Download to read offline

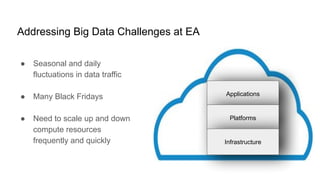



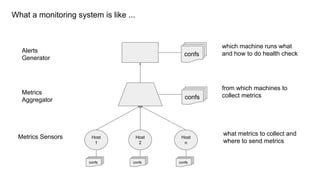

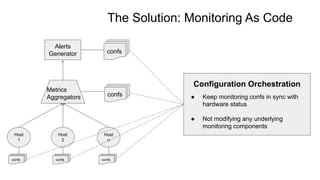
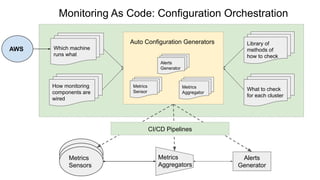

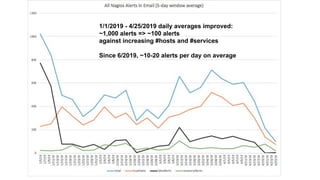

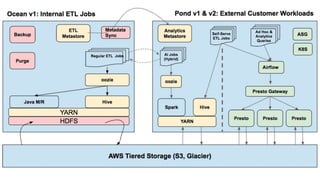
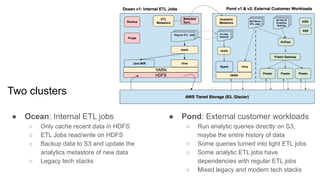
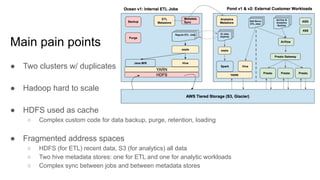

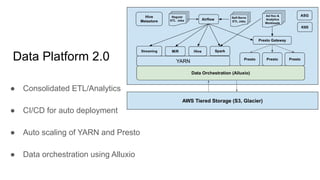






The document discusses strategies for developing and operating cloud-native data platforms and applications, highlighting challenges such as data traffic fluctuations and operational inefficiencies in DevOps. It proposes solutions like monitoring as code and data orchestration using Alluxio to enhance performance and simplify management. Key takeaways emphasize the shift towards automation in cloud computing, aiming for more efficient development and operational workflows.













































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)









