Download to read offline

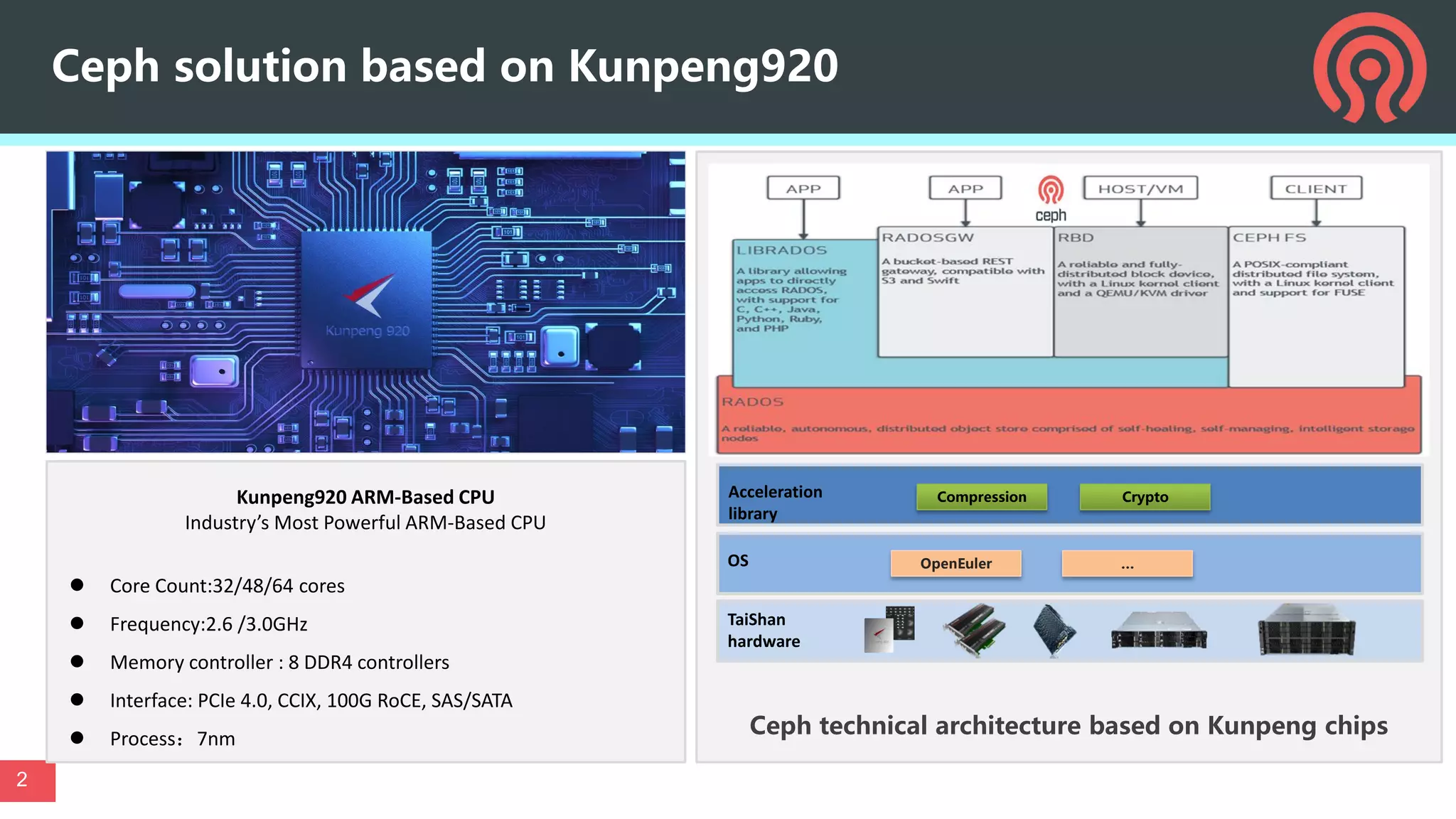
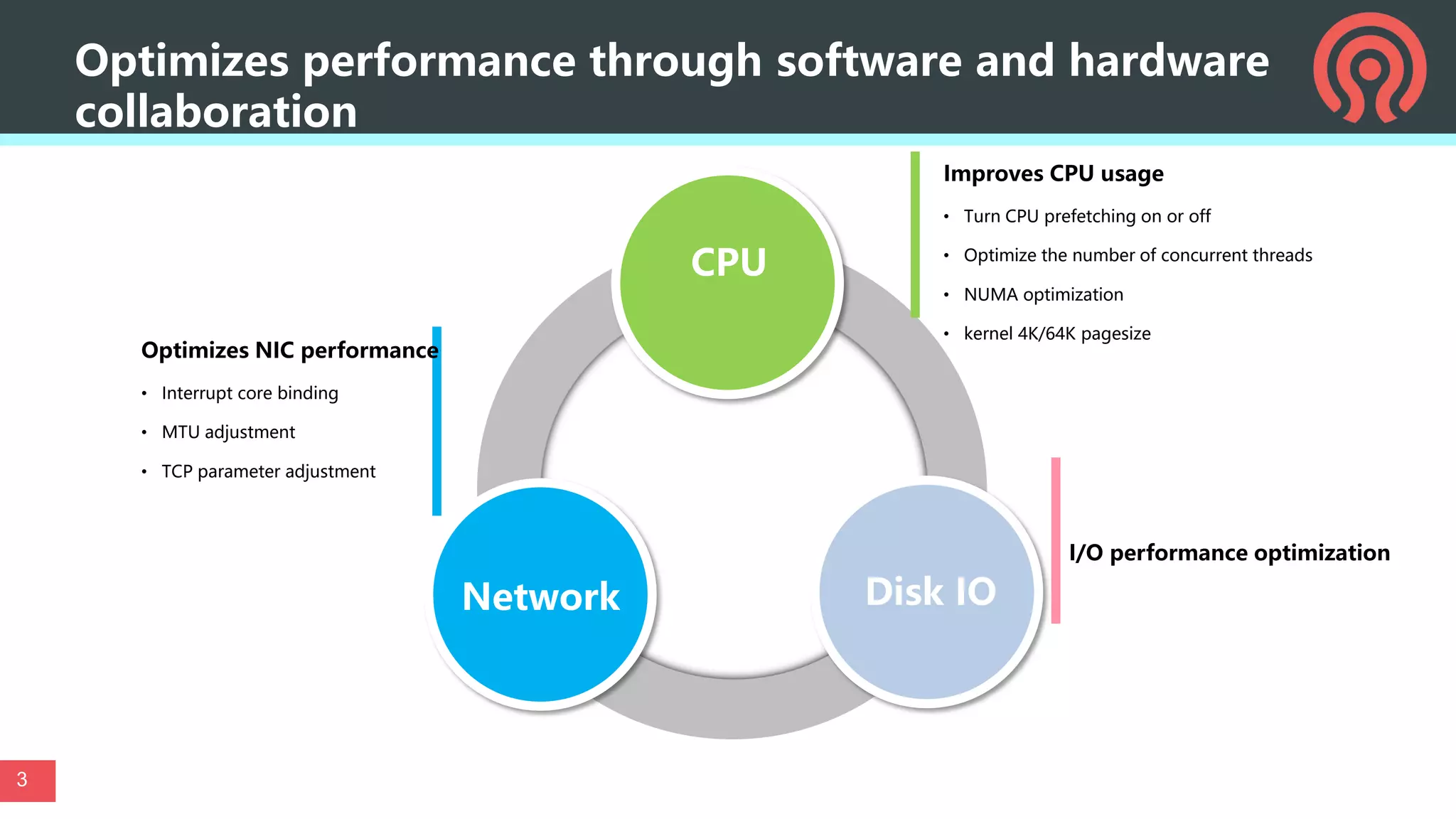

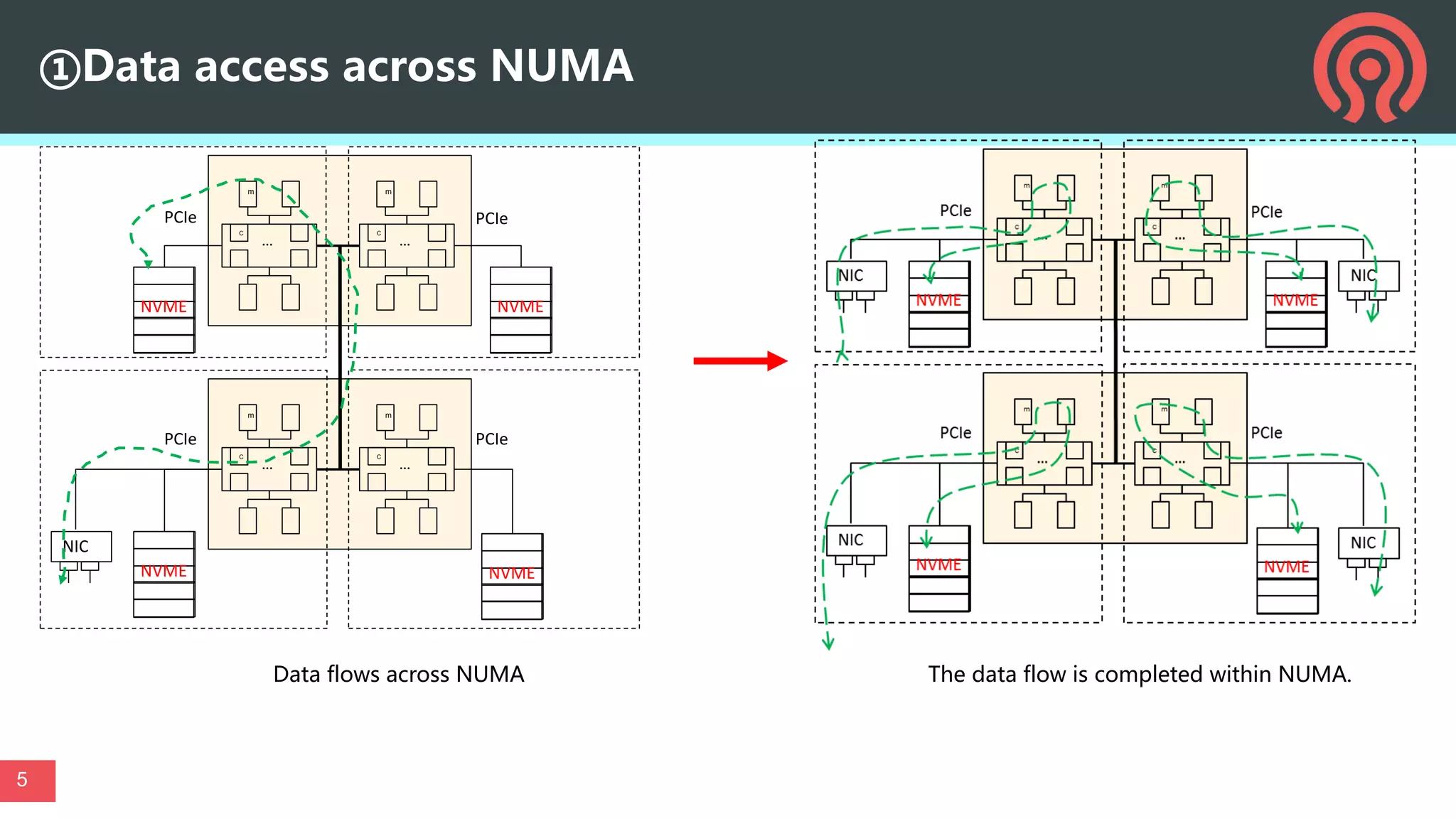
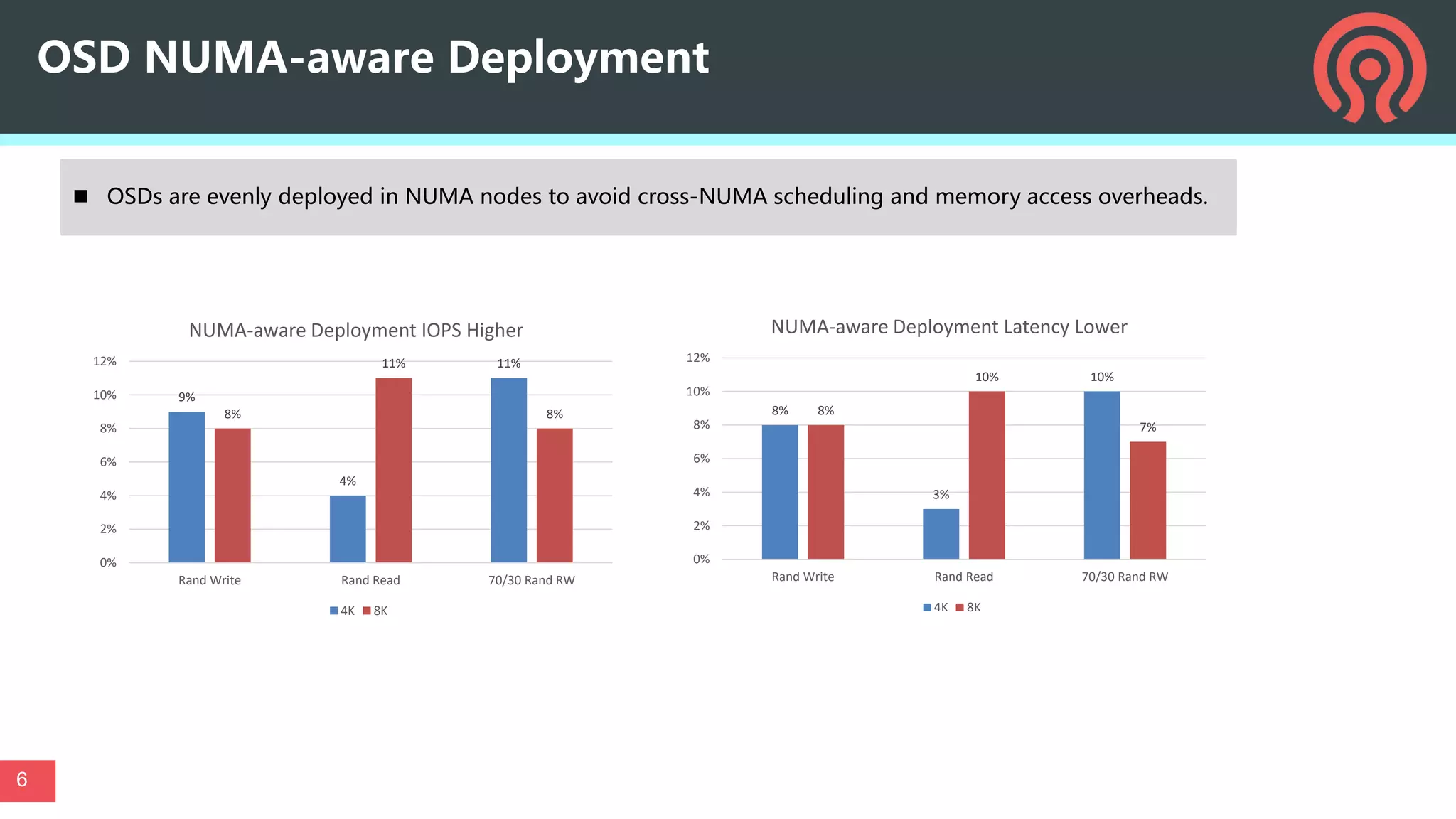
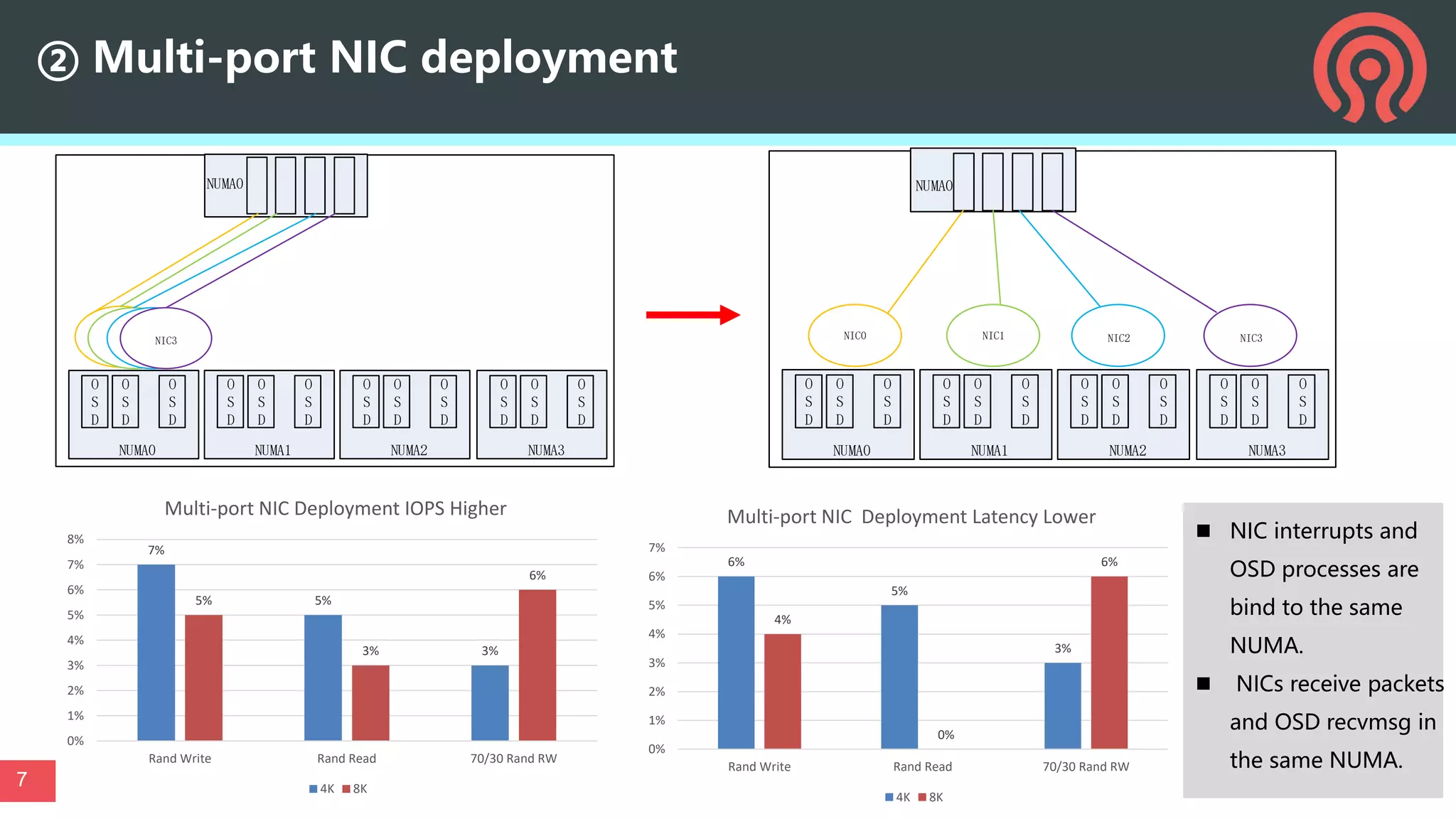
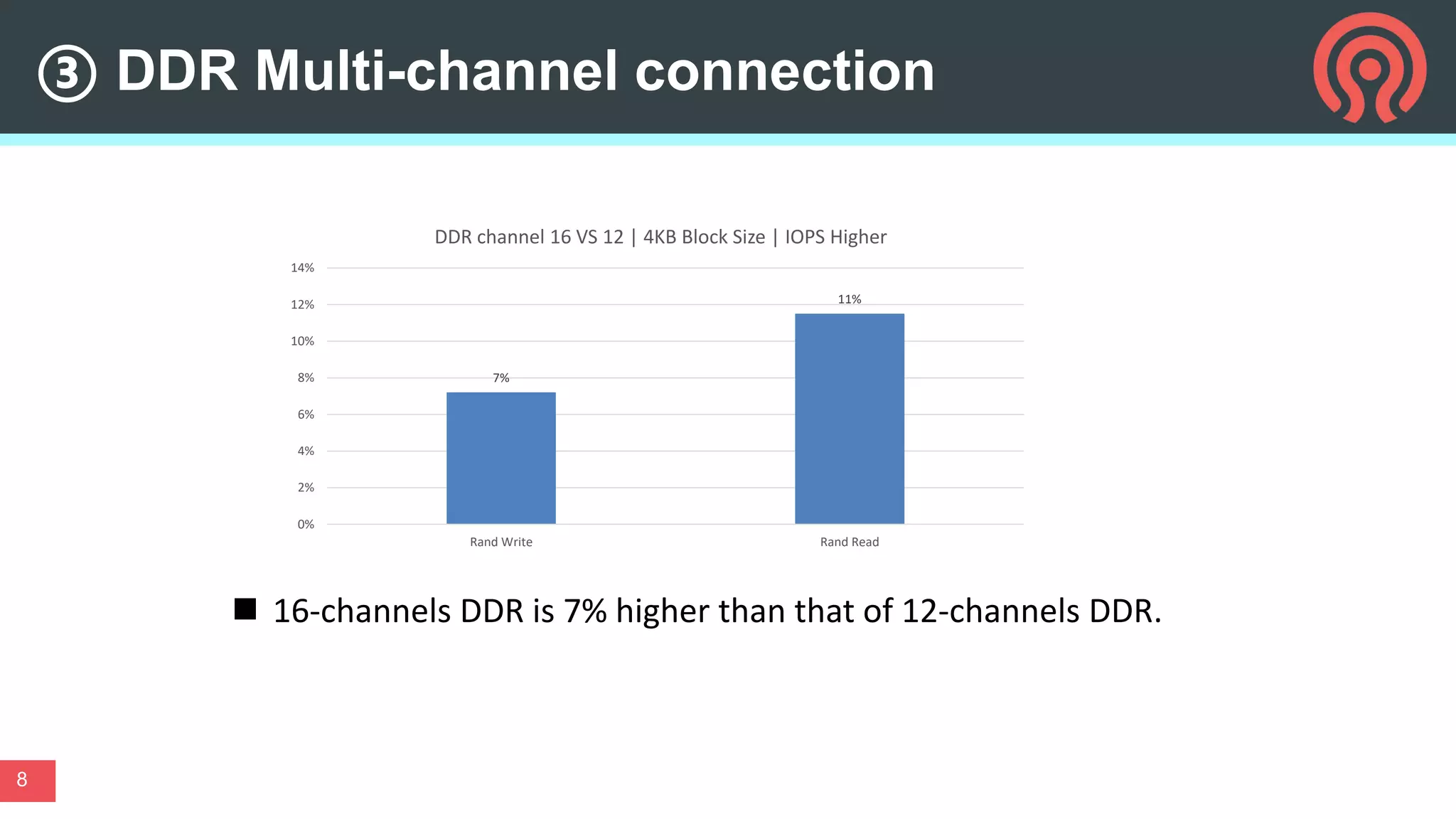
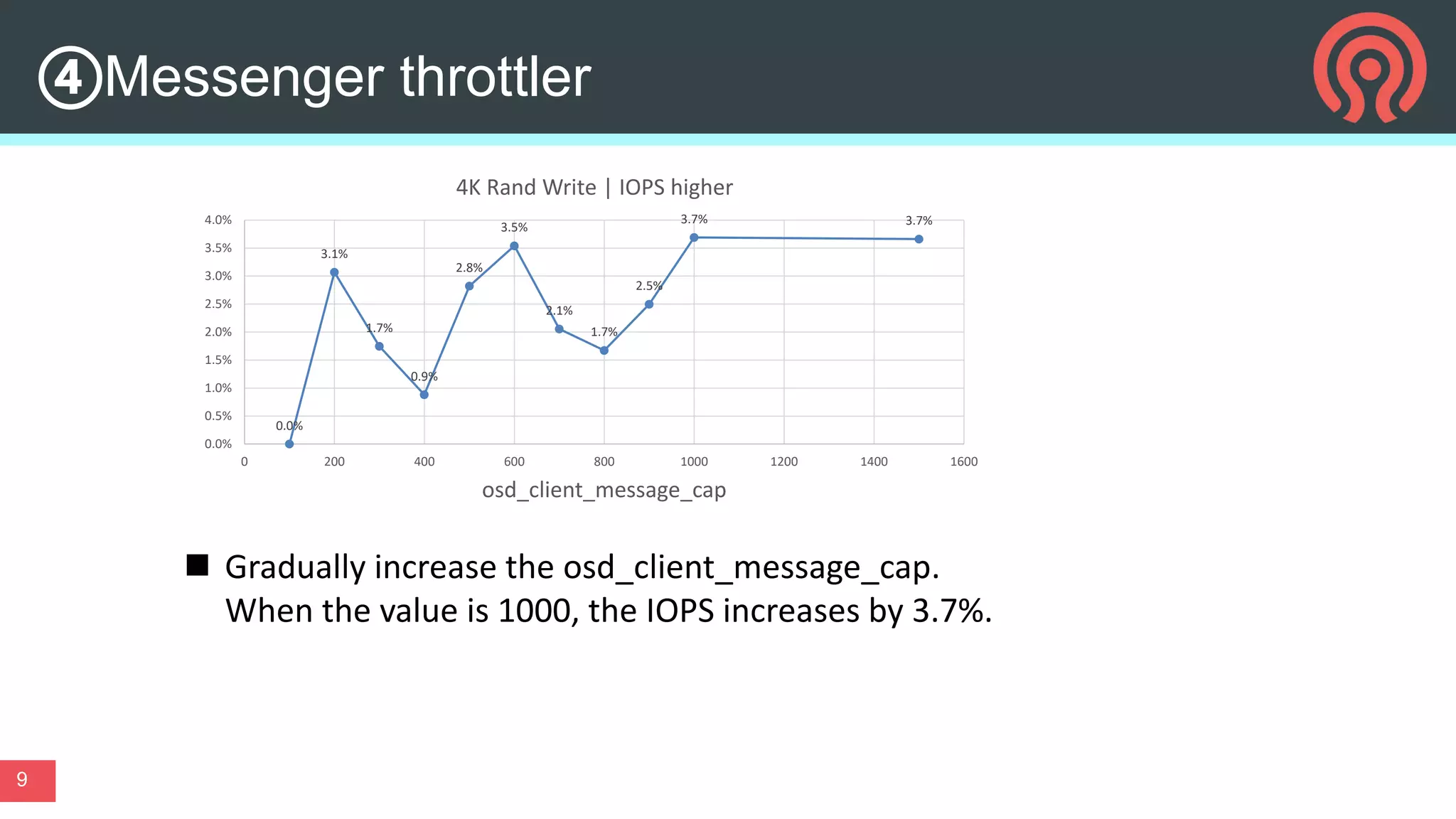
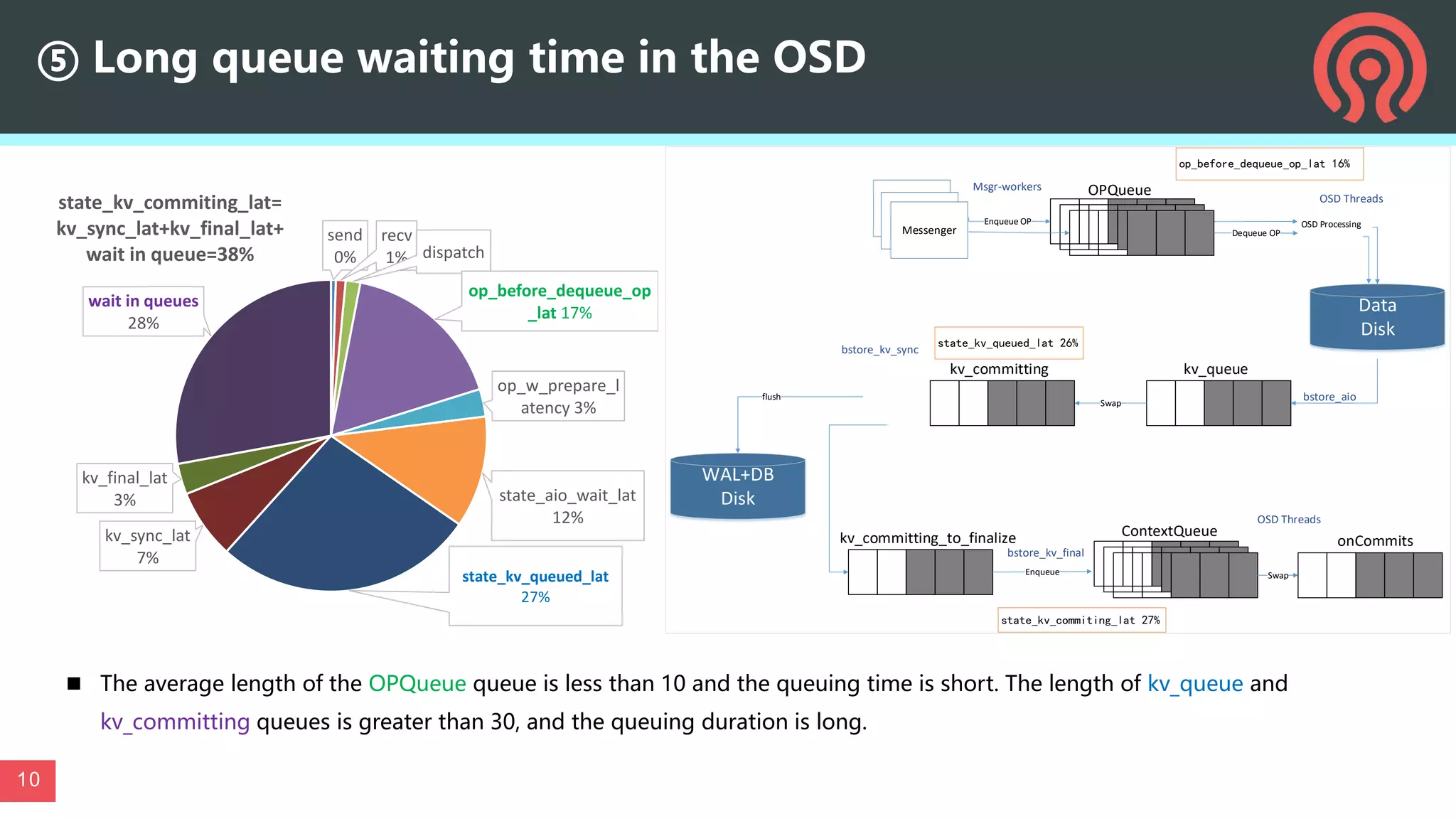


This document discusses performance optimization techniques for All Flash storage systems based on ARM architecture processors. It provides details on: - The processor used, which is the Kunpeng920 ARM-based CPU with 32-64 cores at 2.6-3.0GHz, along with its memory and I/O controllers. - Optimizing performance through both software and hardware techniques, including improving CPU usage, I/O performance, and network performance. - Specific optimization techniques like data placement to reduce cross-NUMA access, multi-port NIC deployment, using multiple DDR channels, adjusting messaging throttling, and optimizing queue wait times in the object storage daemon (OSD). - Other



























![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)























![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)








