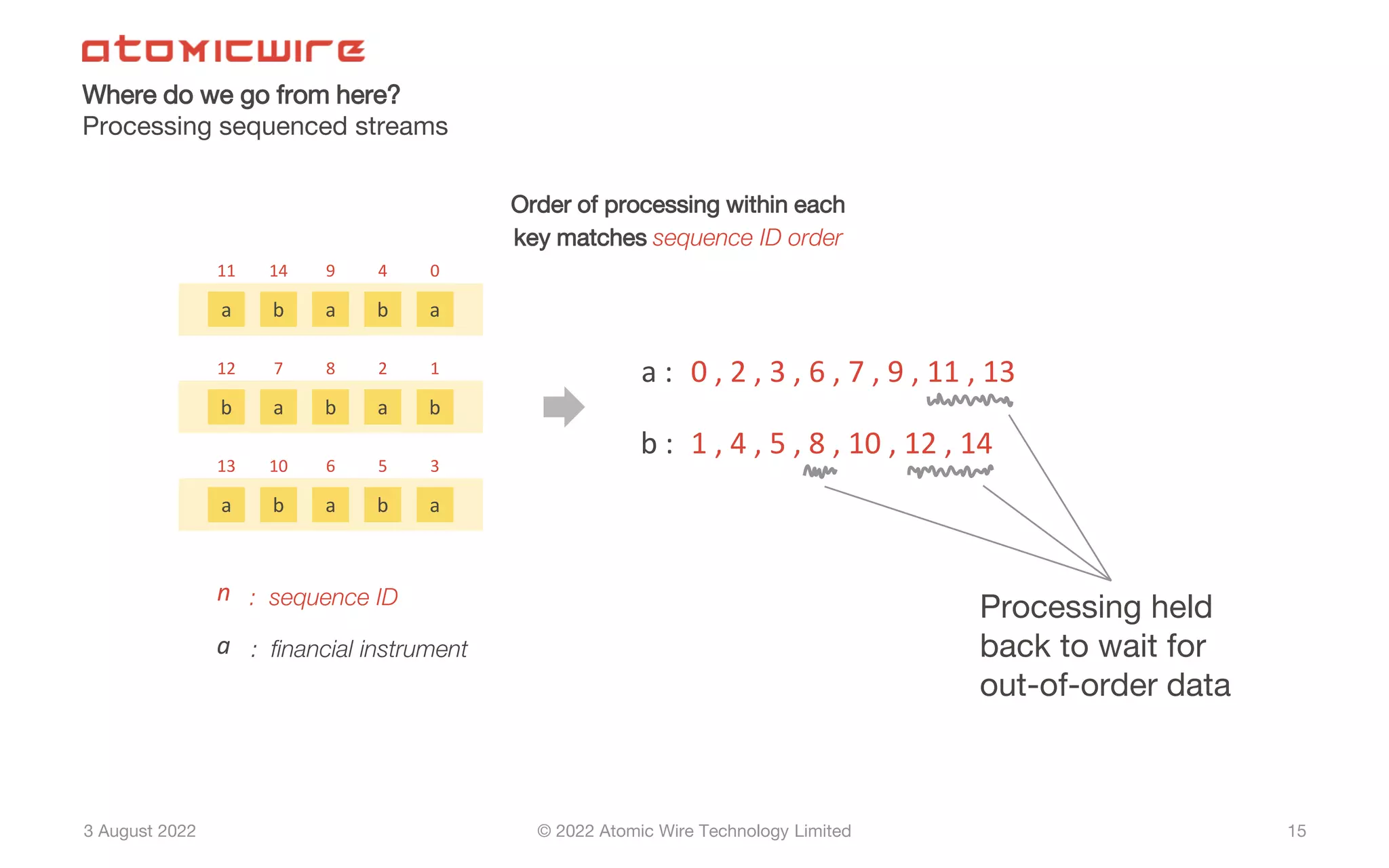
Current frameworks struggle with in-order processing; need for sequenced streams for correct order.
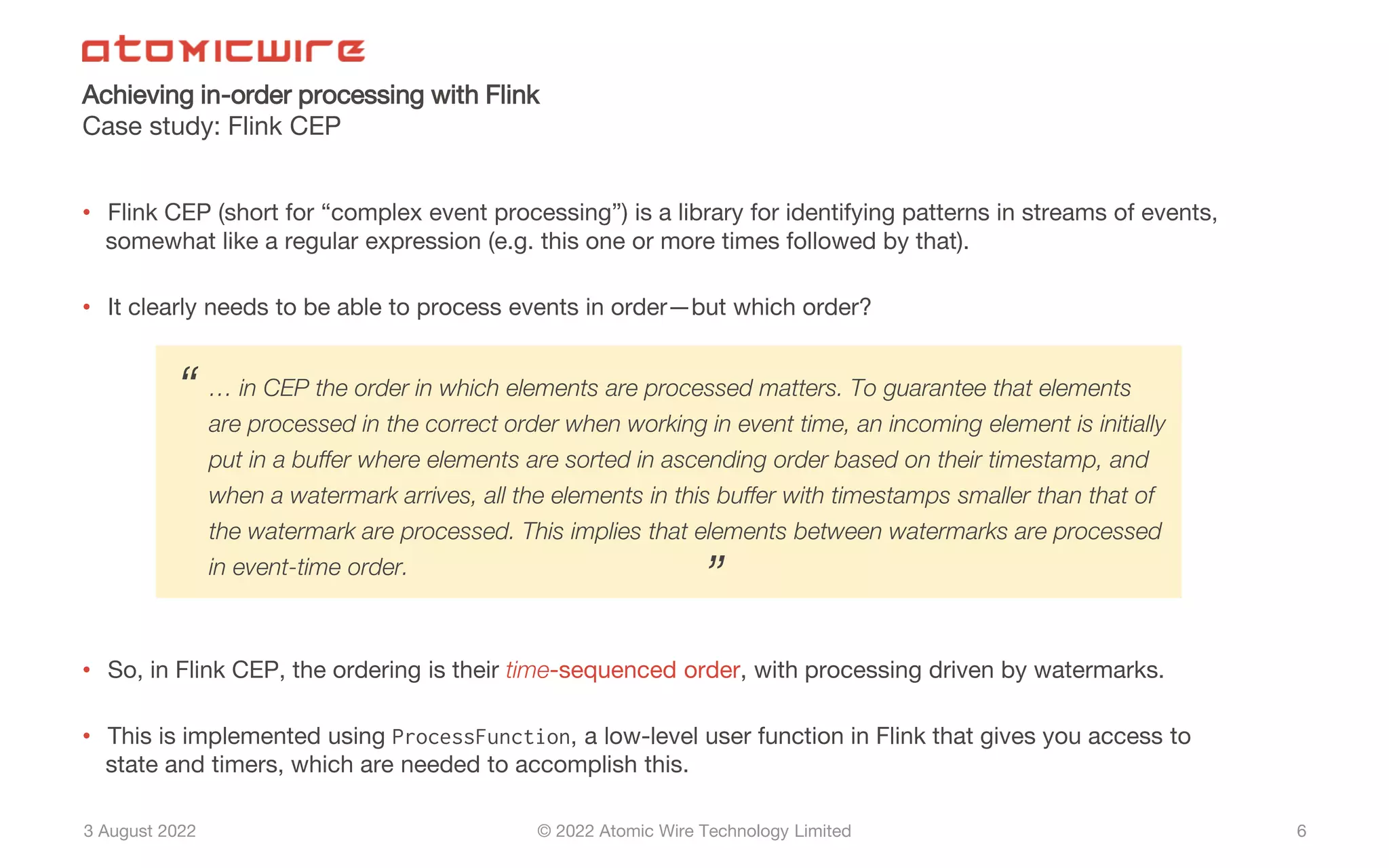
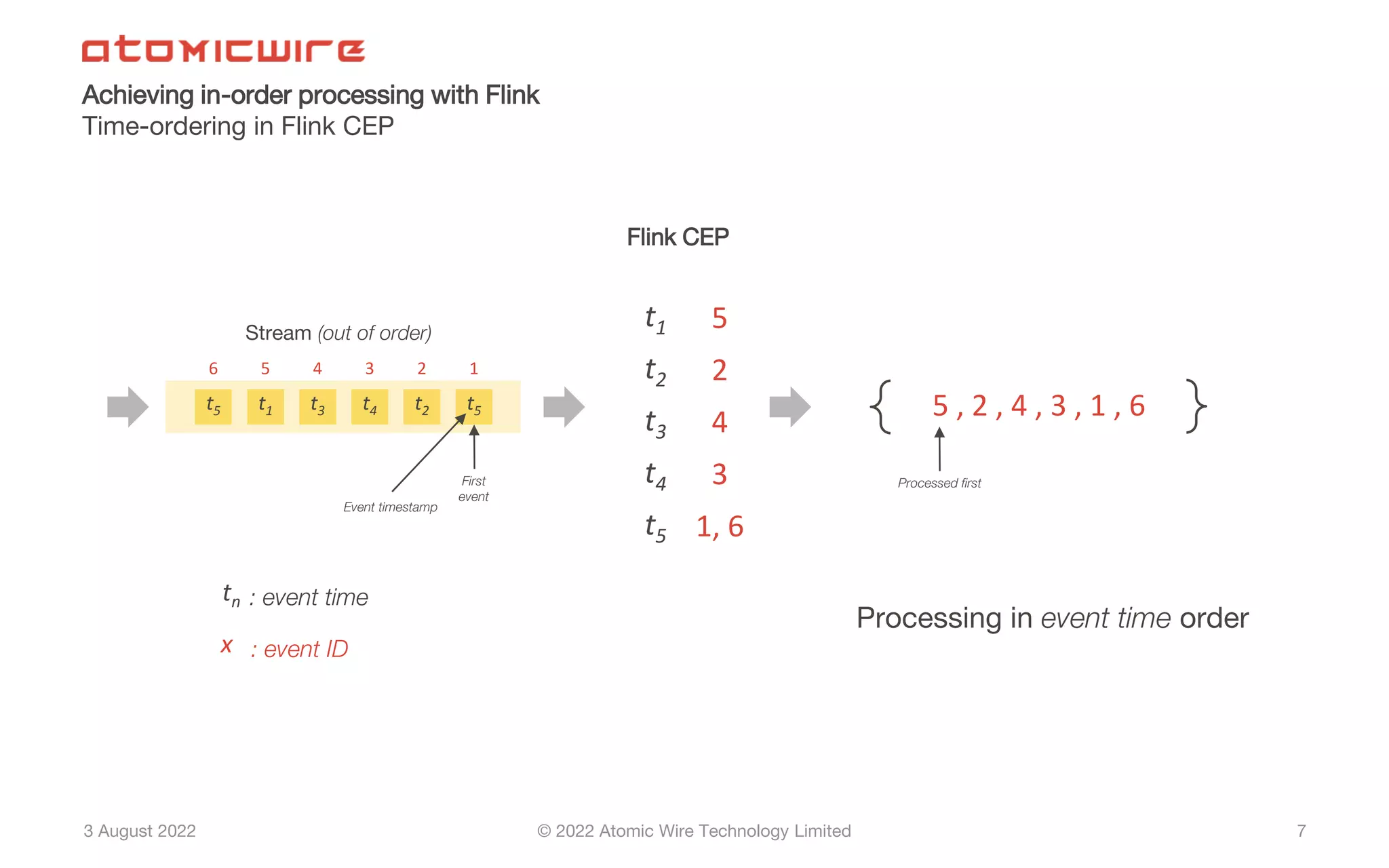
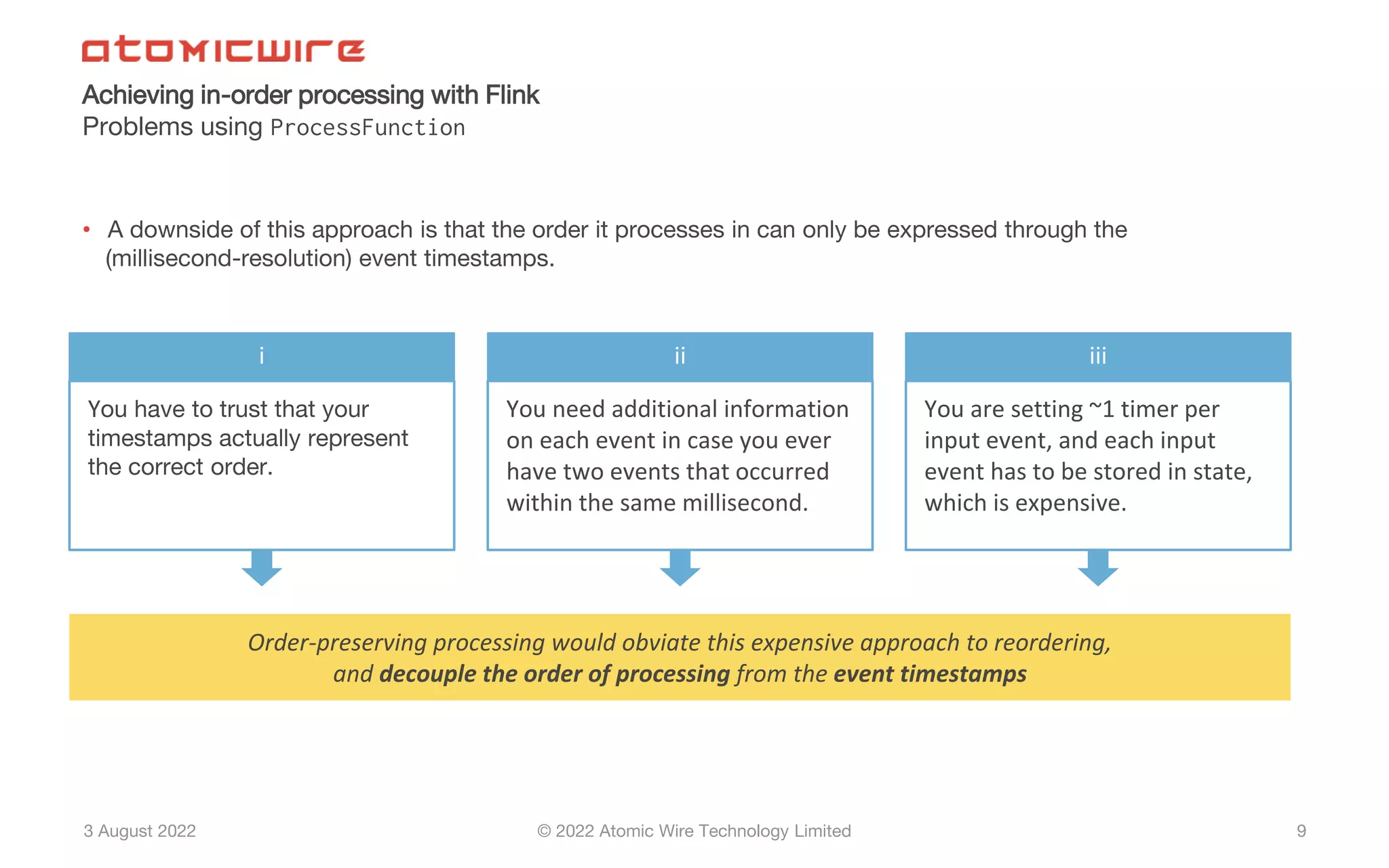
Definition and methods for achieving in-order processing in Flink, including challenges and pseudocode.
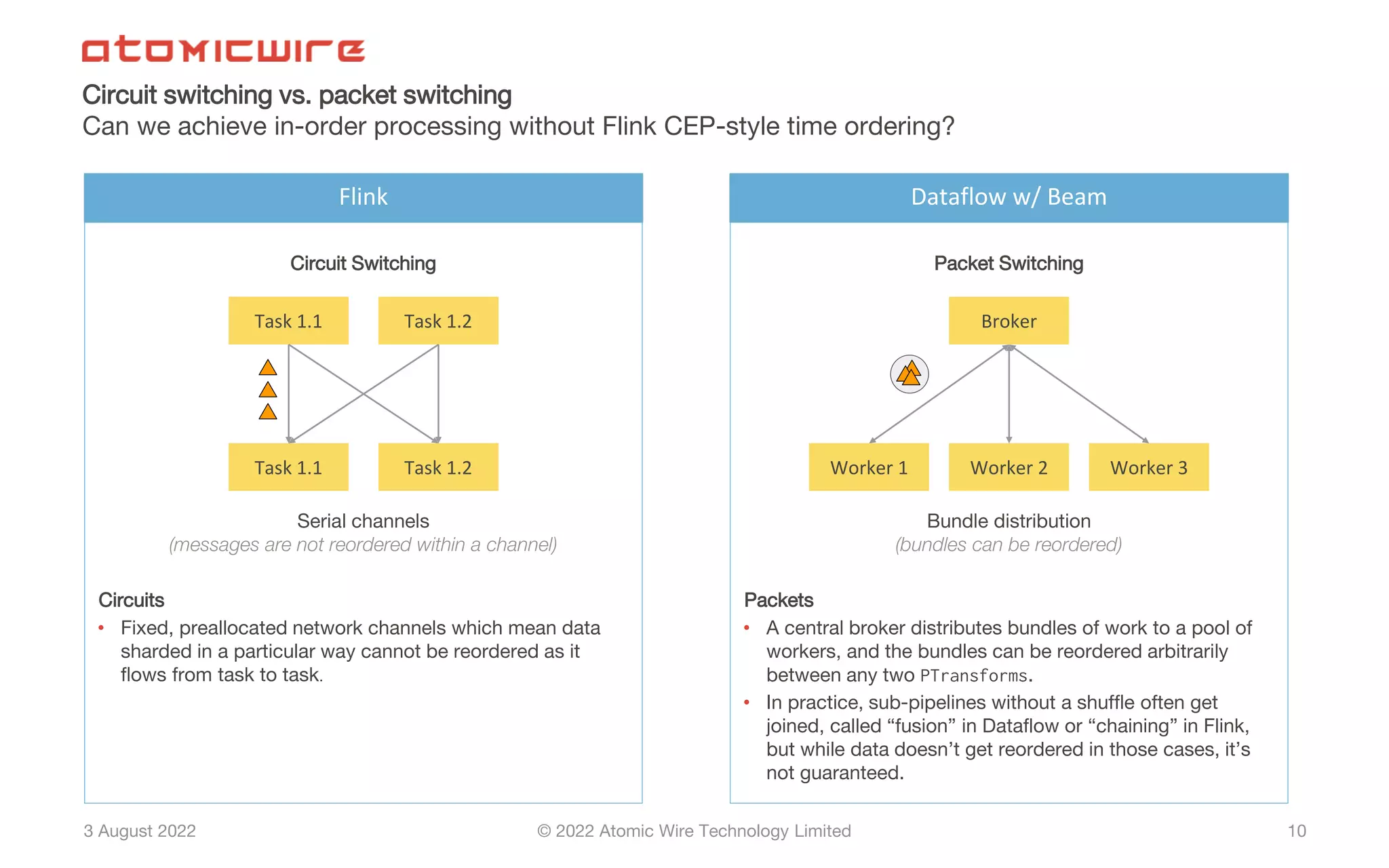
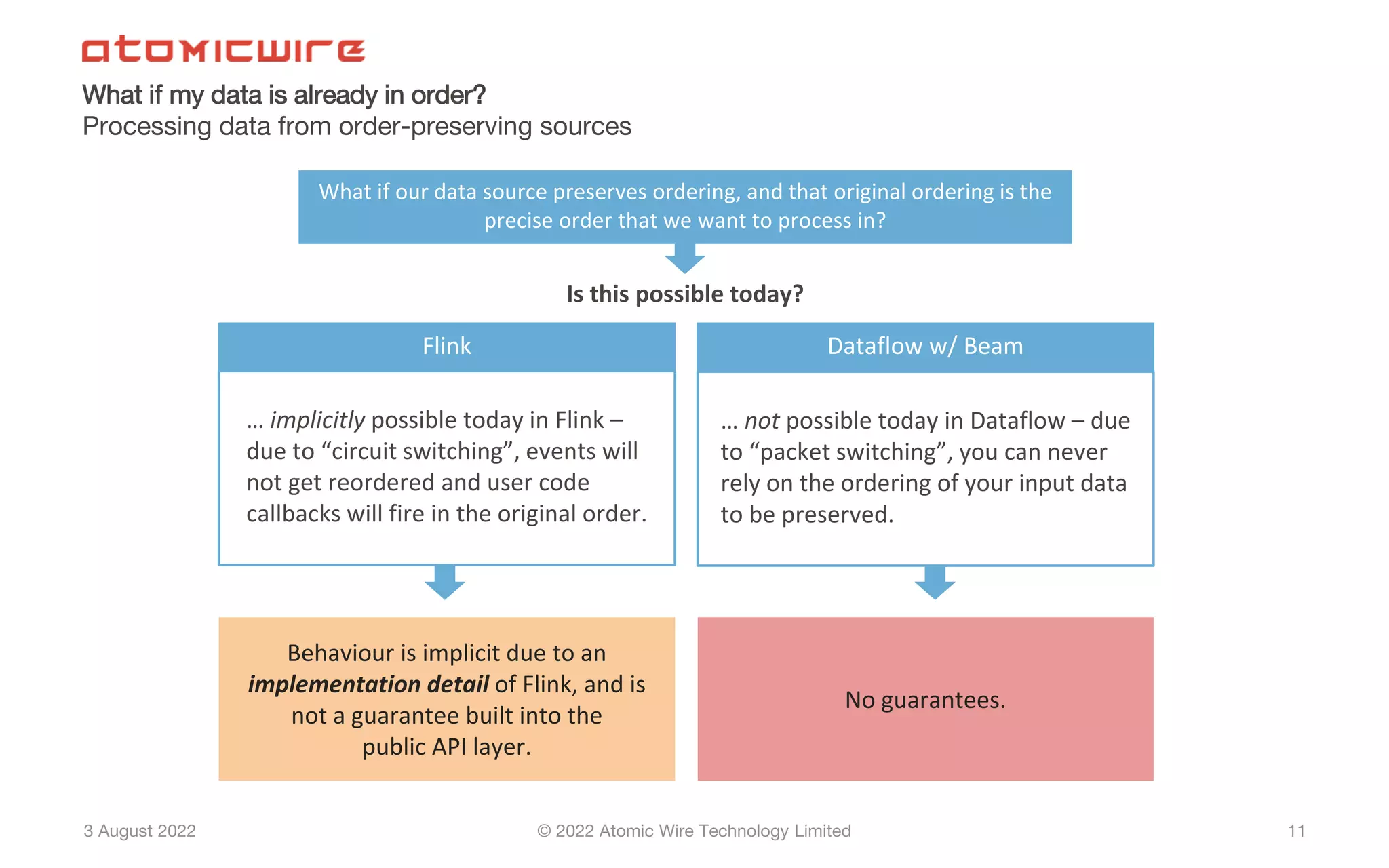
Comparing circuit and packet switching in stream processing; challenges in using Beam for in-order processing.
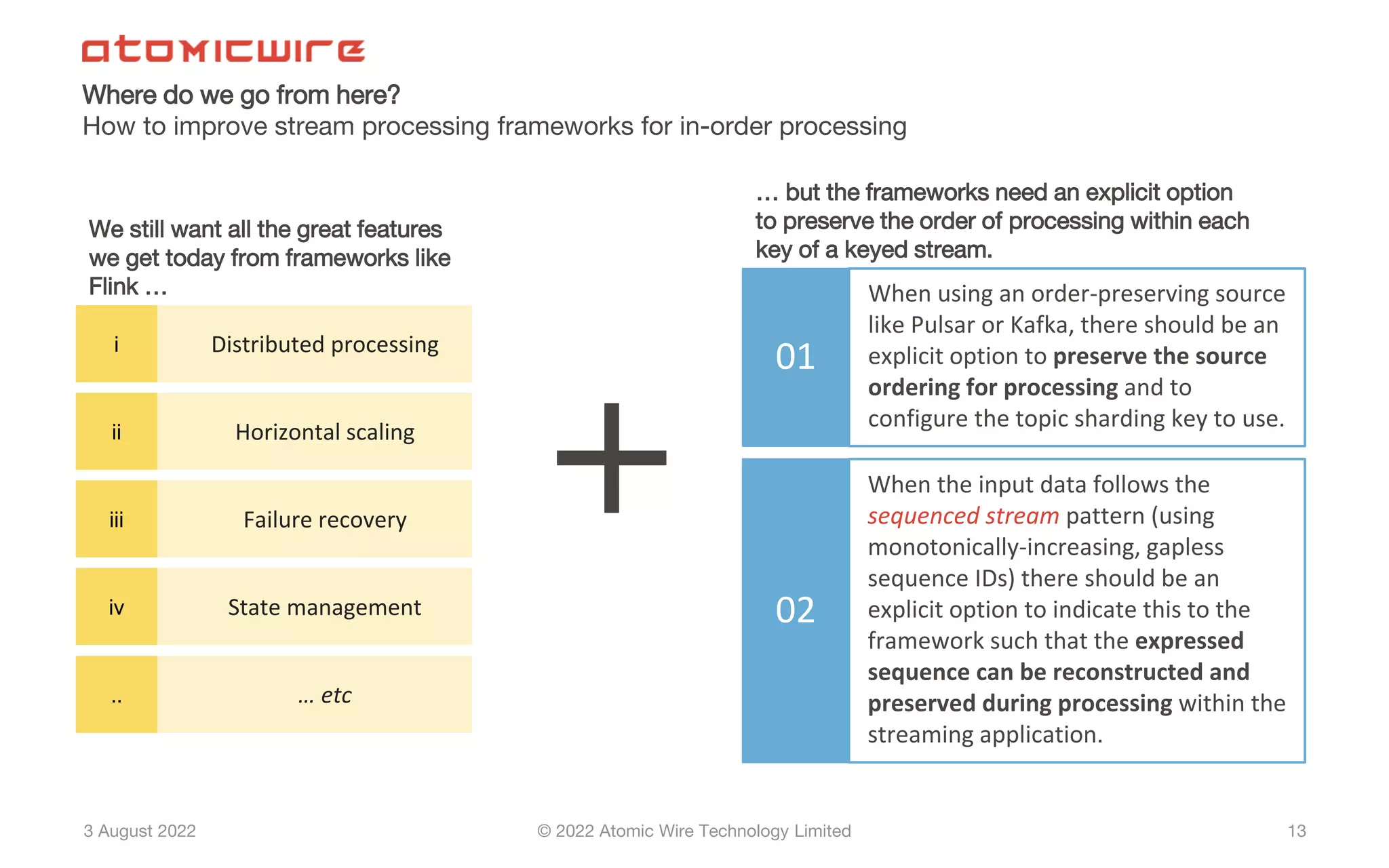
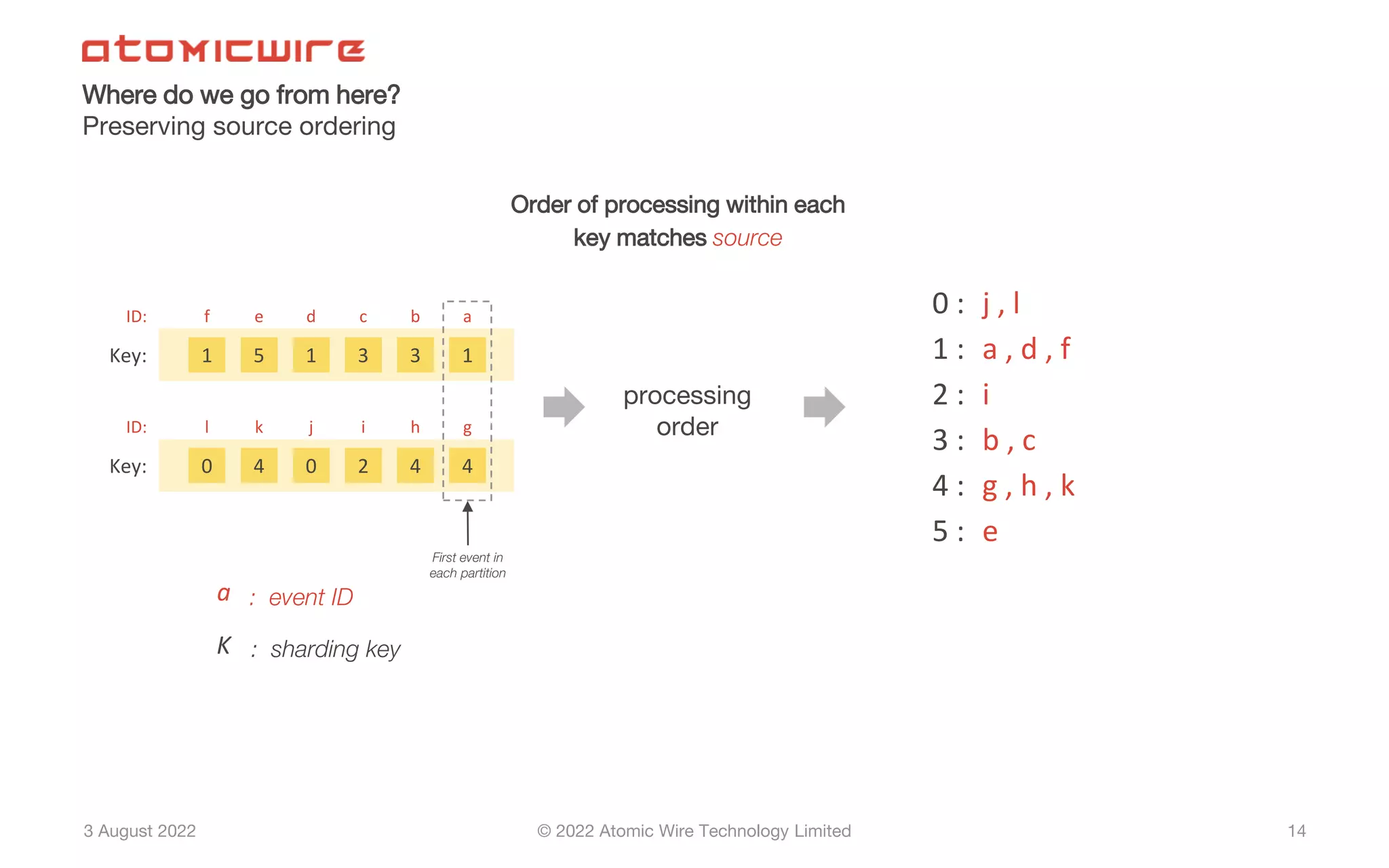
Recommendations for enhancing frameworks like Flink to preserve order in processing sequenced streams.
Invitation for input on achieving in-order processing in Flink and solutions to overcome existing challenges.
Atomic Wire is hiring for positions focused on stream processing within the financial sector.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















