Download as PDF, PPTX









![Create Table
ALLUXIO 19
create table iceberg.test.test1 with
(format = 'PARQUET', partitioning =
ARRAY['c_birth_month']) as
SELECT
c_customer_sk,
c_birth_day,
c_birth_month
FROM
tpcds.sf100.customer](https://image.slidesharecdn.com/alluxiodayslides1-211216012931/75/Iceberg-Alluxio-for-Fast-Data-Analytics-19-2048.jpg)









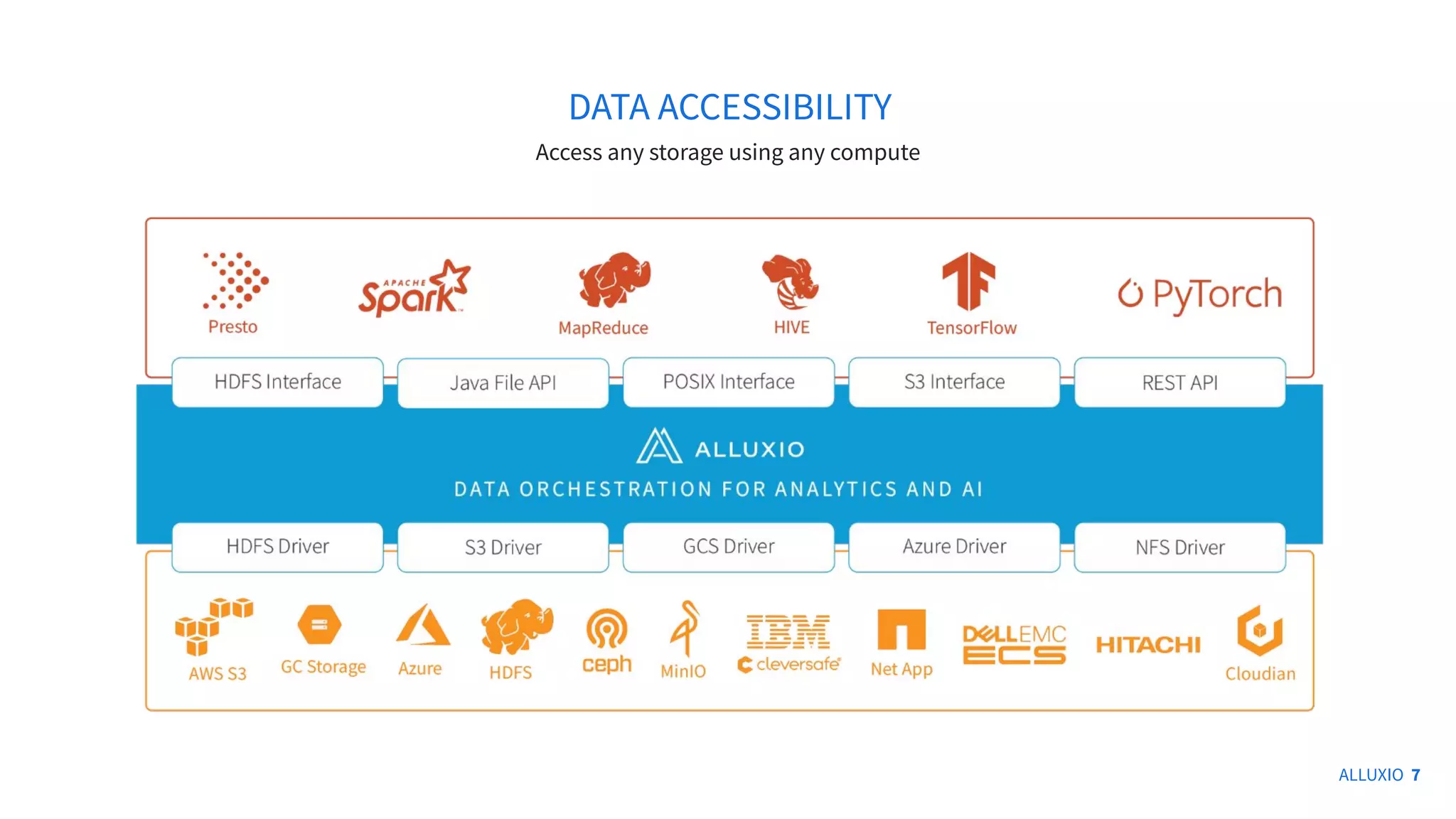
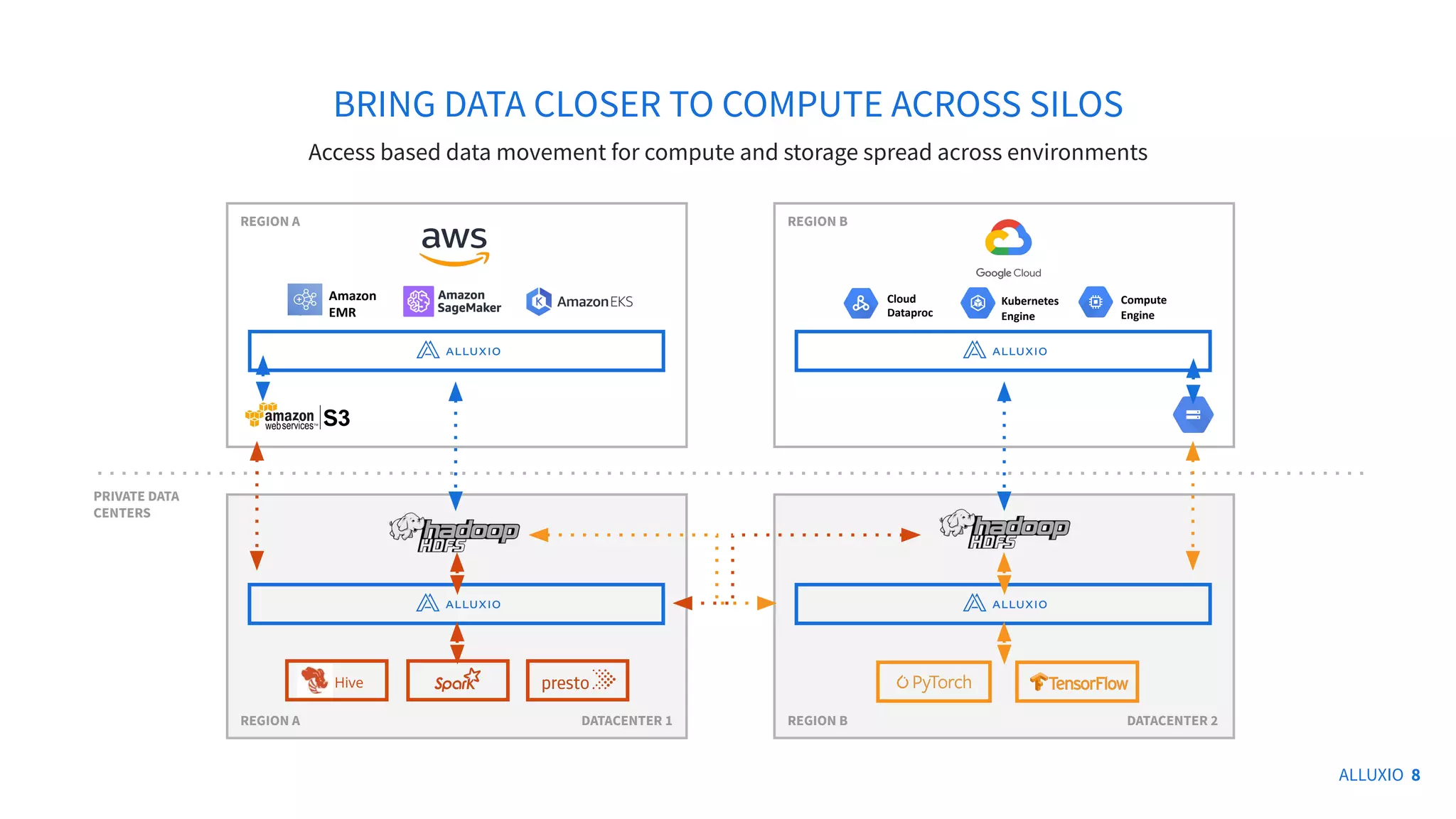
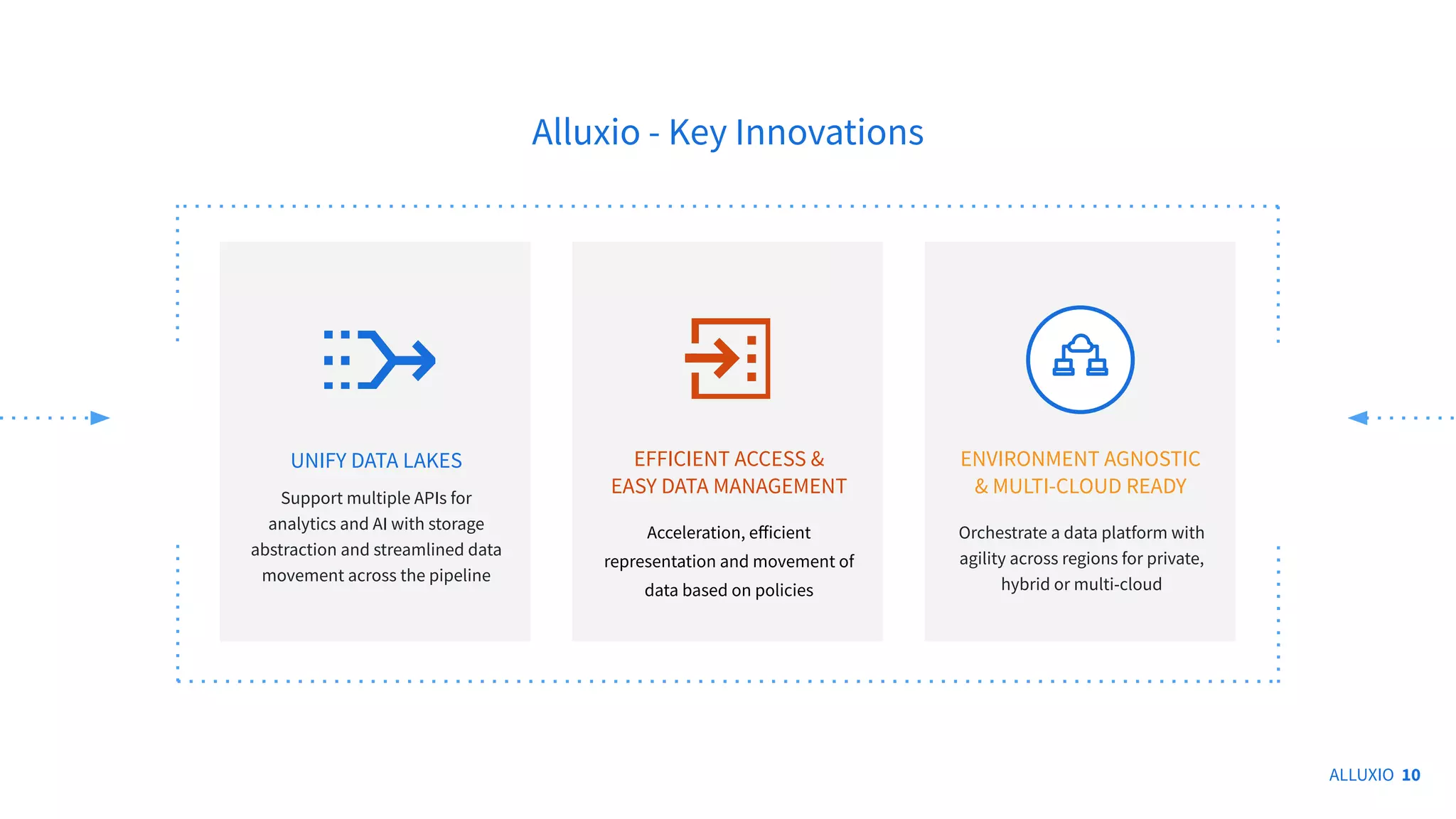
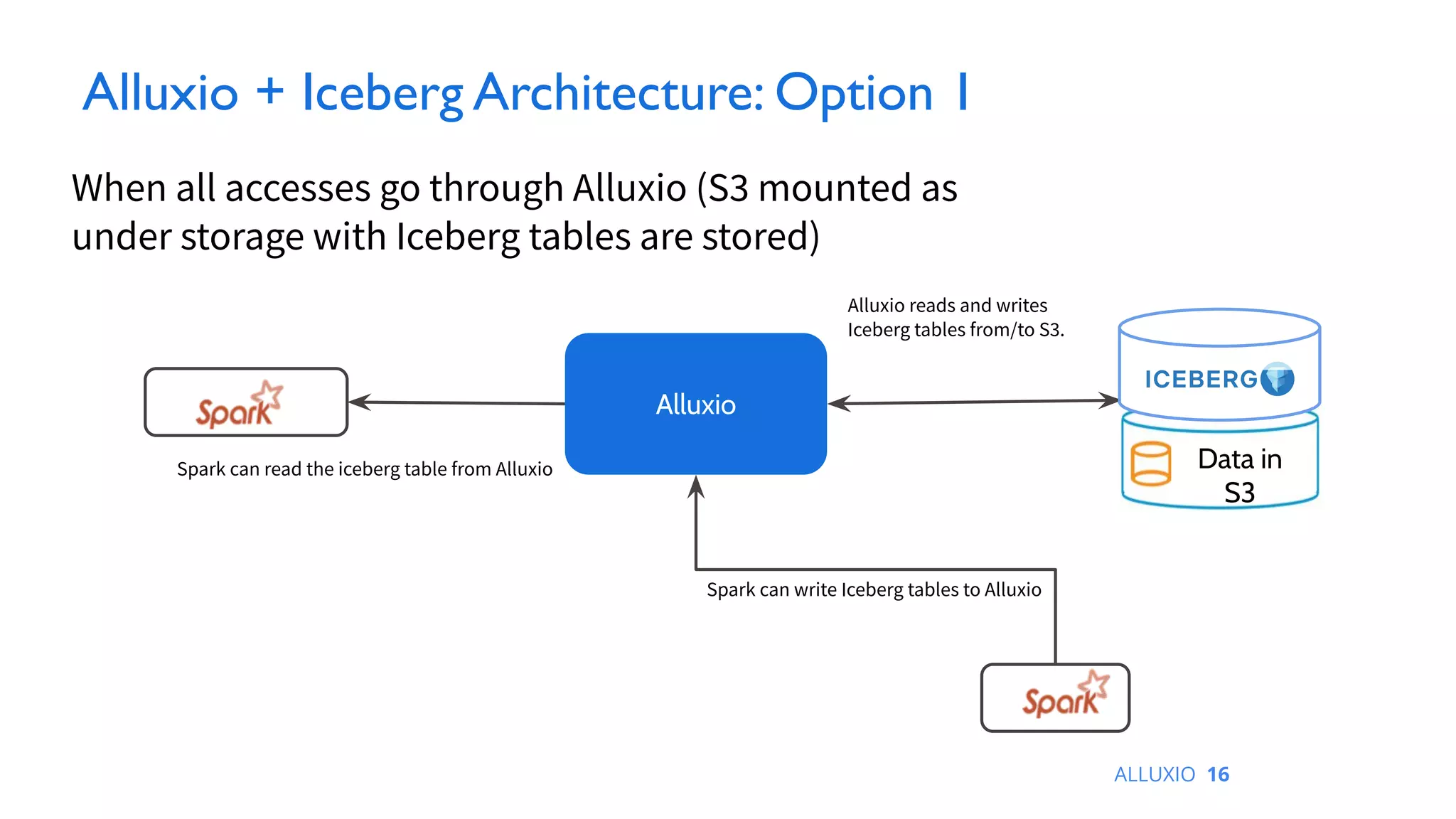
The document presents a discussion on integrating Alluxio with Iceberg for improved data analytics performance, highlighting benefits like enhanced I/O efficiency and simplified management. Key innovations of Alluxio include data orchestration across various cloud environments and support for multiple APIs aiding analytics and AI. It also covers architectural options for using Iceberg tables with Alluxio, including write types and querying methods.






















































































