Download to read offline






The document introduces the new async sink for Apache Flink, detailing its internal architecture and functionality including buffering, batching, retry mechanisms, and managing throughput. It outlines configuration options and current limitations like ordering guarantees and thread pool management. Future enhancements mentioned include rate limiting features and integration with Amazon DynamoDB.
Introduction of the Async Sink by AWS team members Danny Cranmer and Steffen Hausmann.
Overview of the Apache Flink connector ecosystem including Amazon Kinesis, Elasticsearch, RabbitMQ, and Google PubSub.
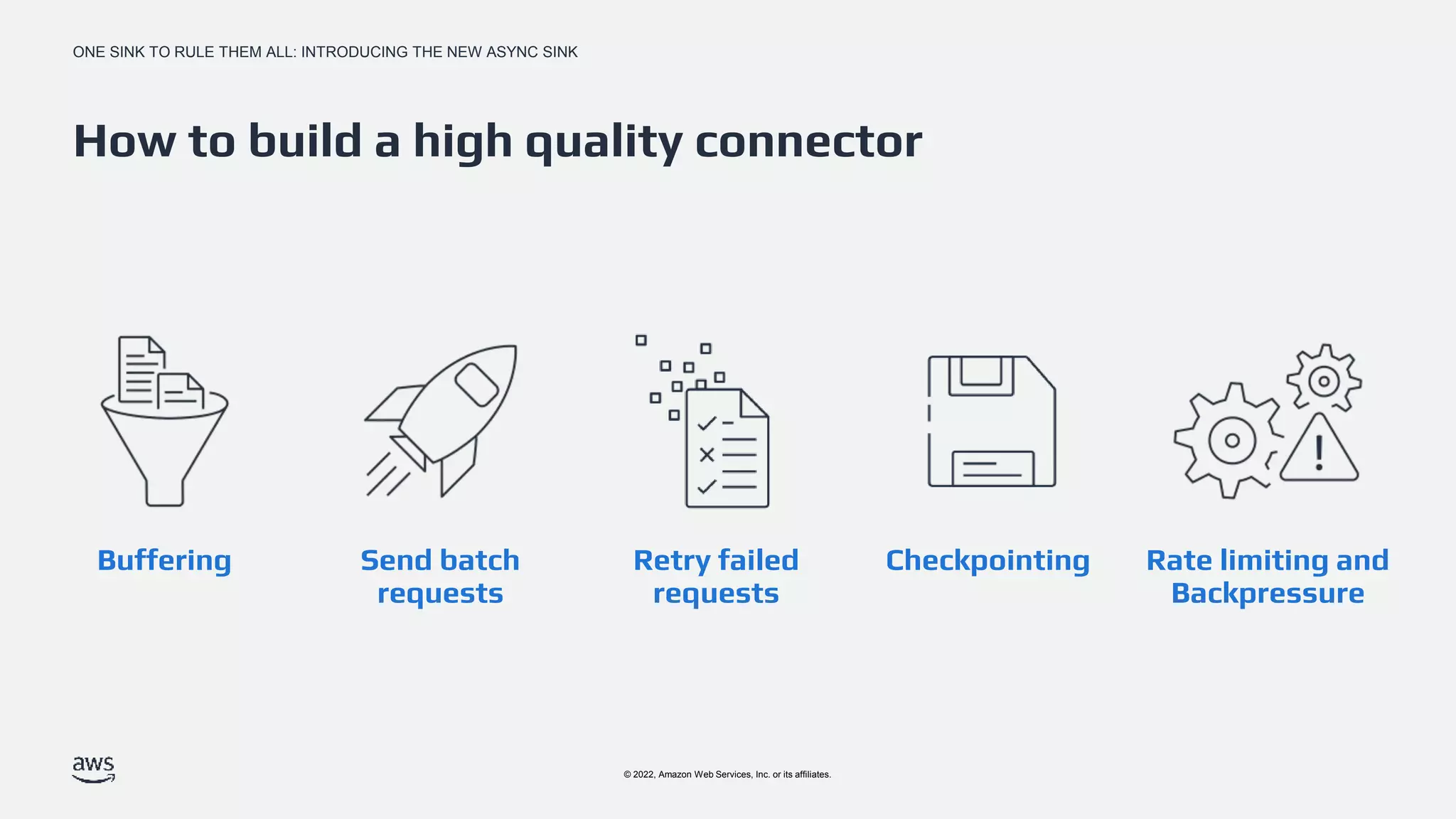
Key aspects for developing a high-quality connector: buffering, batch sending, request retries, checkpointing, and rate limiting.
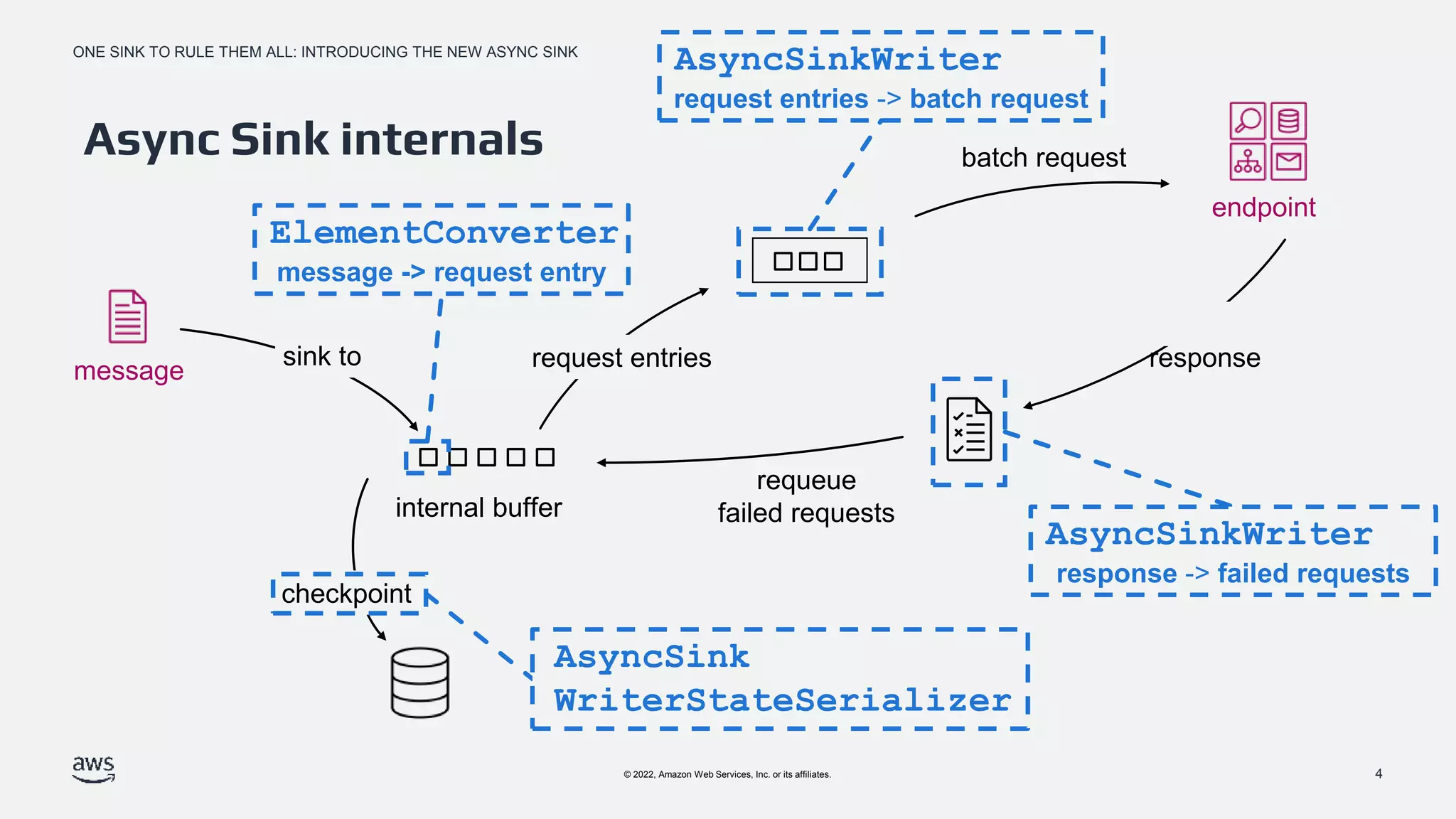
Detailed internals of the Async Sink focusing on components like the internal buffer, request entries, and error handling.
Methodologies for managing throughput, including in-flight request limits and adjustments based on batch request success or failure.
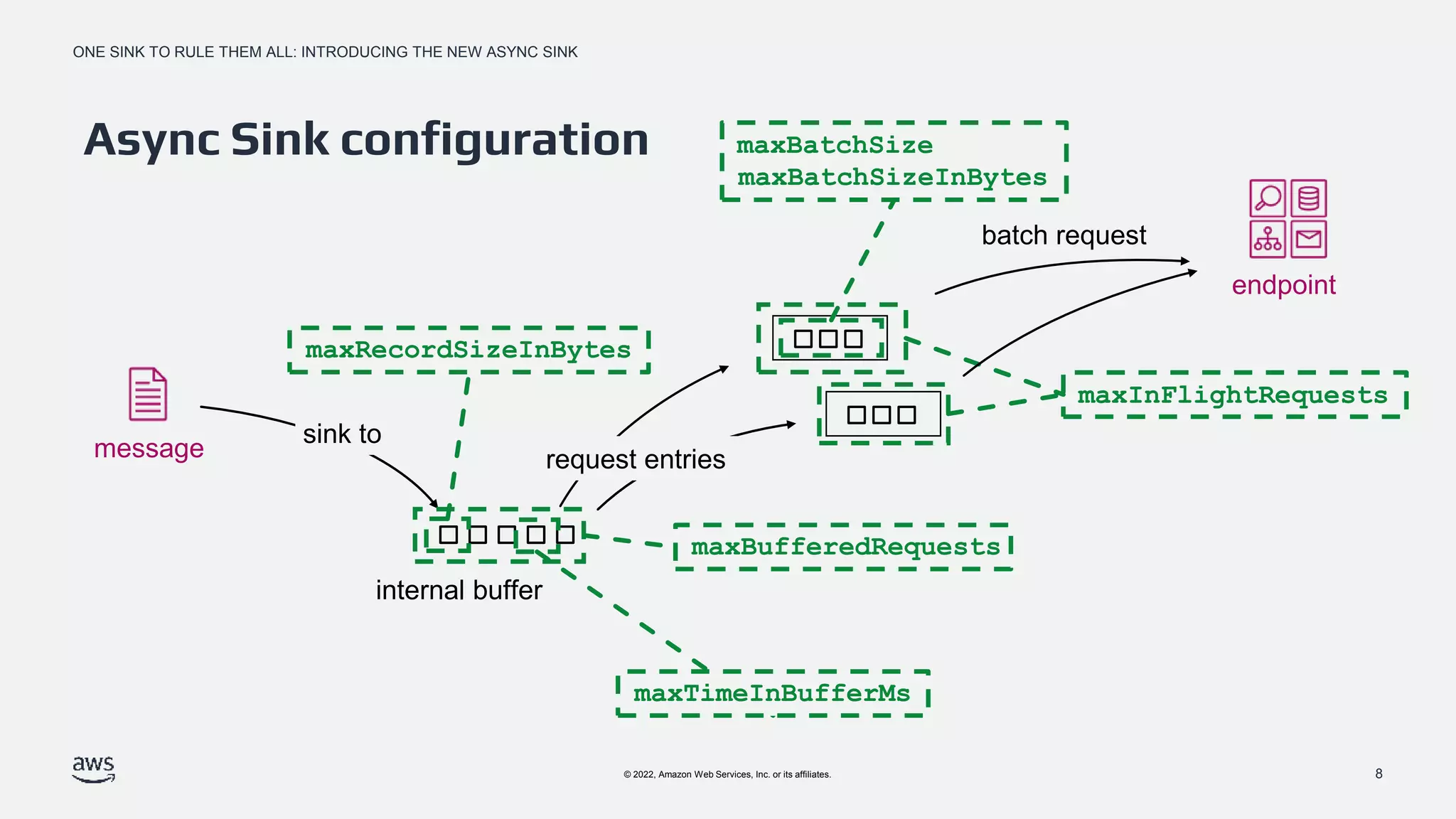
Configuration settings for Async Sink, including max record size, in-flight requests, batch size, and buffer timing.
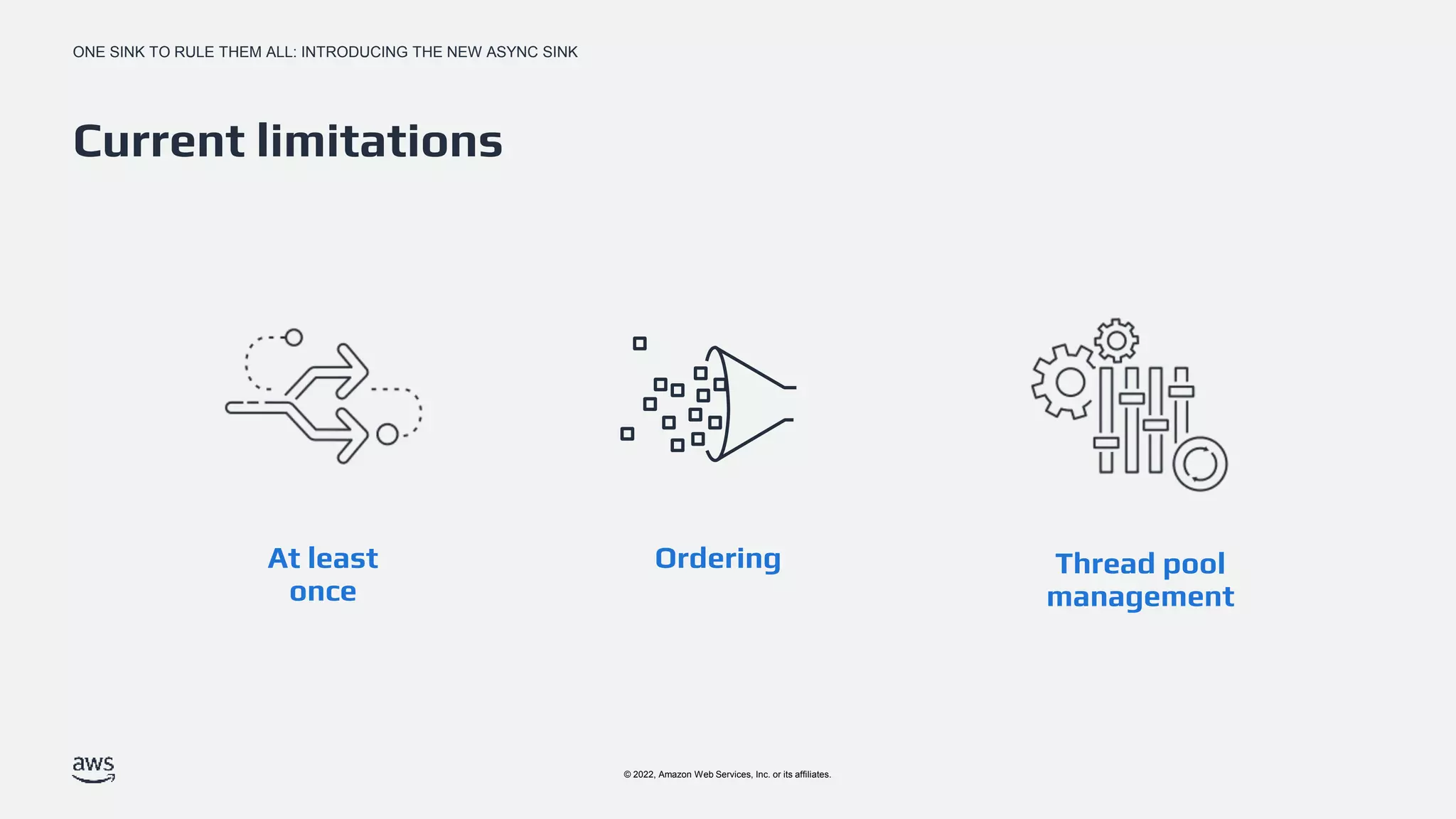
Discussion of limitations in the Async Sink such as at-least-once delivery, ordering, and thread pool management.
Next steps for Async Sink including configurable rate limiting and a new Amazon DynamoDB Sink to boost community adoption.
Concluding remarks and thanks from presenters Danny Cranmer and Steffen Hausmann.
























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

