Download as PDF, PPTX

















![Streaming Random Forest
24#SAISEco7
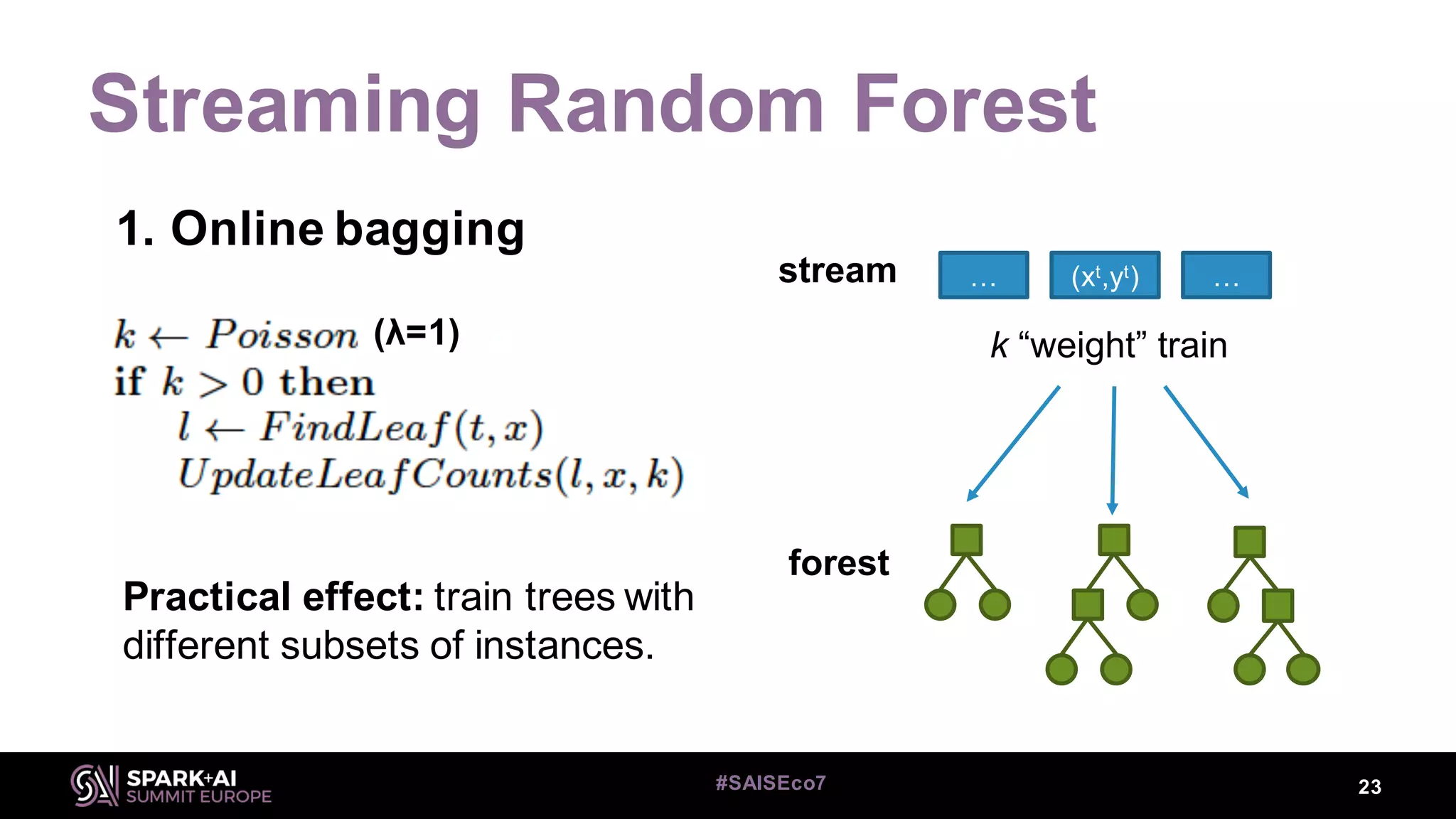
1. Online bagging
Leveraging [online] bagging
Augment λ (usually 6), such that instances are used more often
Leveraging bagging for evolving data streams. Bifet, Holmes, Pfahringer
(2010). ECML-PKDD, Springer.](https://image.slidesharecdn.com/07heitormurilogomesalbertbifet-181010225722/75/Streaming-Random-Forest-Learning-in-Spark-and-StreamDM-with-Heitor-Murilogomes-and-Albert-Bifet-24-2048.jpg)




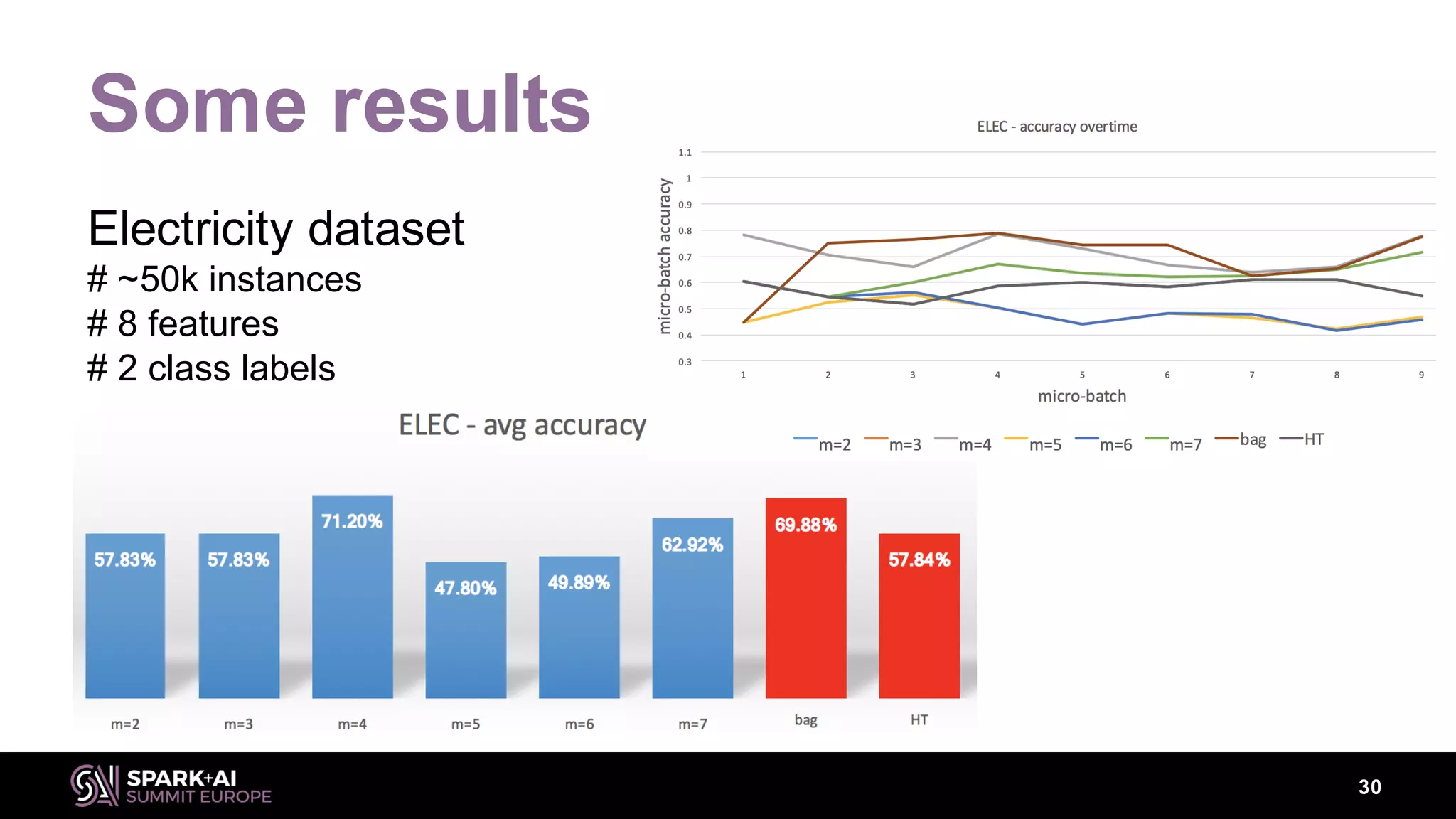
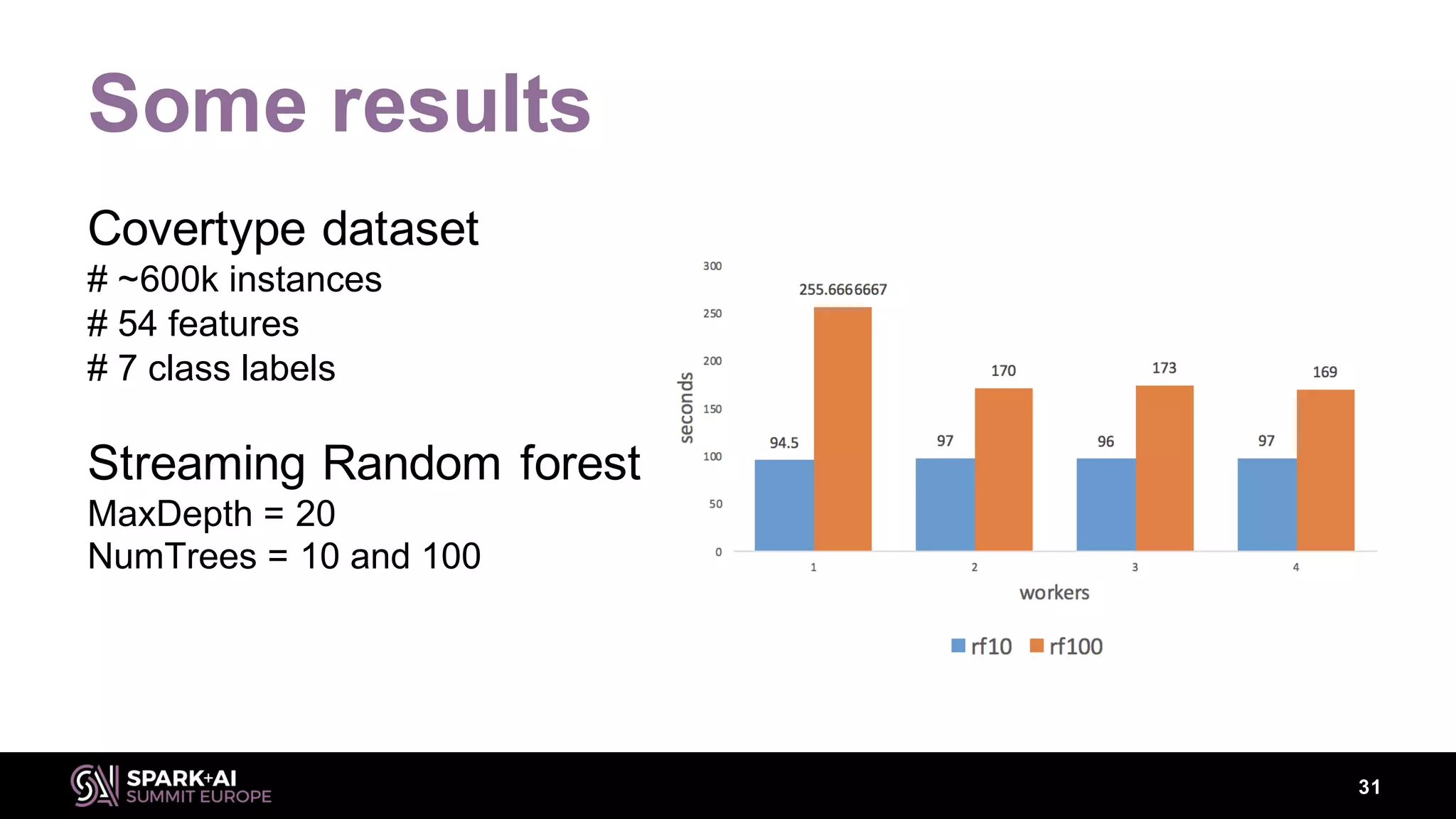






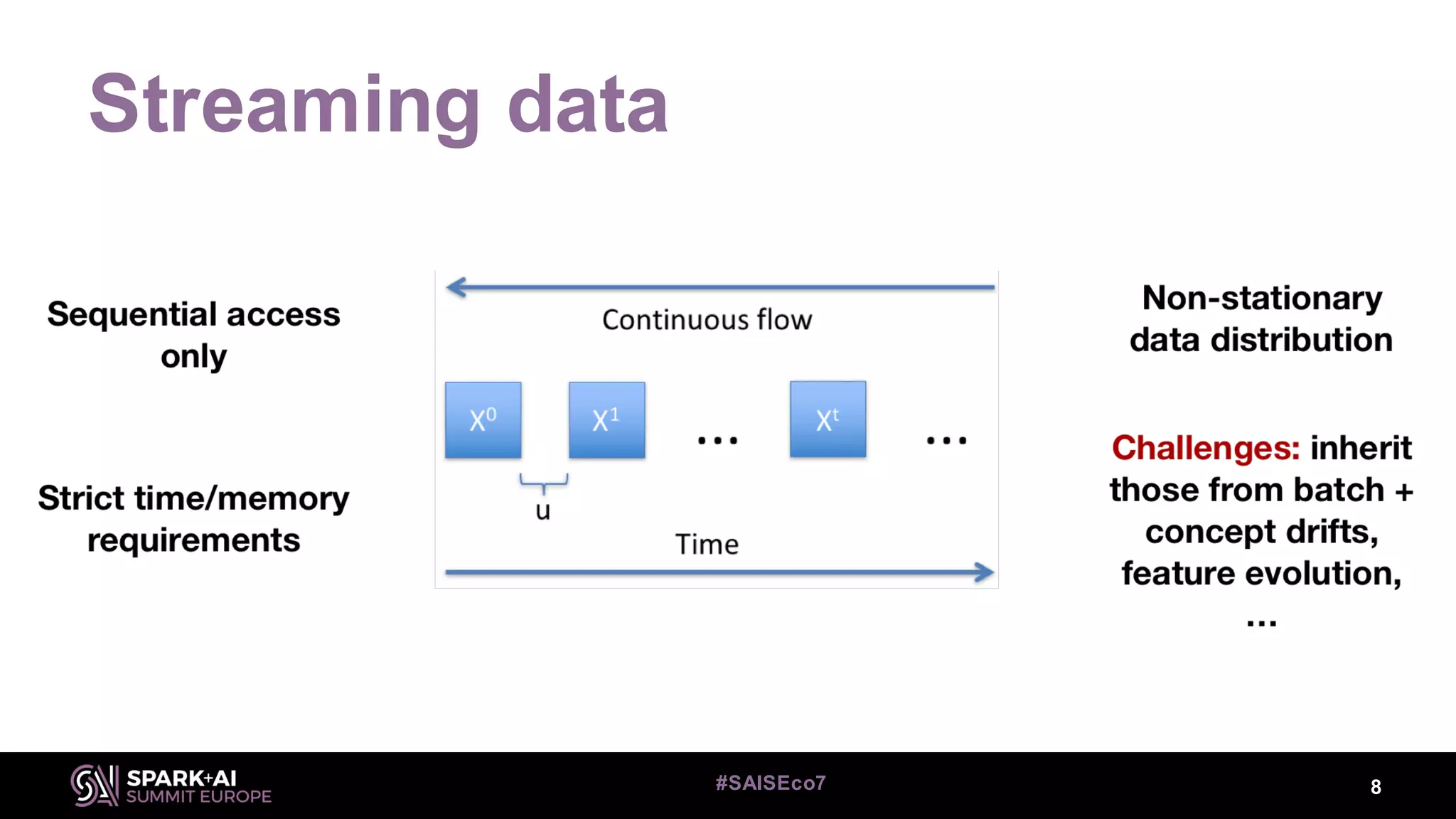
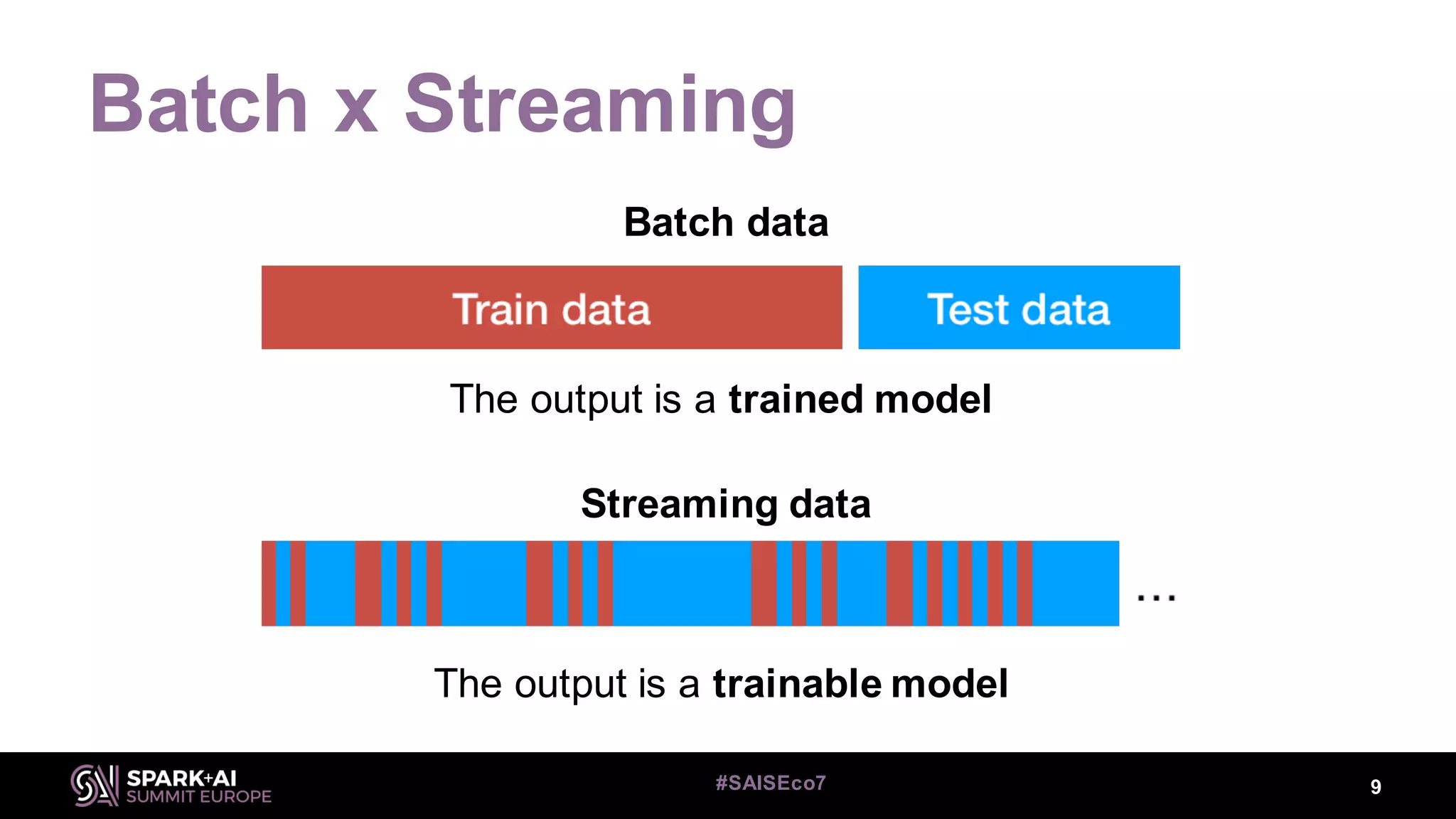
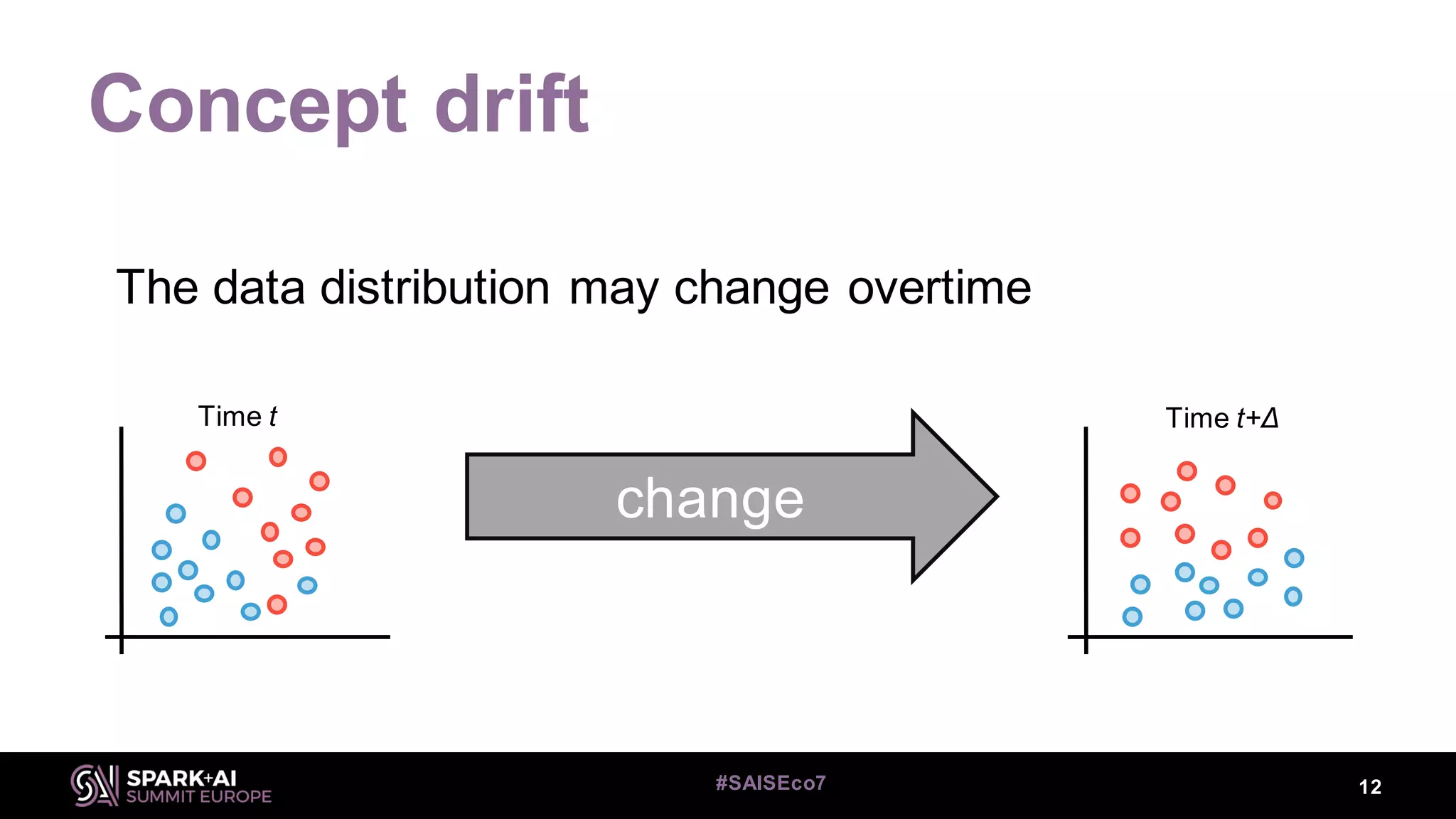
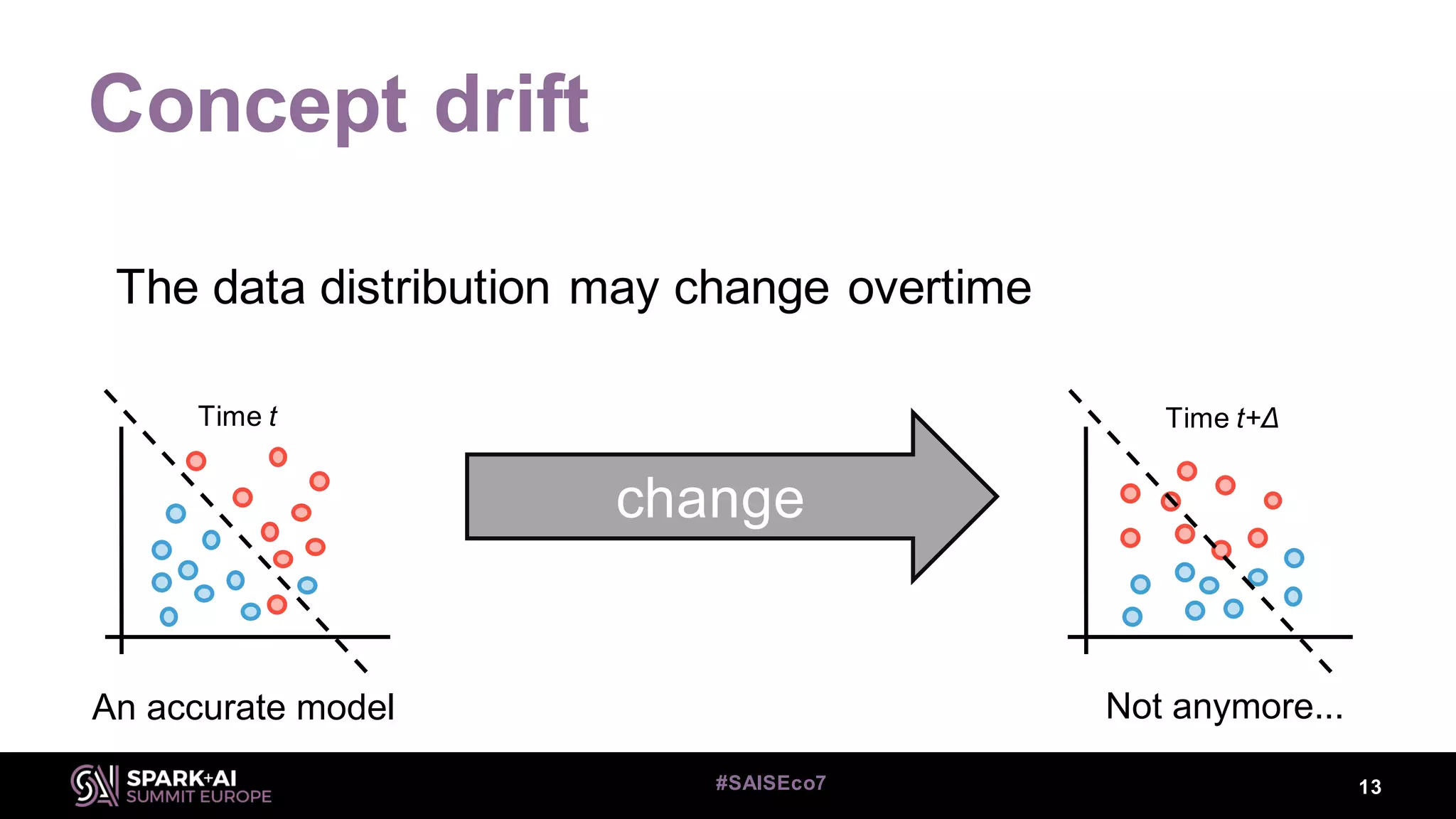
This document discusses machine learning for streaming data and summarizes the Streaming Random Forest algorithm and its implementation in Spark and StreamDM. It begins with an introduction to the speaker and definitions of key concepts like data streams, batch vs streaming data, and concept drift. It then describes the Streaming Decision Tree algorithm and how Streaming Random Forest extends it with online bagging and random feature selection. The document demonstrates implementations in MLLib and StreamDM and shows results on electricity and covertype datasets. It concludes with future directions for StreamDM, algorithms, and performance improvements.













































































