Downloaded 83 times



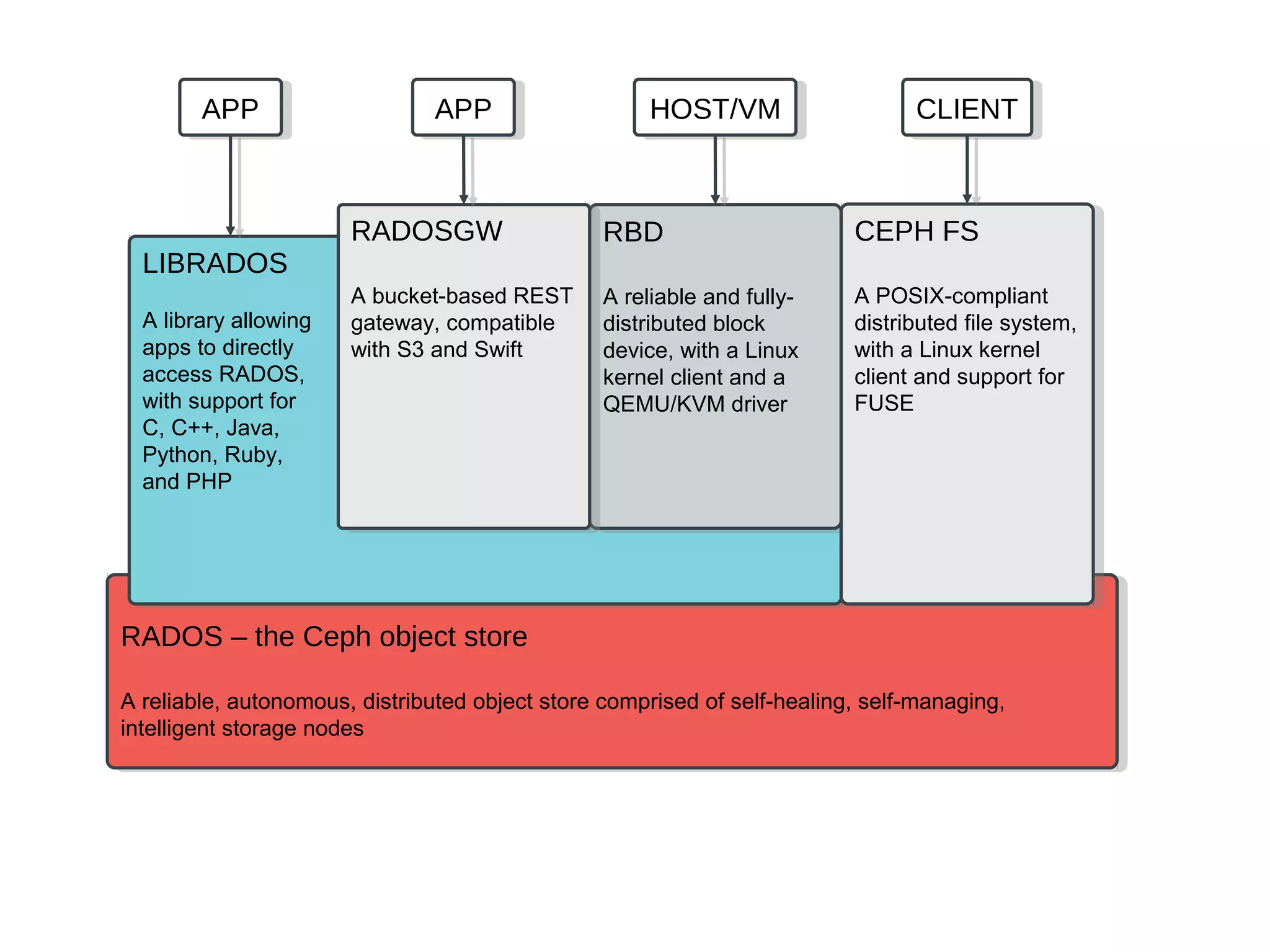
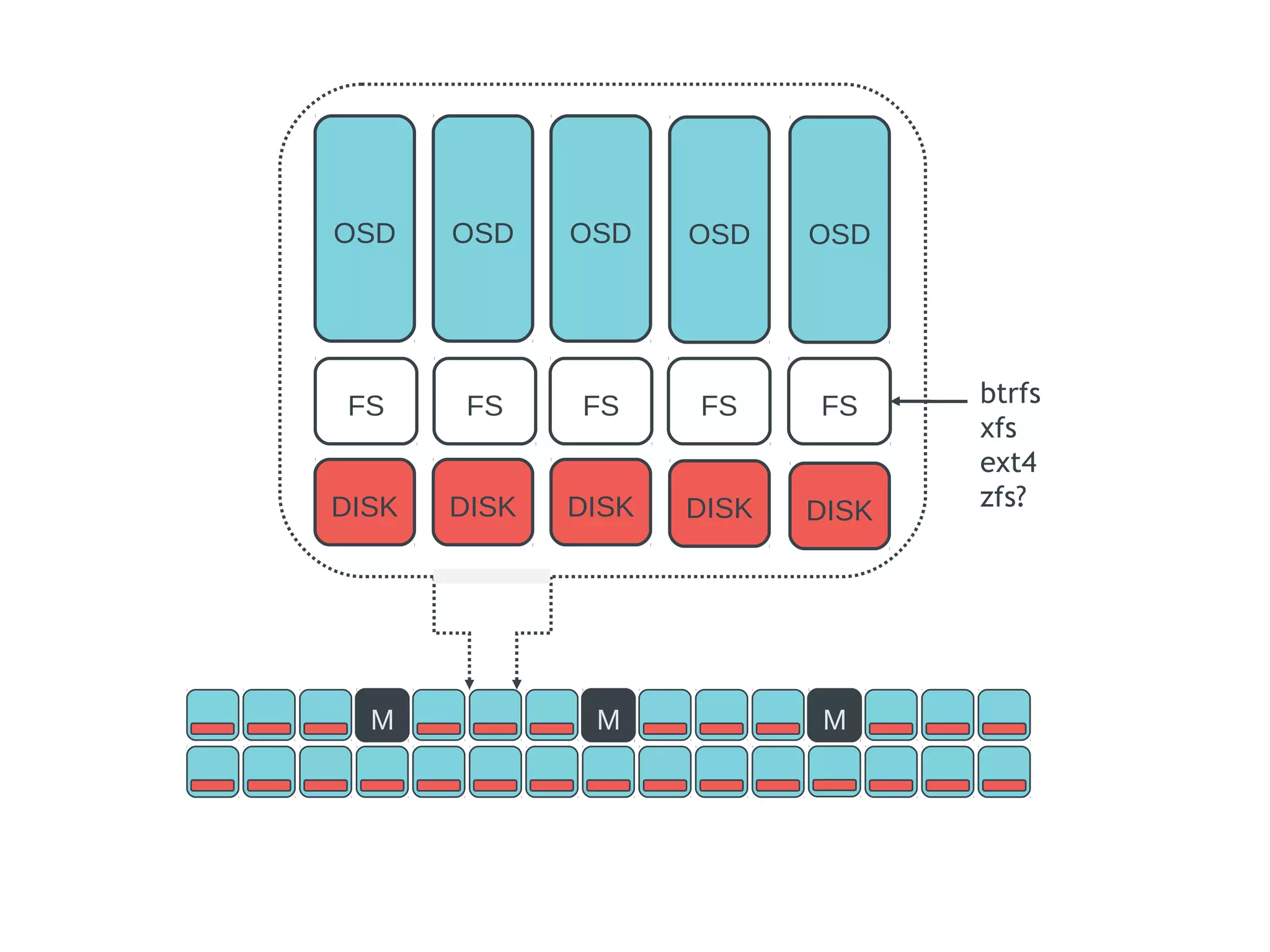
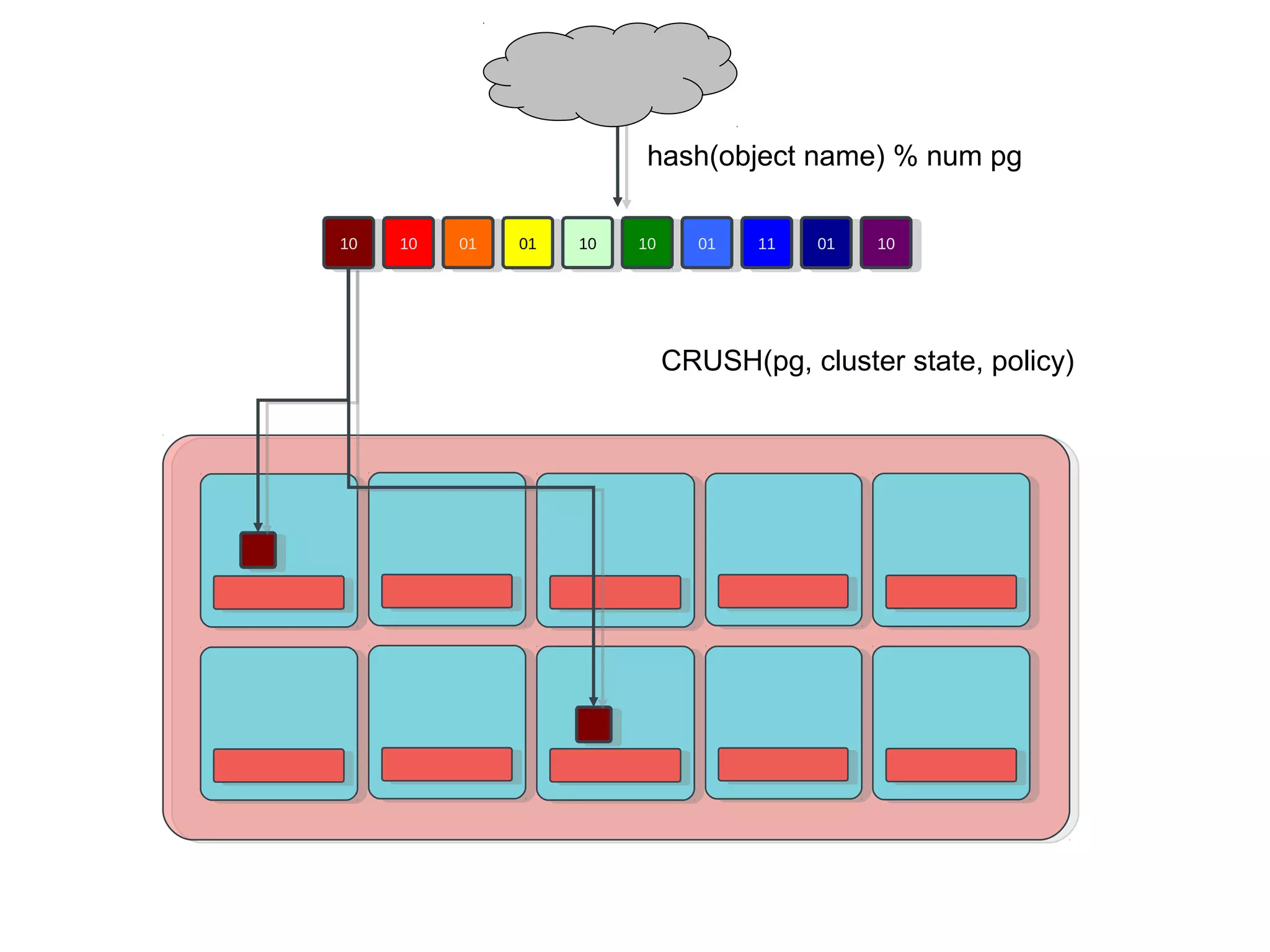
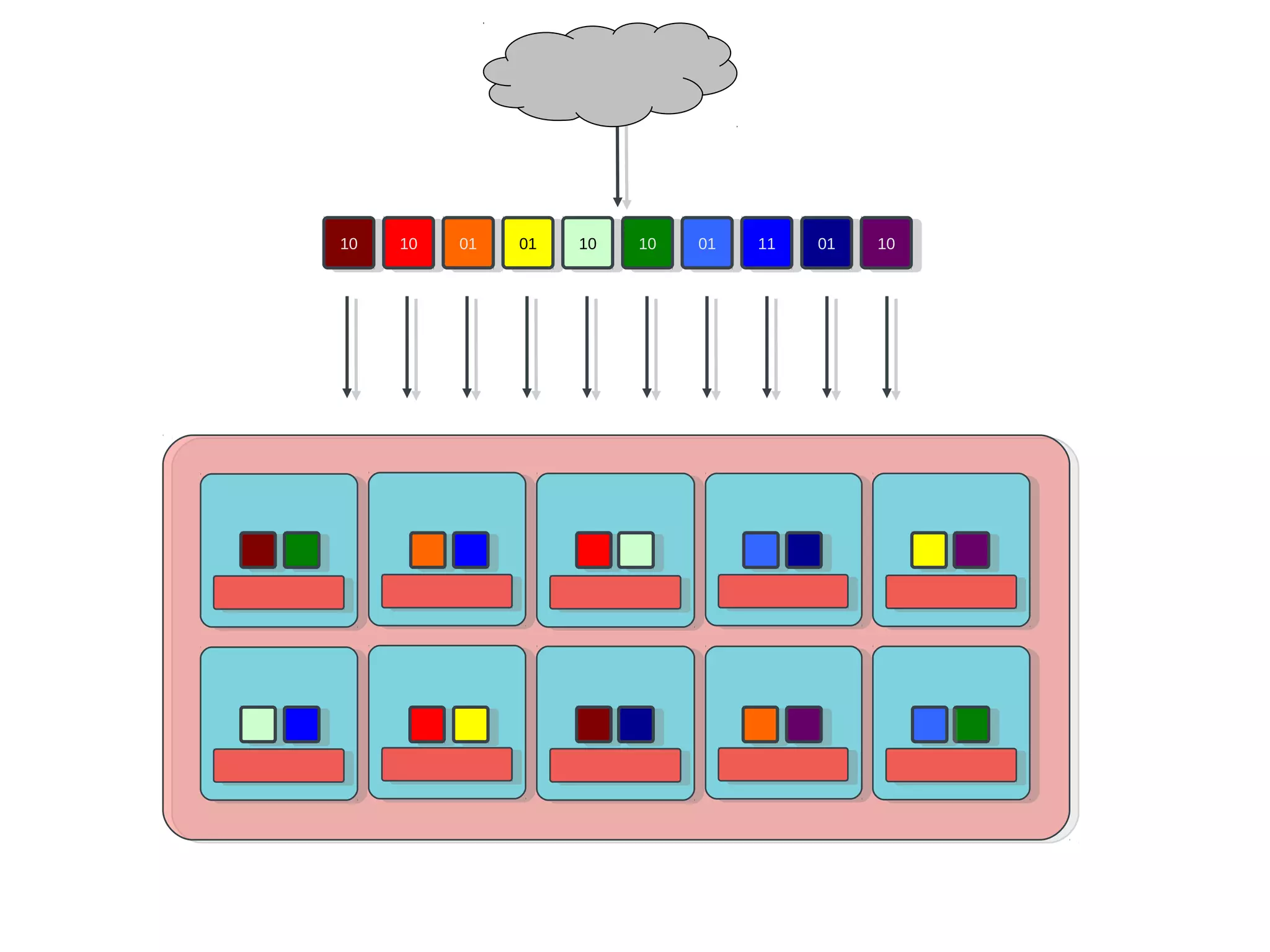
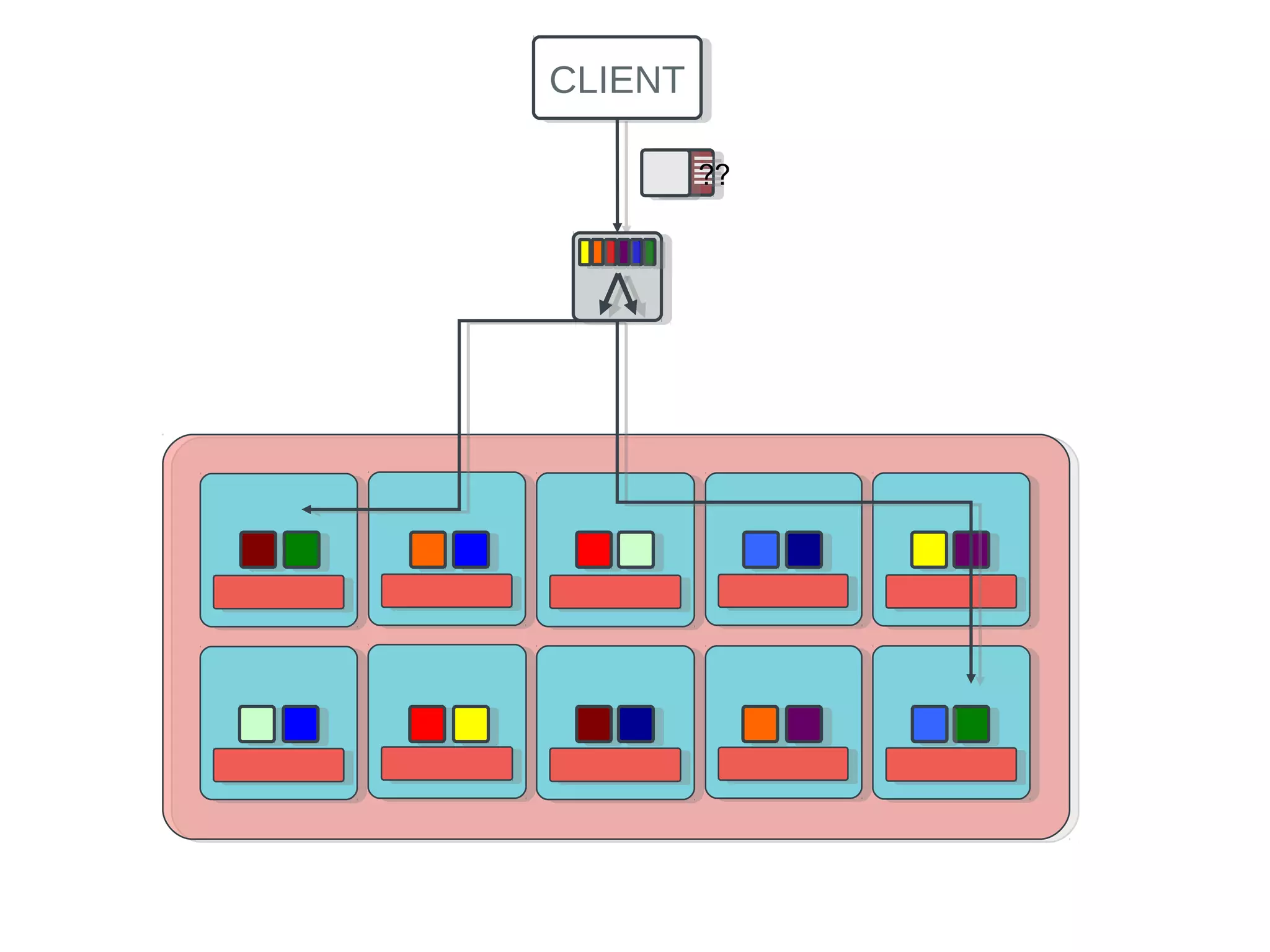
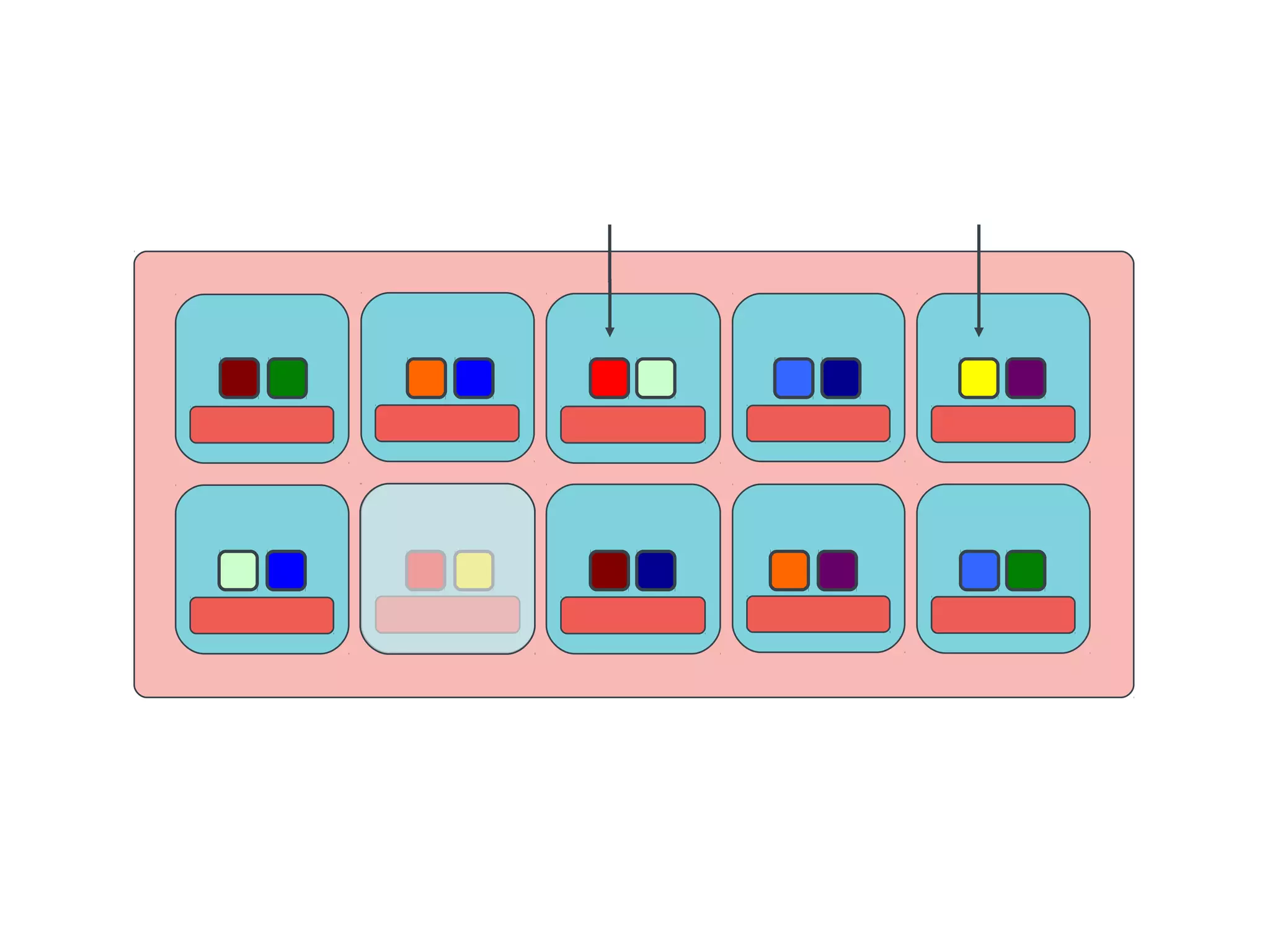
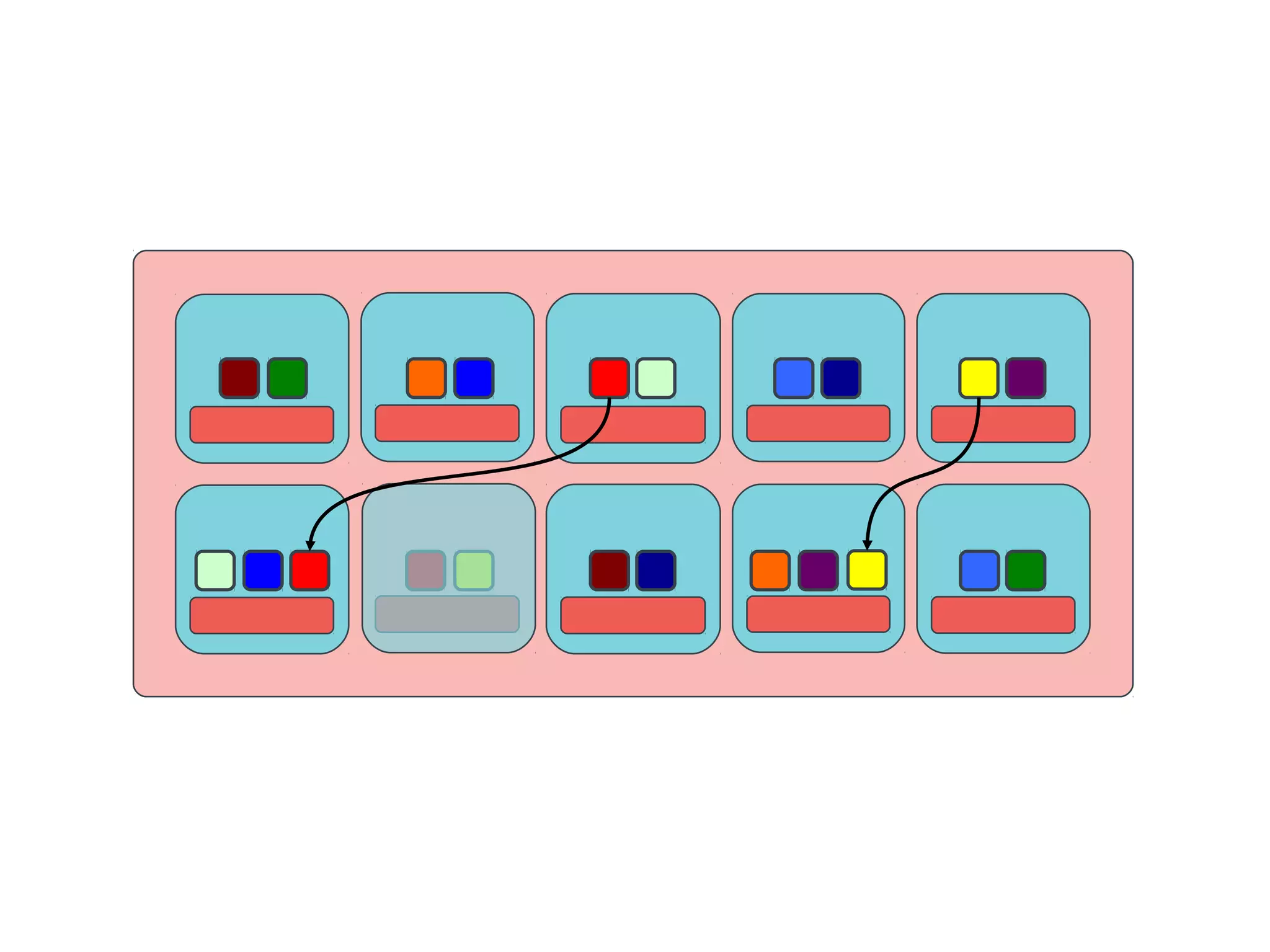
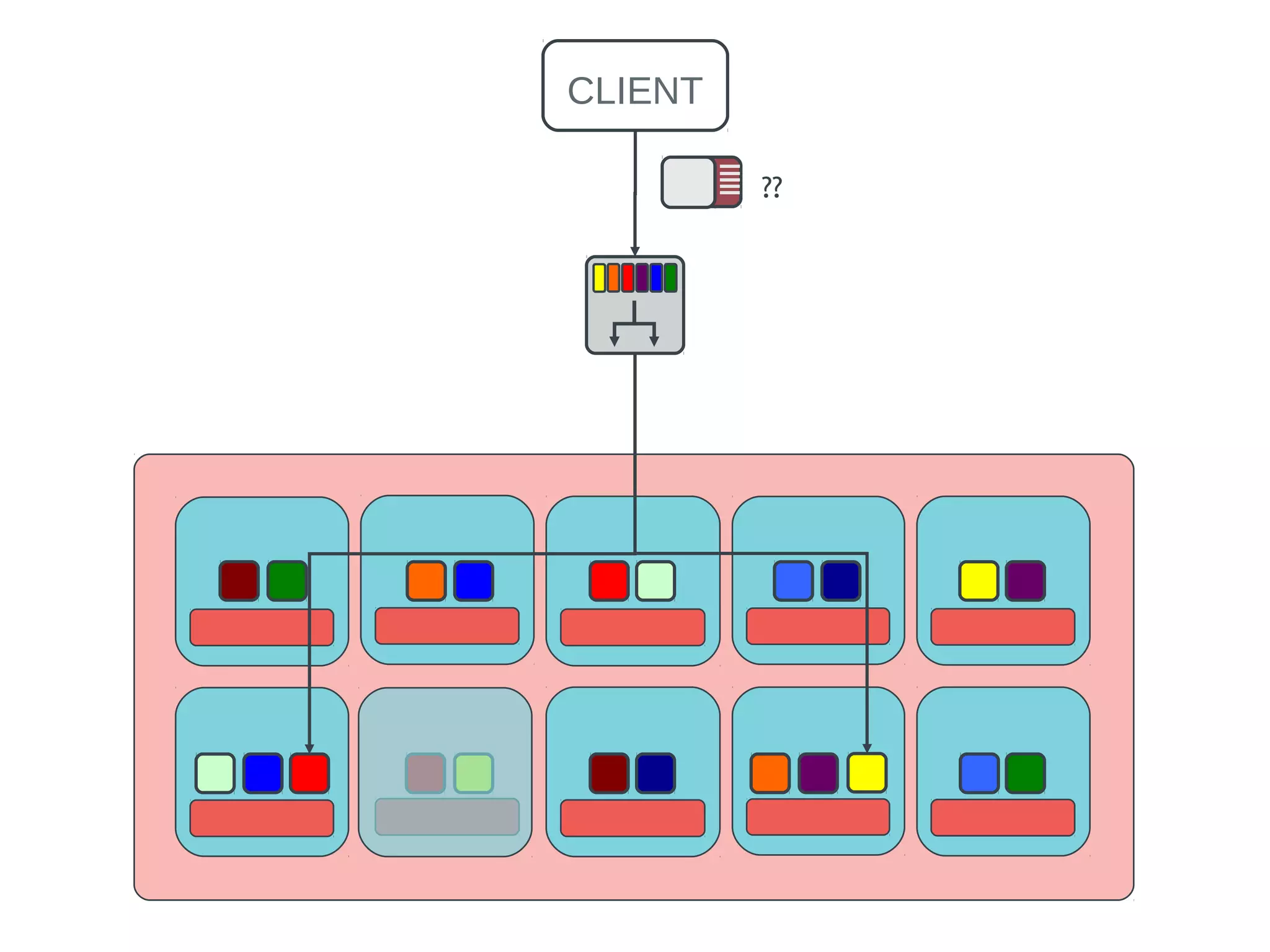





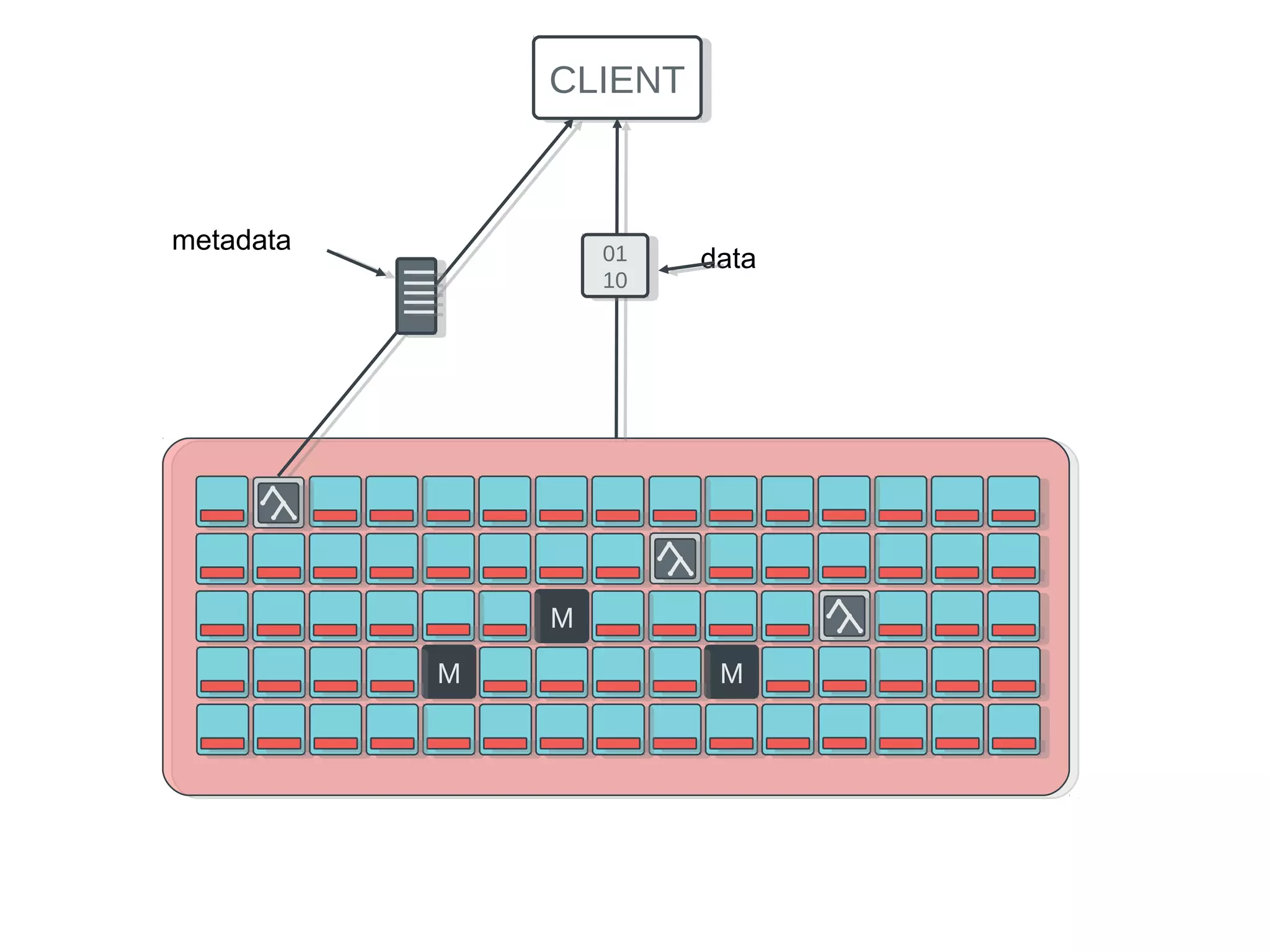

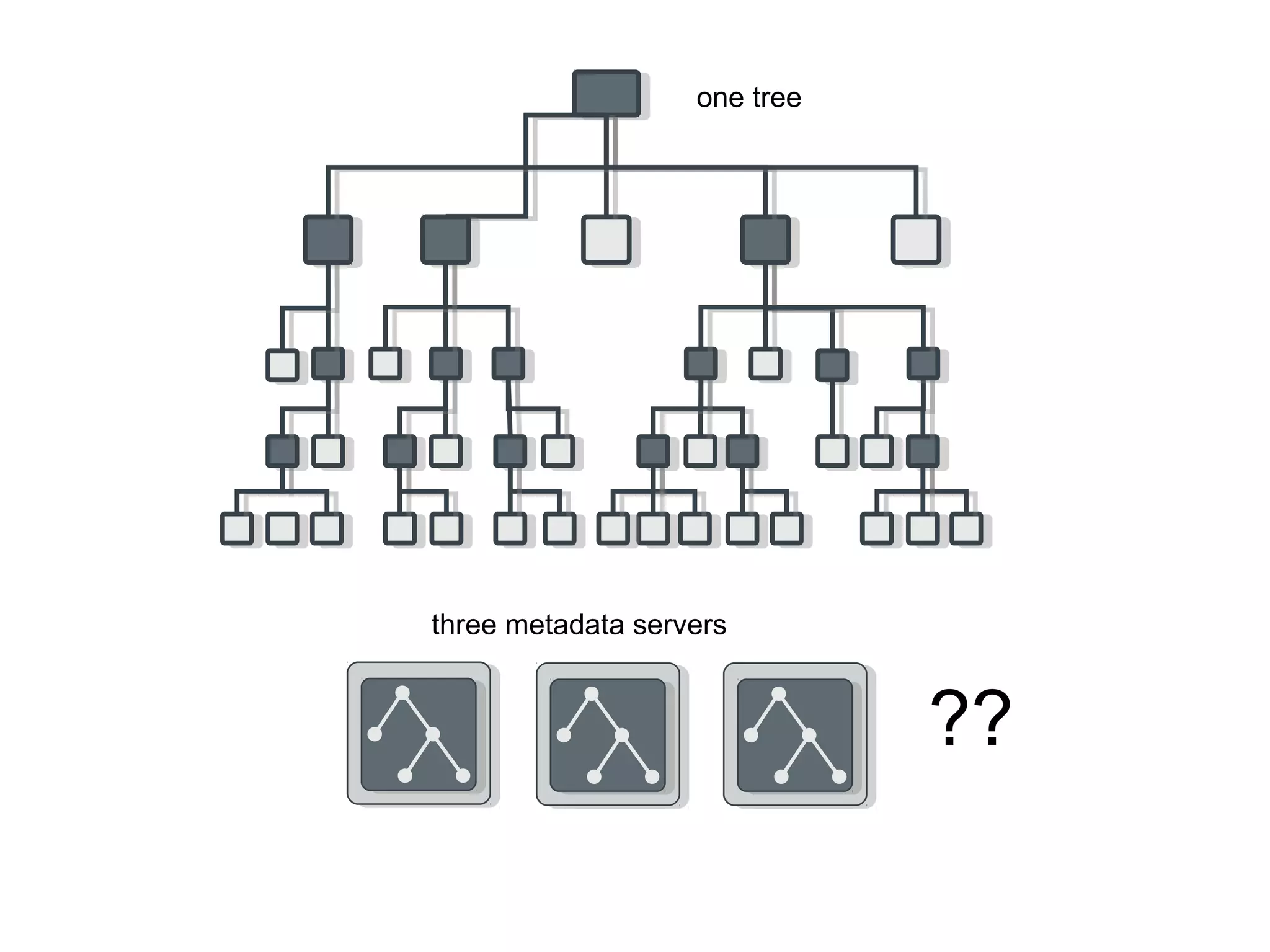
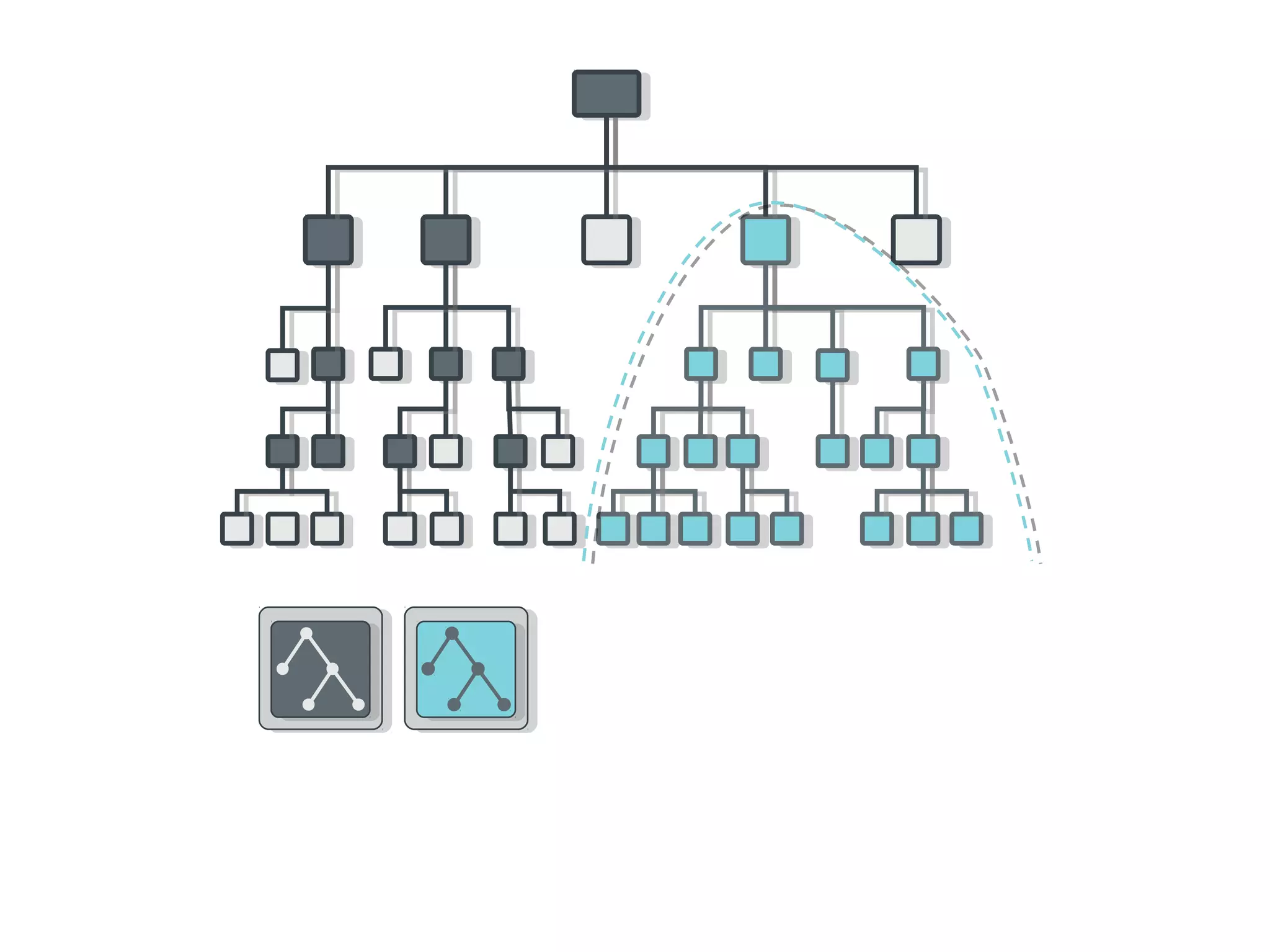
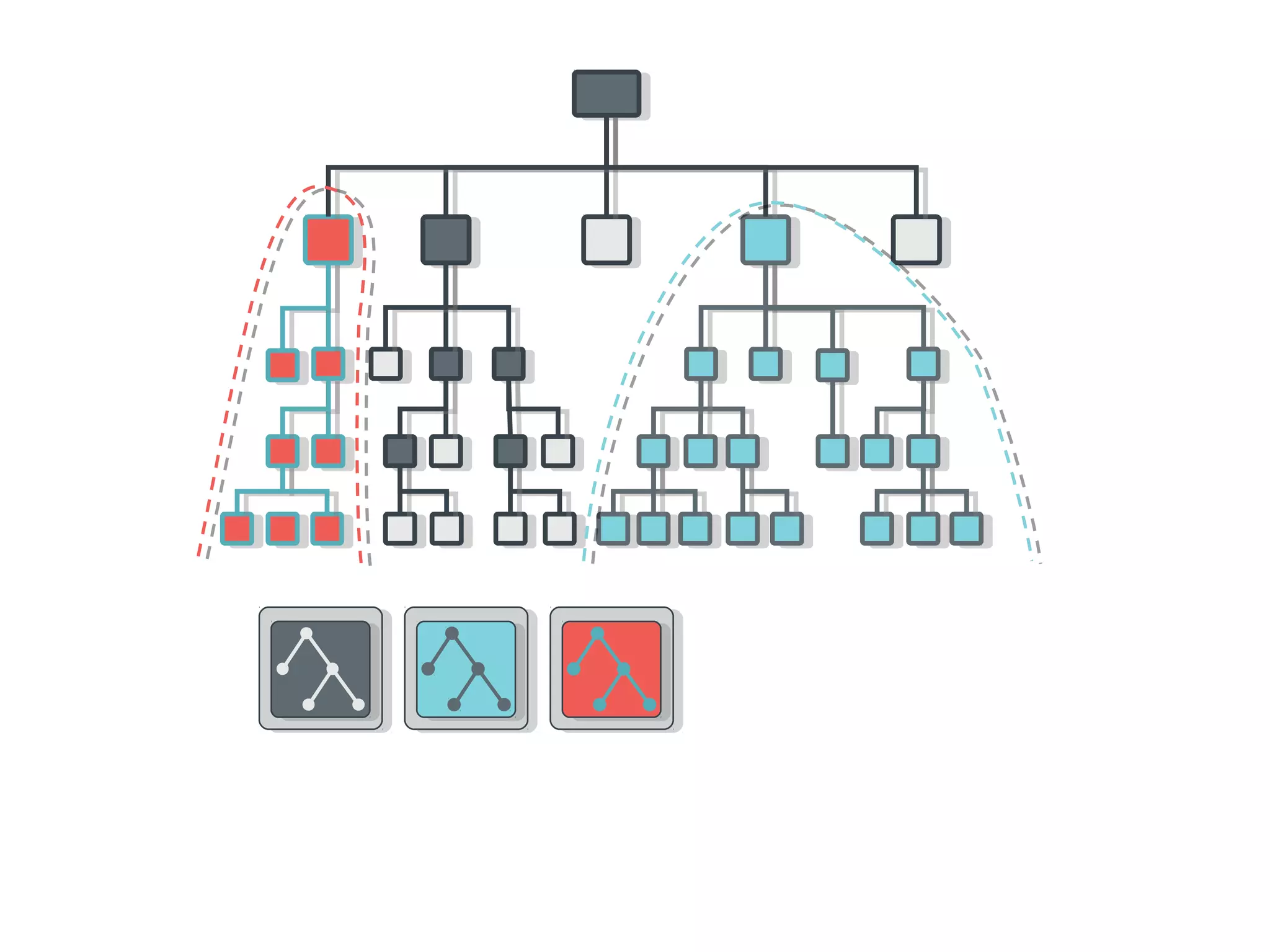
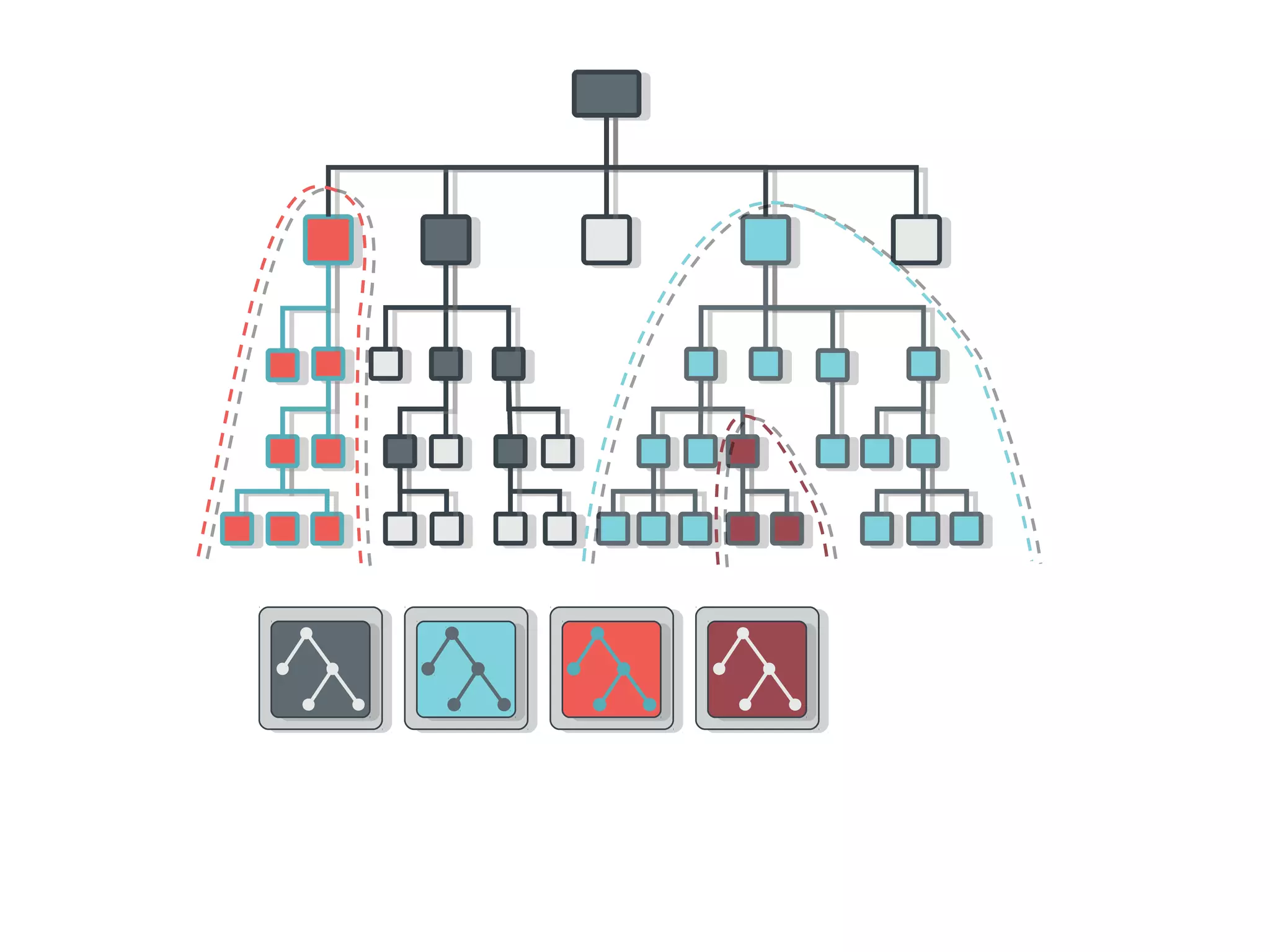
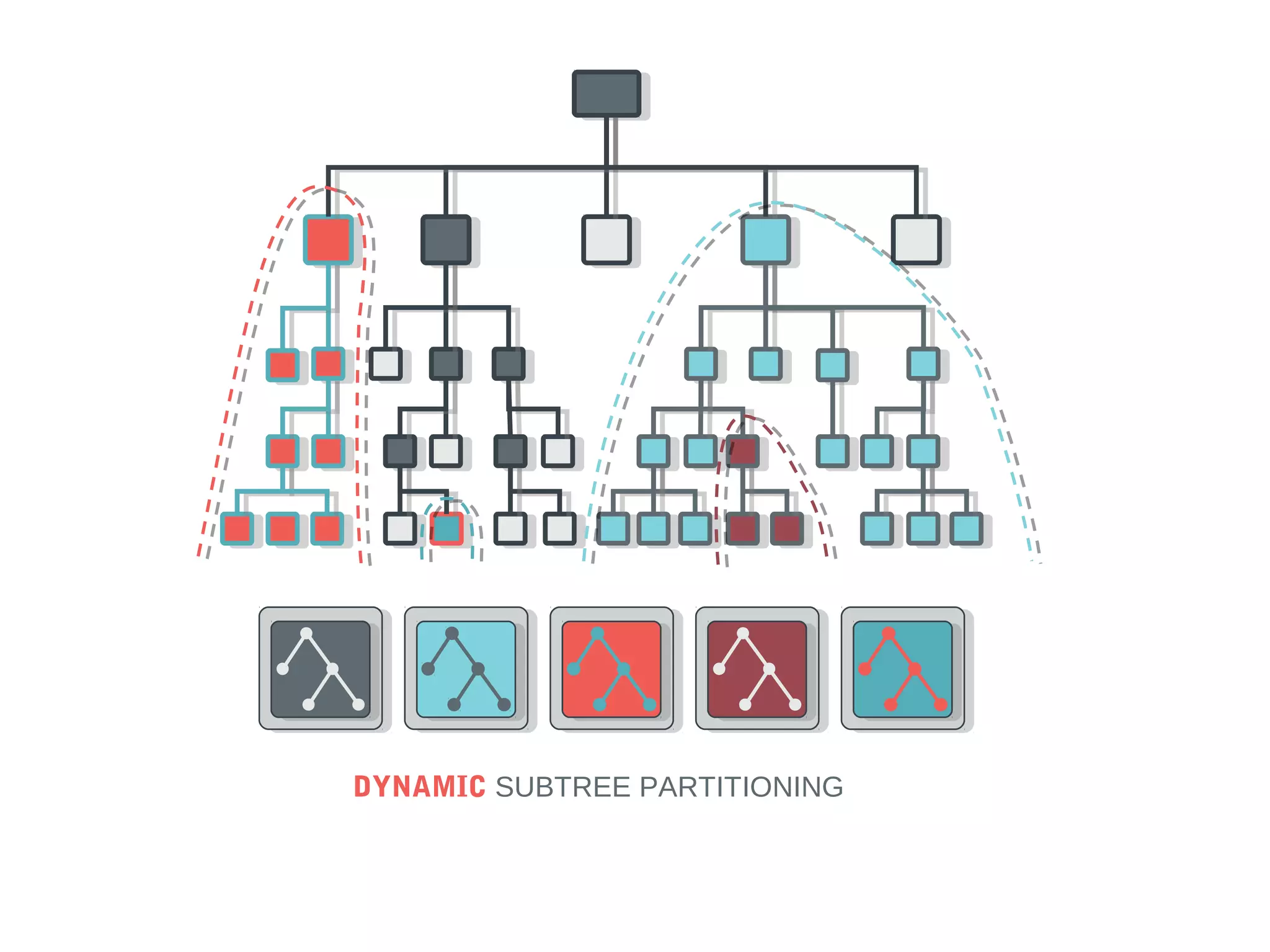






Ceph is an open-source distributed storage system that provides scalable object, block, and file storage in a single unified platform. It uses a technique called CRUSH to automatically distribute data across clusters of commodity servers and provides self-healing capabilities through data replication. Ceph's unified storage platform includes RADOS, an object store; RBD for block storage; CephFS for distributed file storage; and RADOSGW for cloud storage compatibility. It is designed for large-scale deployments of 10s to 10,000s of nodes using heterogeneous hardware.





































































































