Download as PDF, PPTX


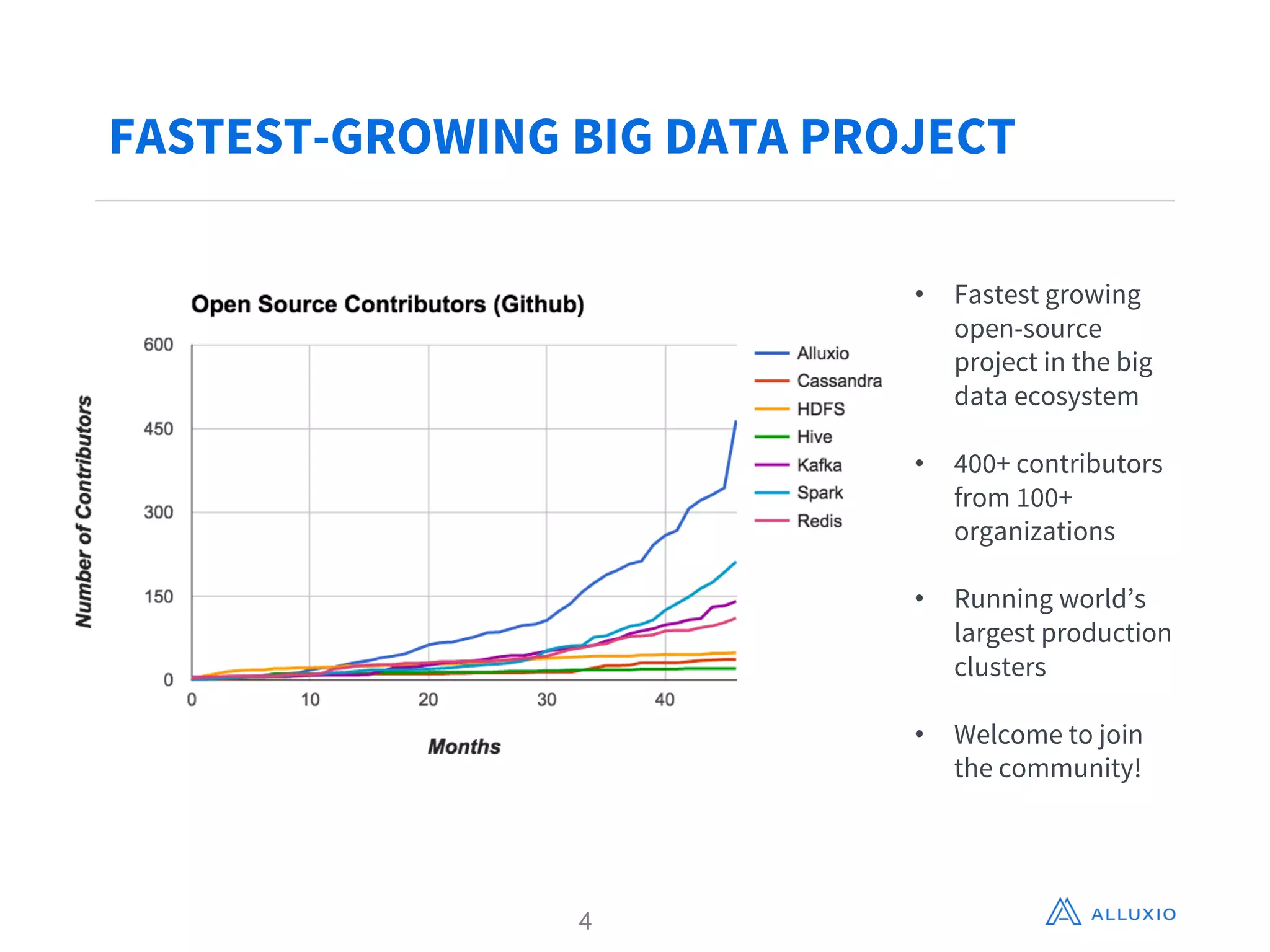
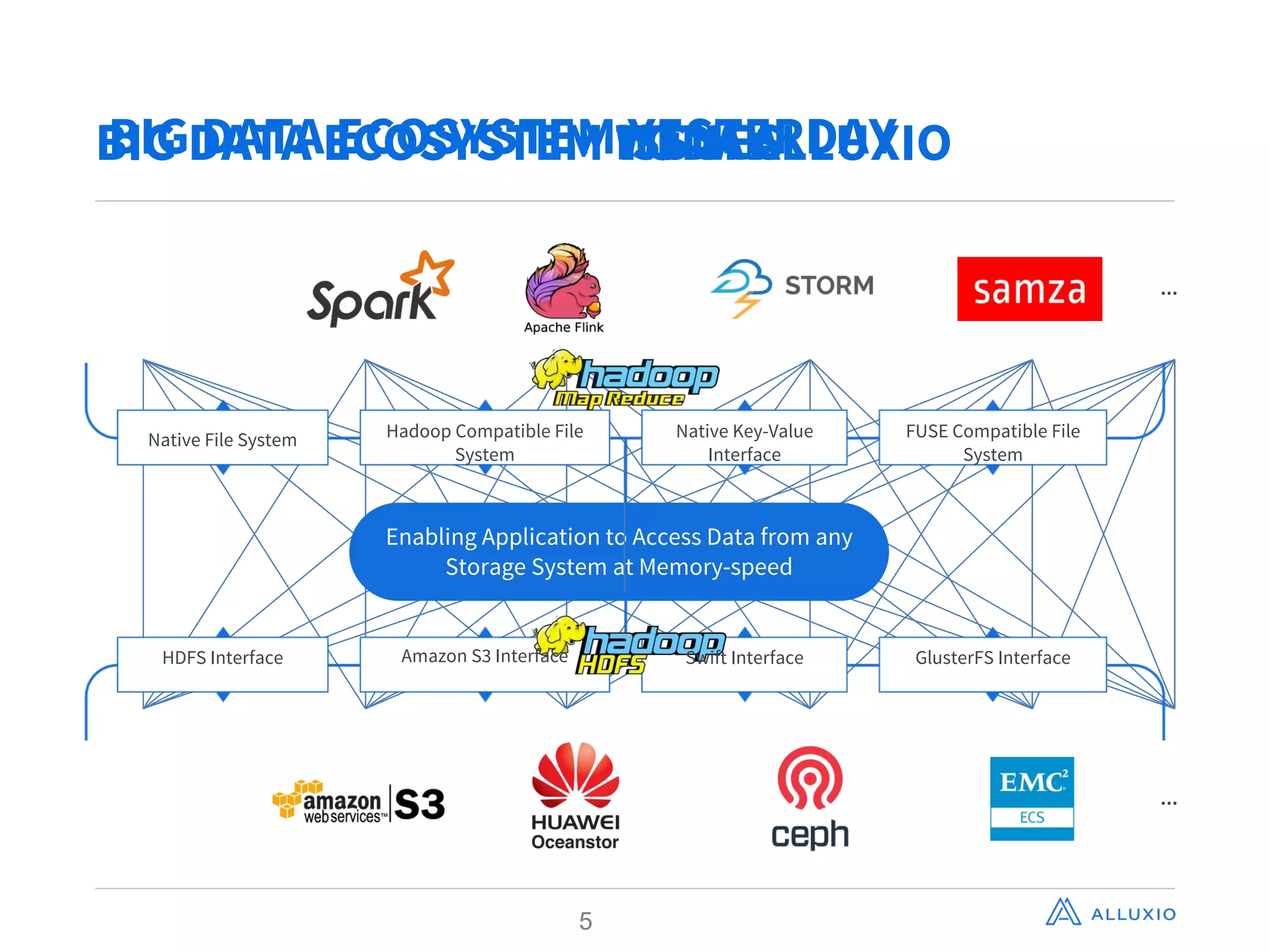



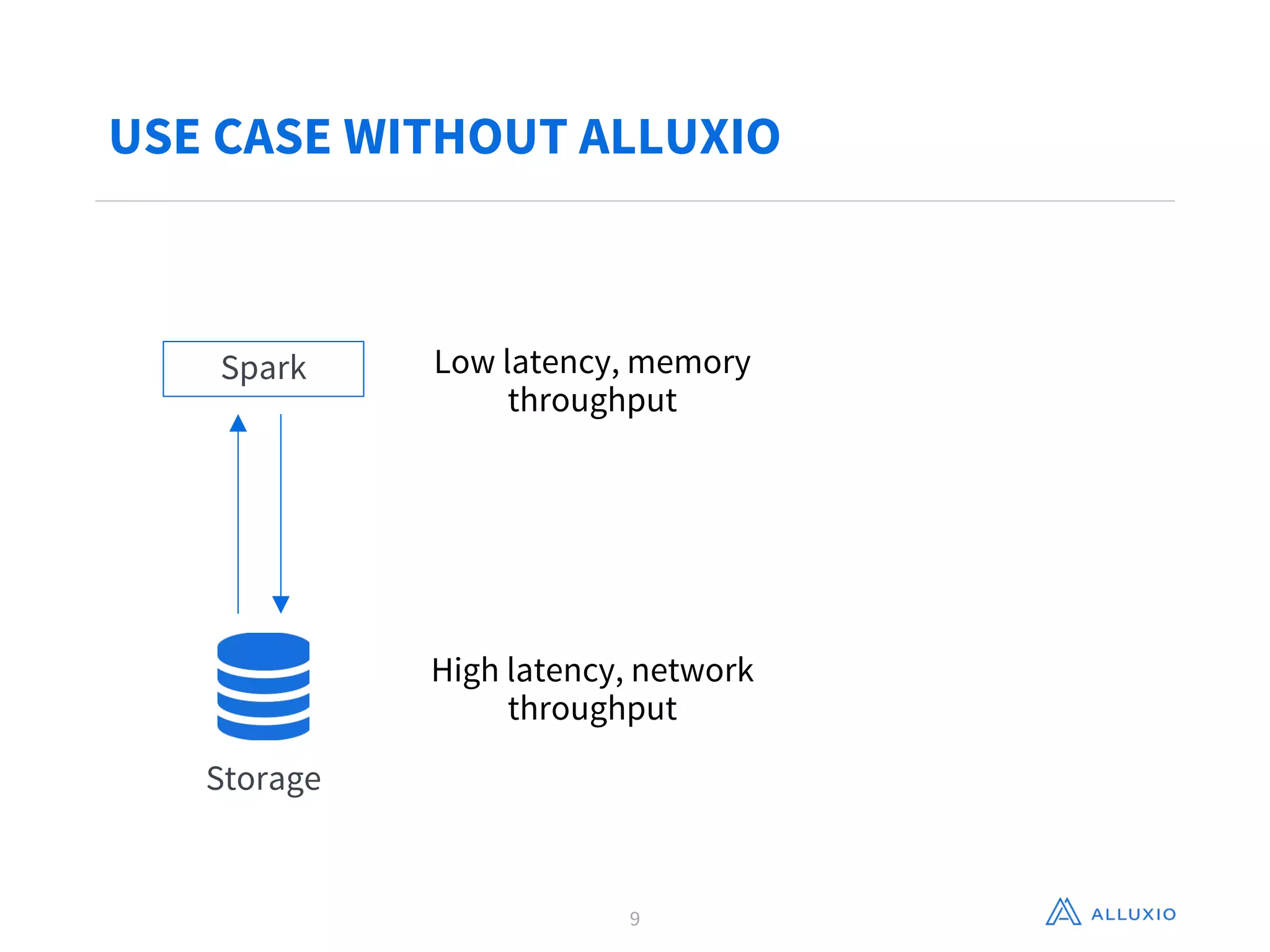
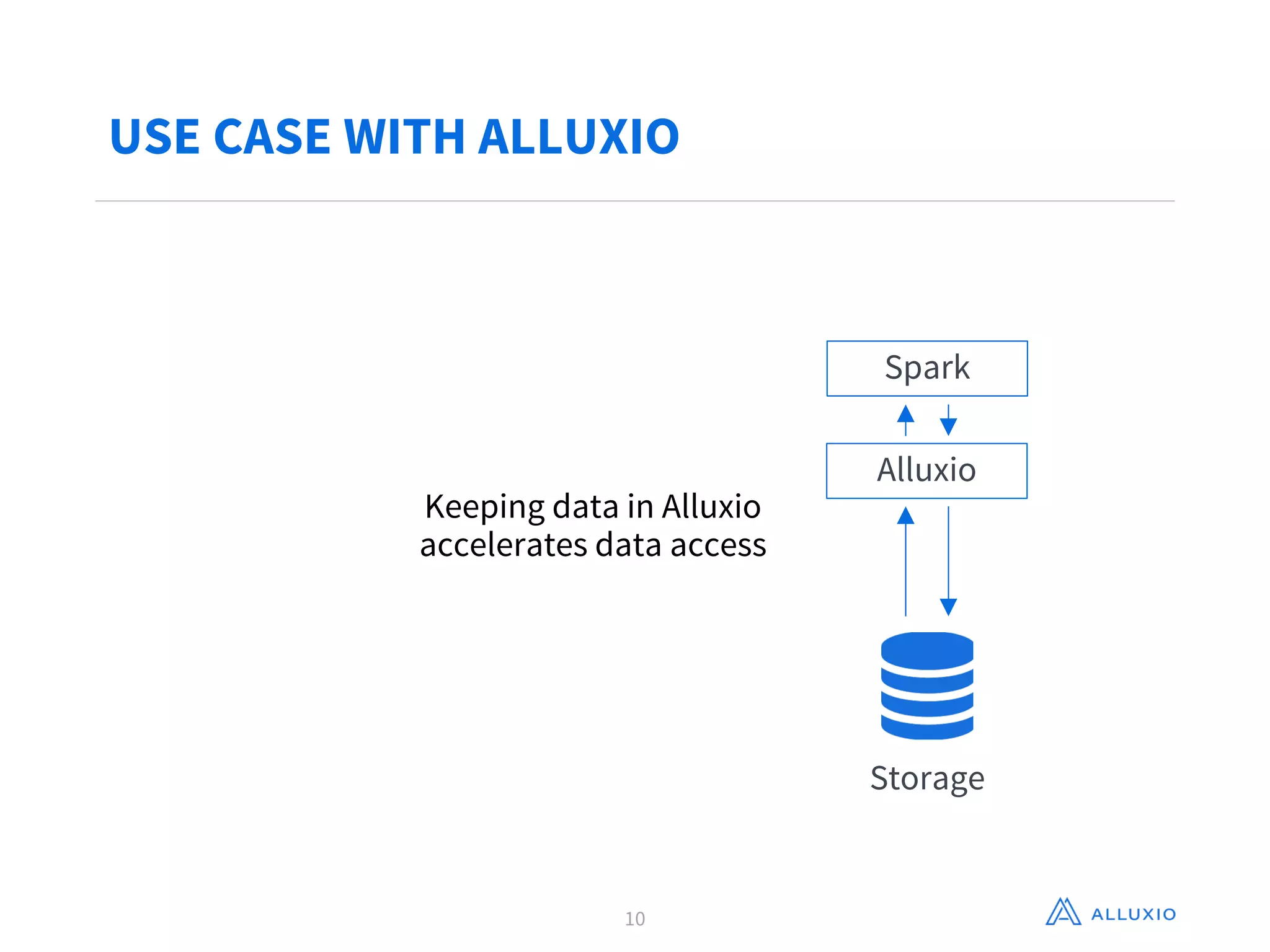






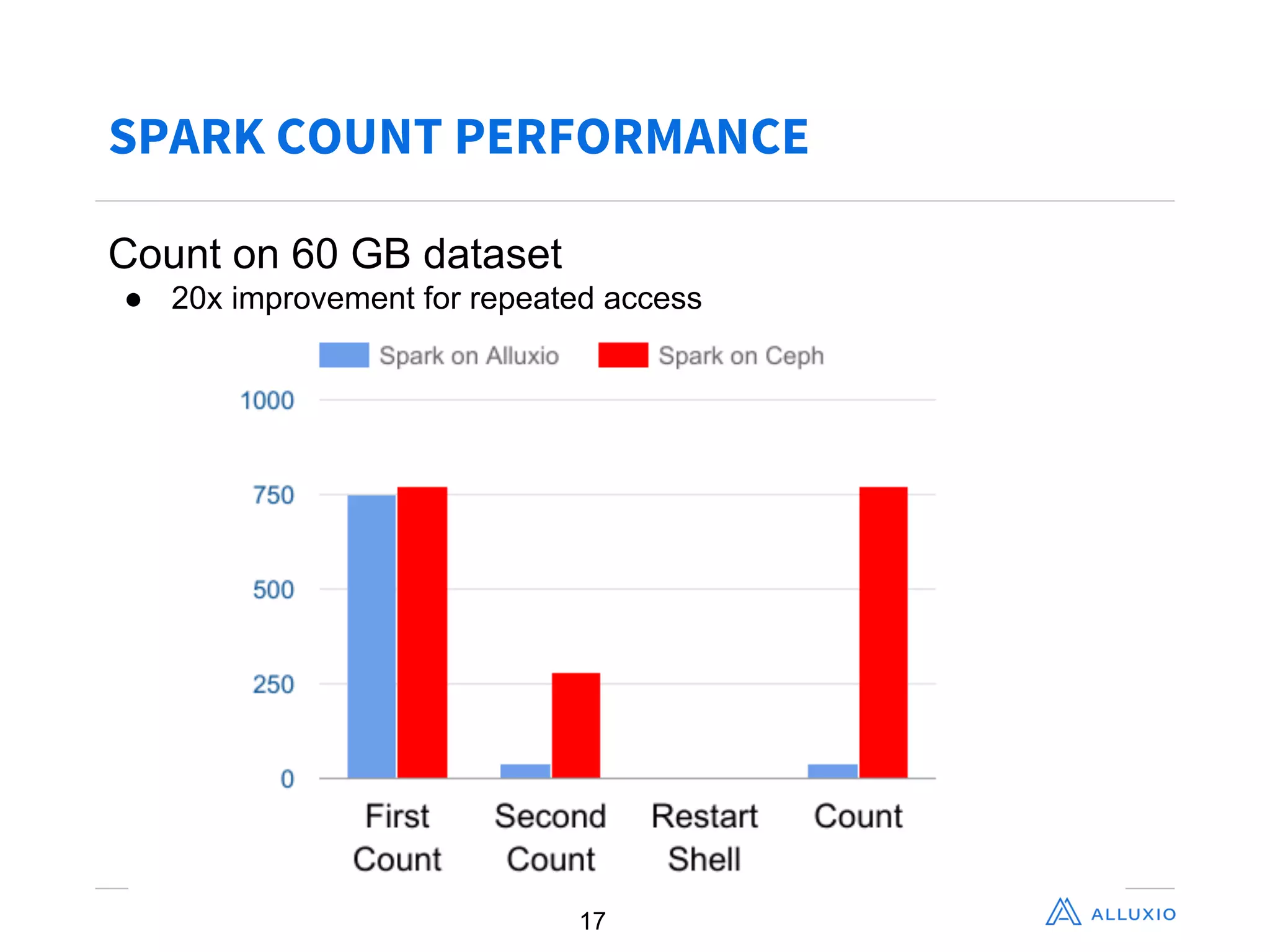

Adit Madan from Alluxio presented on using Alluxio to accelerate analytics on data stored in Ceph object storage. Alluxio acts as a virtual distributed file system that caches data in memory to provide faster access to data across different storage systems. It was shown to provide up to 20x faster performance for repeated Spark jobs on a 60GB dataset in Ceph compared to without Alluxio. Details are provided in Alluxio's whitepaper on accelerating analytics on Ceph with Alluxio.






















































































