Download to read offline






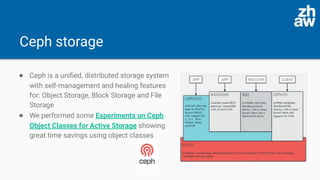



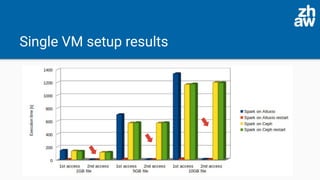
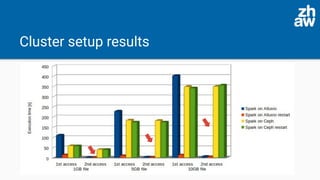
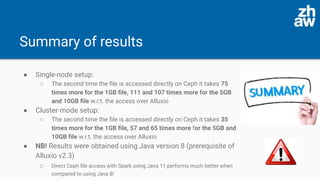
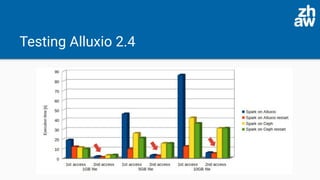




The presentation discusses the acceleration of data computation using Ceph objects and Alluxio, highlighting the increasing demand for efficient data storage solutions amidst a growing global storage market. Experiments demonstrated significant improvements in data access times using Alluxio compared to direct Ceph access, with Alluxio 2.4 resolving previous performance limitations by supporting Java 11. The findings indicate that Alluxio can enhance memory-speed data access, leading to substantial efficiency gains in both single-node and cluster setups.




















































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)


