Downloaded 15 times










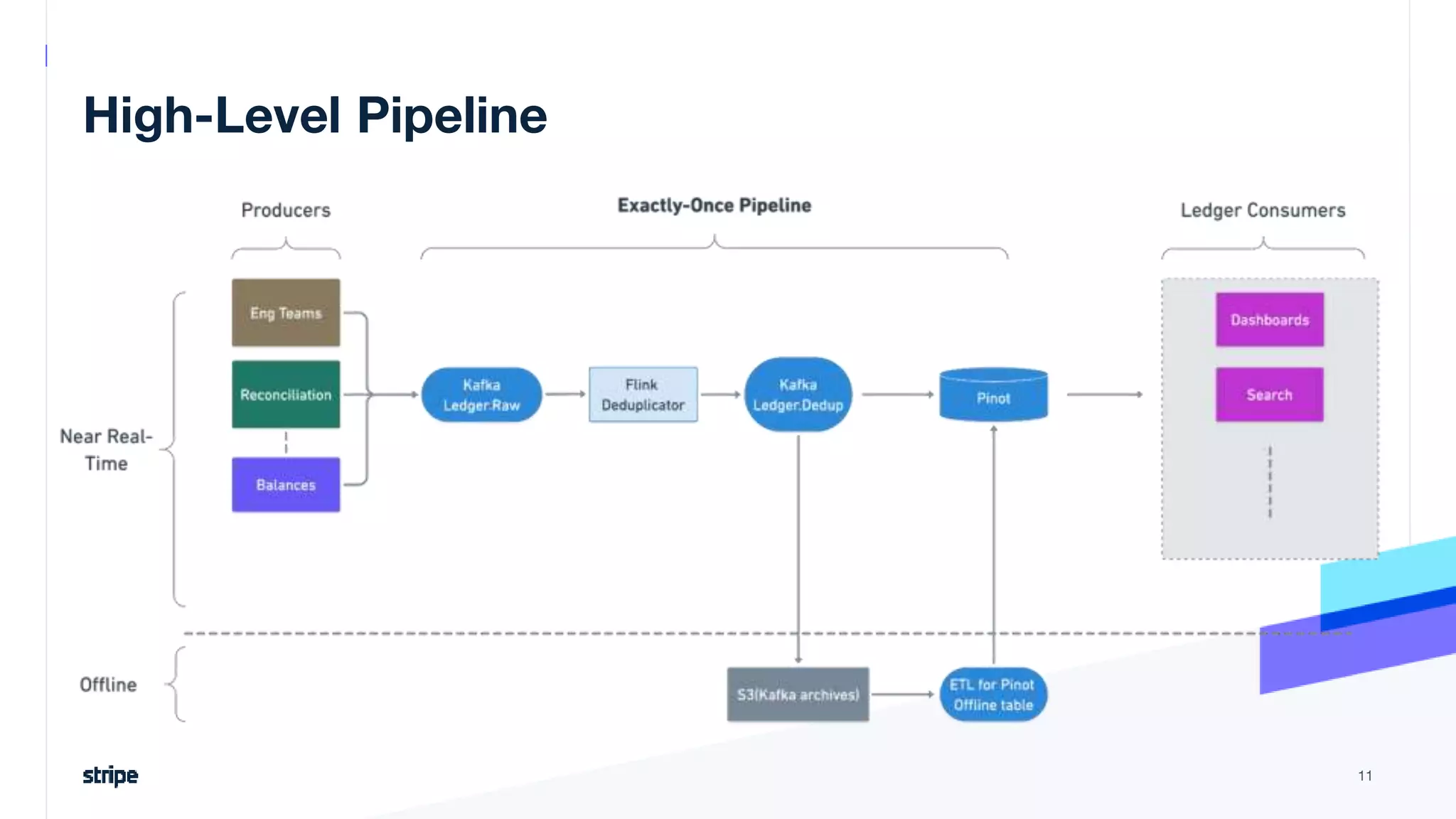
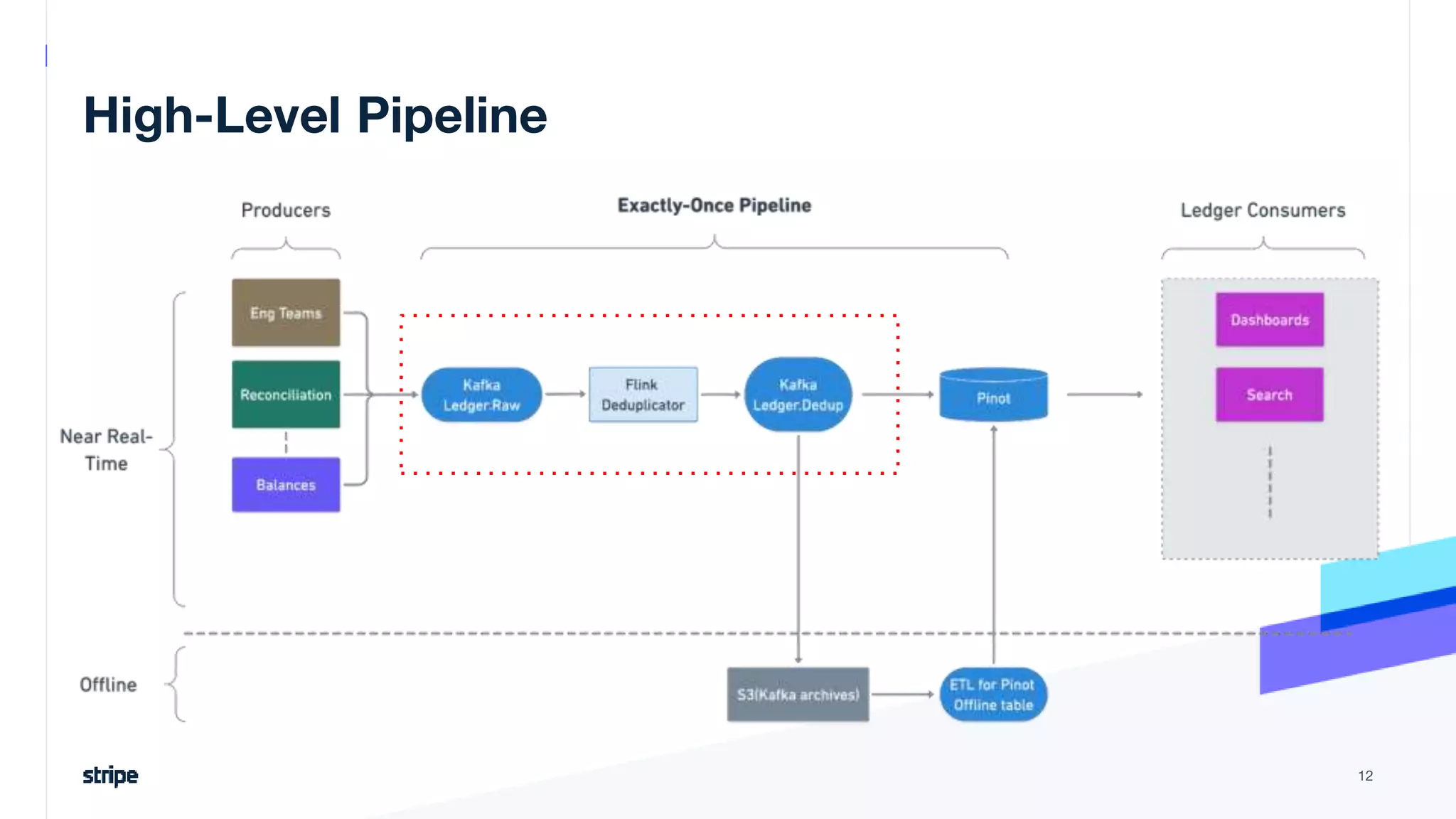
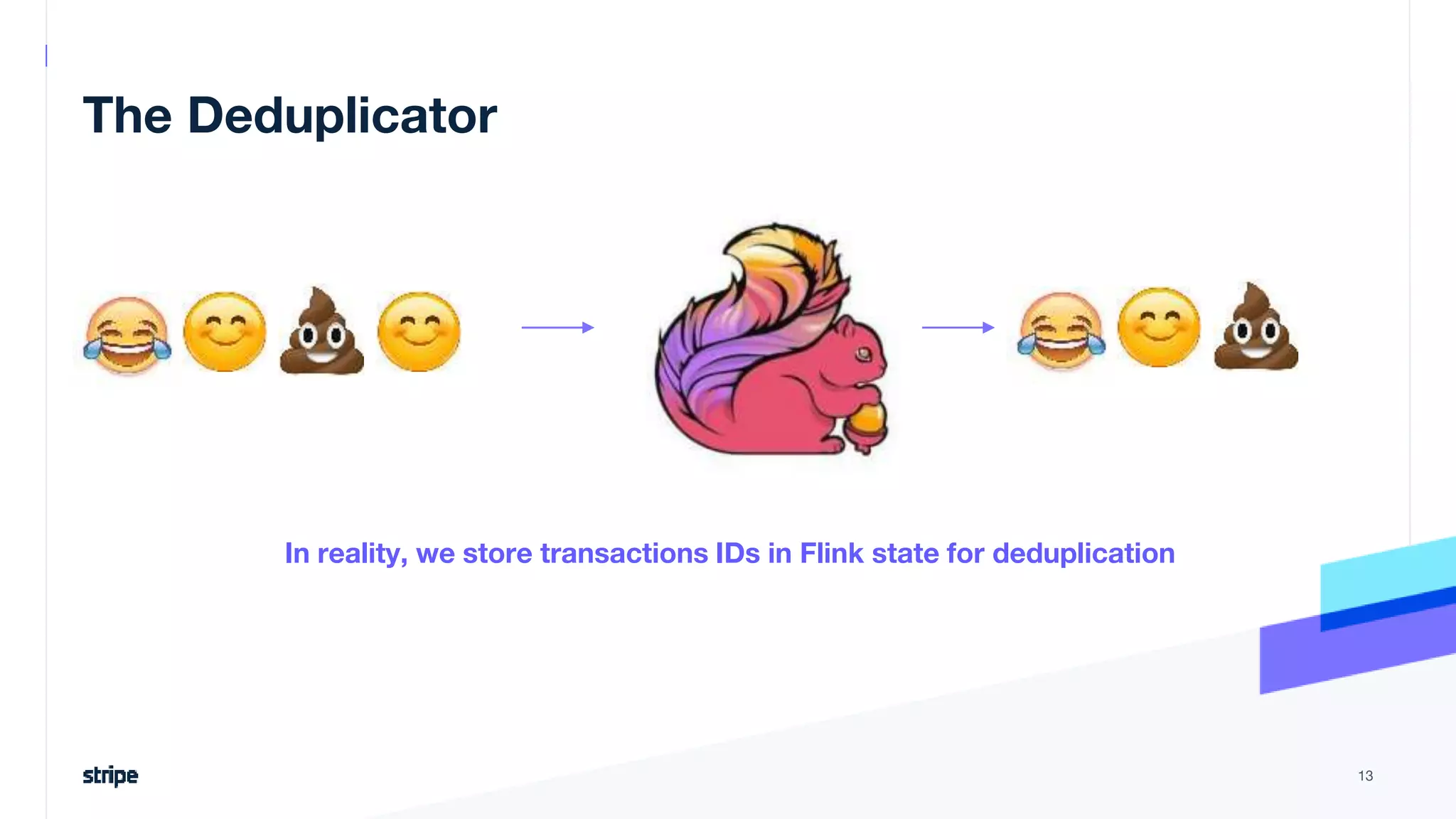
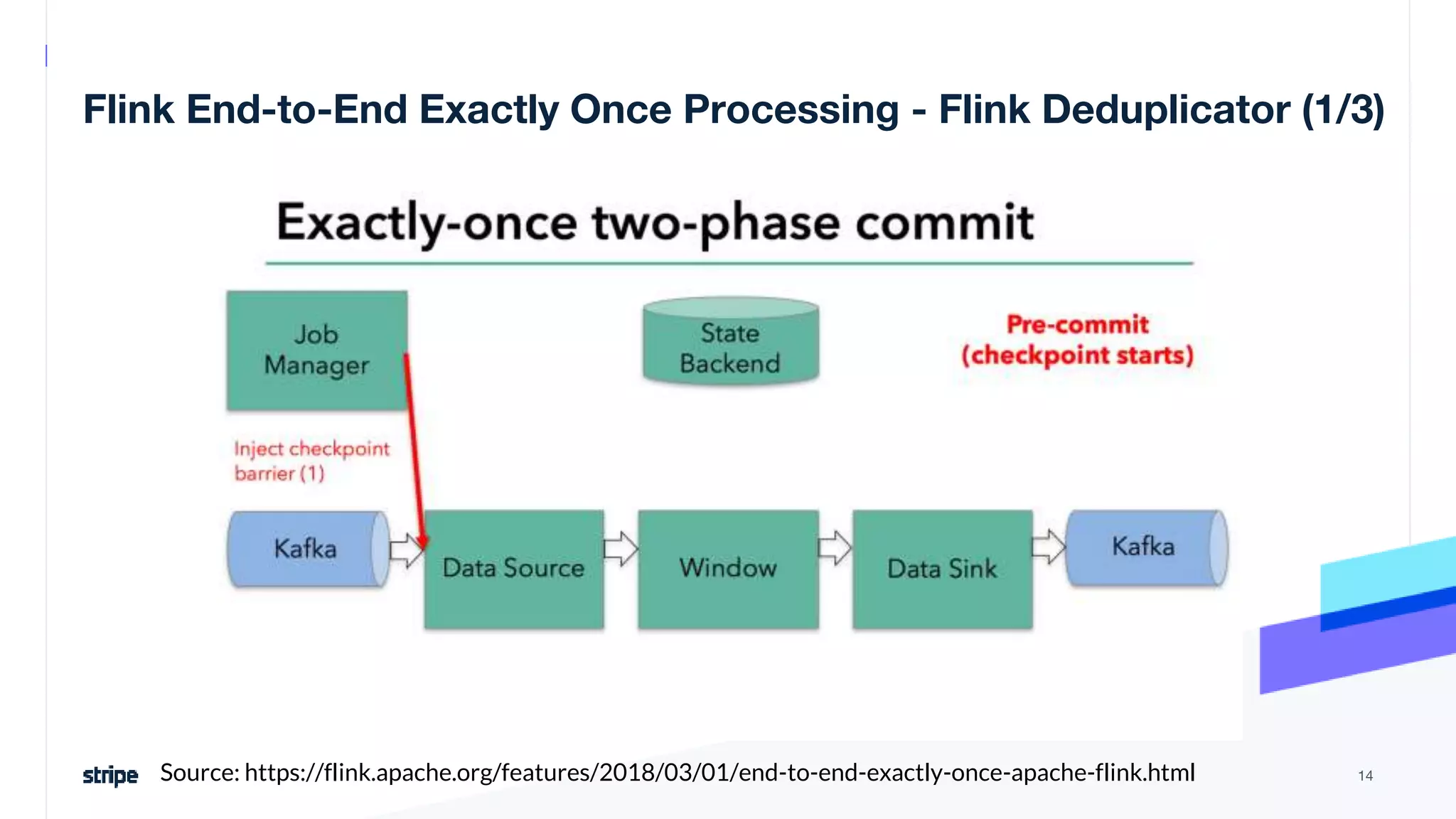
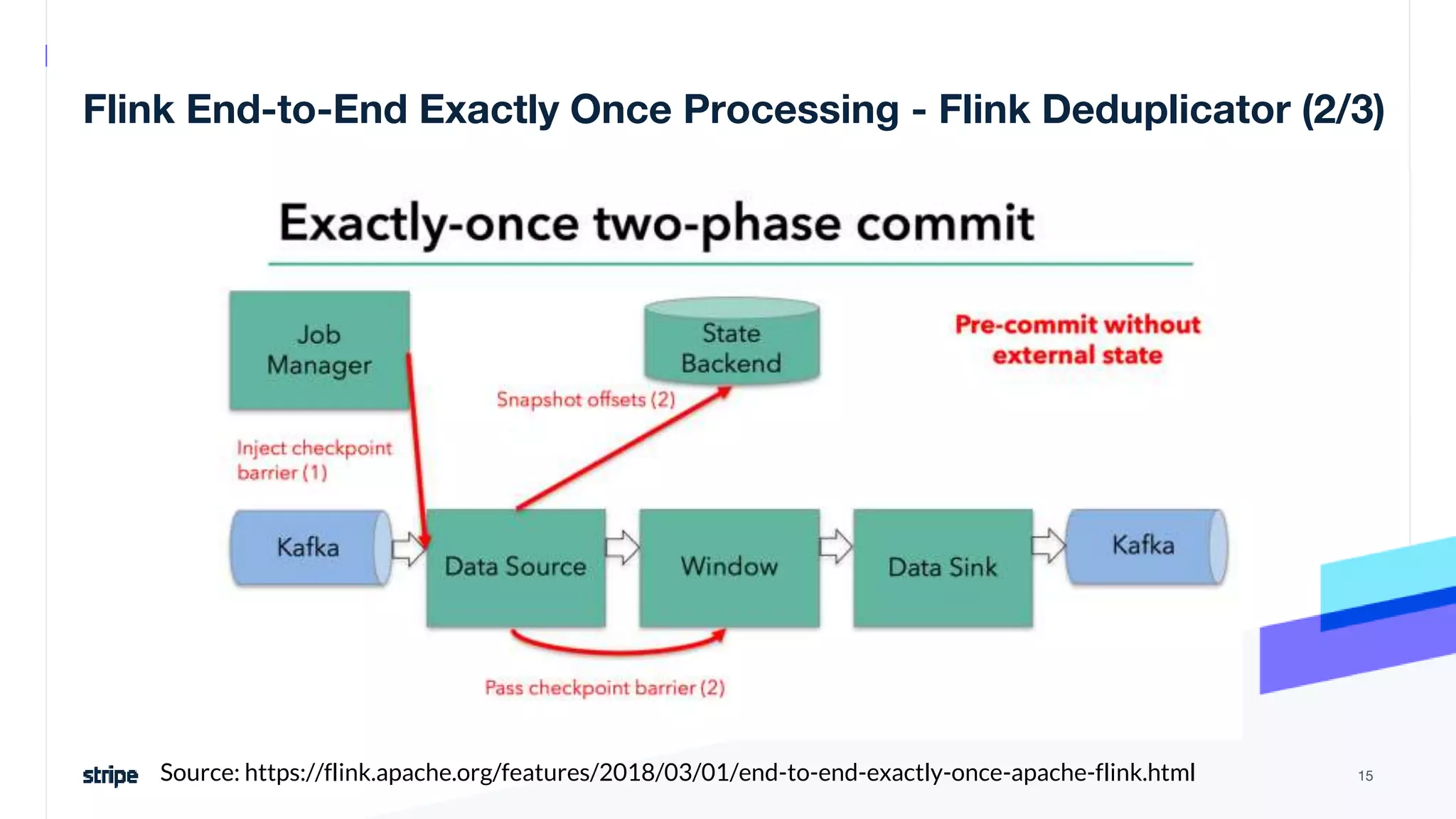
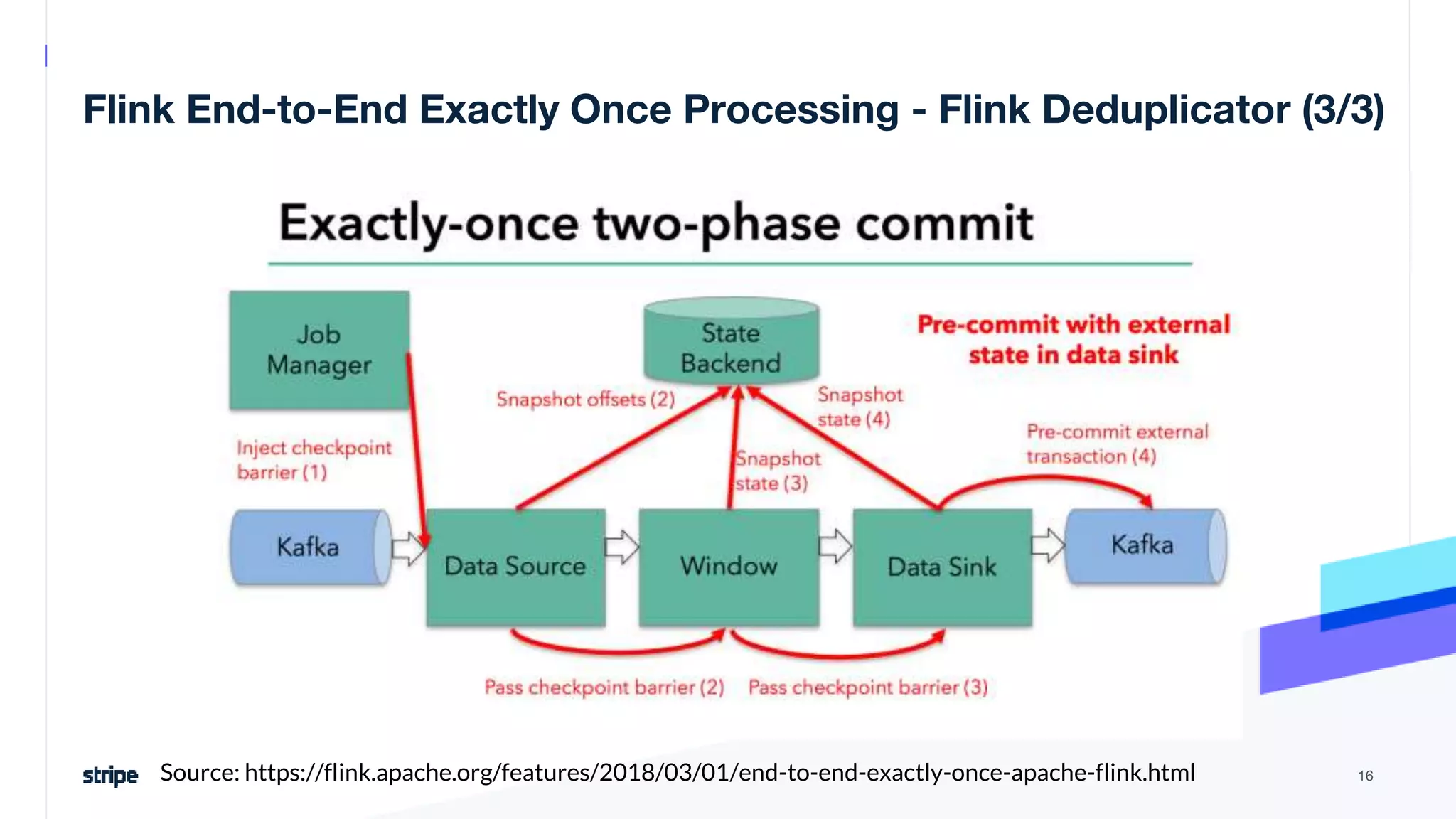
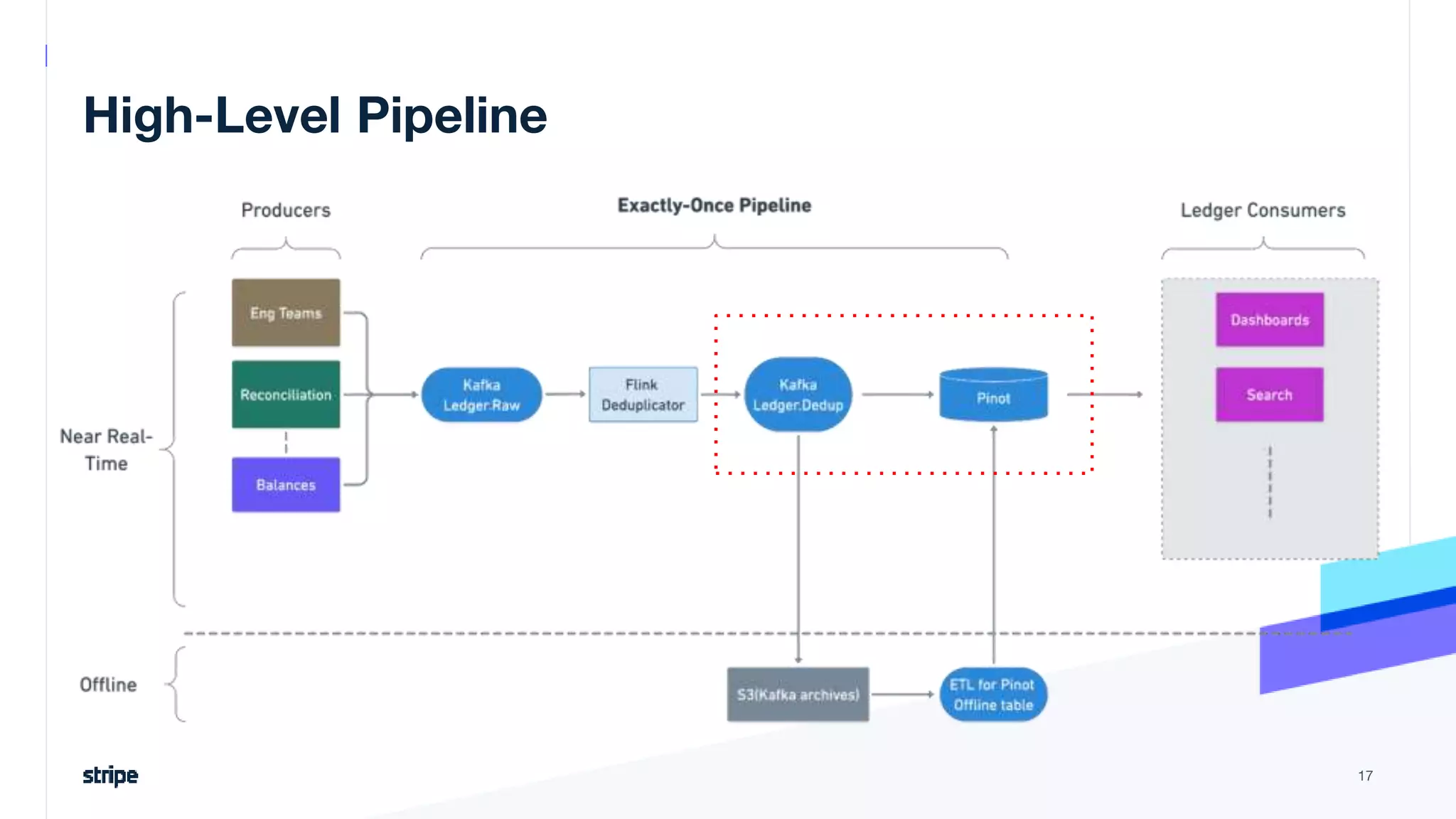
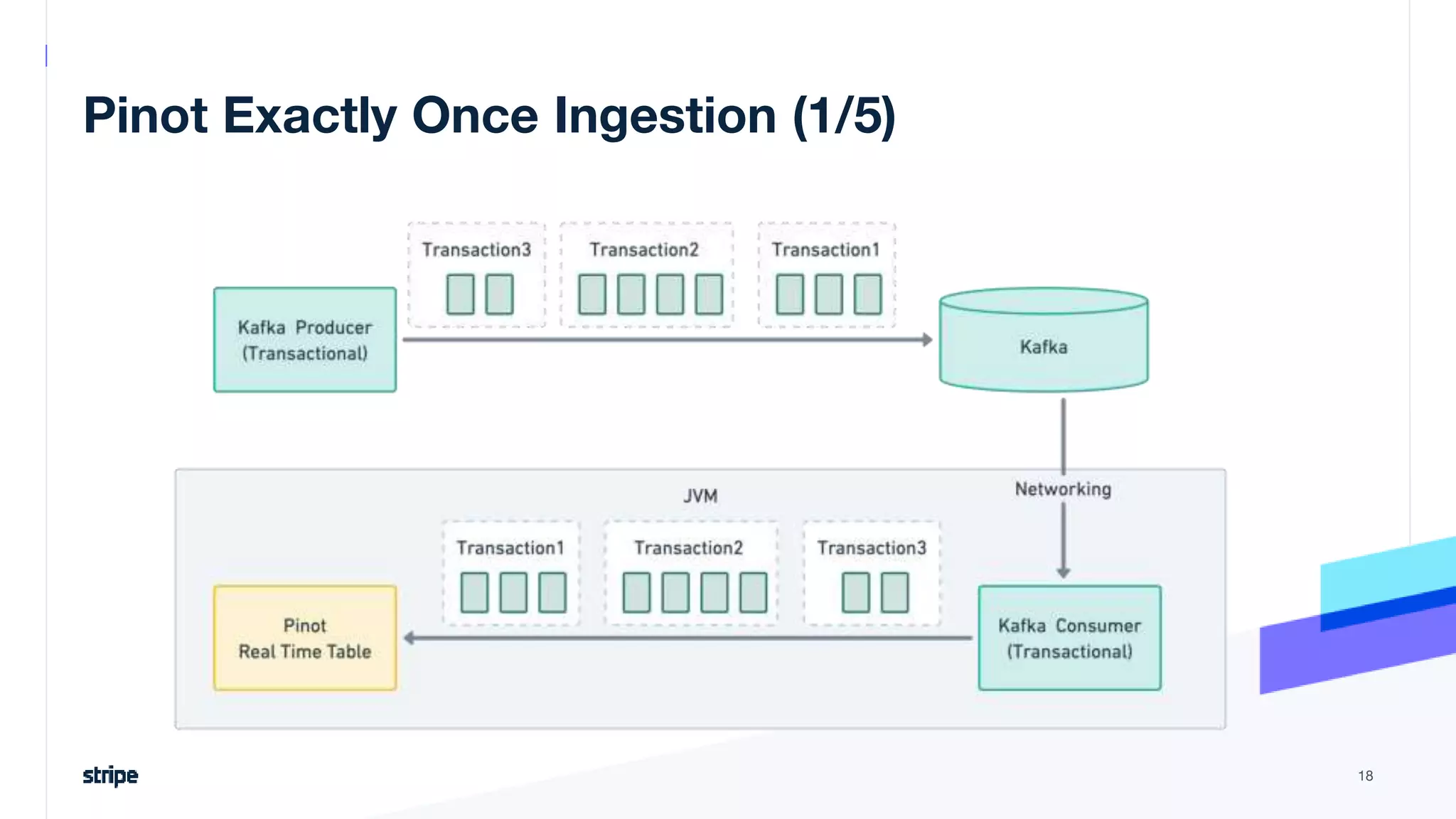
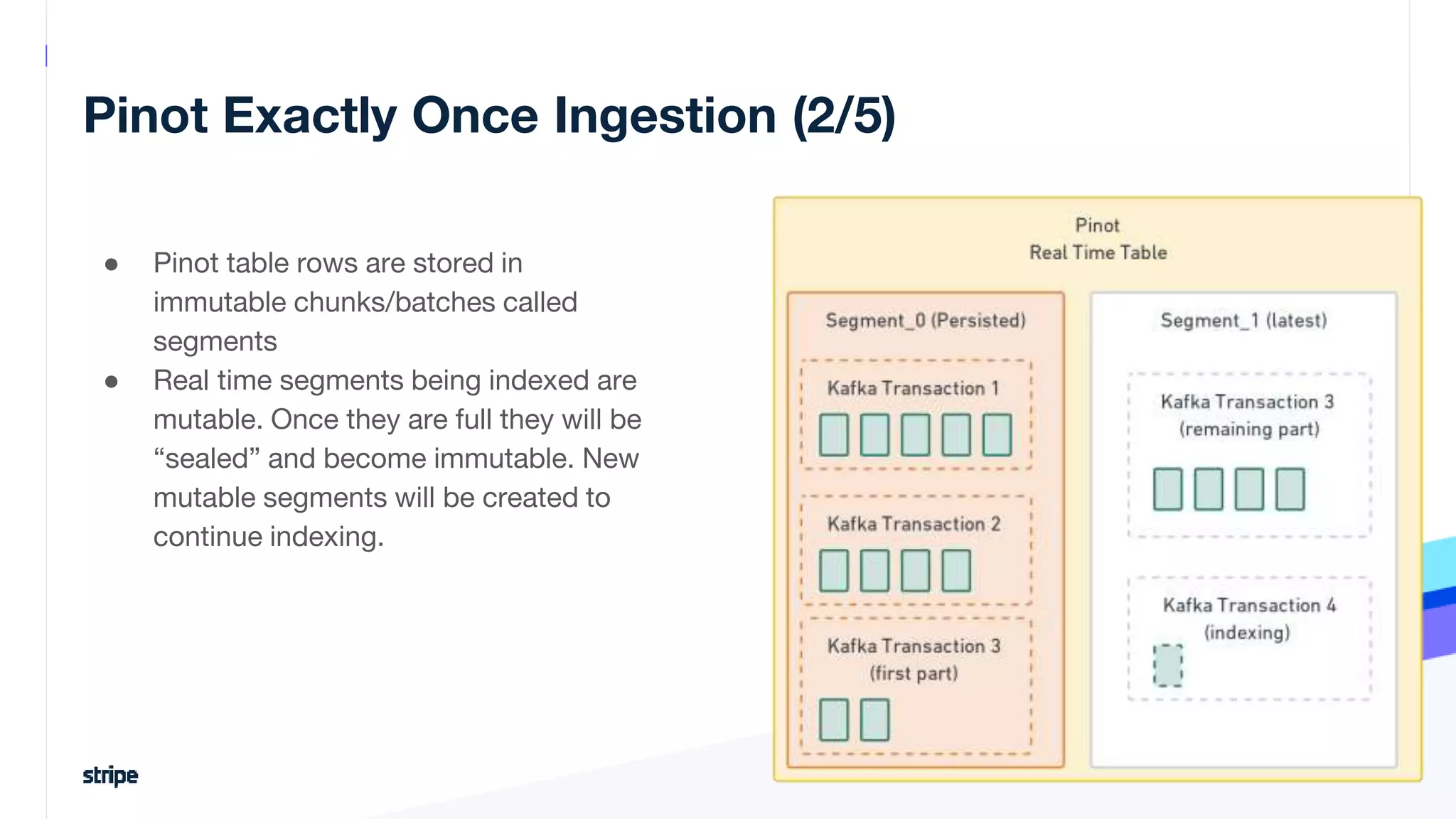
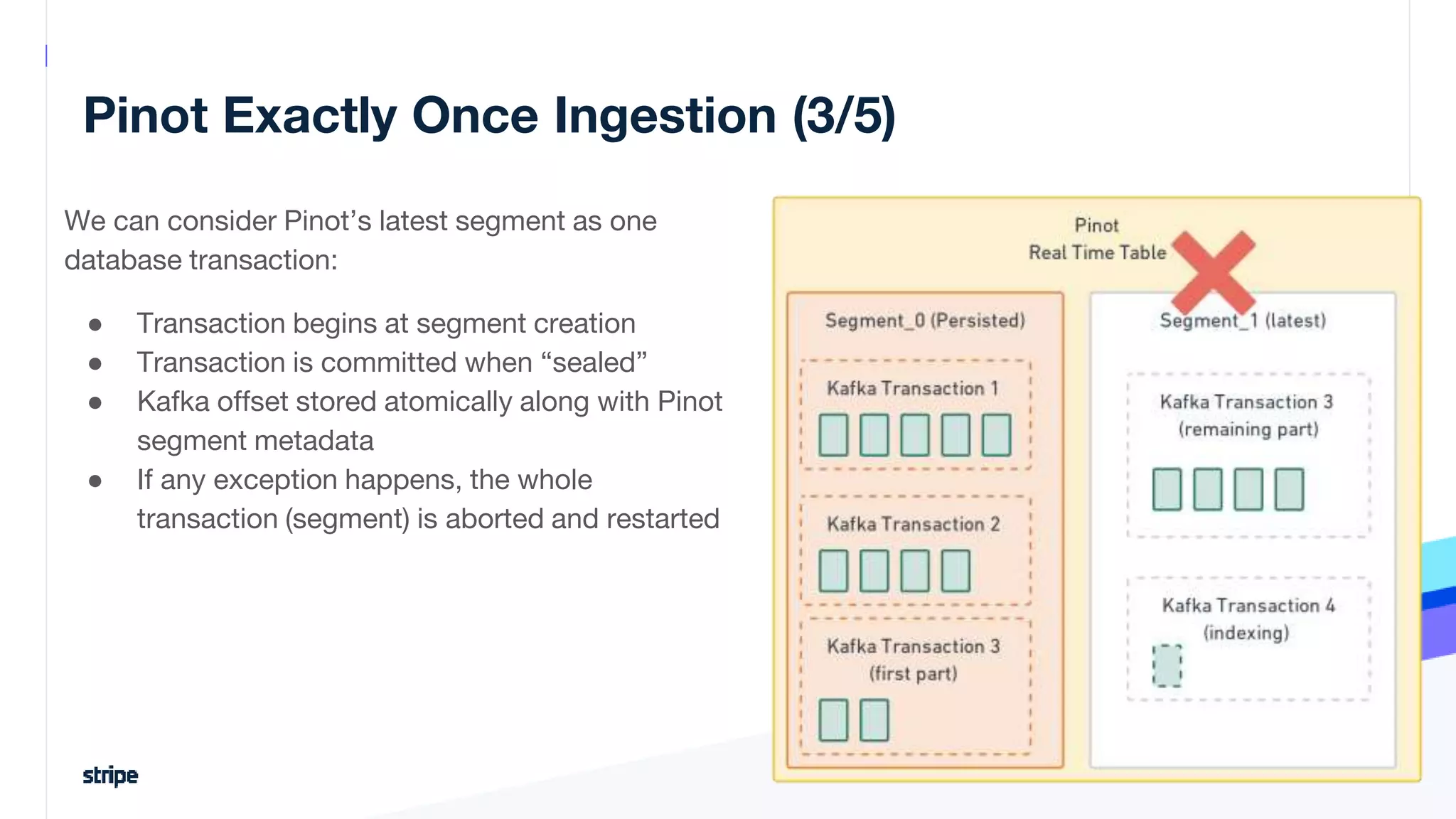

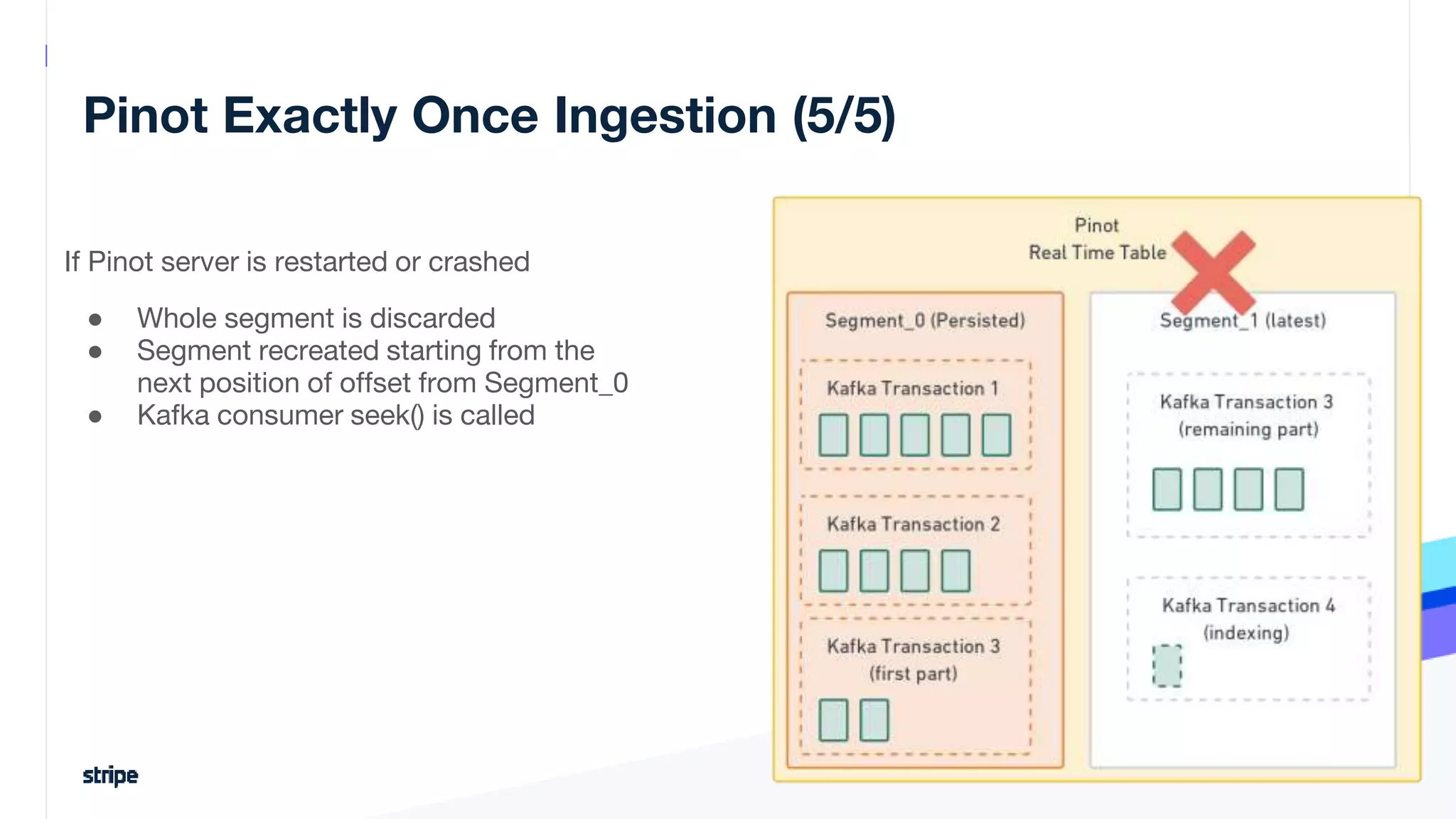




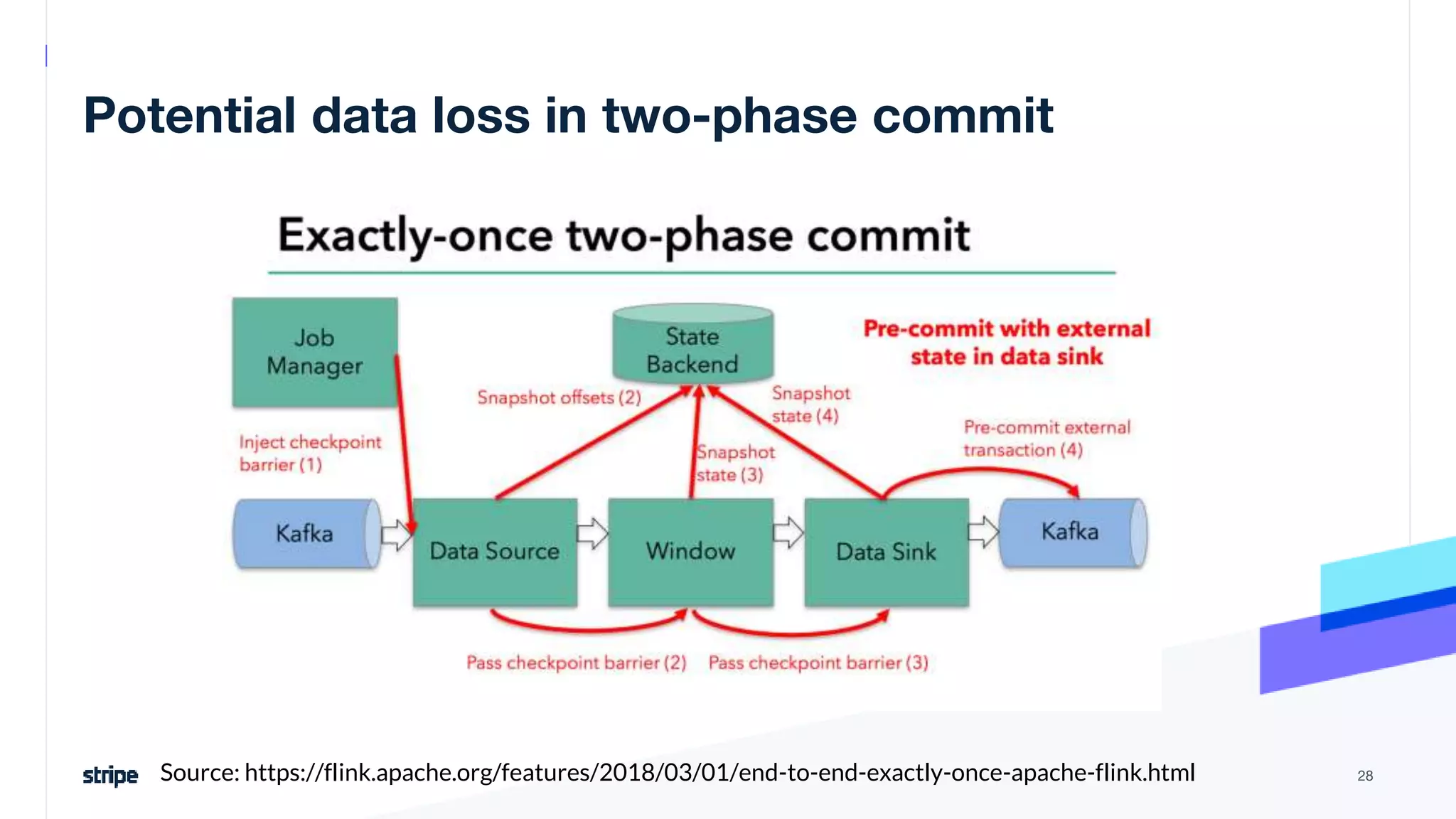
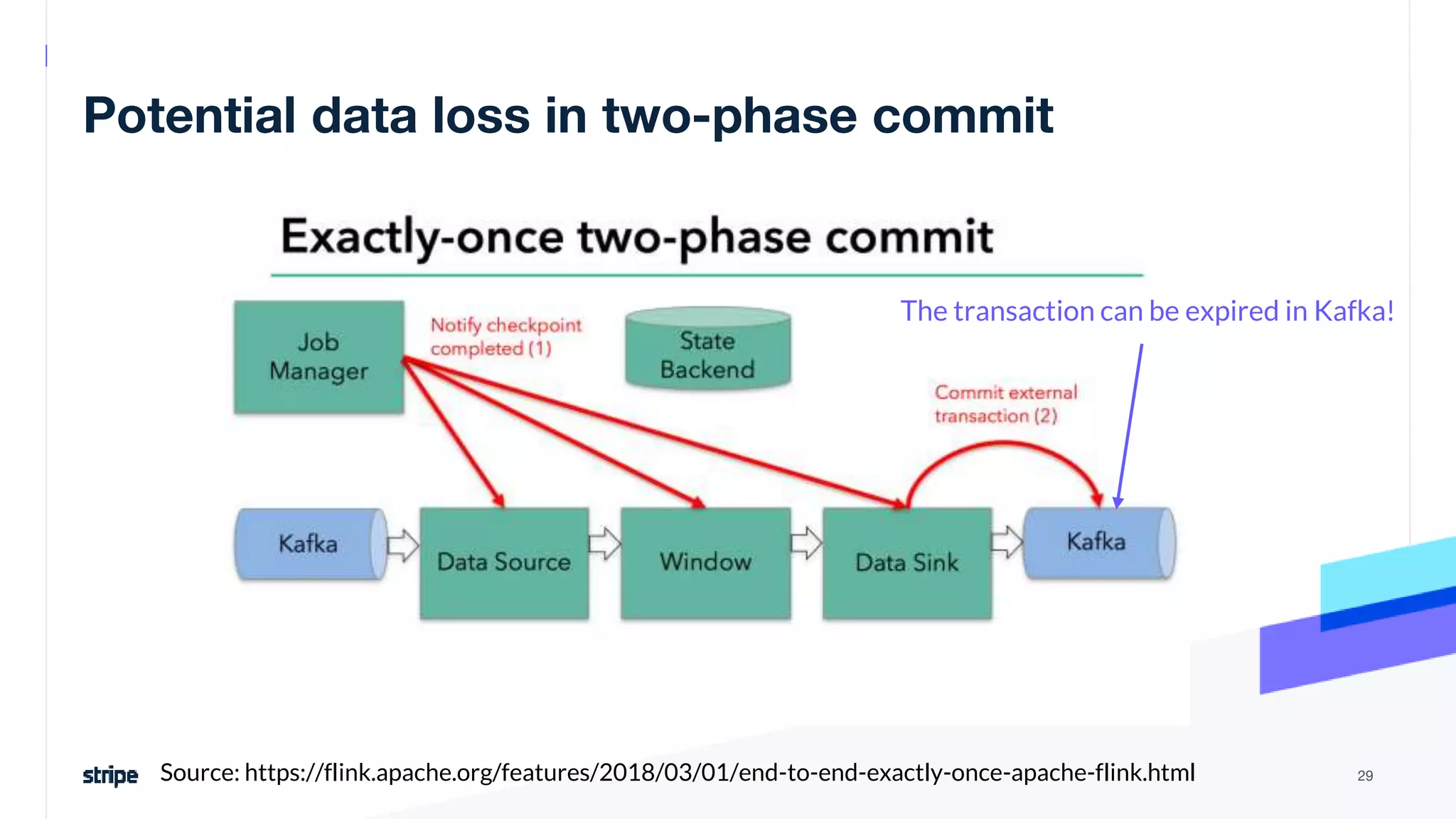

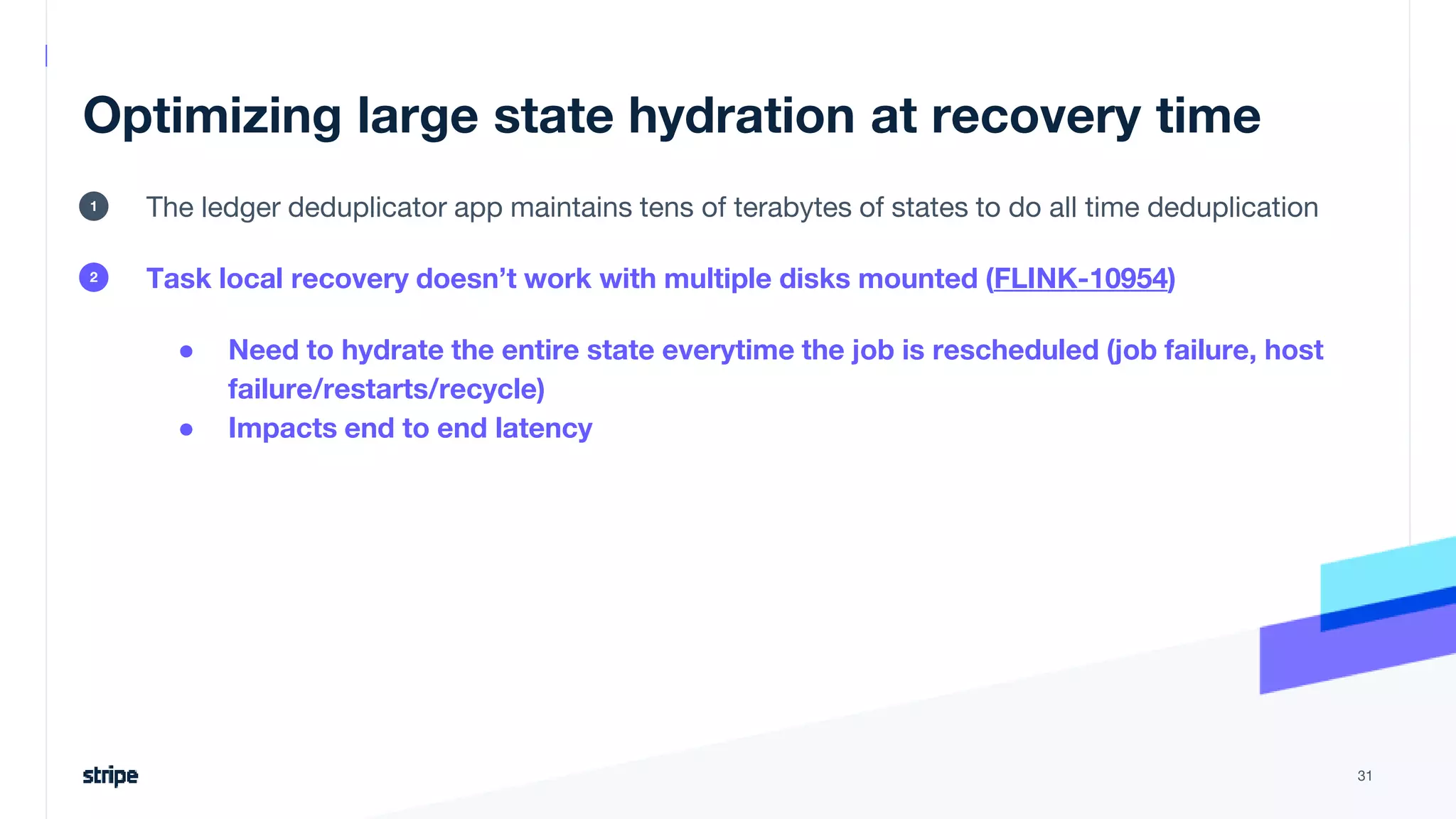


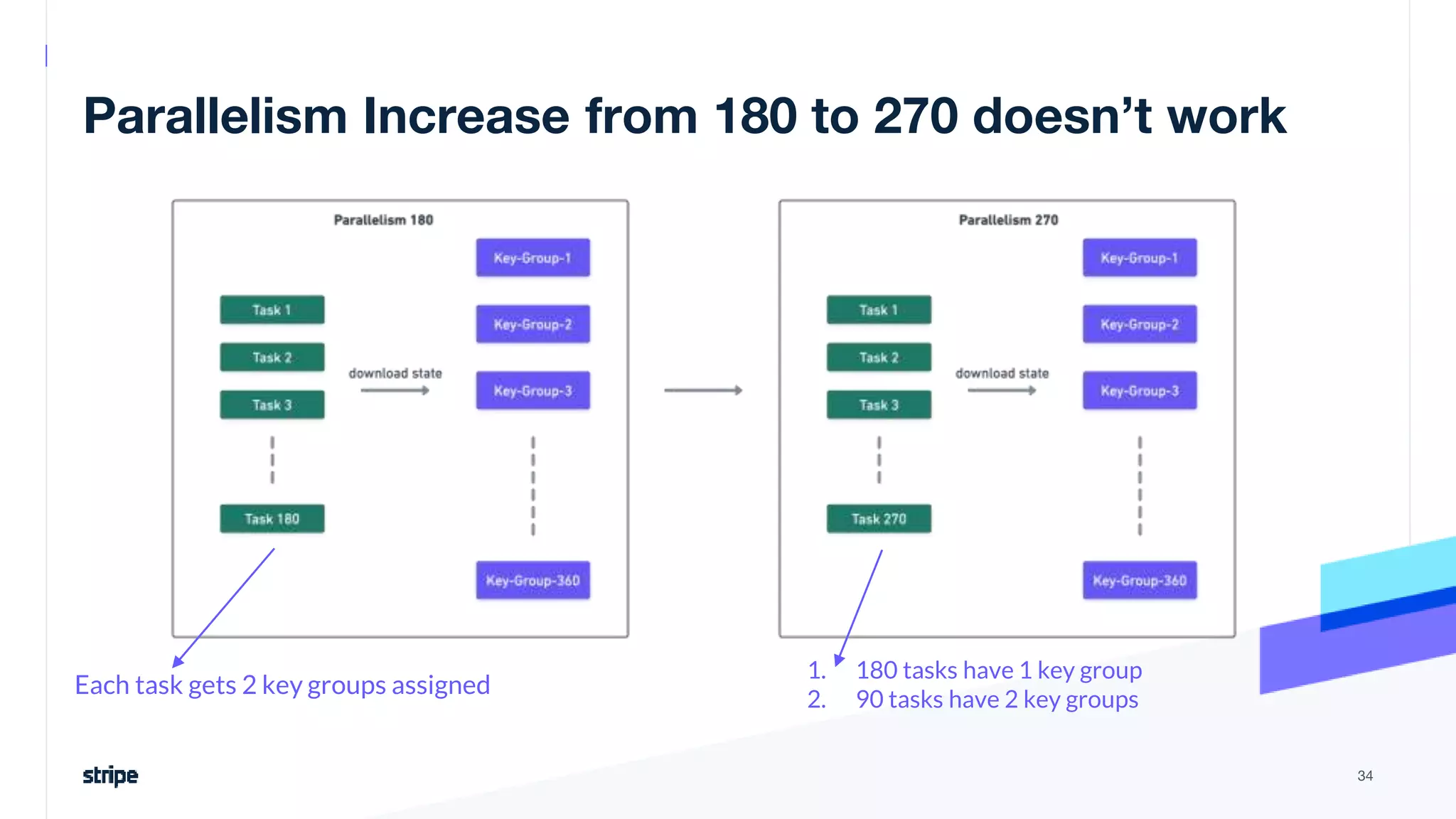
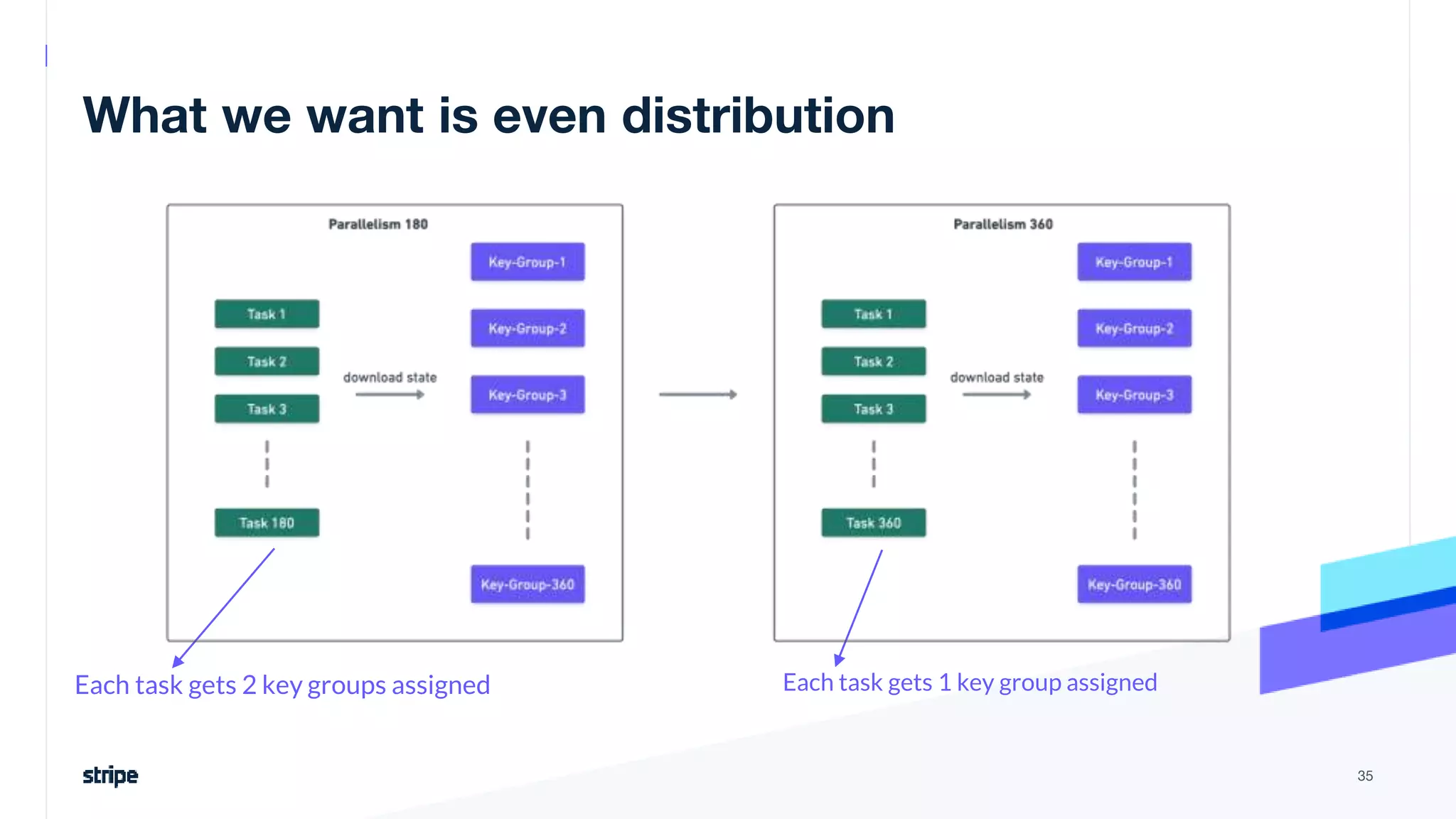


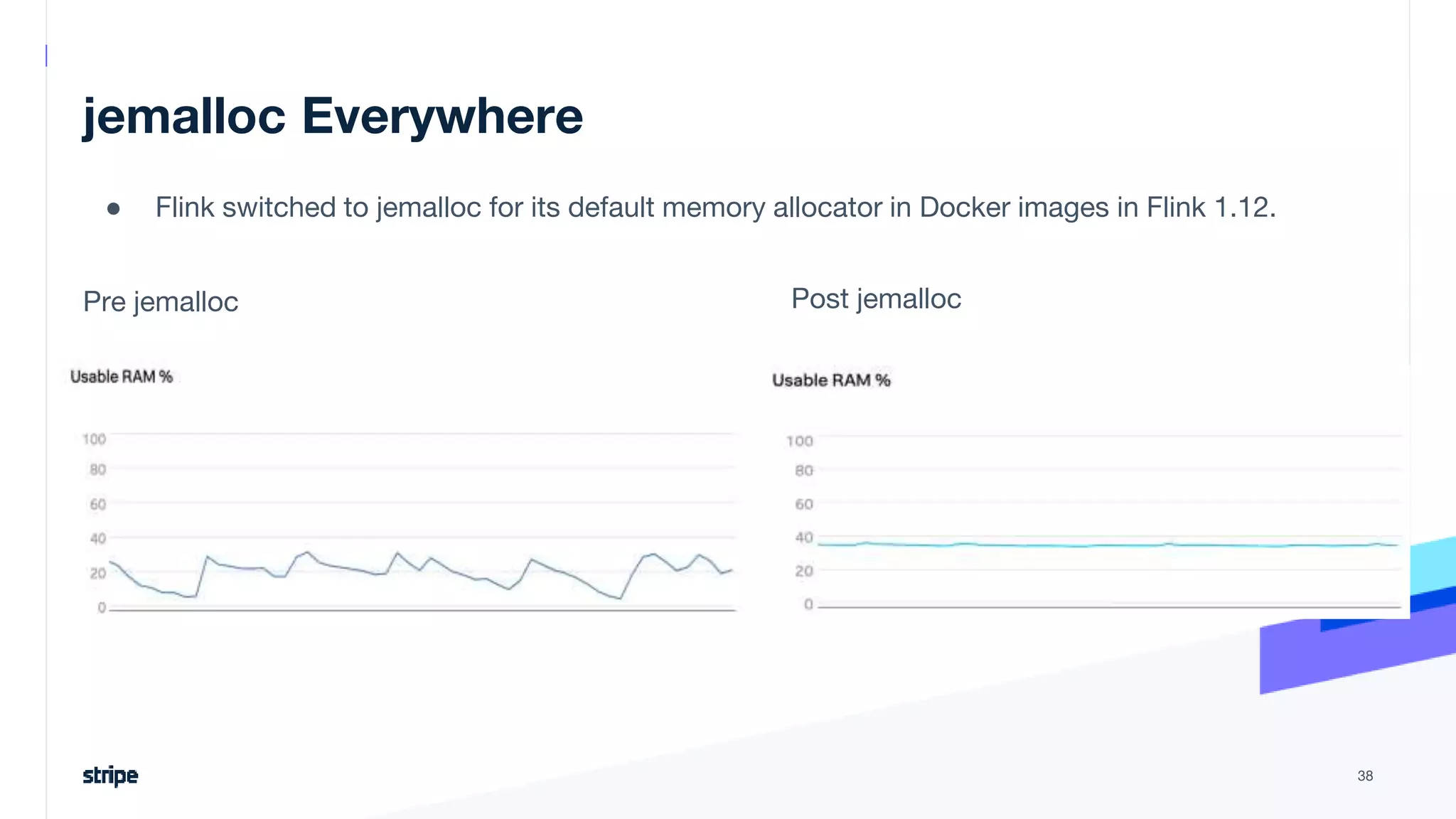




The document discusses the implementation of a near real-time, exactly-once financial data processing pipeline using Kafka, Flink, and Pinot at Stripe, addressing the challenges of processing large volumes of transactions without missing or duplicating them. Key requirements include low latency and operational efficiency, with focus on deduplication strategies and handling Kafka transactions carefully to prevent data loss. Additionally, it outlines lessons learned and offers best practices for managing the architecture effectively.





















































































