Downloaded 18 times

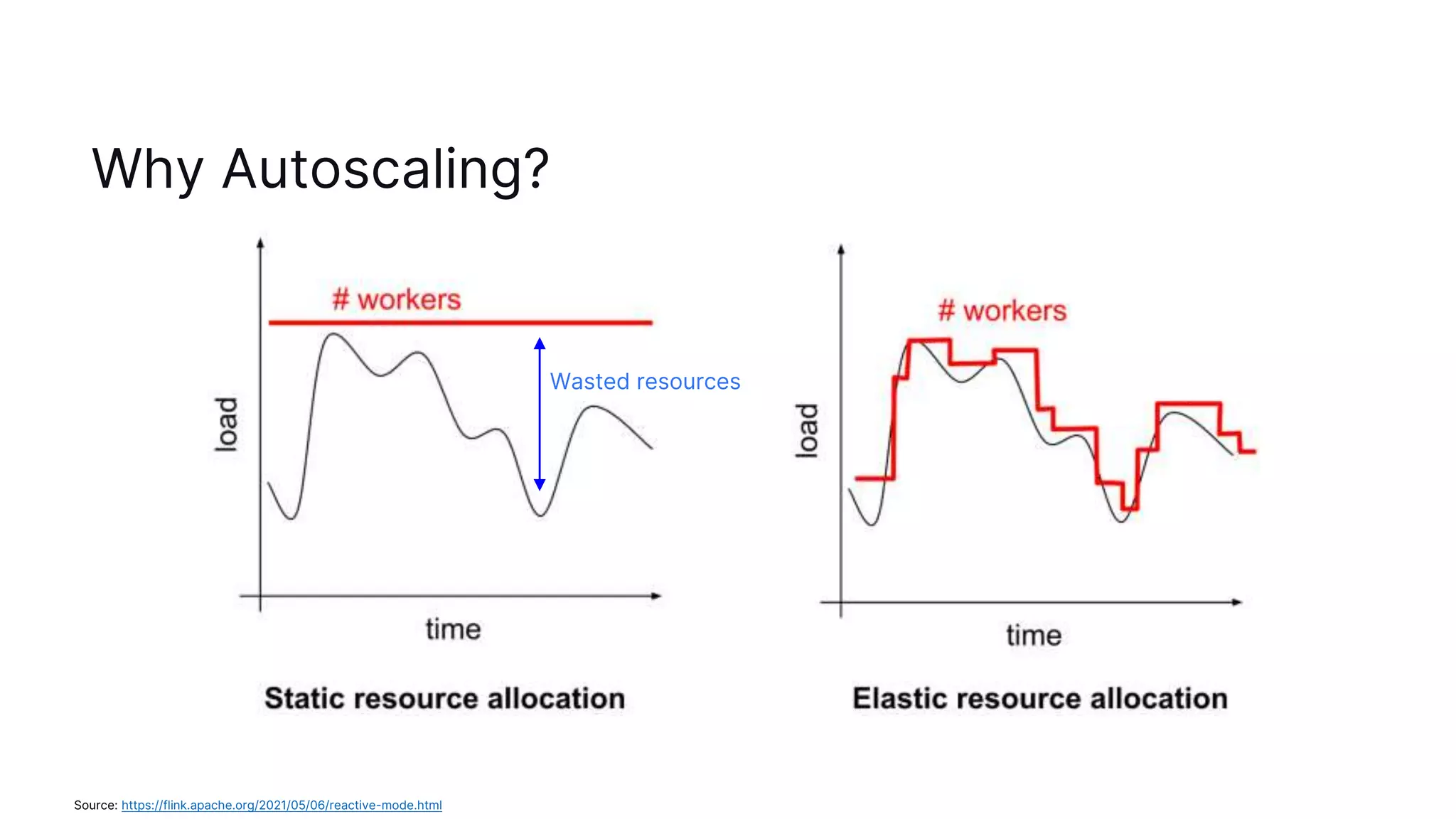



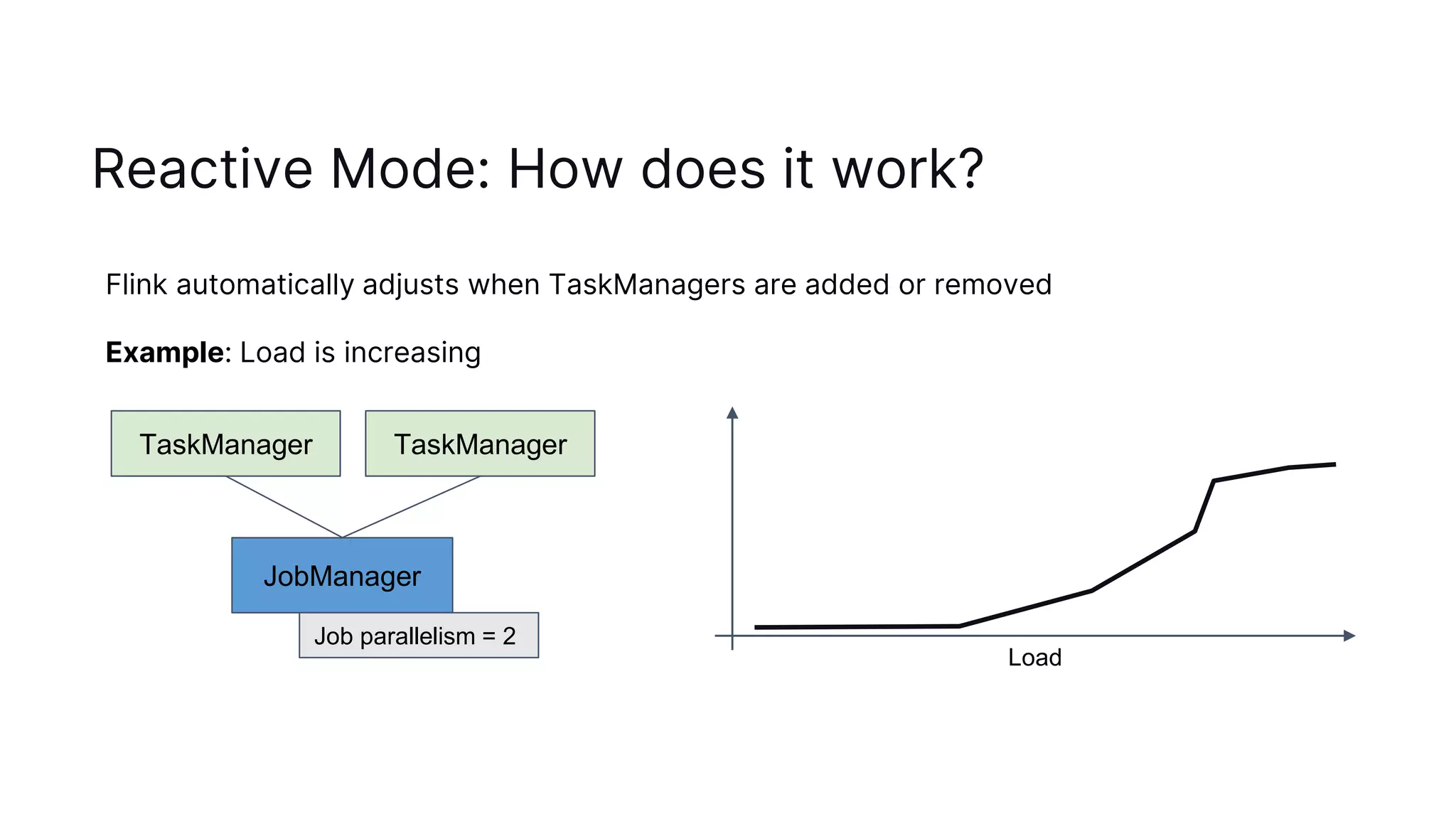
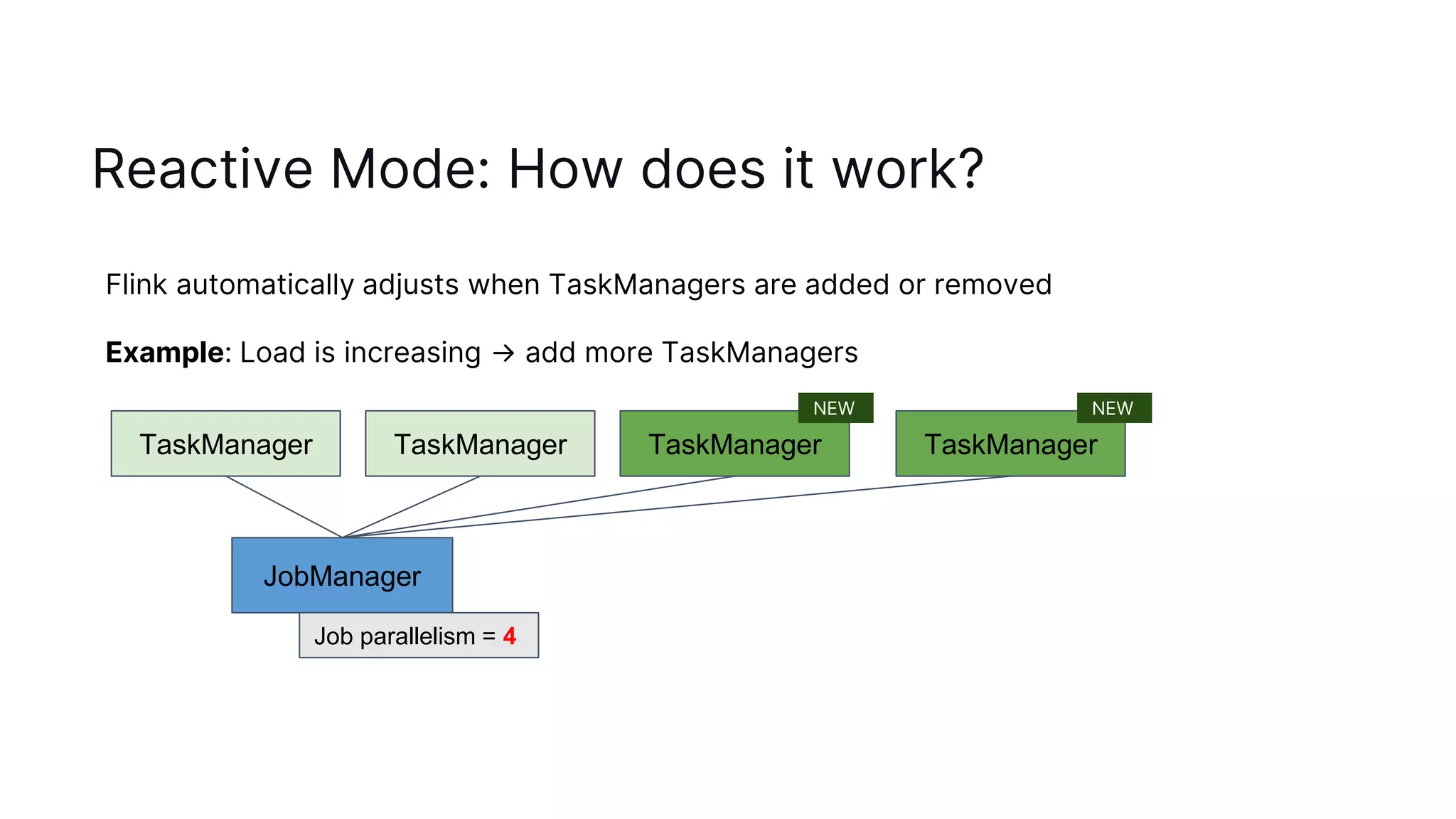

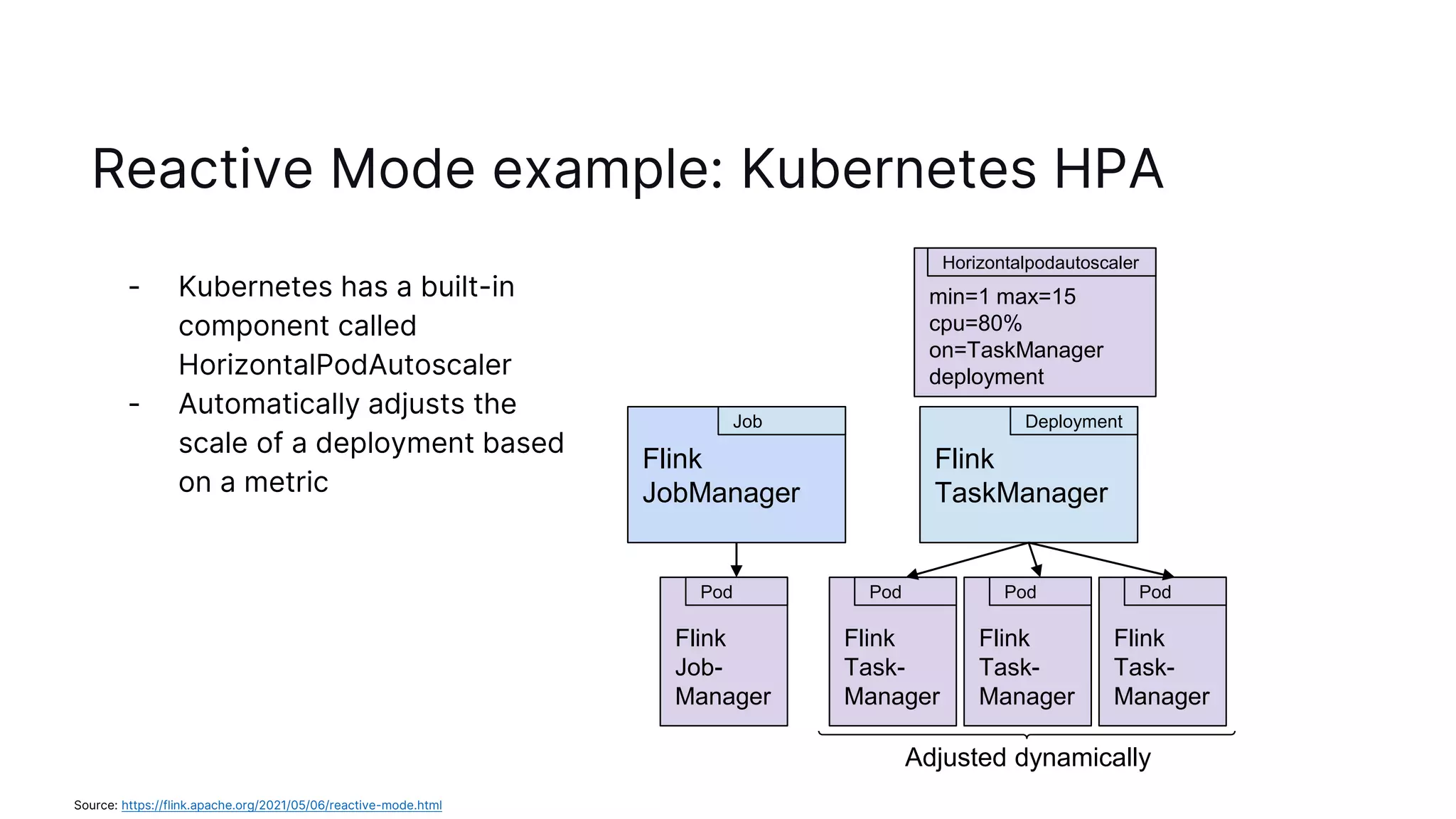


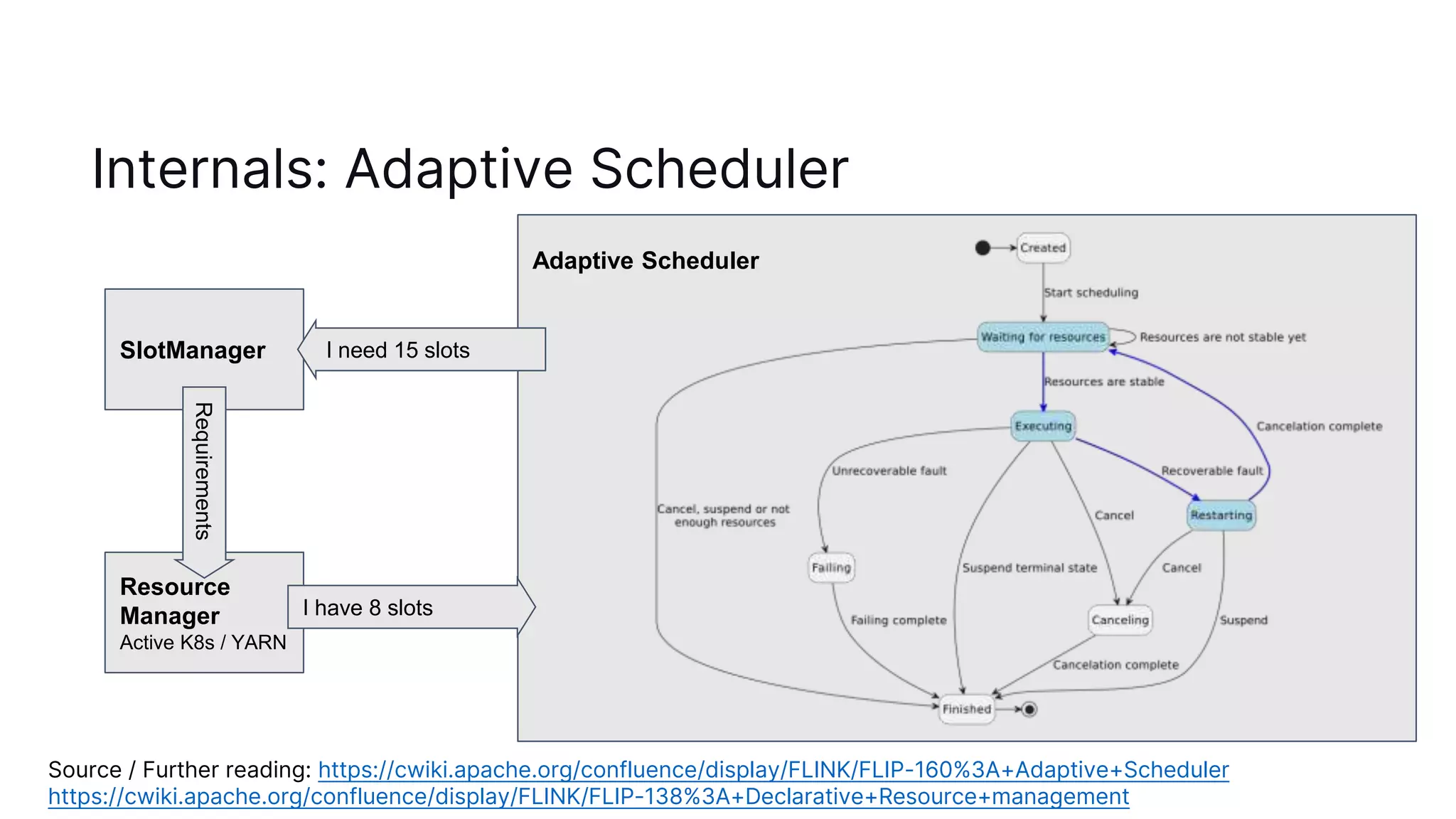
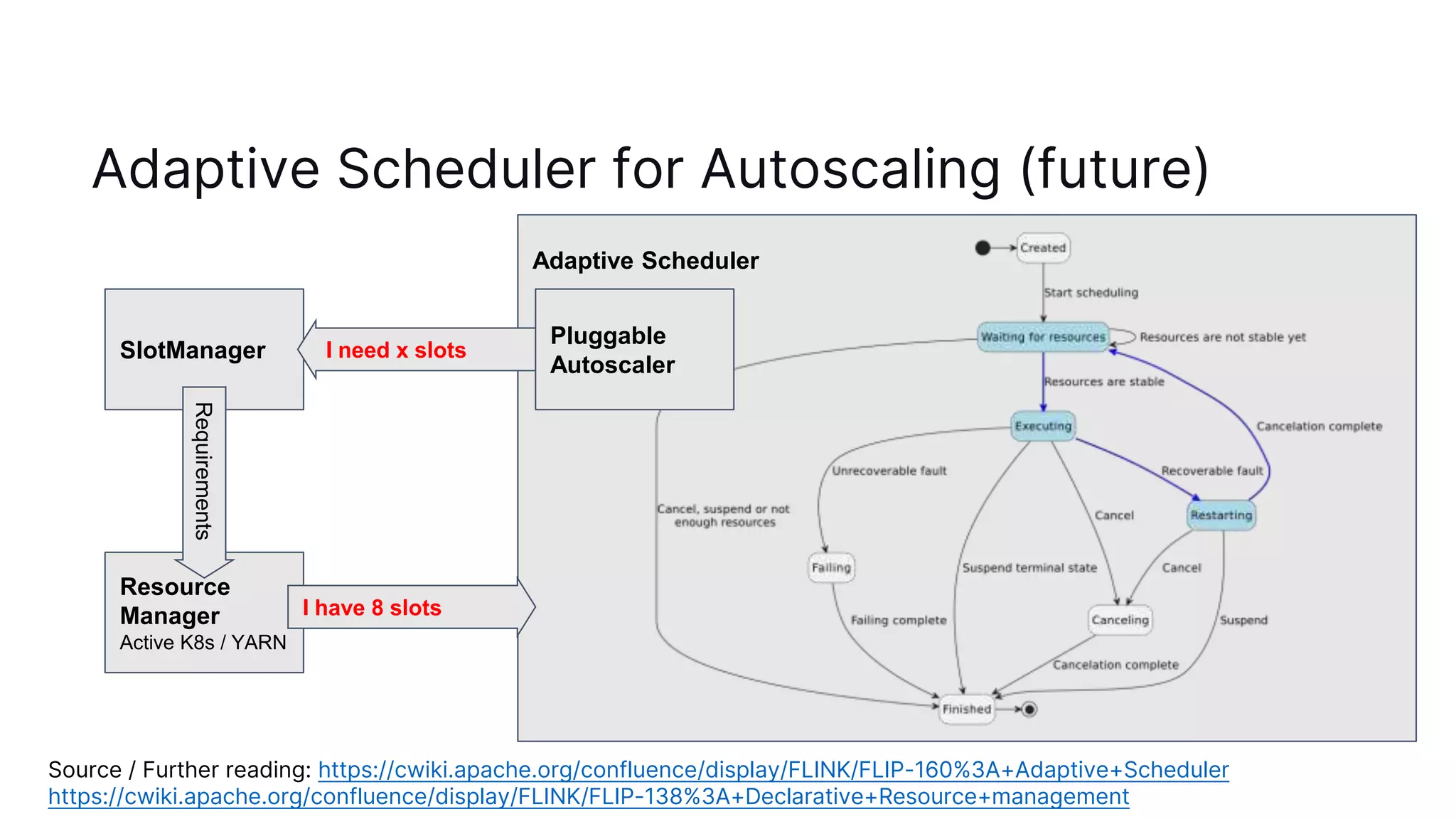





The document discusses autoscaling in Apache Flink, emphasizing the evolution of its capabilities from the introduction of rescalable state in Flink 1.2 to the deployment of reactive mode in Flink 1.15. Reactive mode allows Flink to automatically adjust the number of task managers based on workload, requiring external tools for management and scaling metrics. It outlines the pros and cons of different deployment strategies and introduces the adaptive scheduler for improving scaling decisions.



































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















