Downloaded 17 times













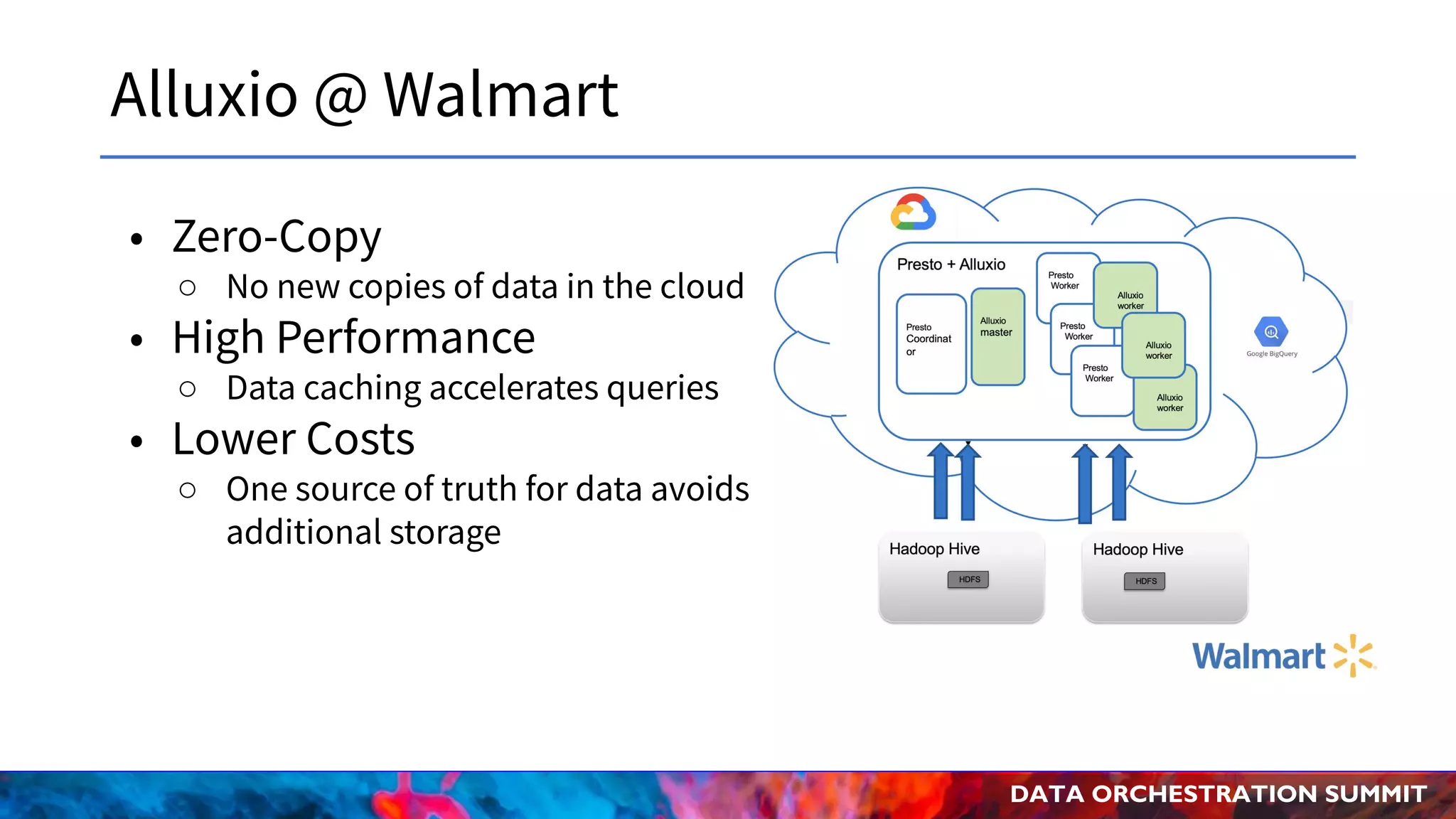




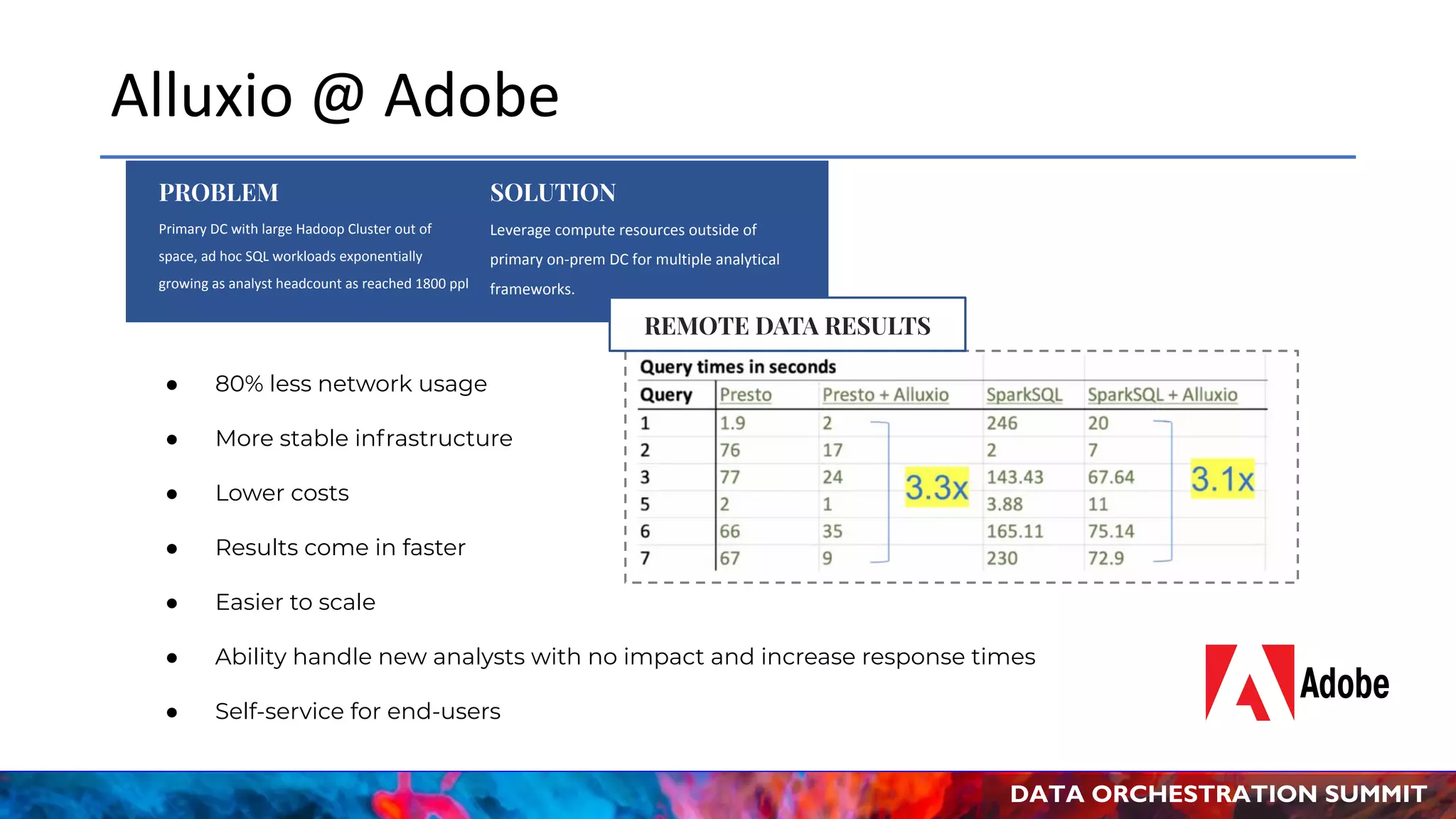













The document discusses the Data Orchestration Summit 2020 hosted by Alluxio, highlighting use cases in cloud and on-prem environments, as well as challenges and solutions related to data orchestration for analytics and AI. It addresses issues like inefficient access to cloud storage, performance inconsistencies, and costly metadata operations, while proposing Alluxio as a solution to enhance performance and cost-effectiveness across various deployment scenarios. Additionally, it emphasizes community involvement and the growing collaboration within the Alluxio open-source ecosystem.























































































