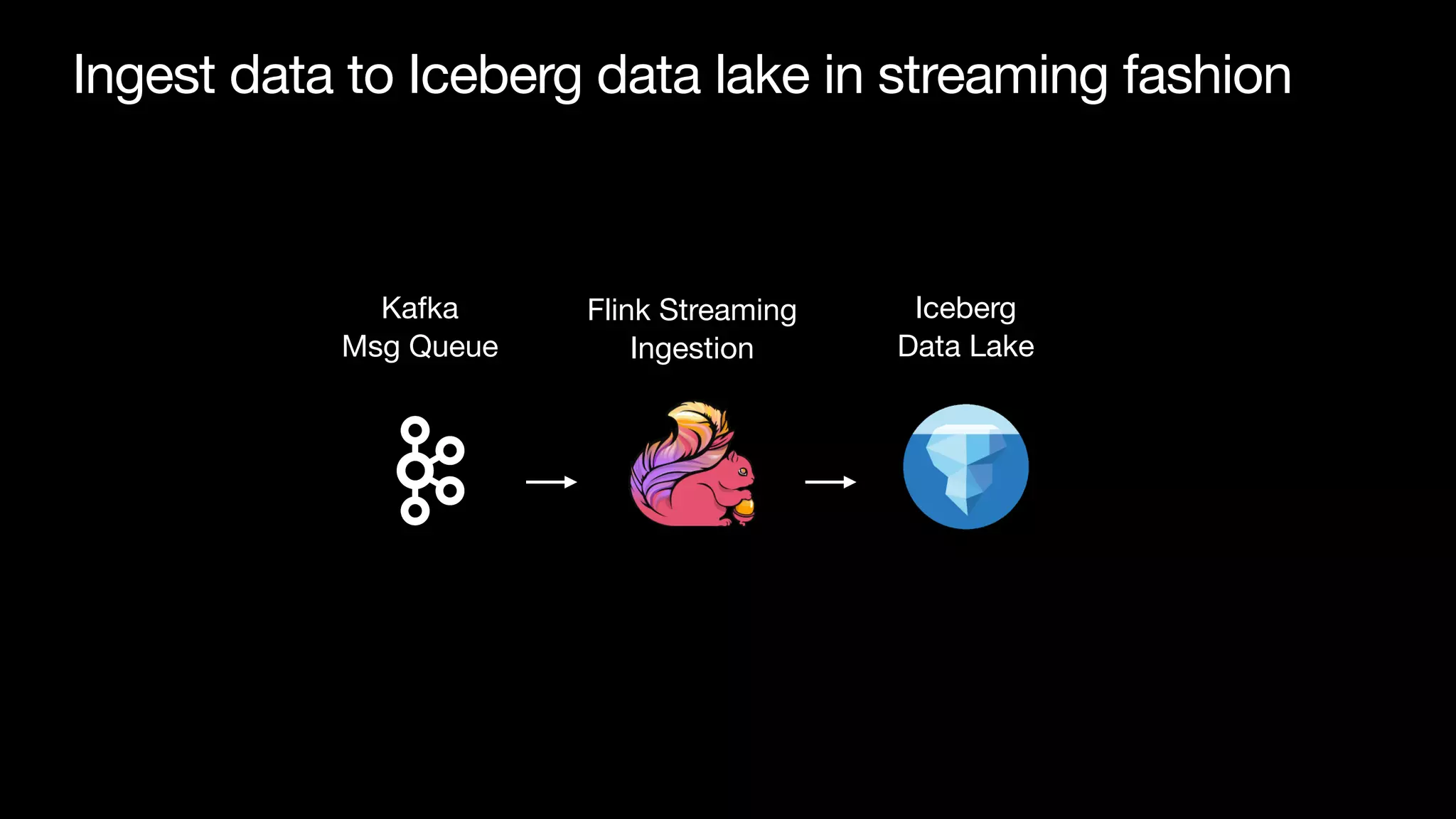
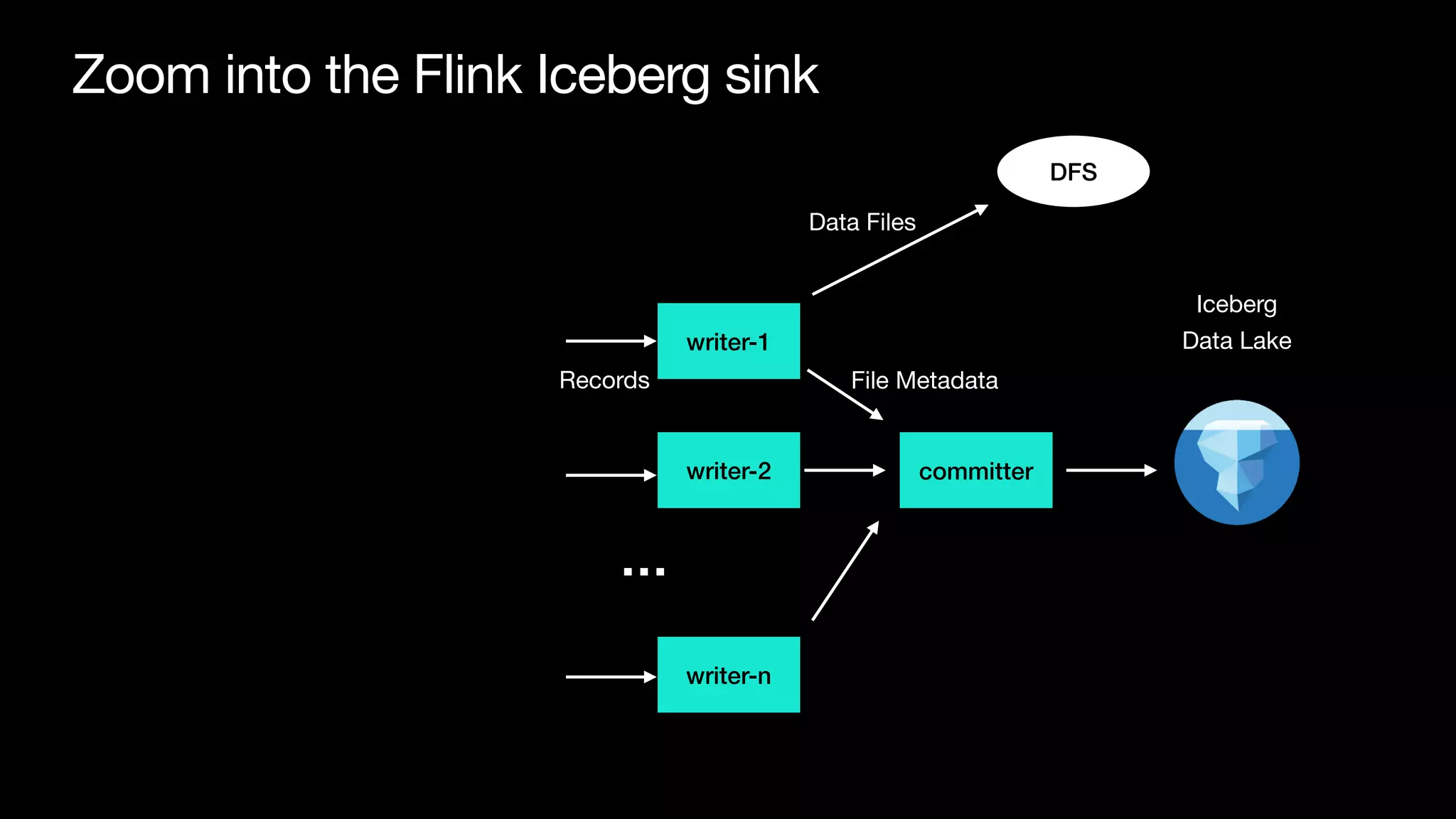
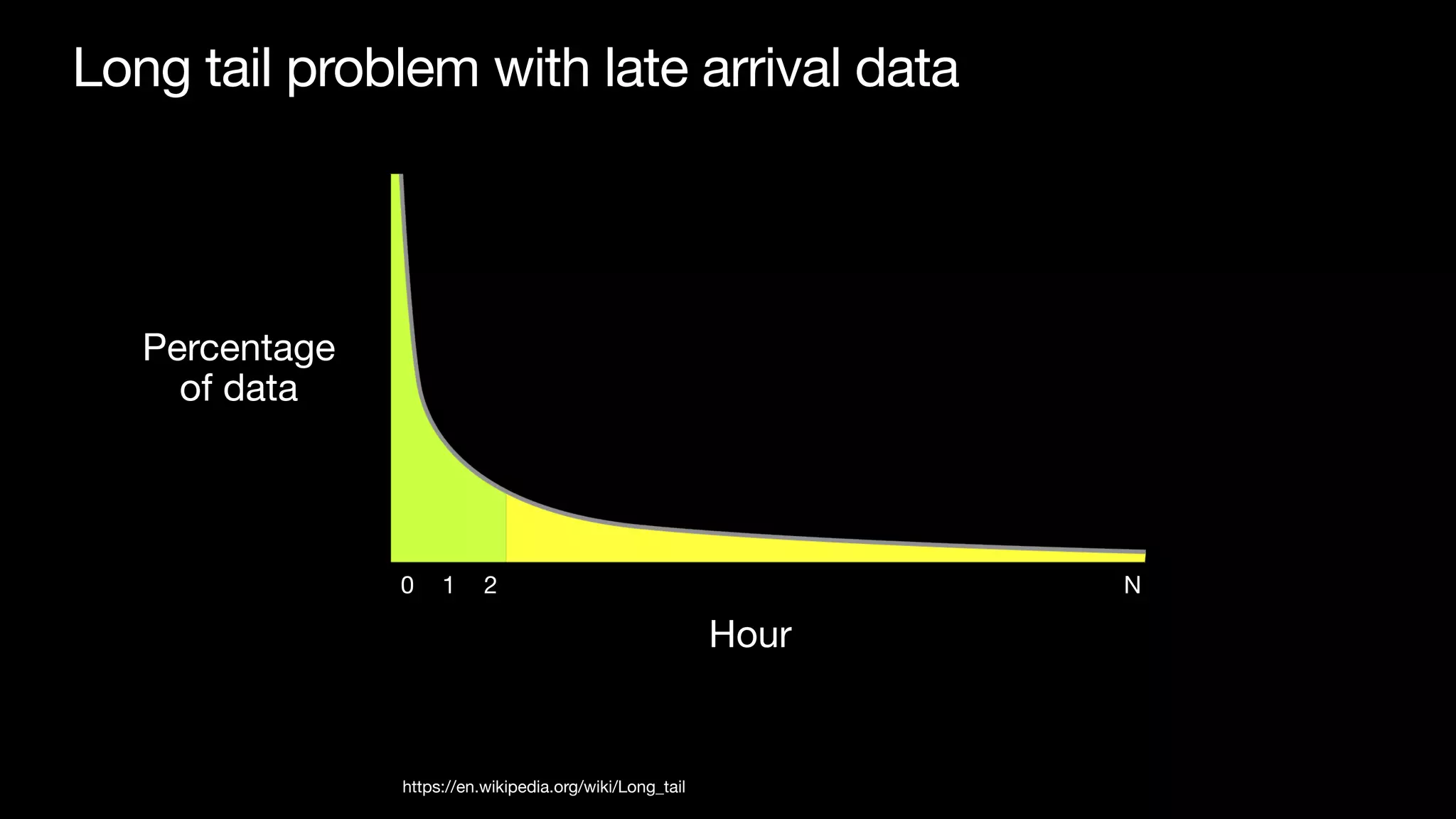
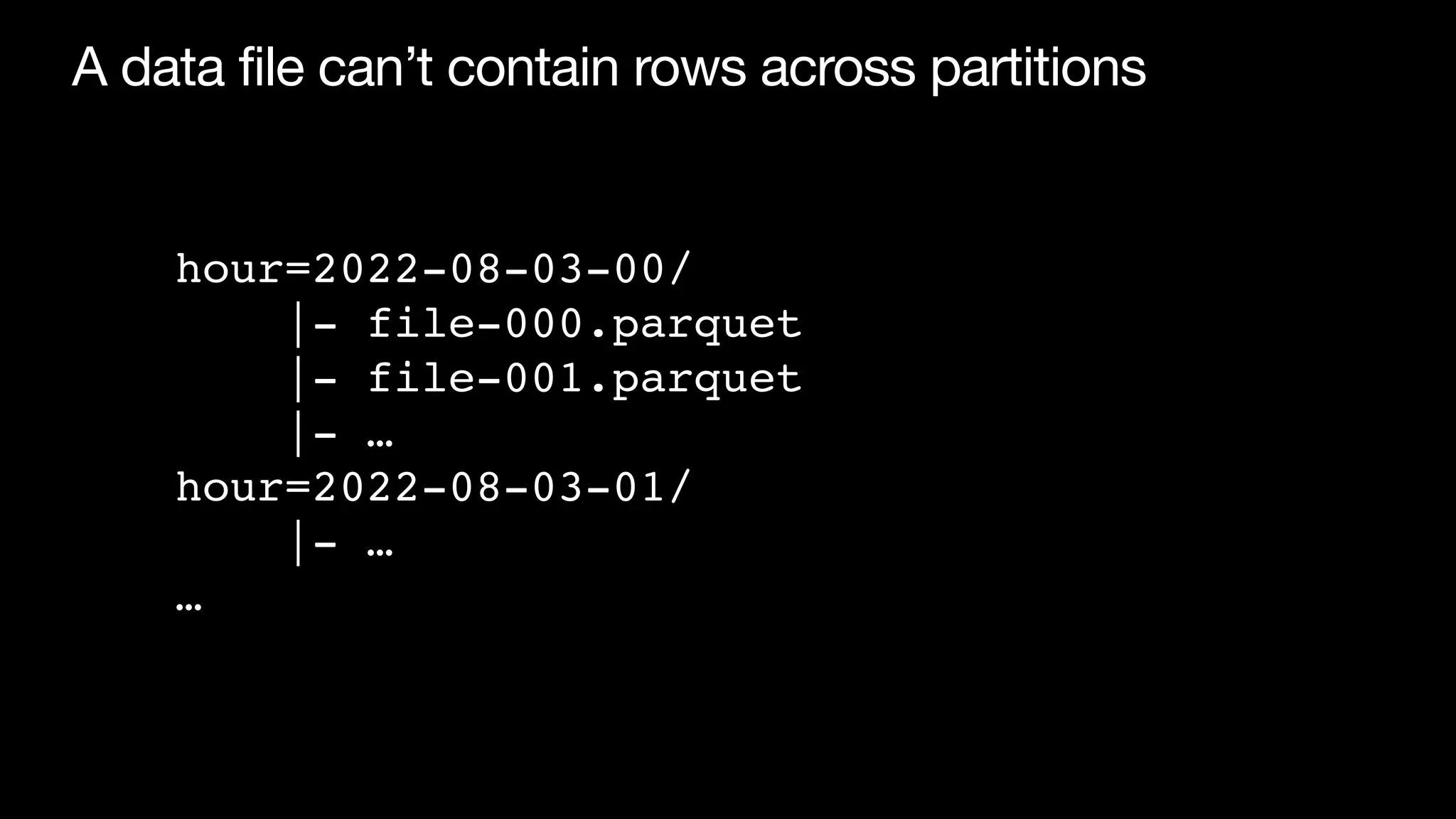
Download as PDF, PPTX




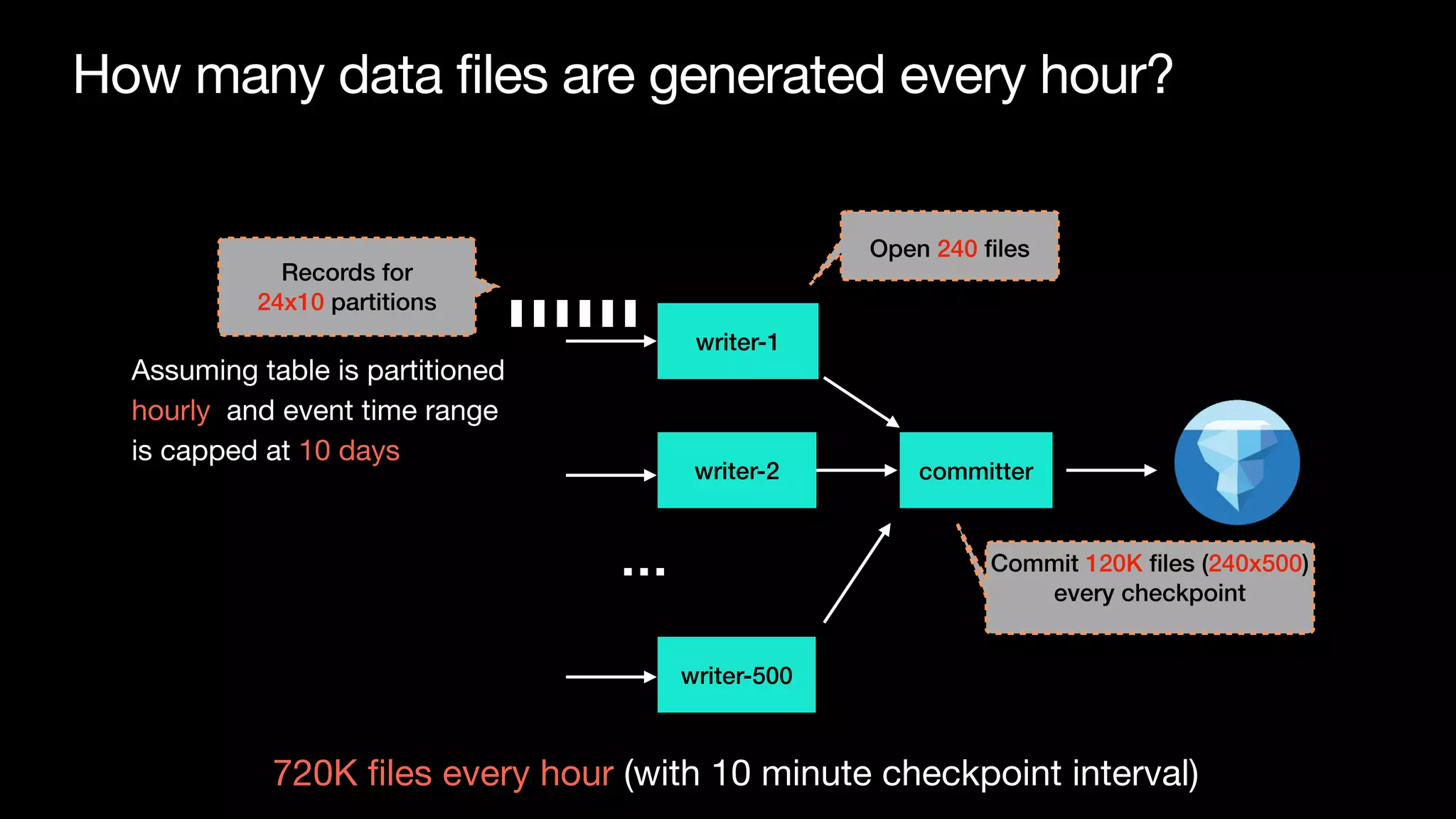


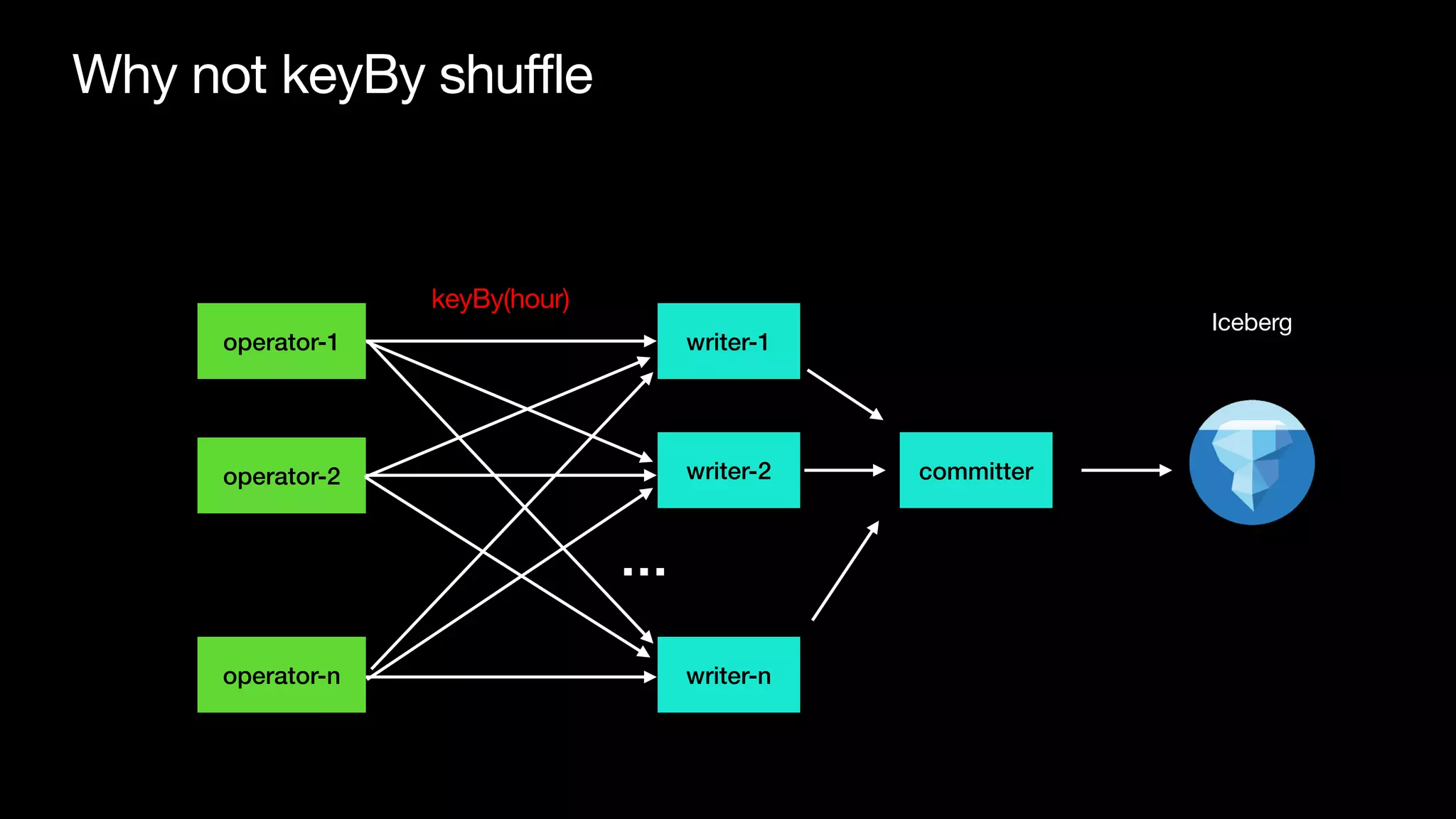
![There are two problems
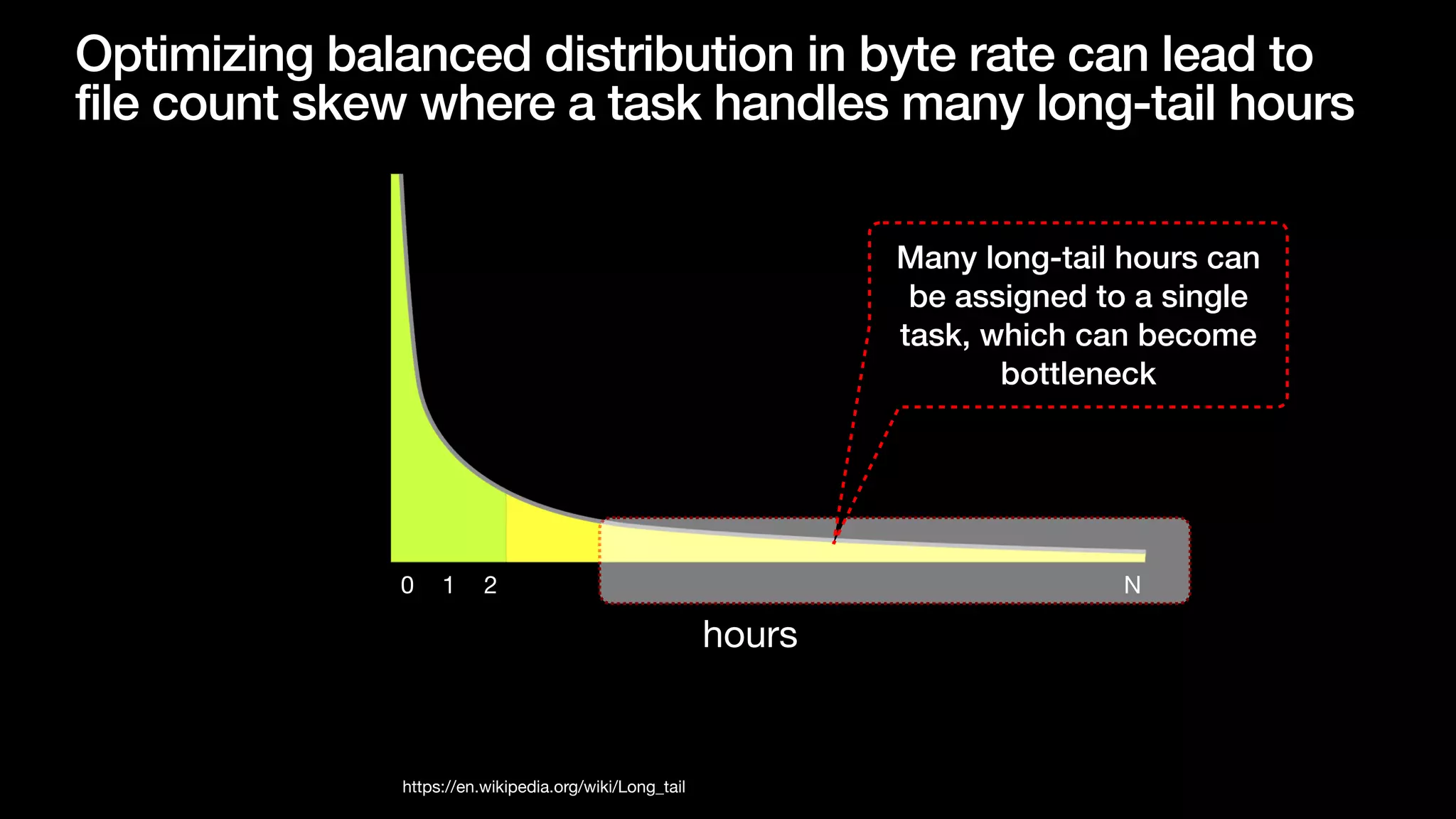
• Tra
ffi
c are not evenly distributed across event hours
• keyBy for low cardinality column won’t be balanced [1]
[1] https://github.com/apache/iceberg/pull/4228](https://image.slidesharecdn.com/215pmtamethesmallfilesproblemandoptimizedatalayoutforstreamingingestiontoicebergswu-220809112100-d909fe3b/75/Tame-the-small-files-problem-and-optimize-data-layout-for-streaming-ingestion-to-Iceberg-13-2048.jpg)


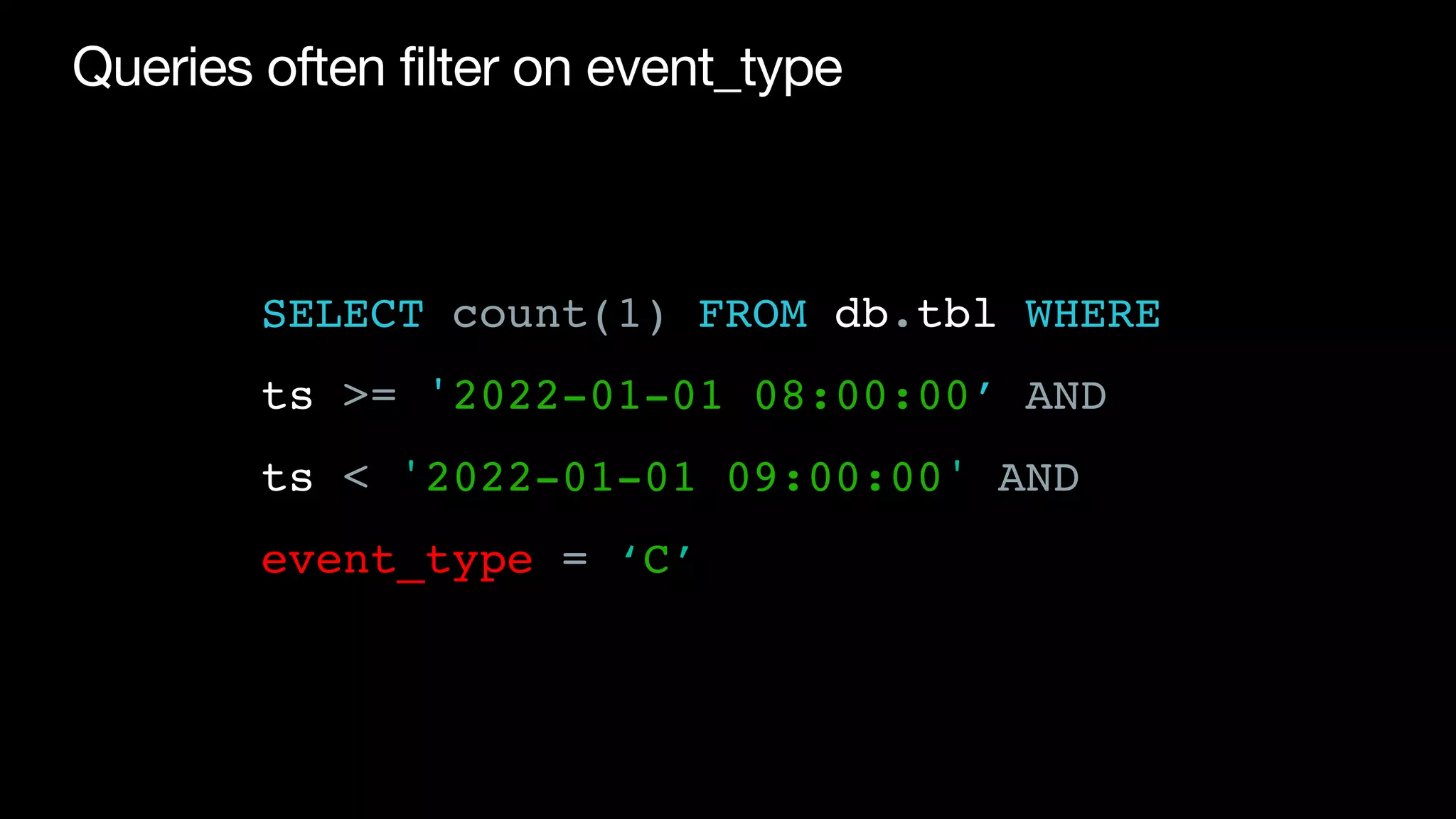
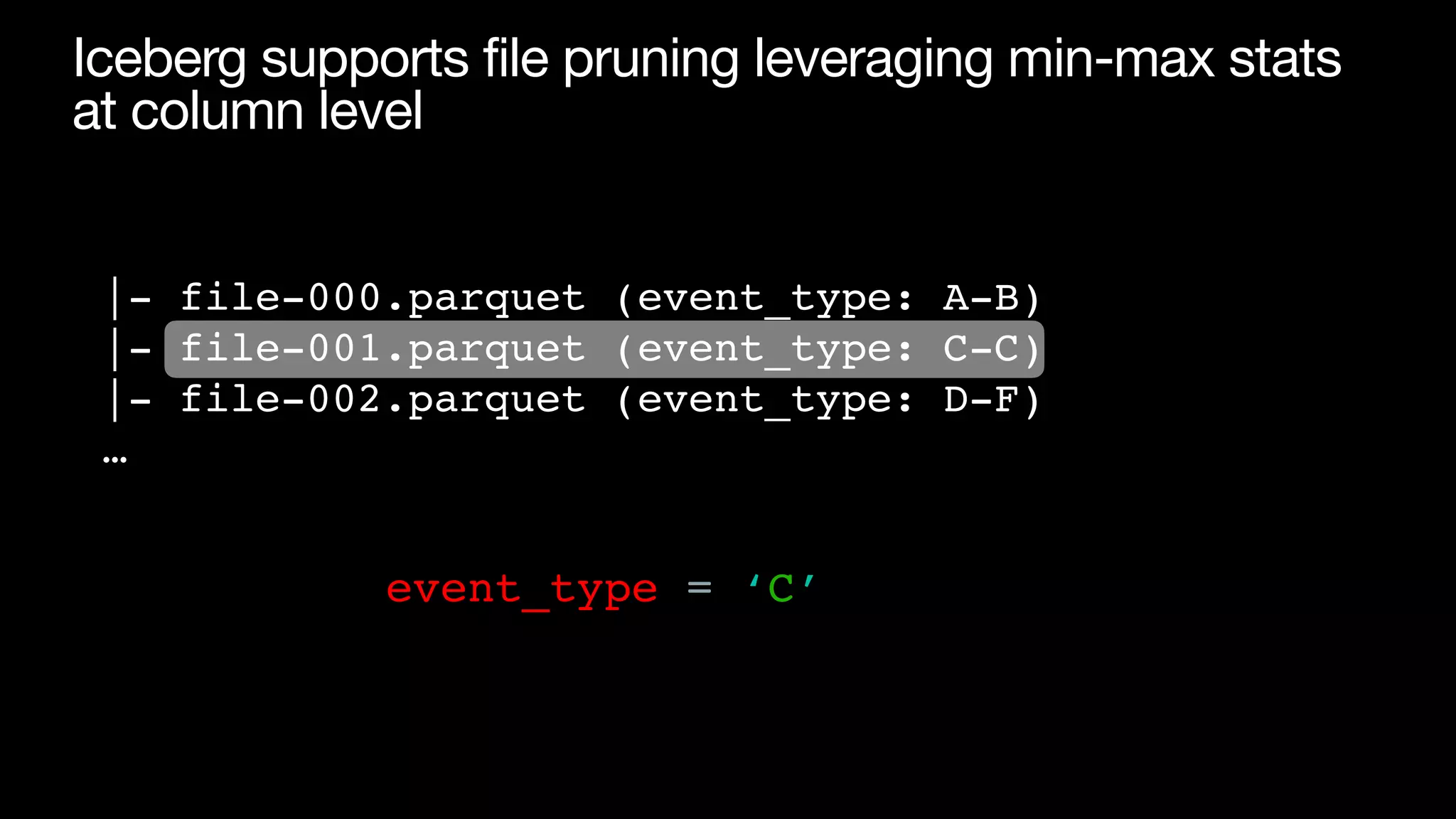

![Making event_type a partition column can lead to
explosion of number of partitions
• Before: 8.8K partitions (365 days x 24 hours) [1]
• After: 4.4M partitions (365 days x 24 hours x 500 event_types) [2]
• Can stress metadata system and lead to small
fi
les
[1] Assuming 12 months retention
[2] Assuming 500 event types](https://image.slidesharecdn.com/215pmtamethesmallfilesproblemandoptimizedatalayoutforstreamingingestiontoicebergswu-220809112100-d909fe3b/75/Tame-the-small-files-problem-and-optimize-data-layout-for-streaming-ingestion-to-Iceberg-19-2048.jpg)
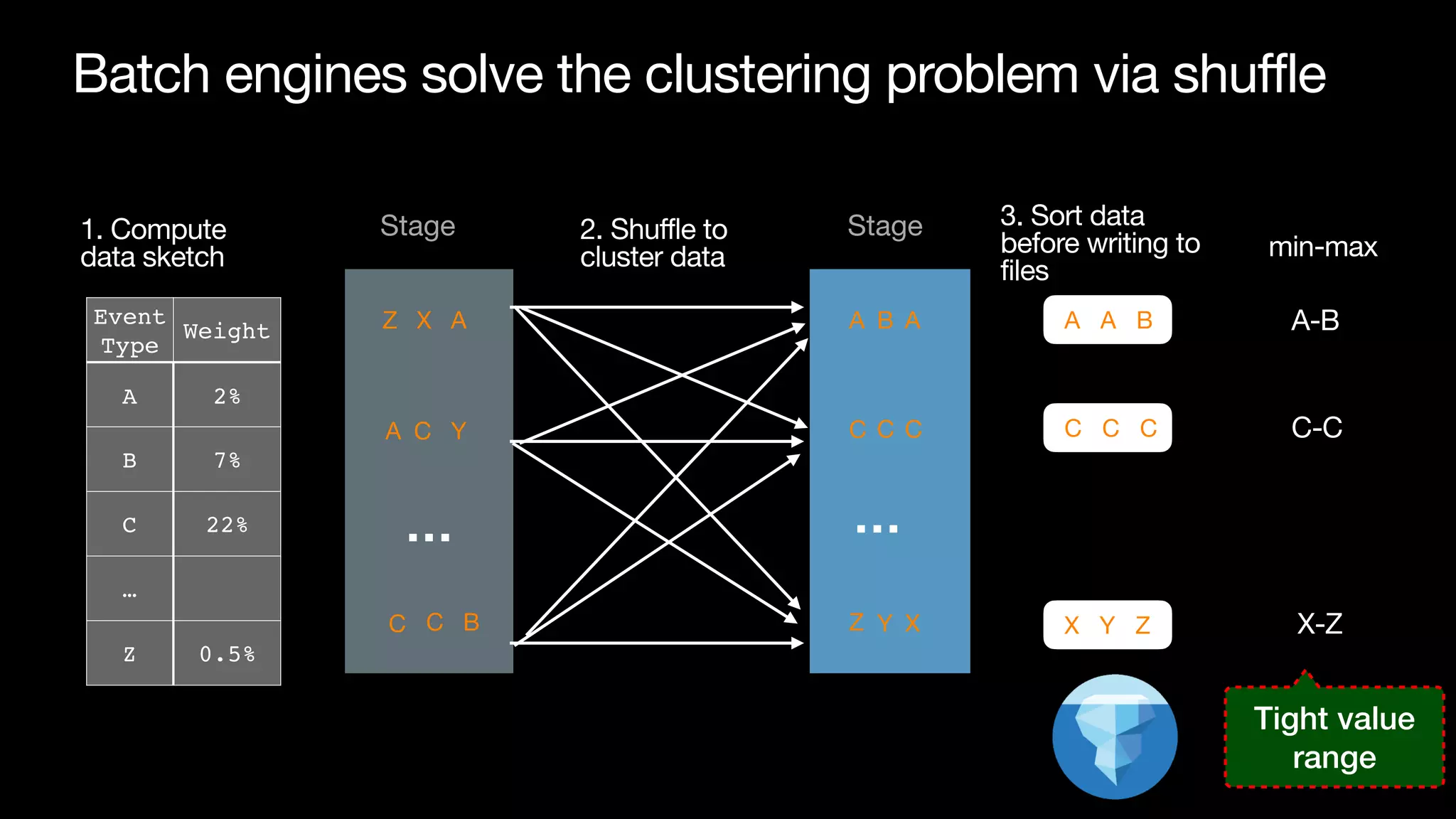


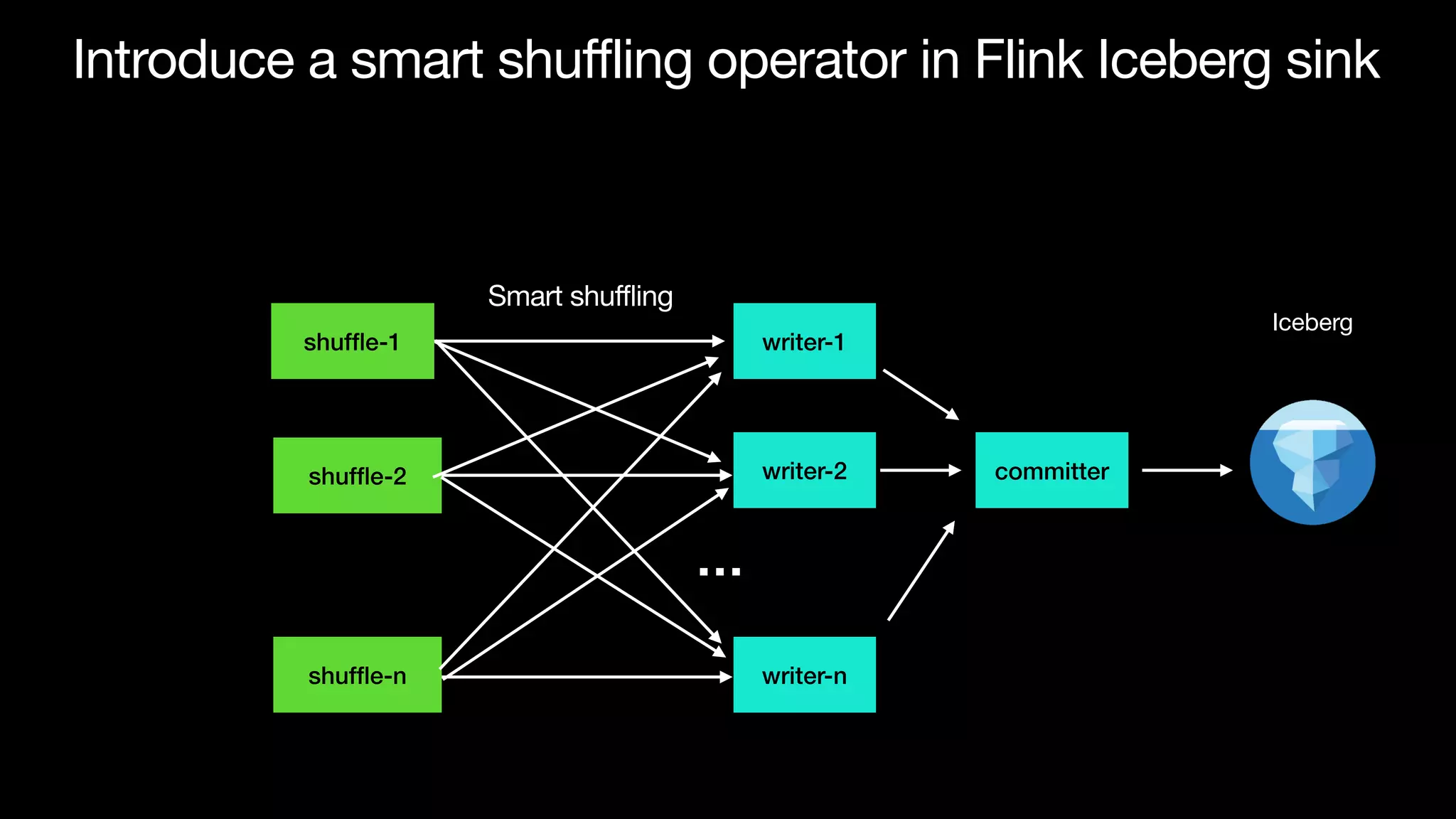
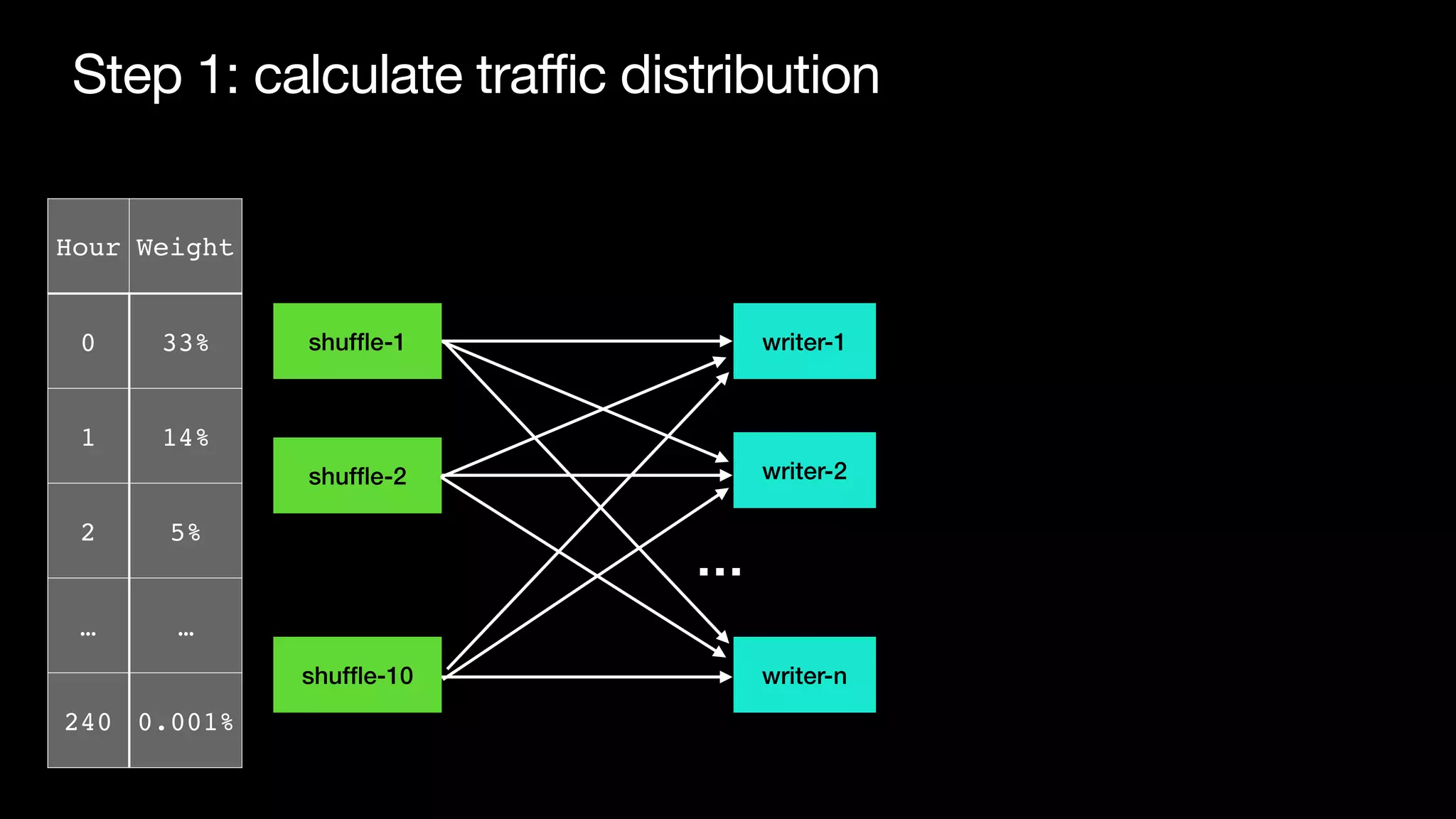
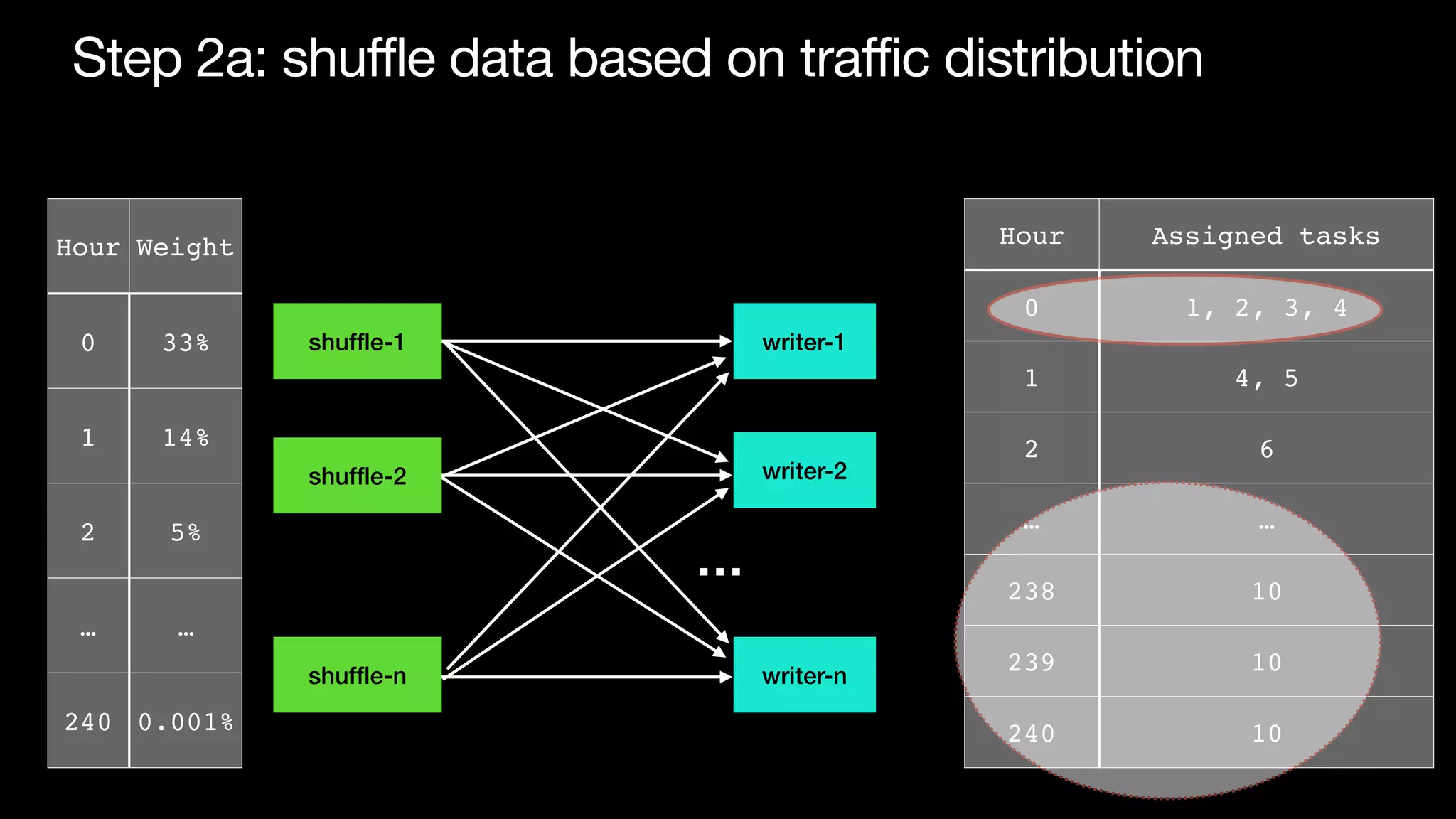
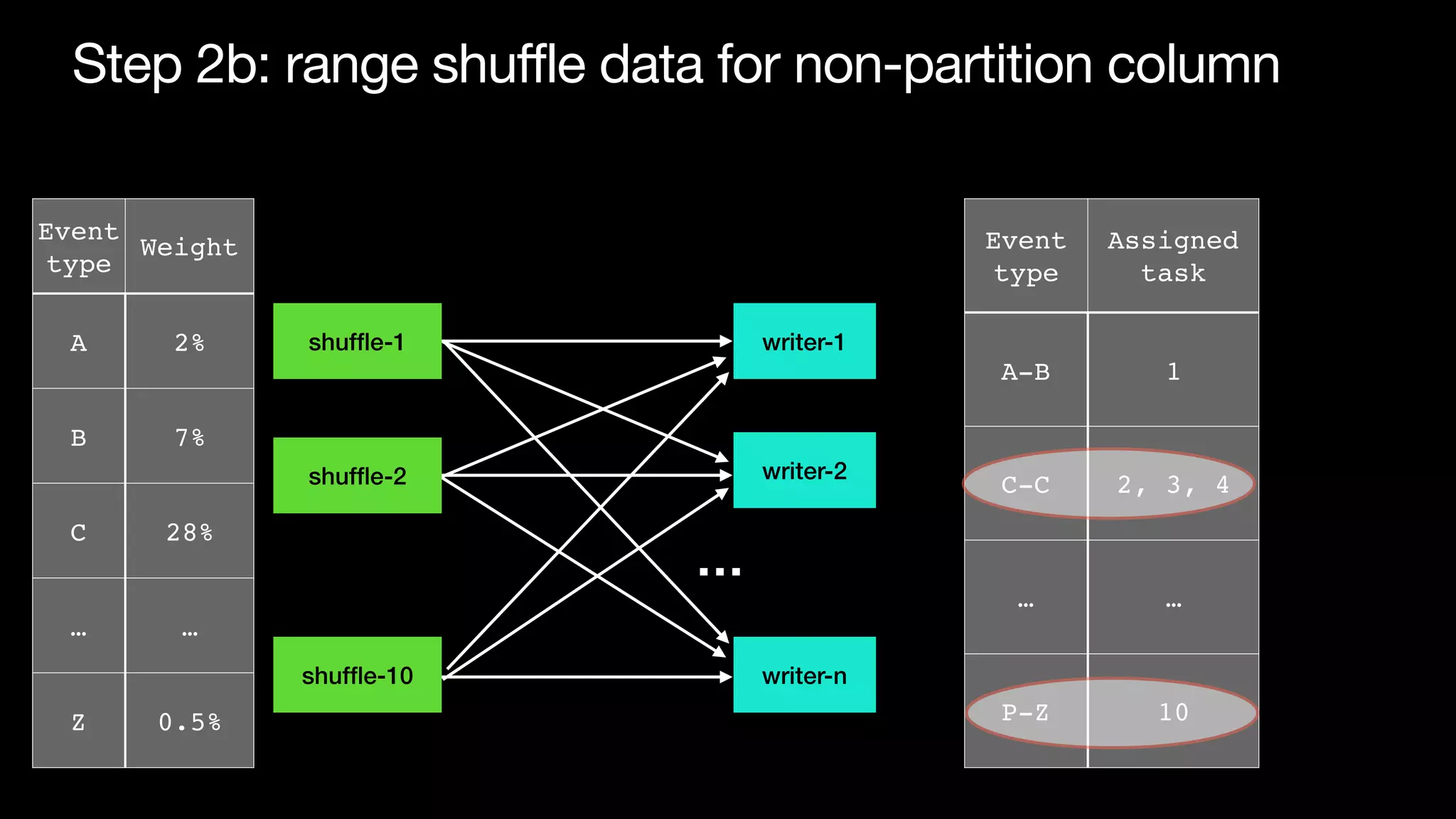
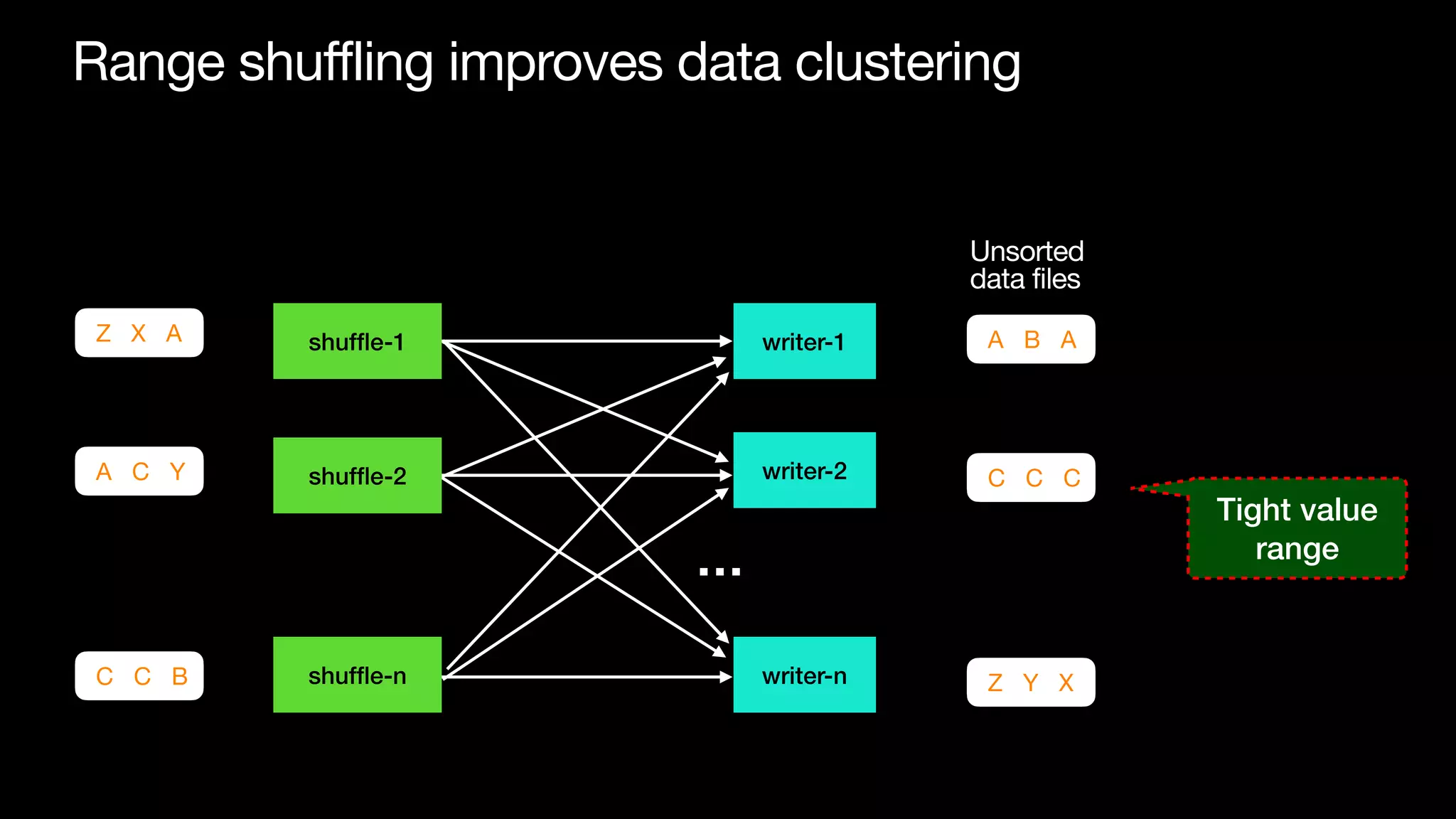



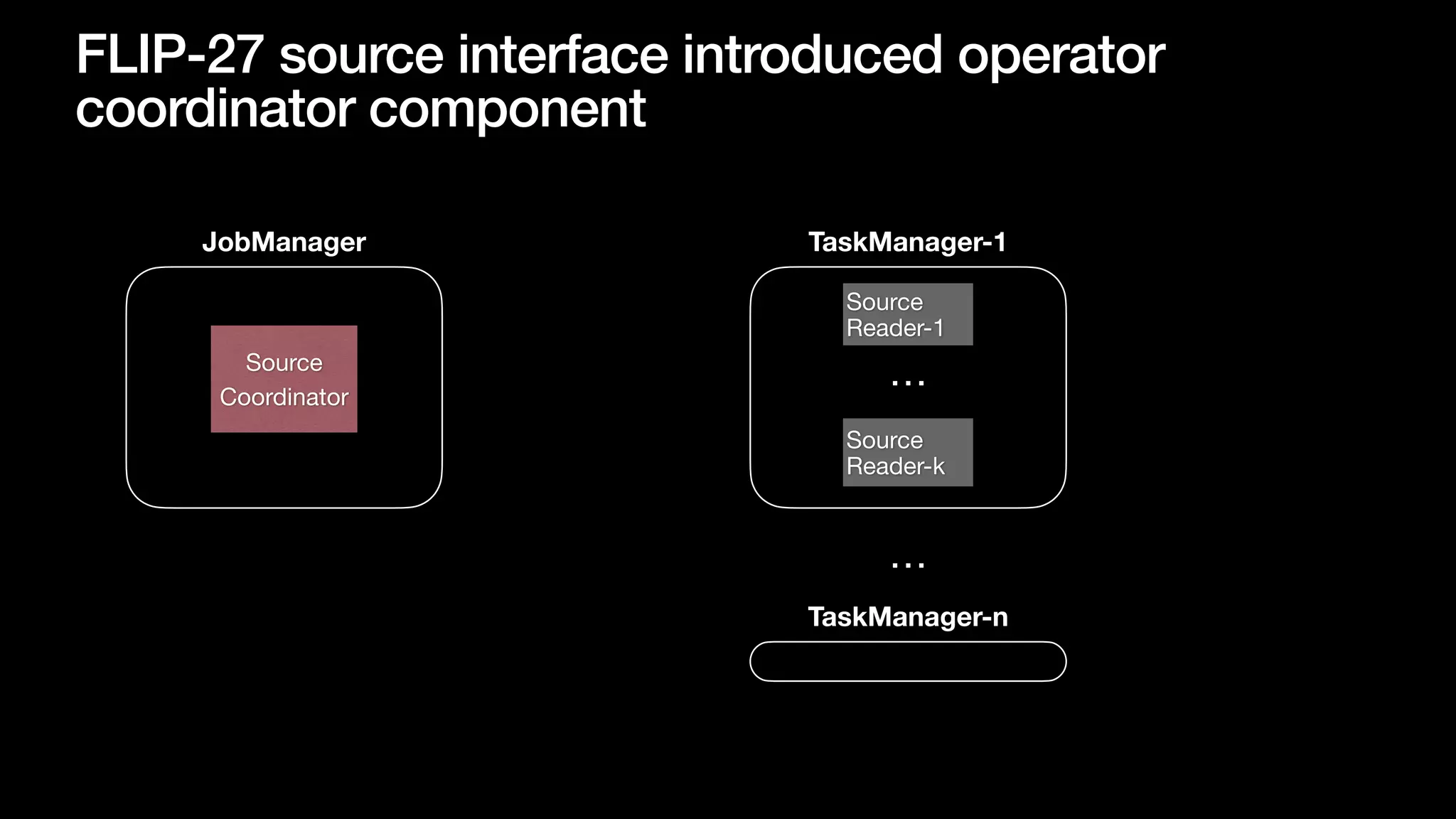
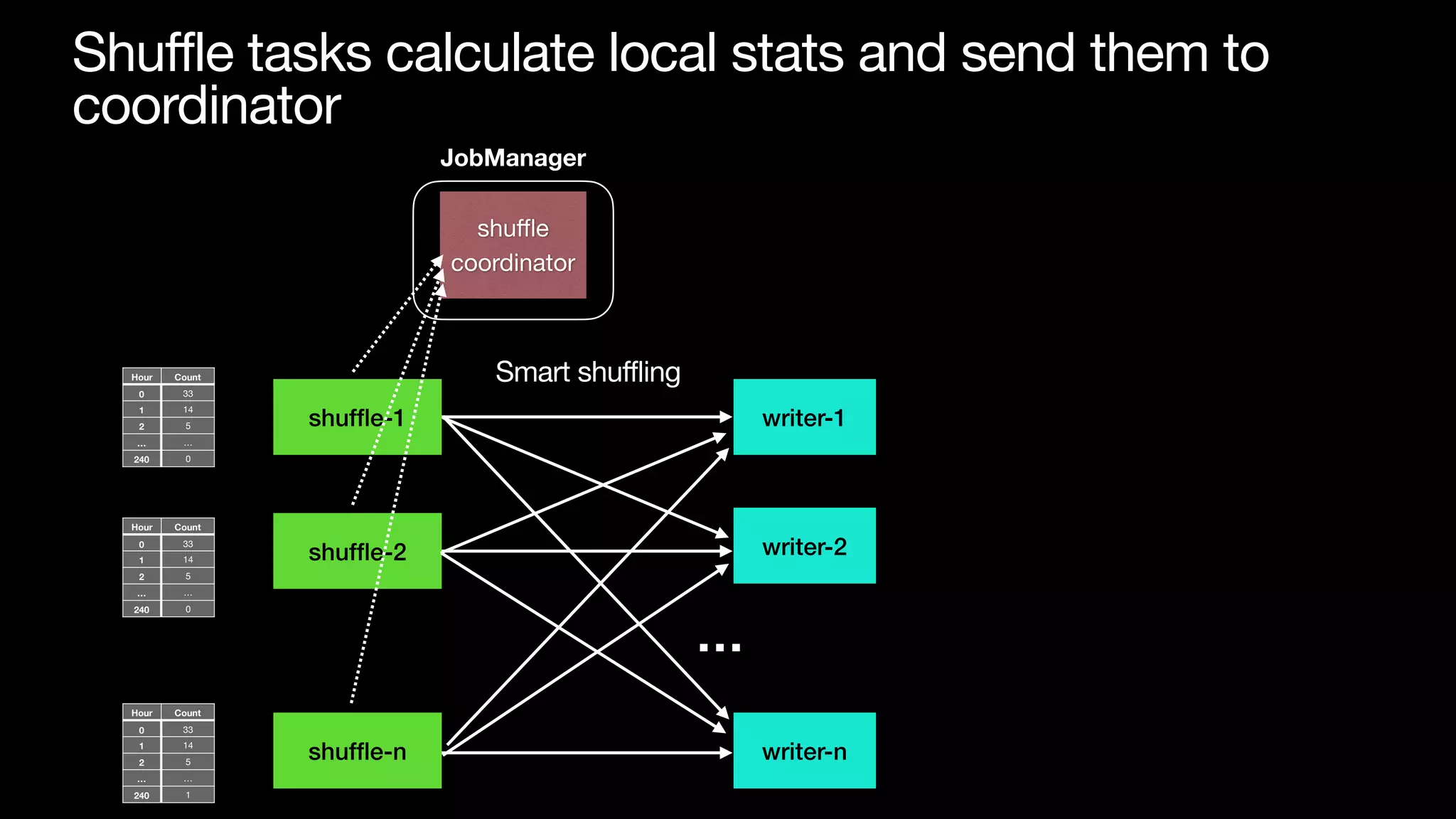
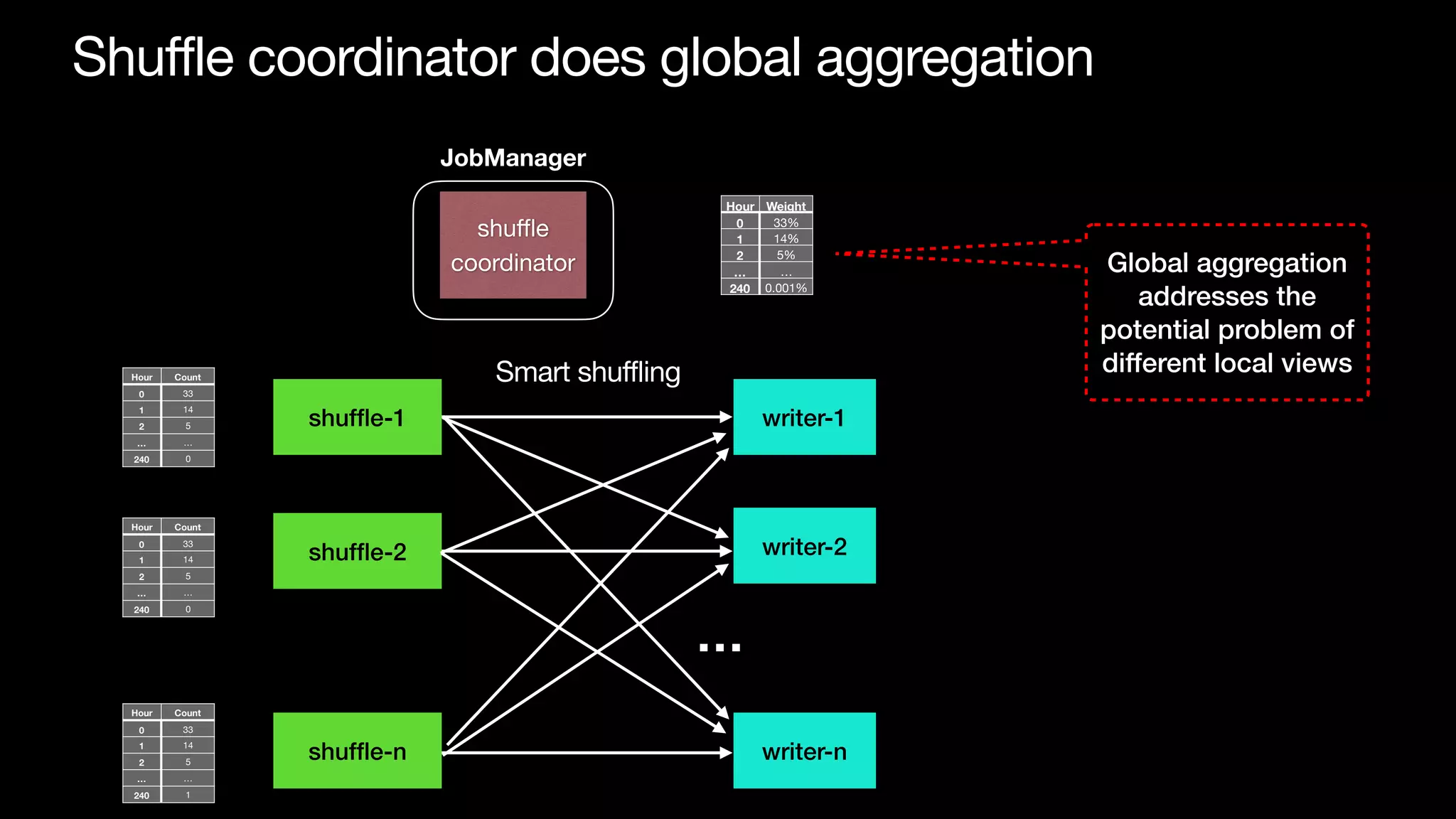
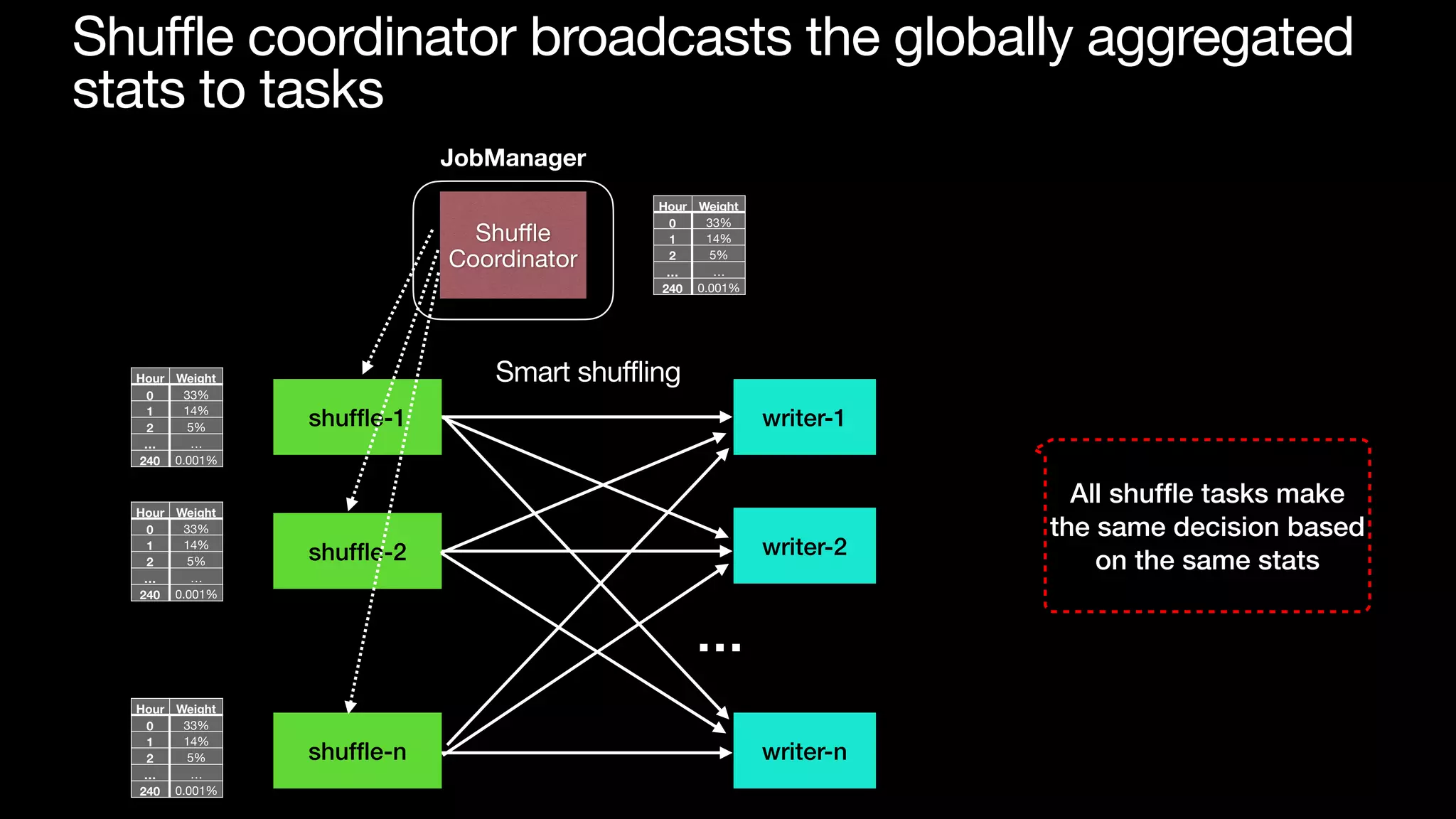






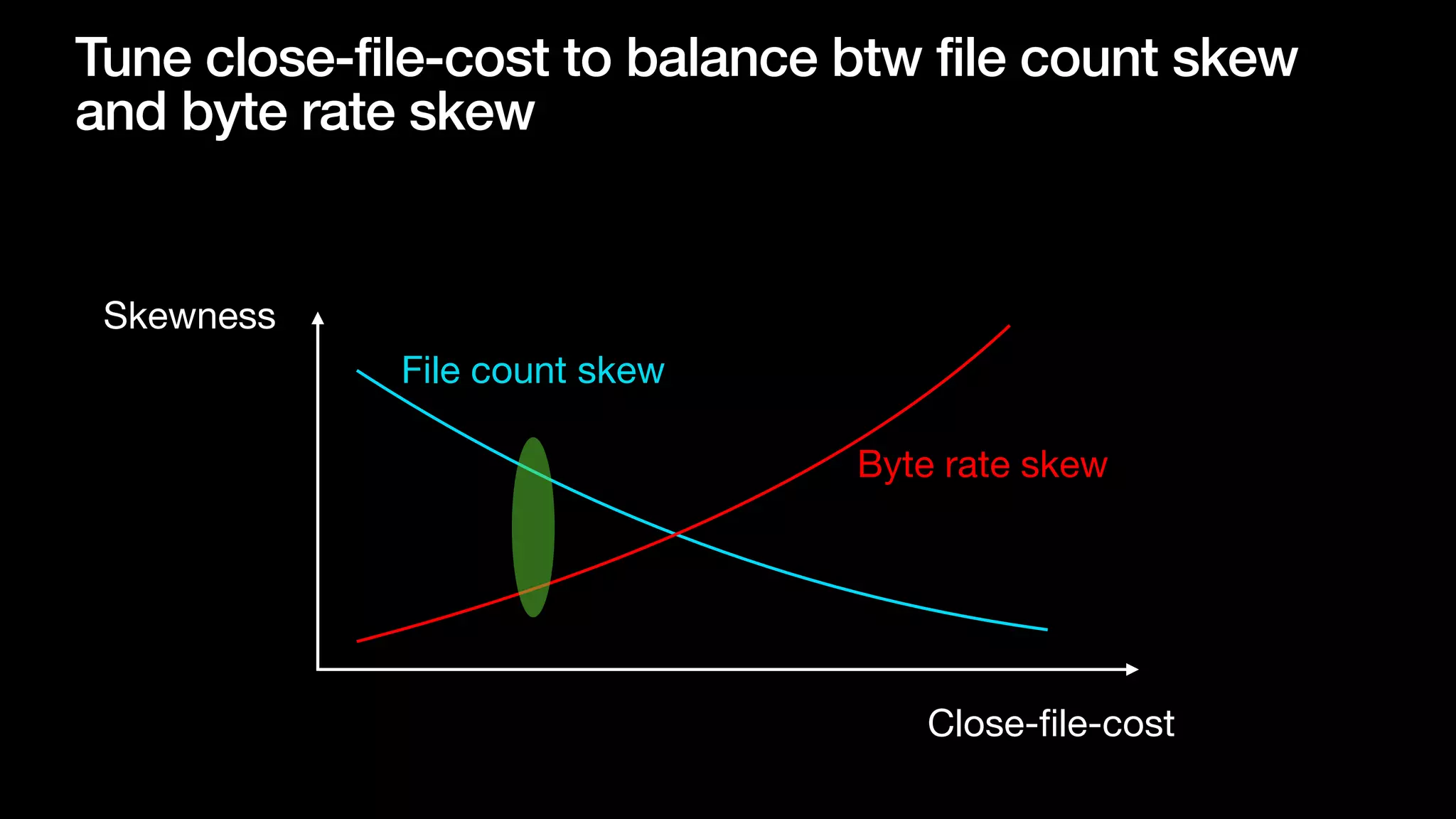
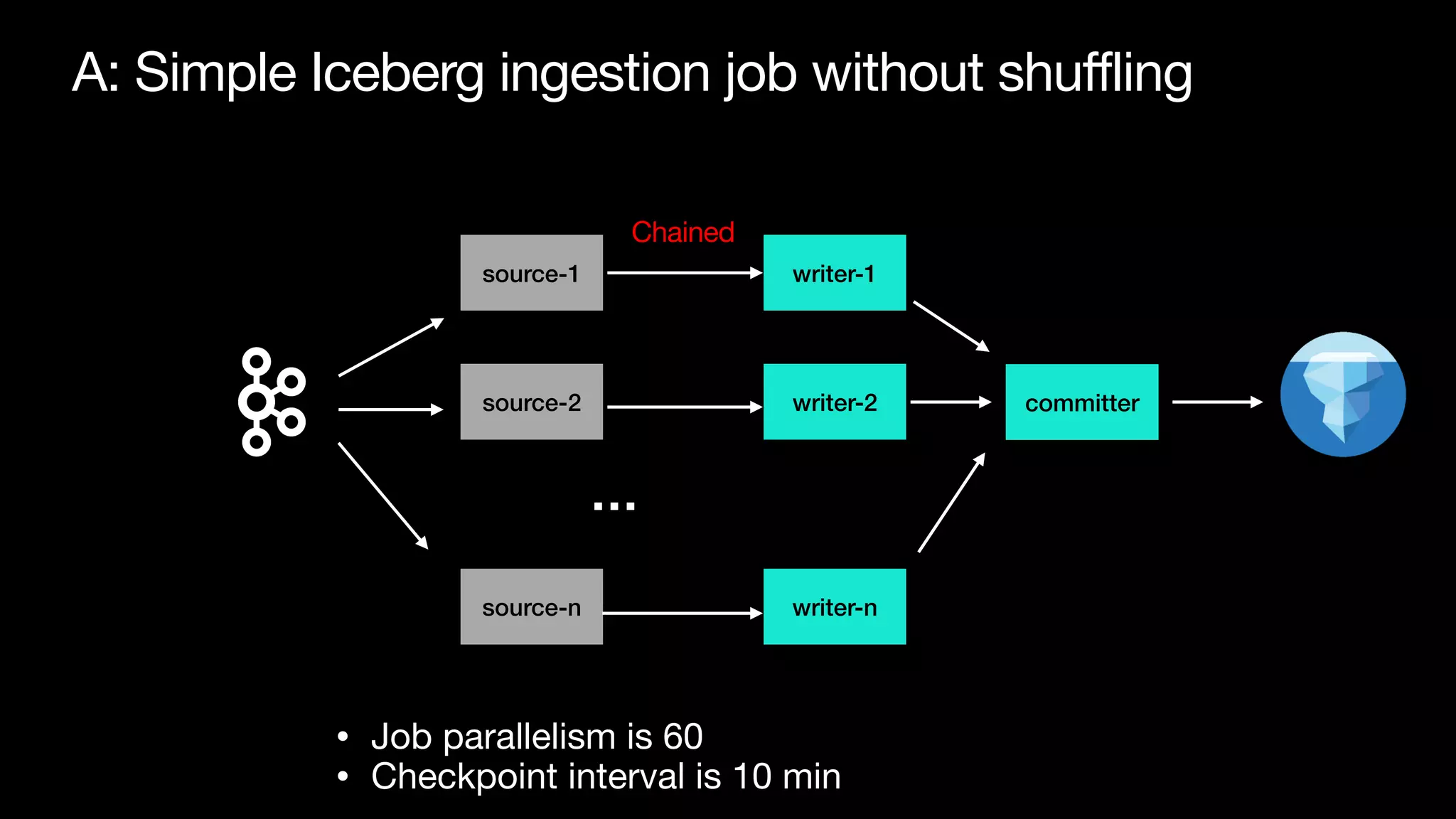
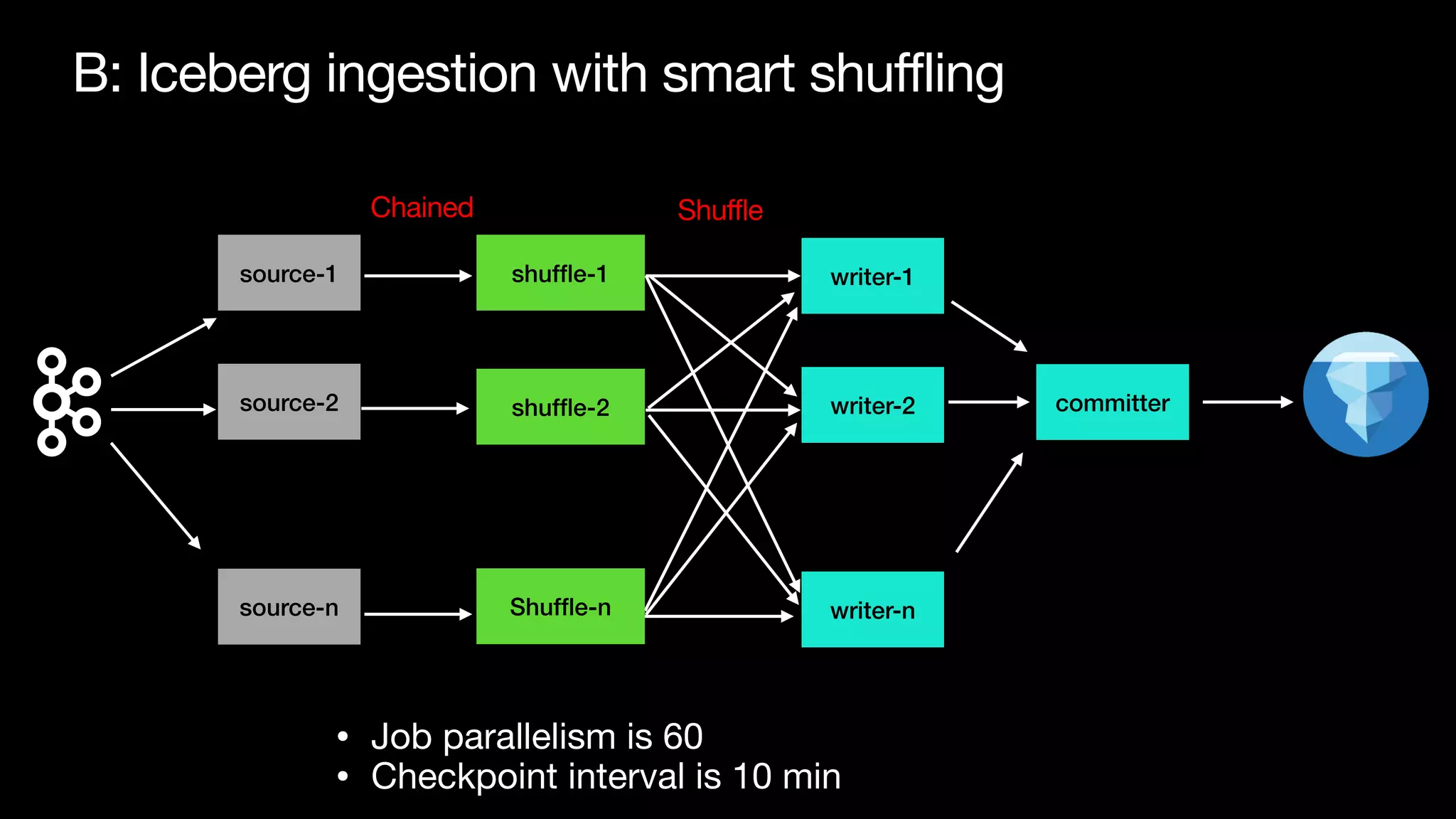


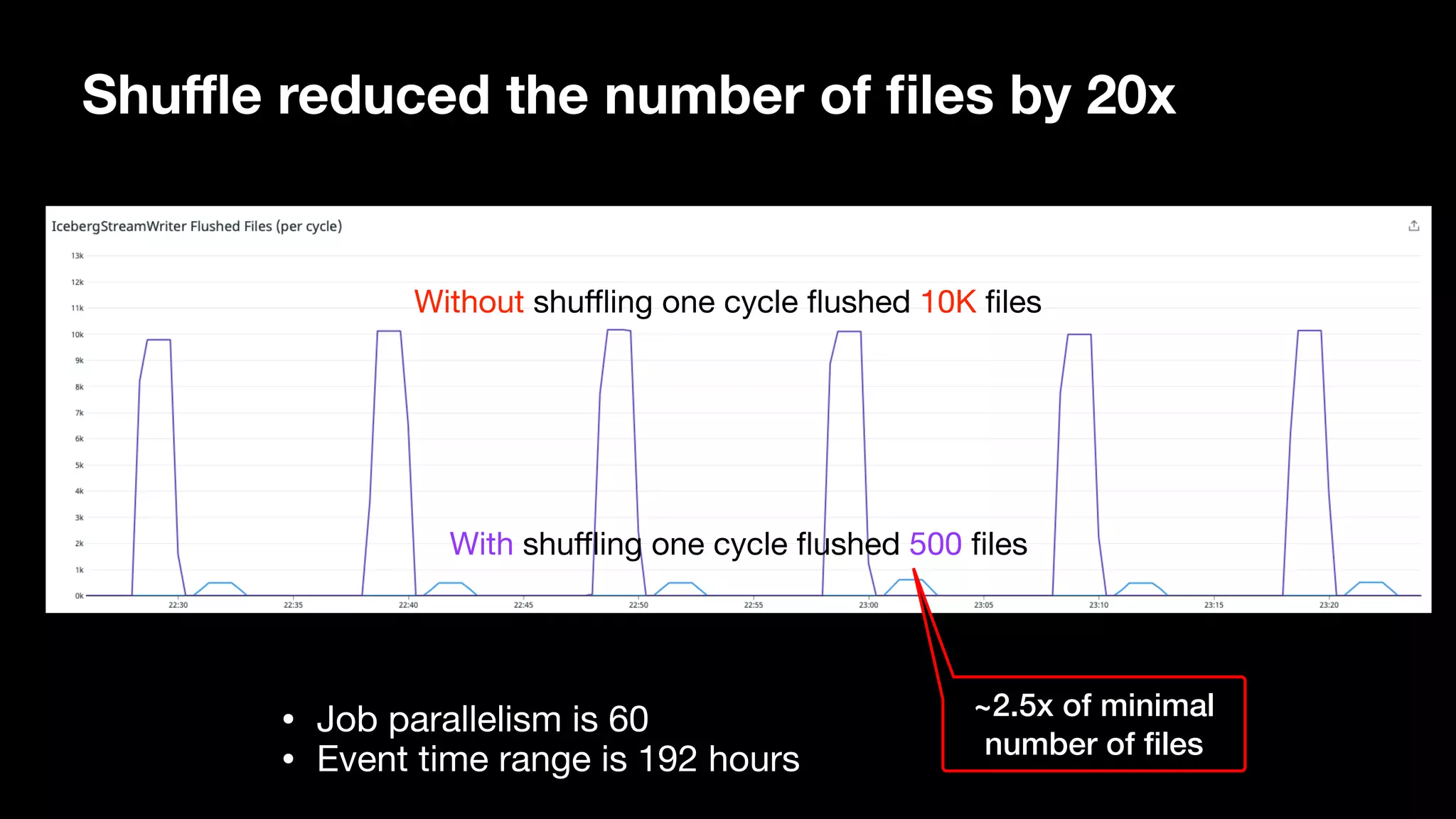
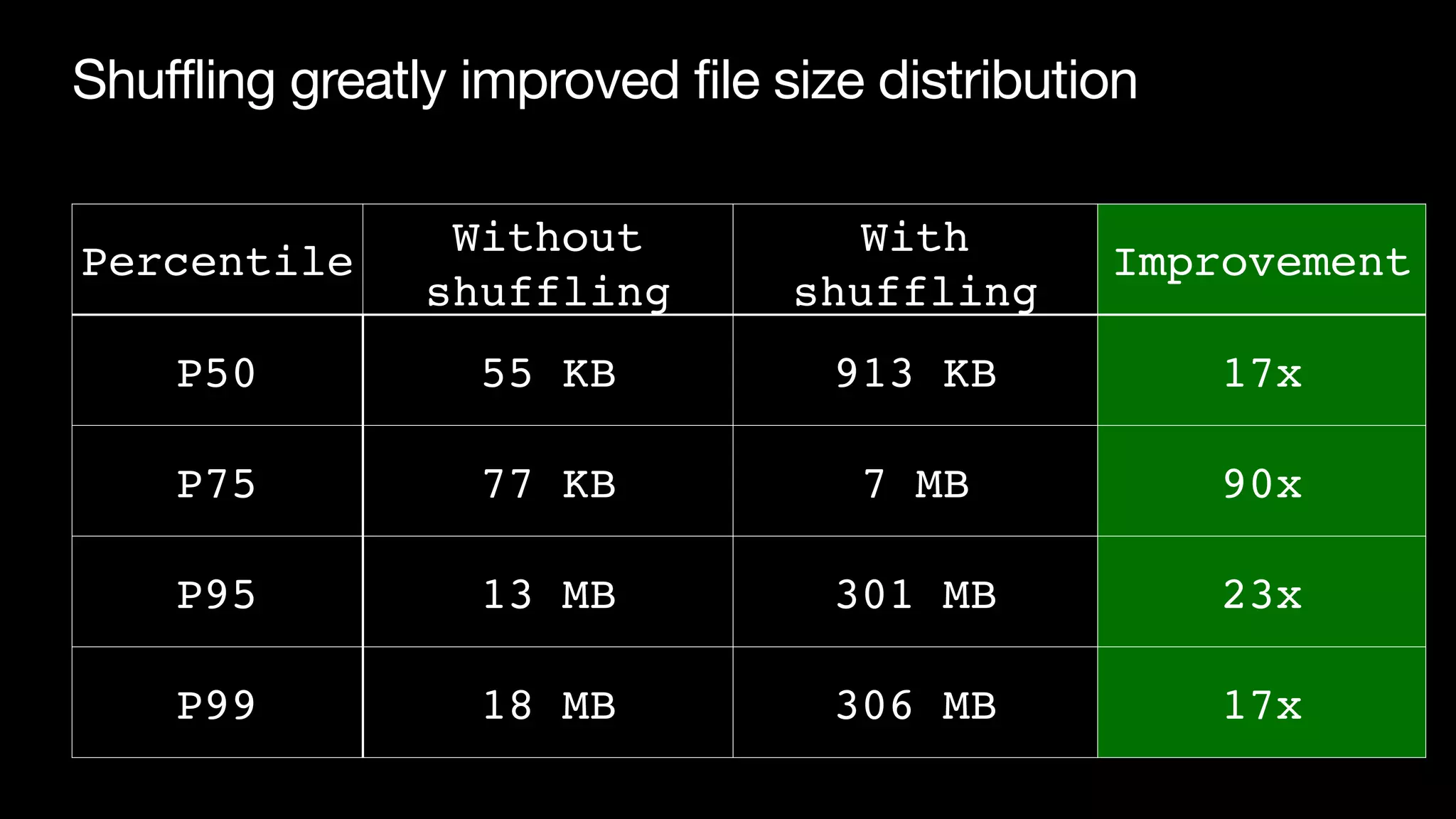
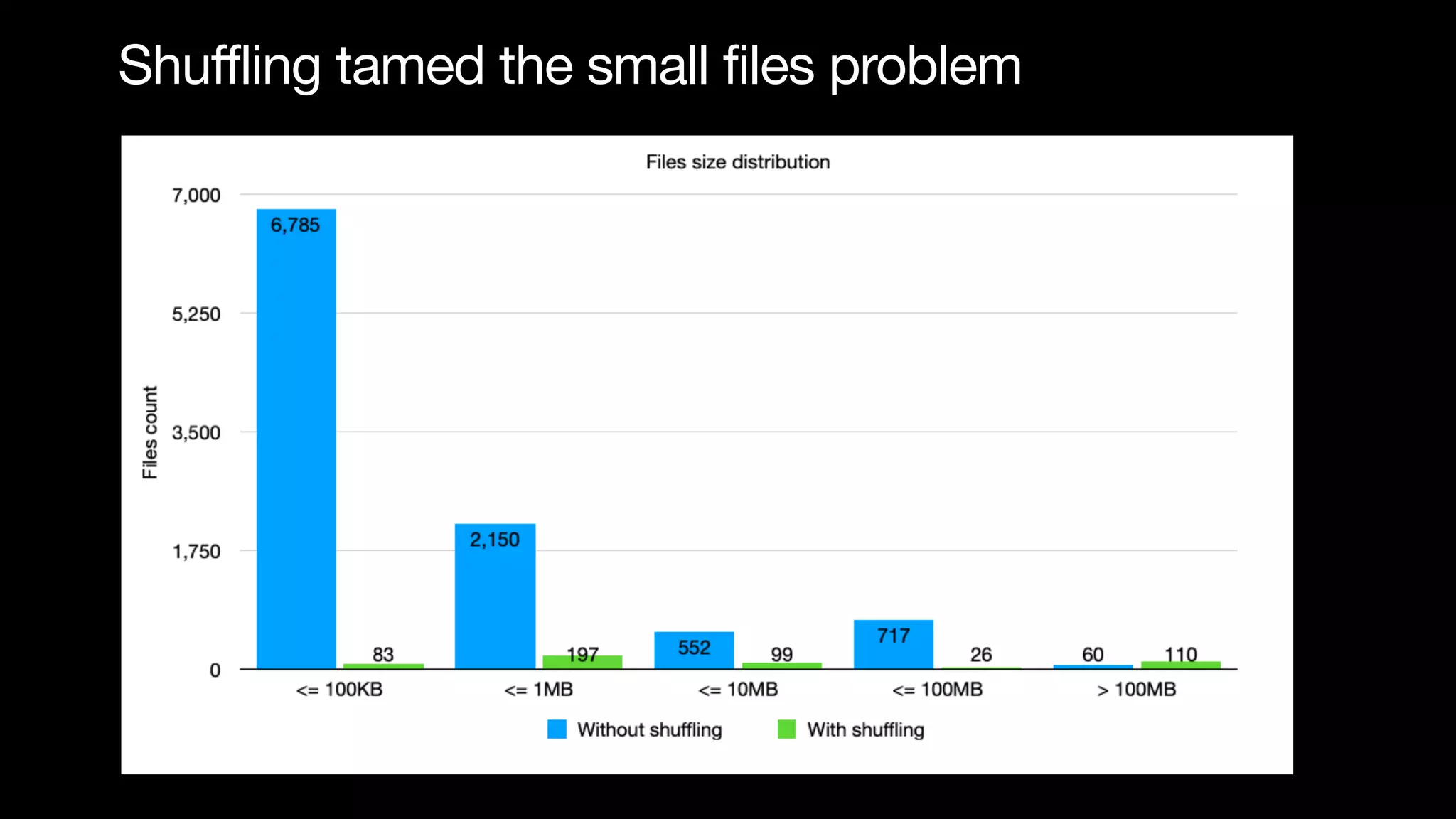
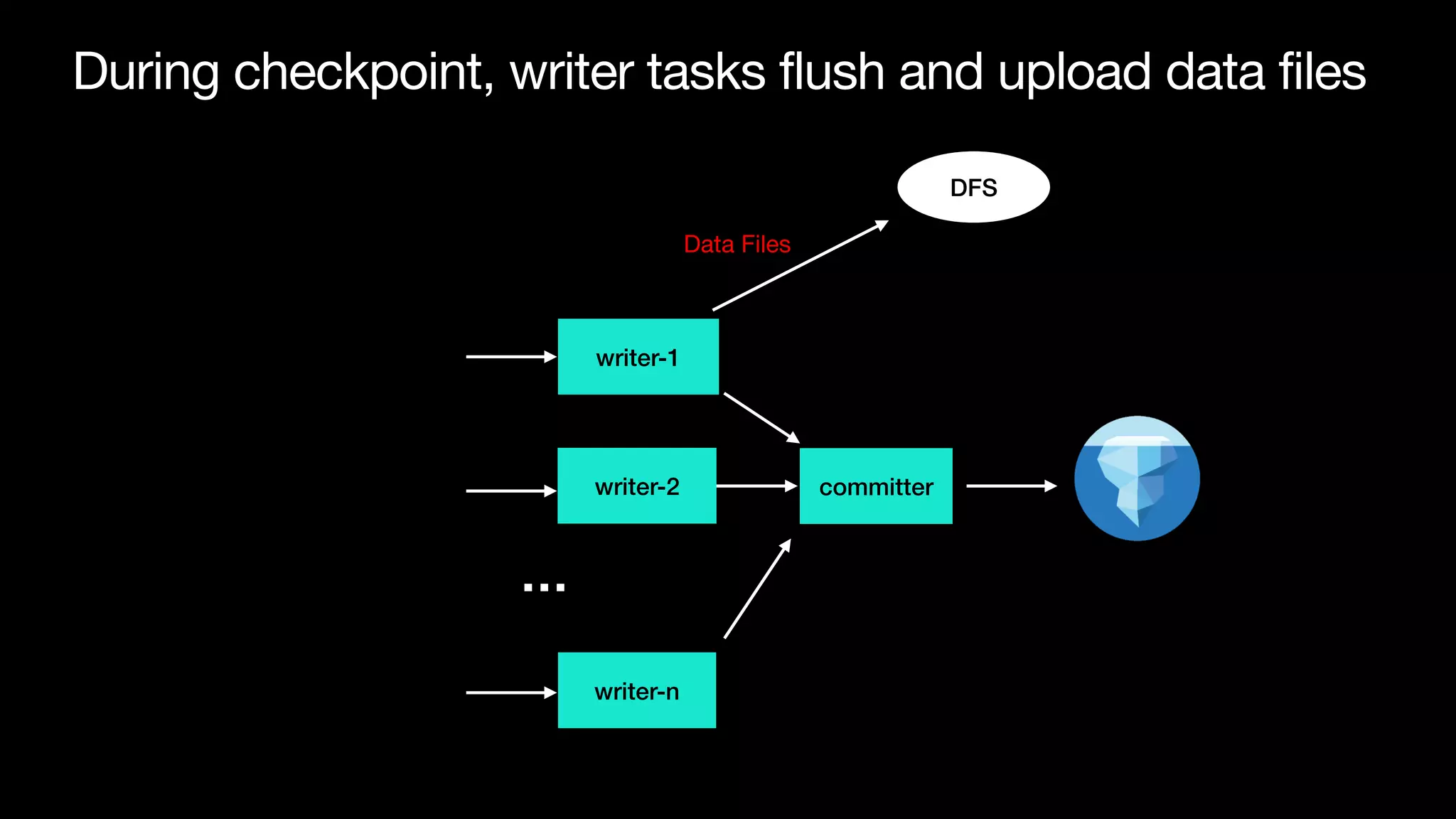
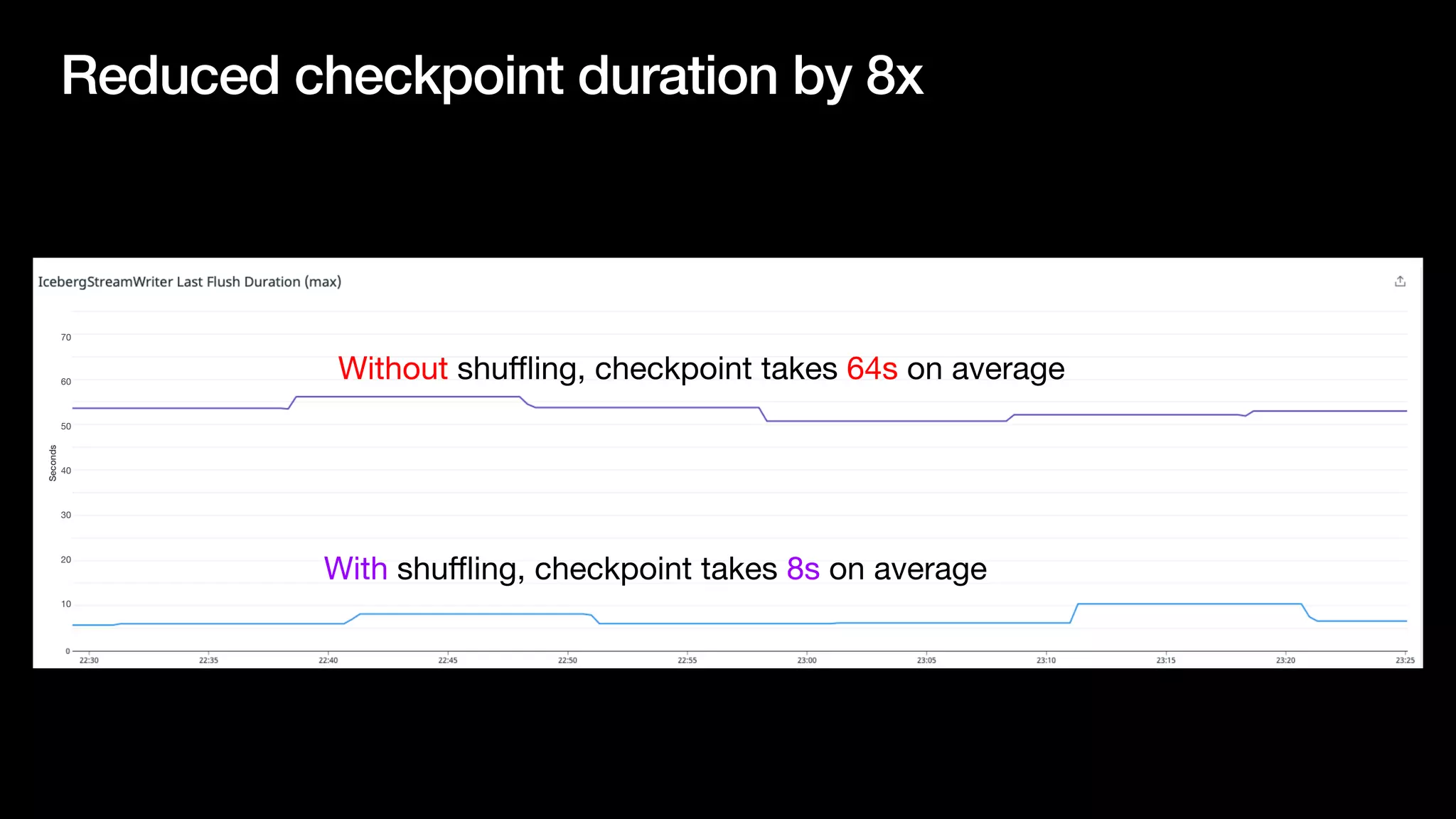
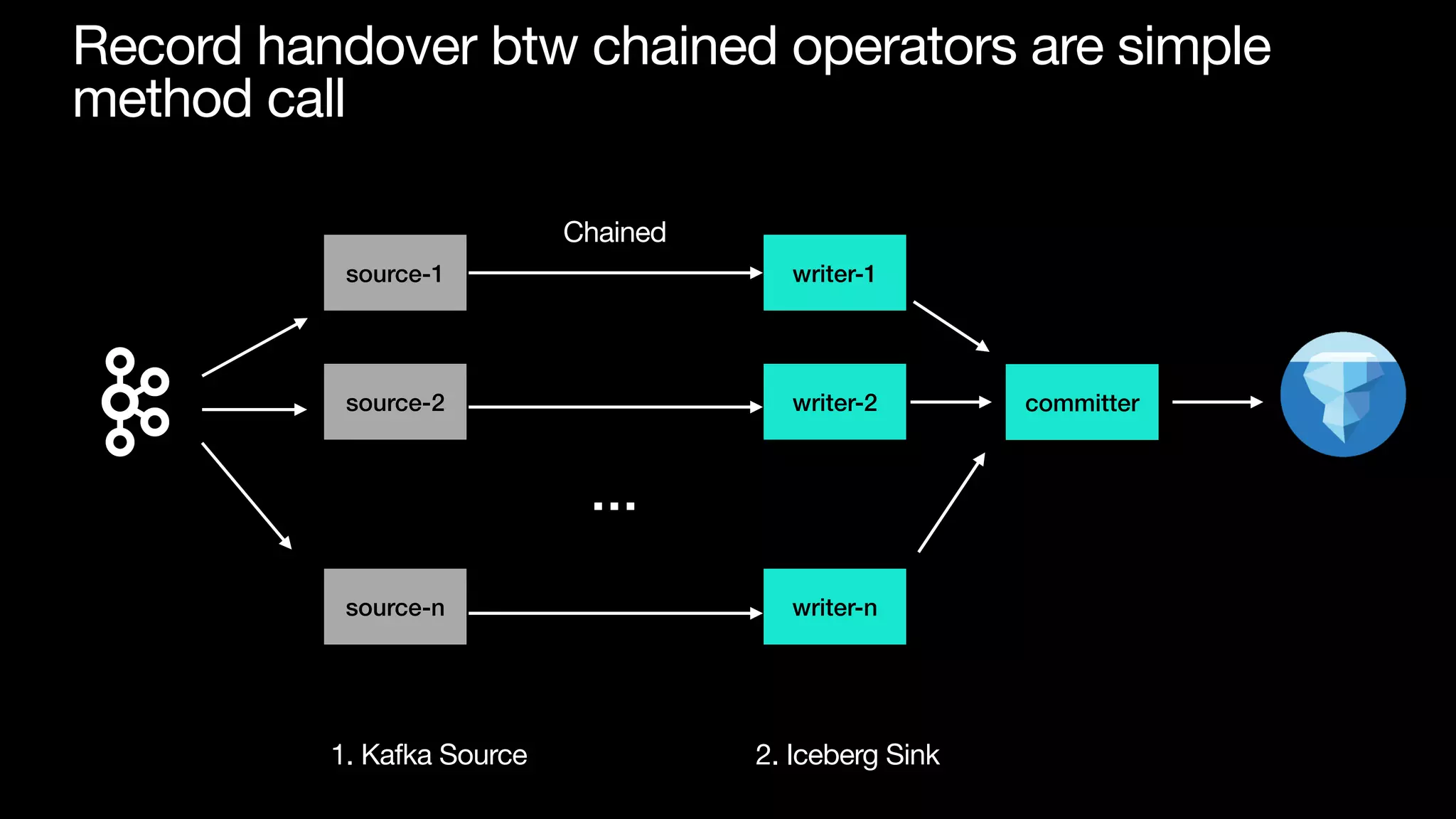

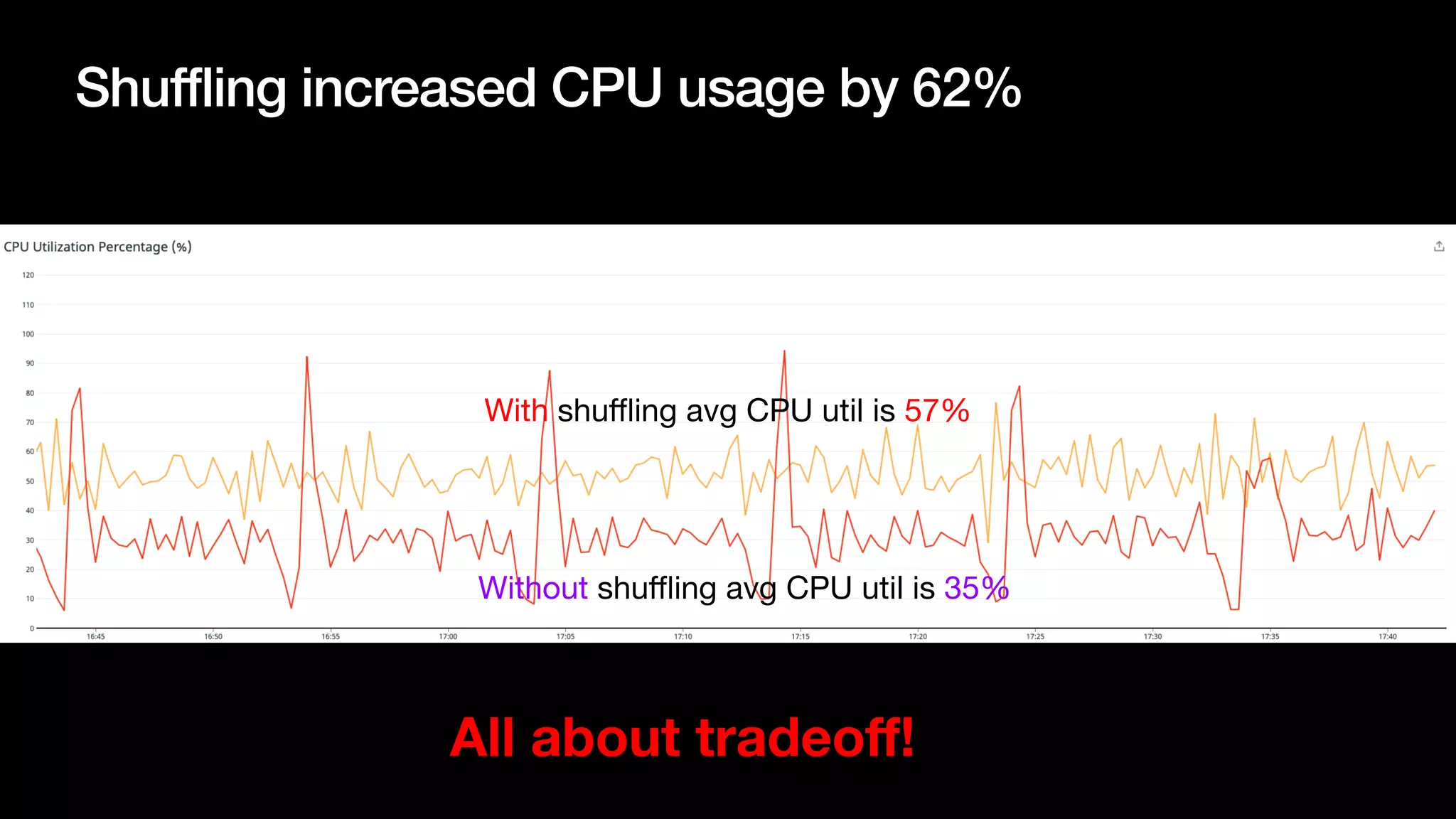
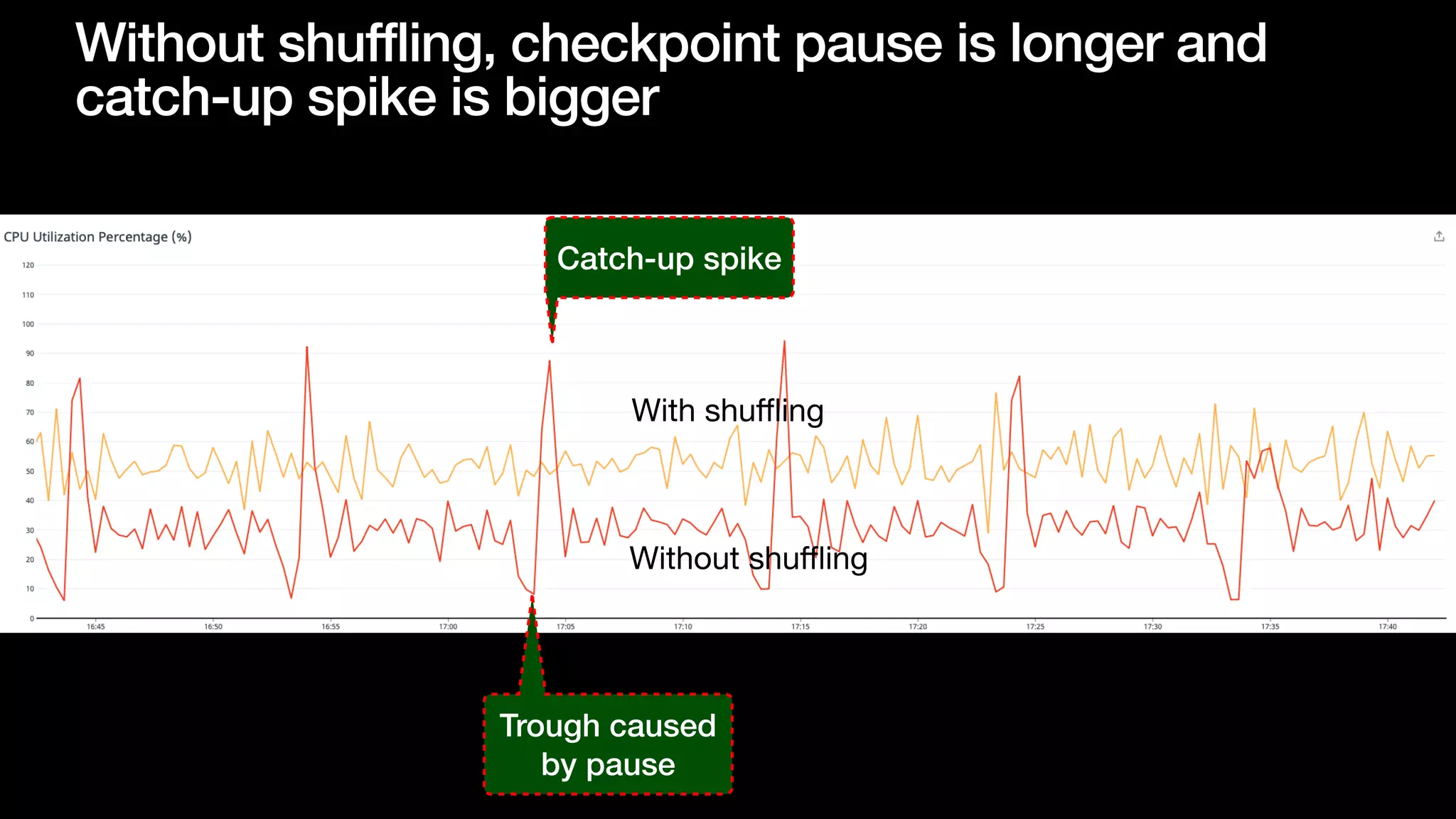
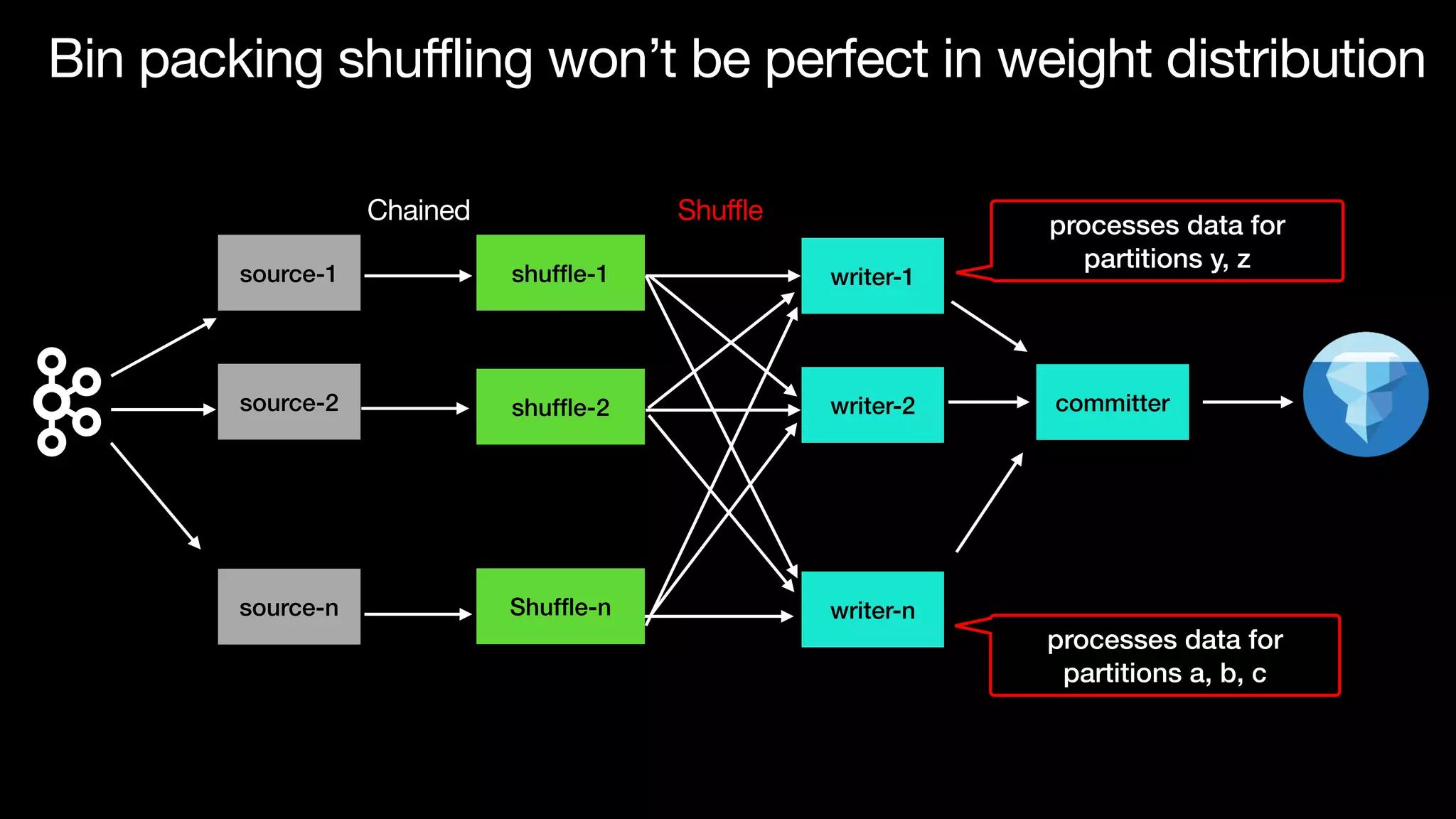










The document discusses optimizing streaming data ingestion to Apache Iceberg by addressing the small files problem through a smart shuffling operator in Flink. It highlights the issues caused by too many small files, such as poor read performance and long checkpoint durations, while presenting strategies to balance data distribution across partitions. The proposed smart shuffling aims to enhance data clustering, reduce the number of files generated, and improve overall performance metrics like checkpoint duration and CPU utilization.








































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












