Download as PDF, PPTX



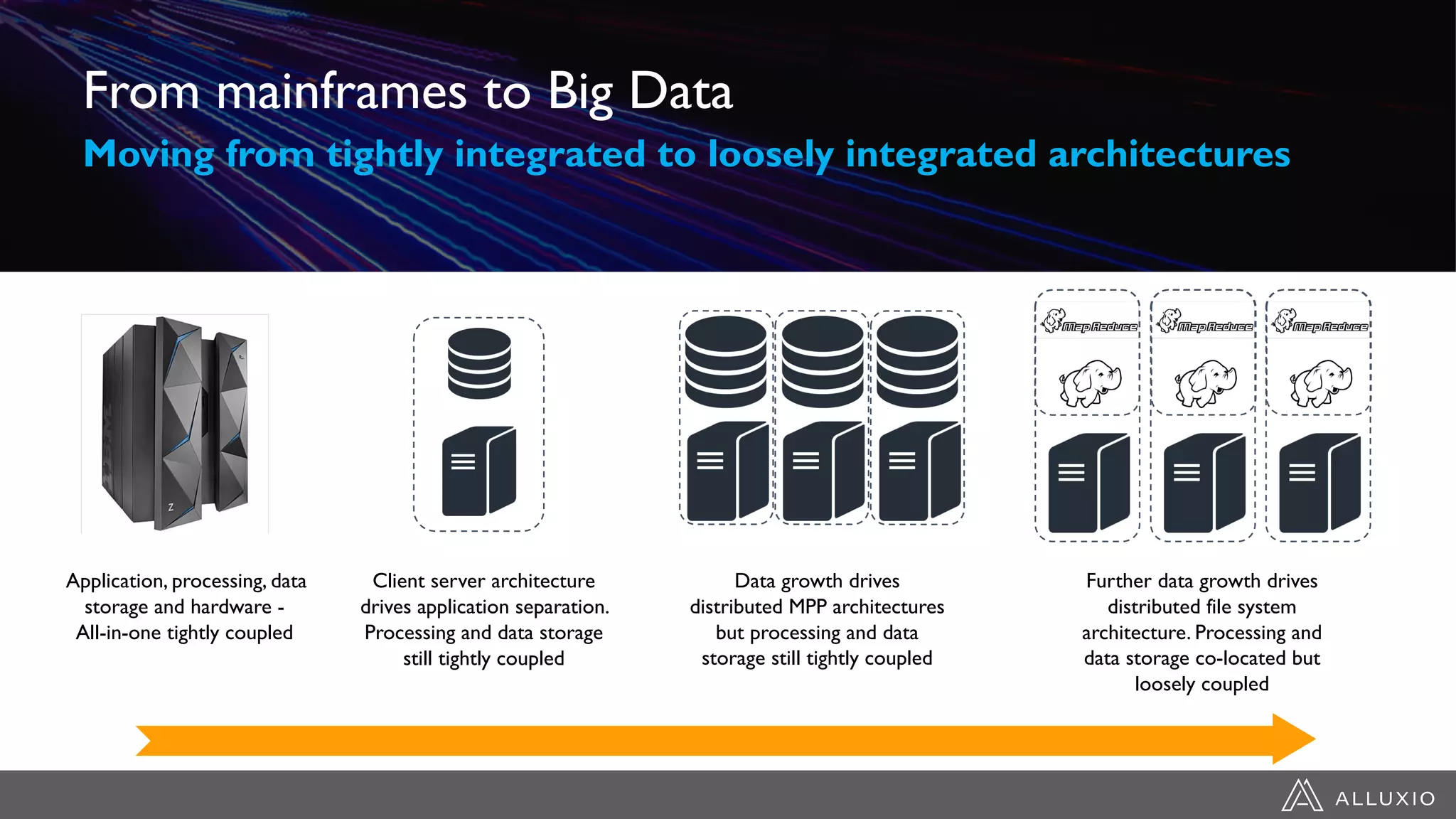


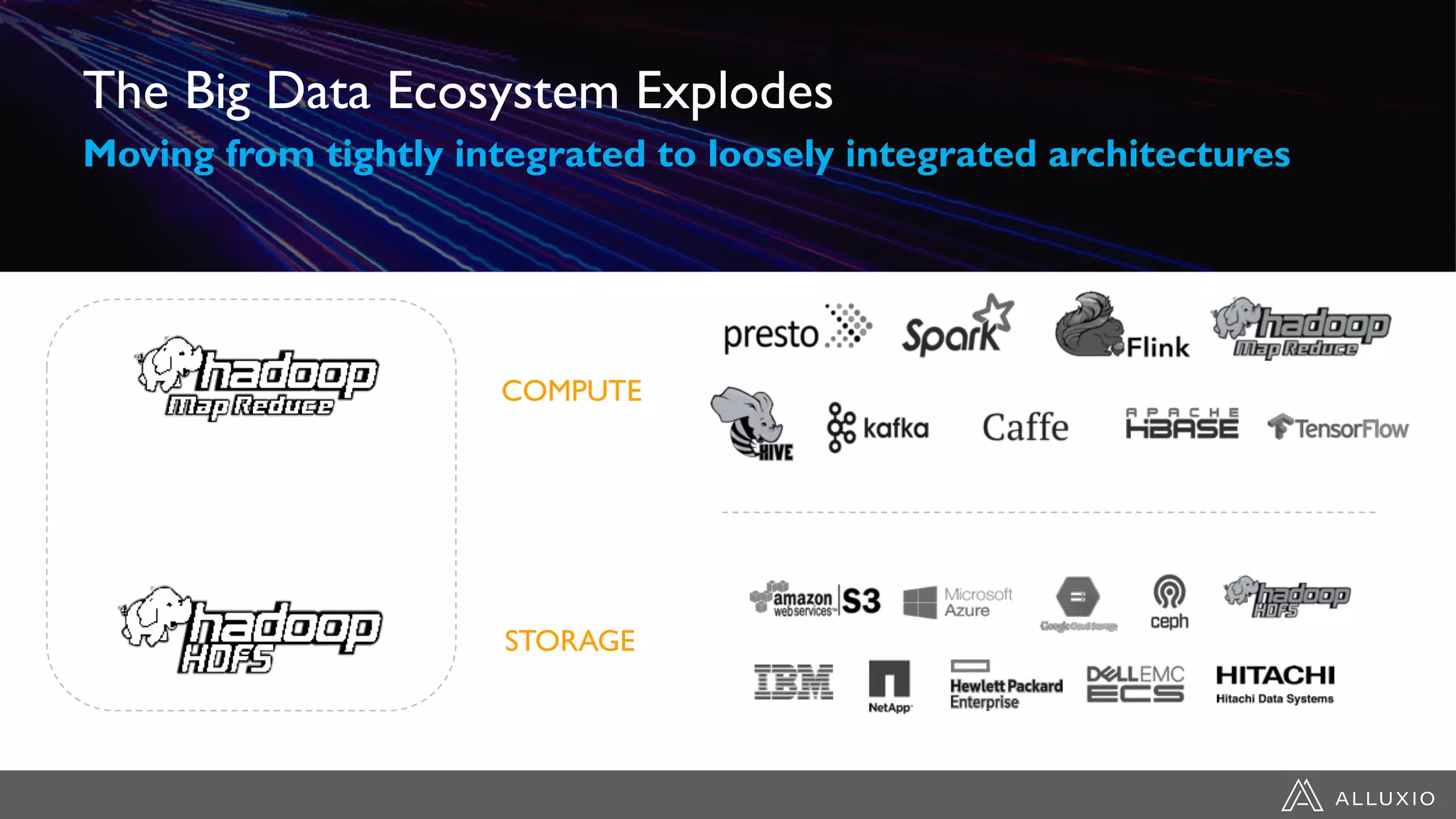

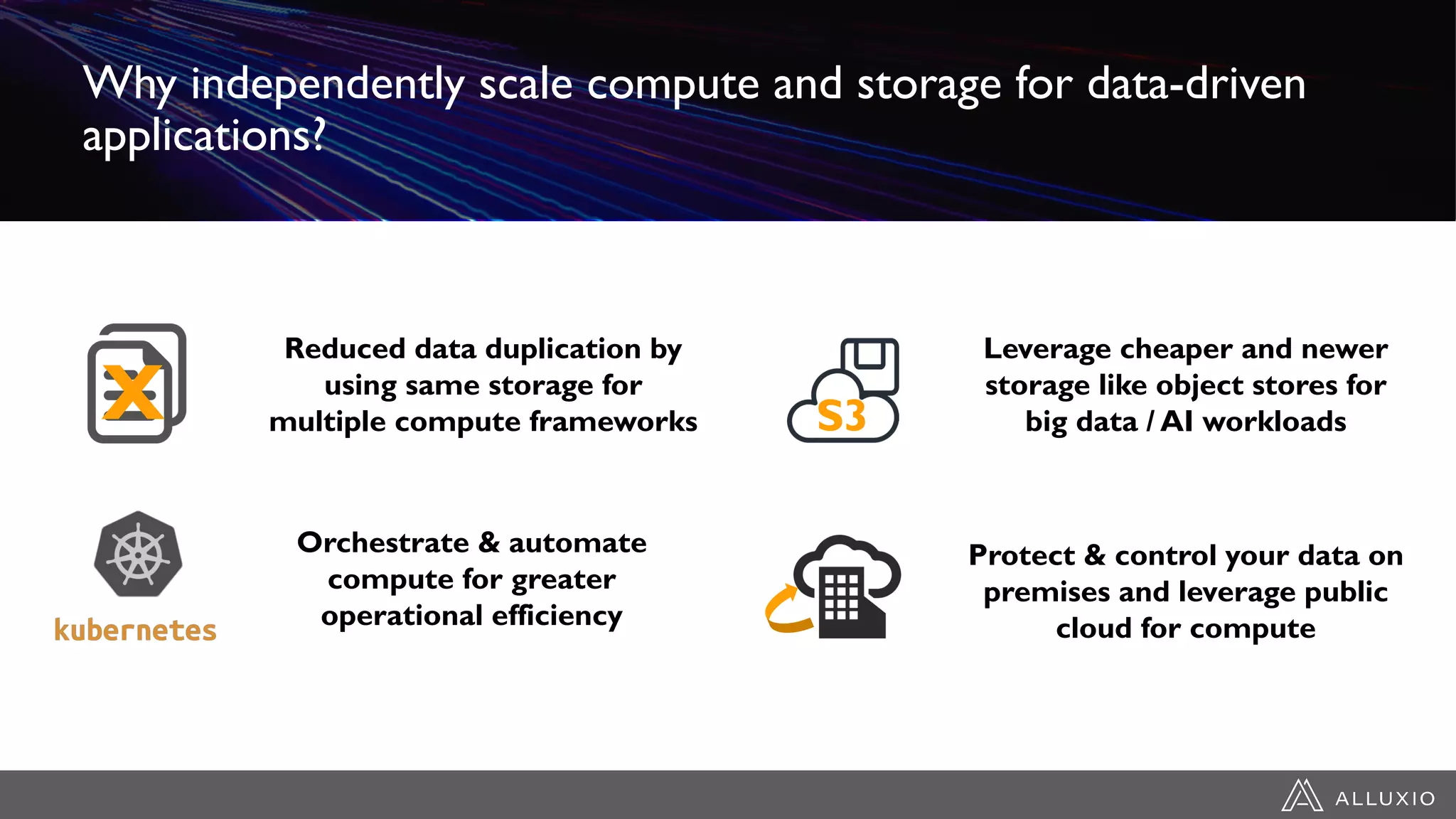






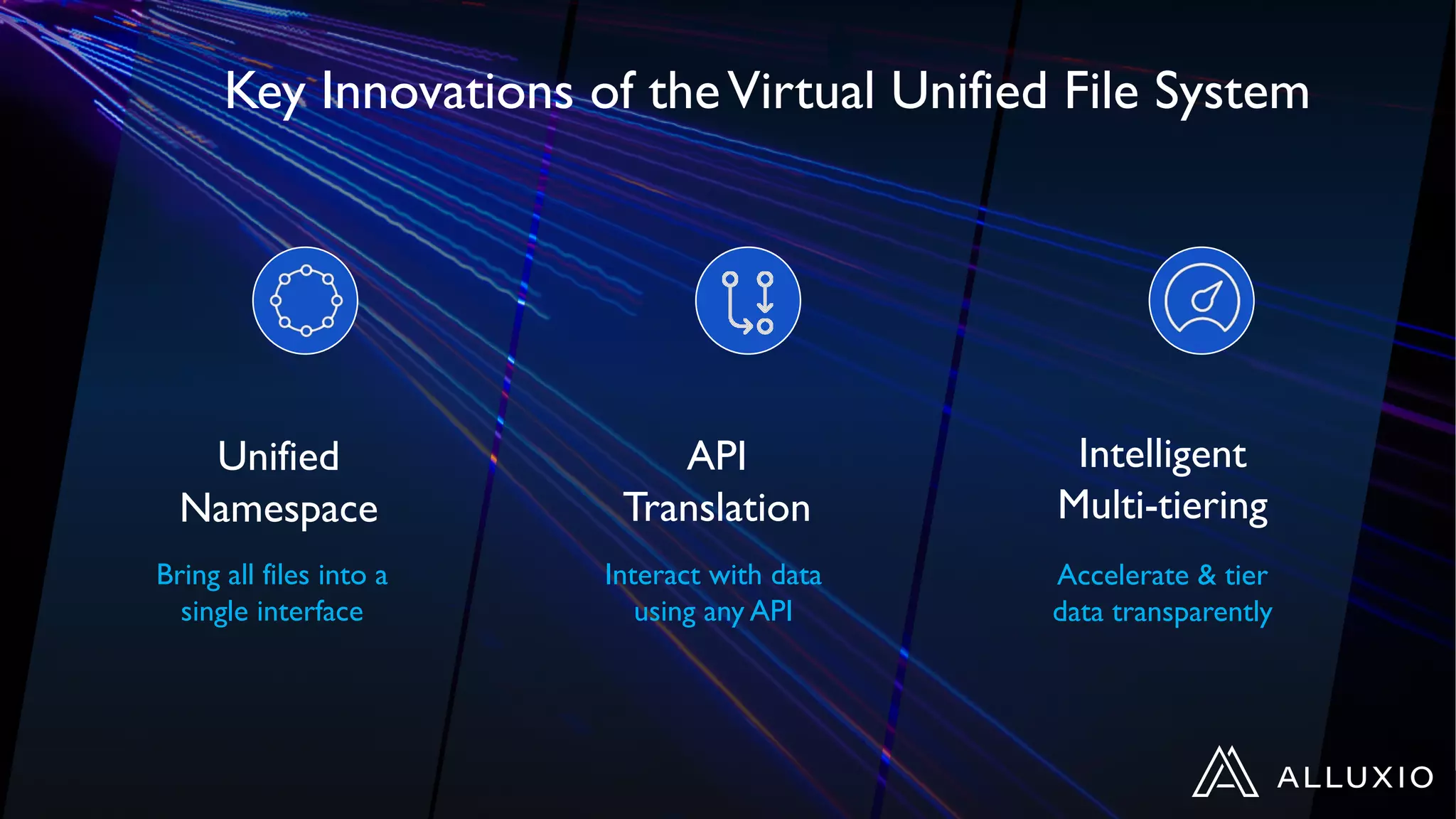
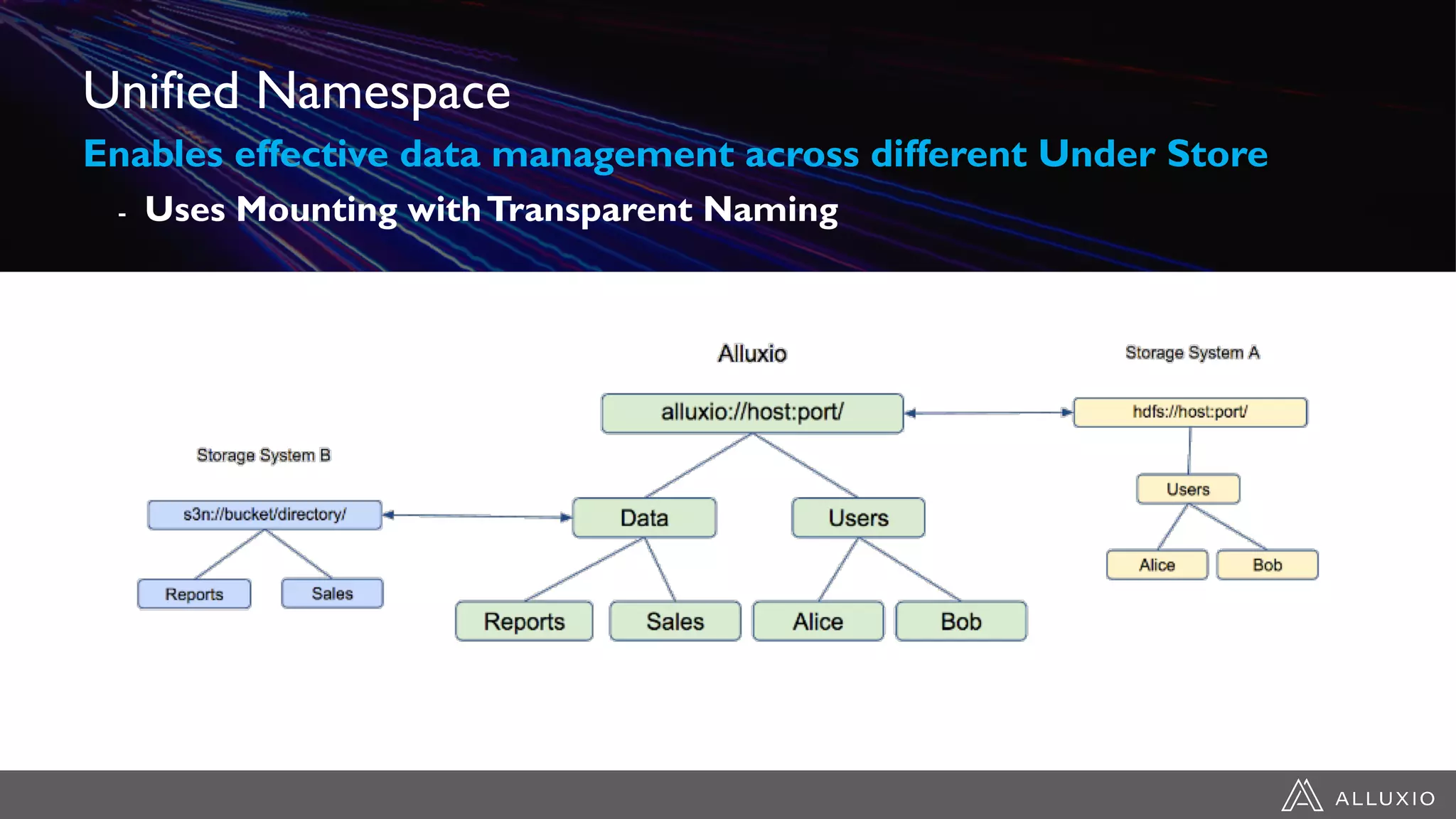

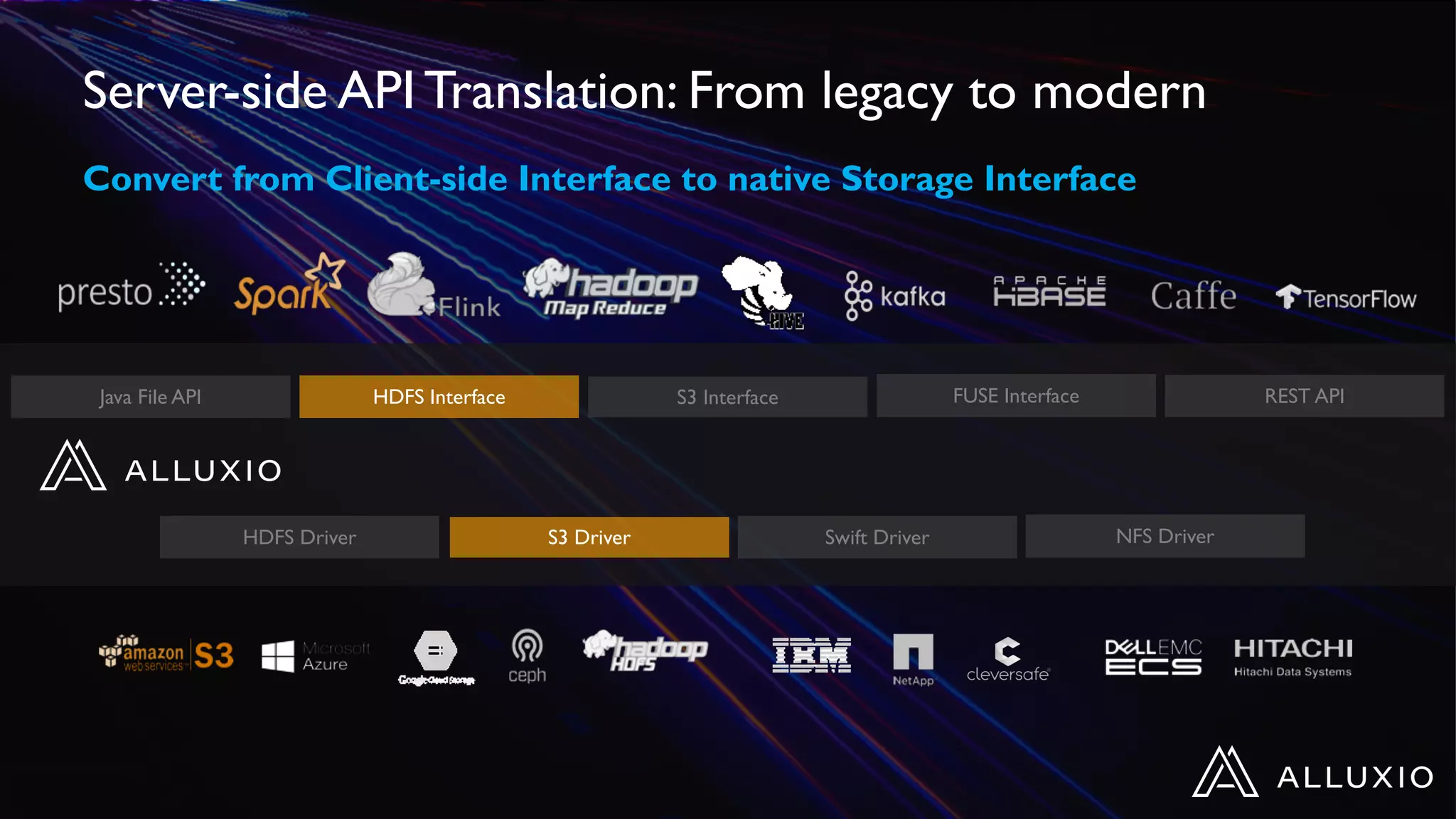
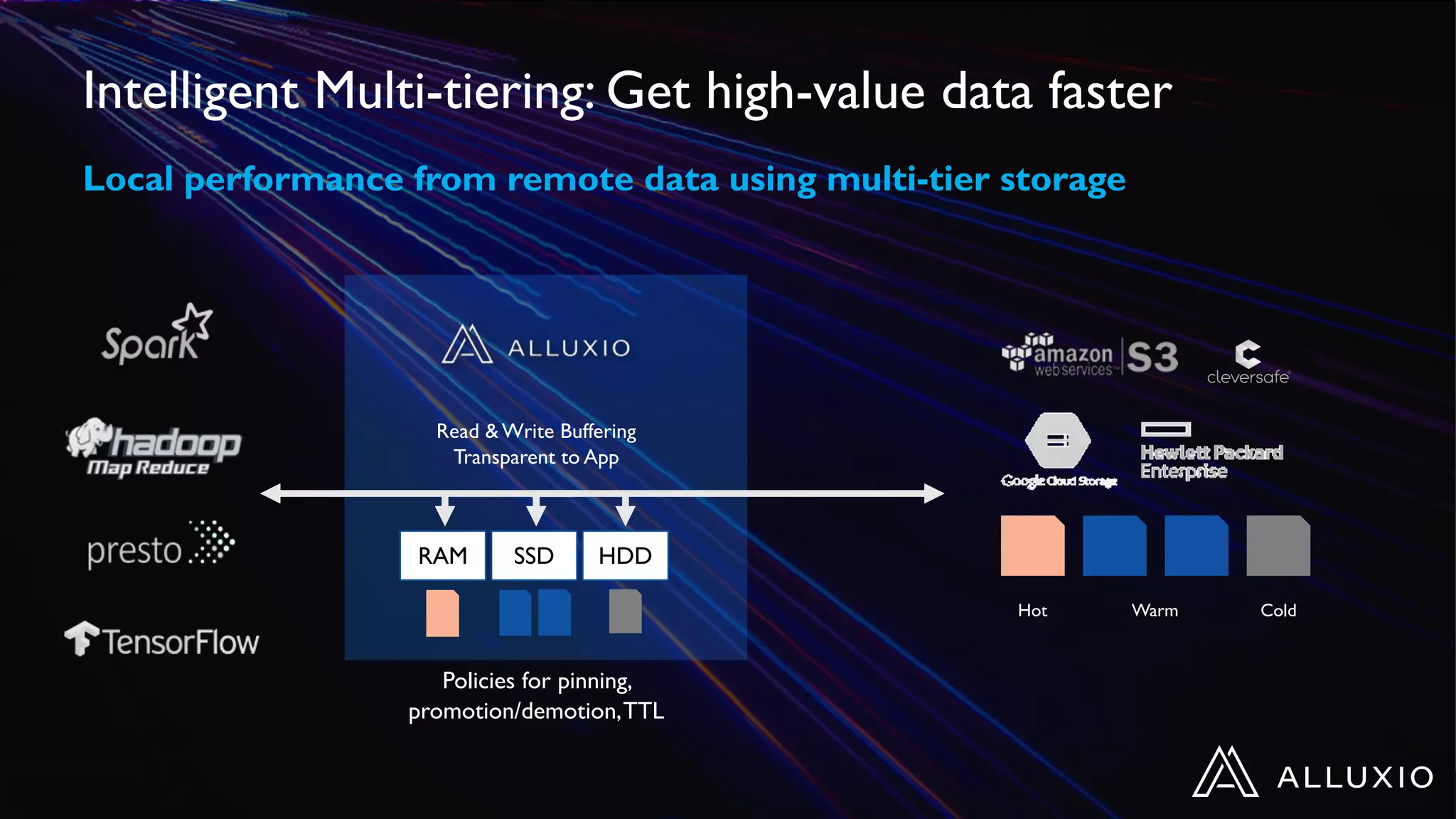
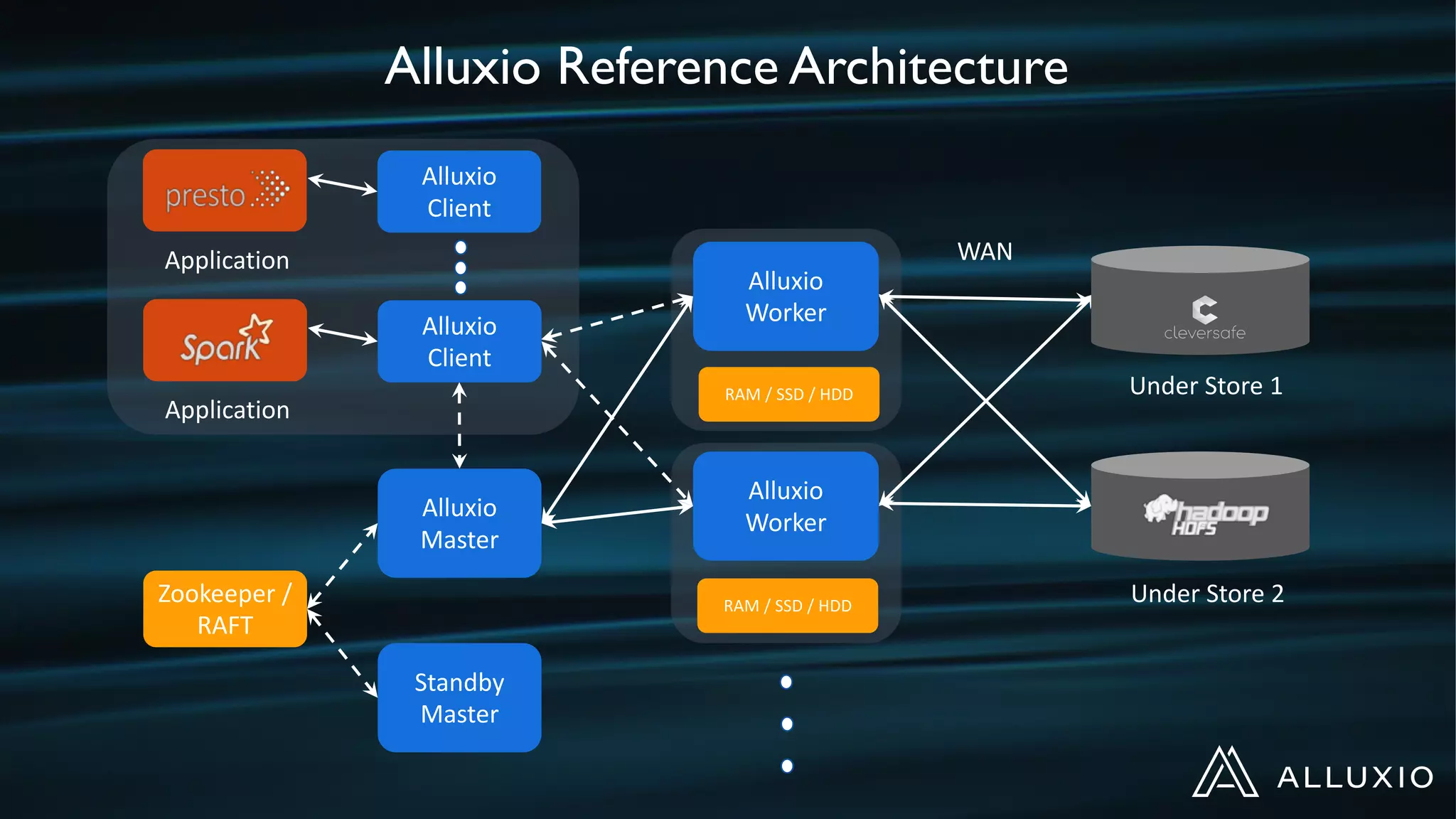


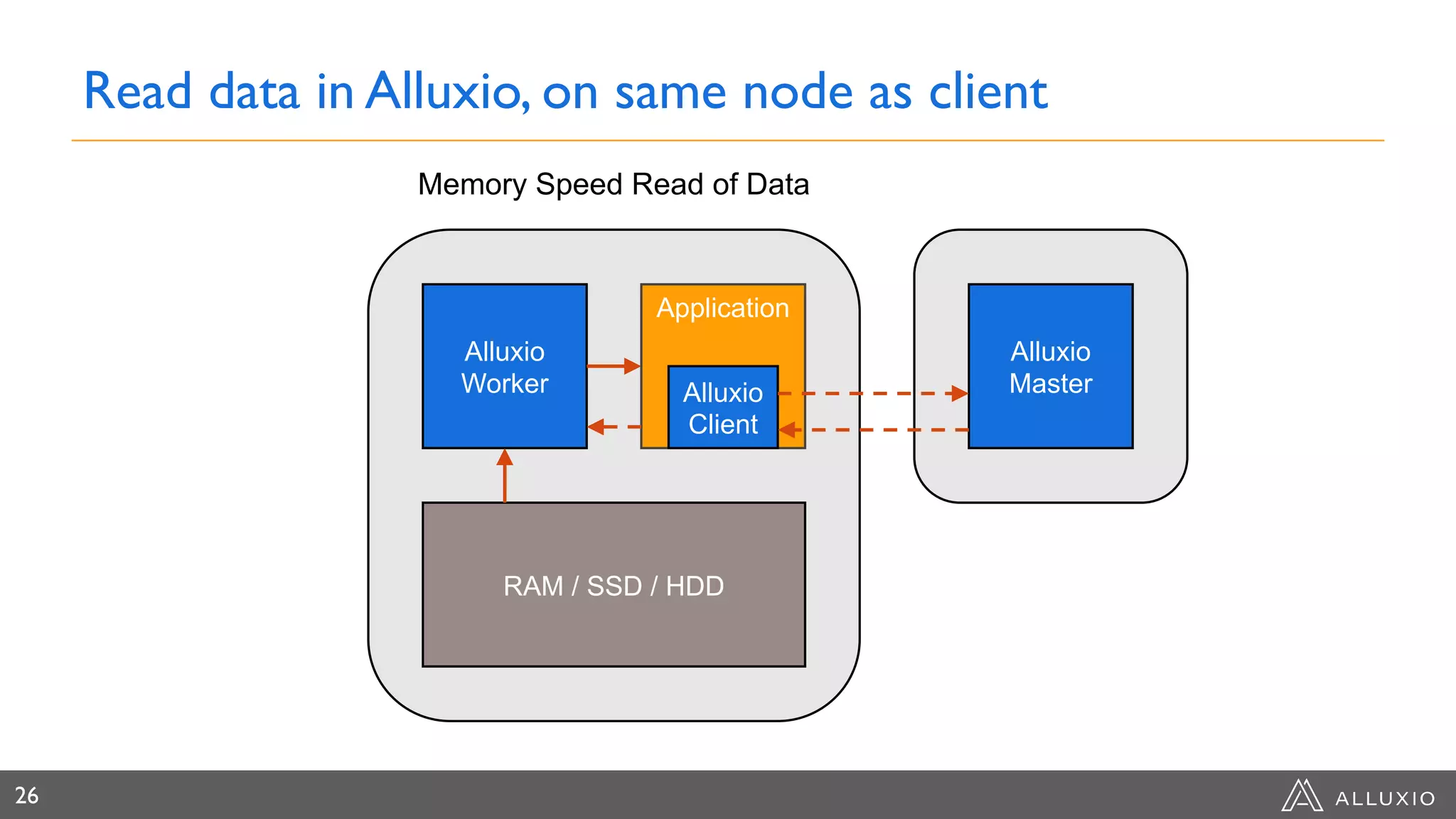
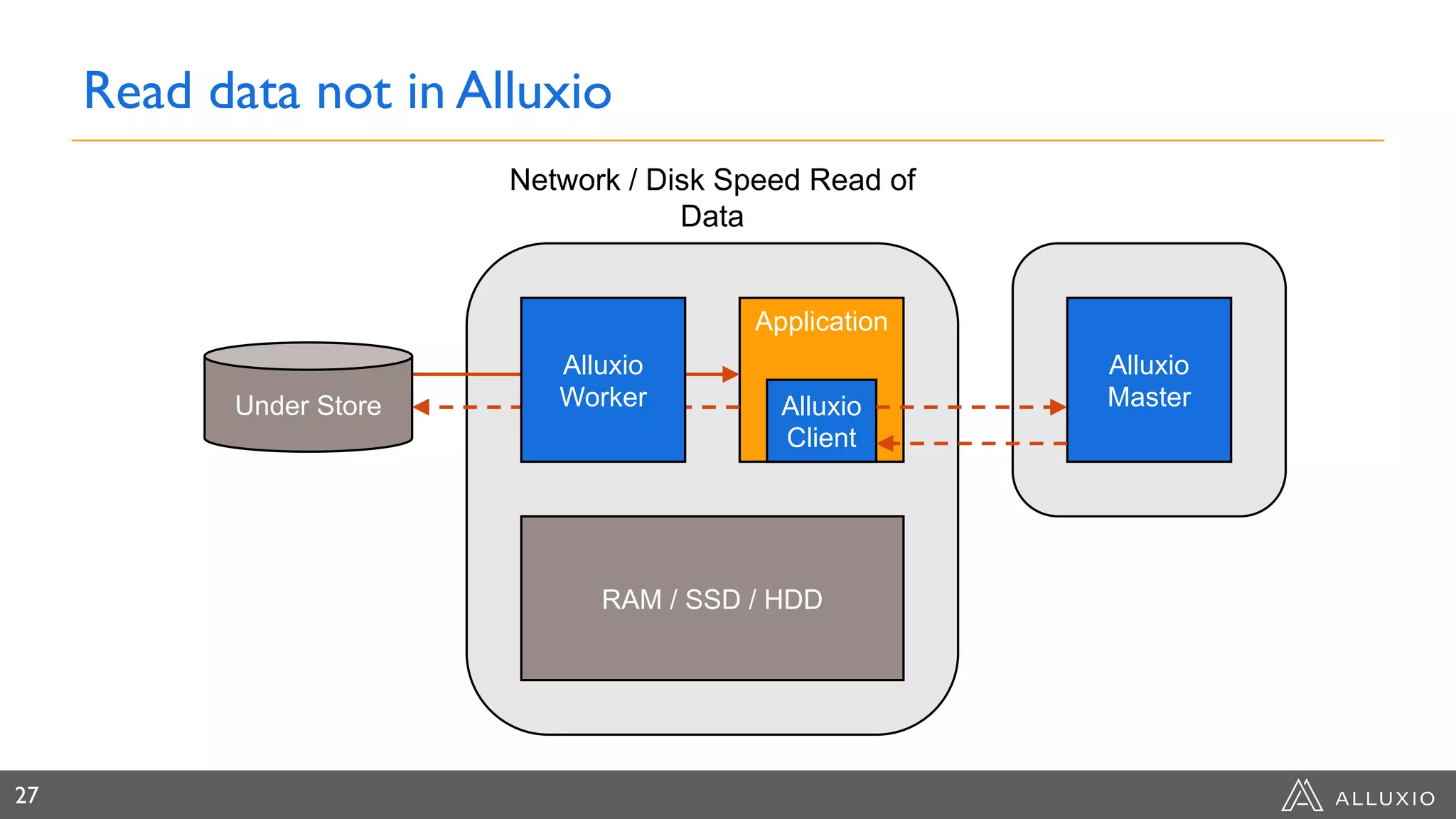
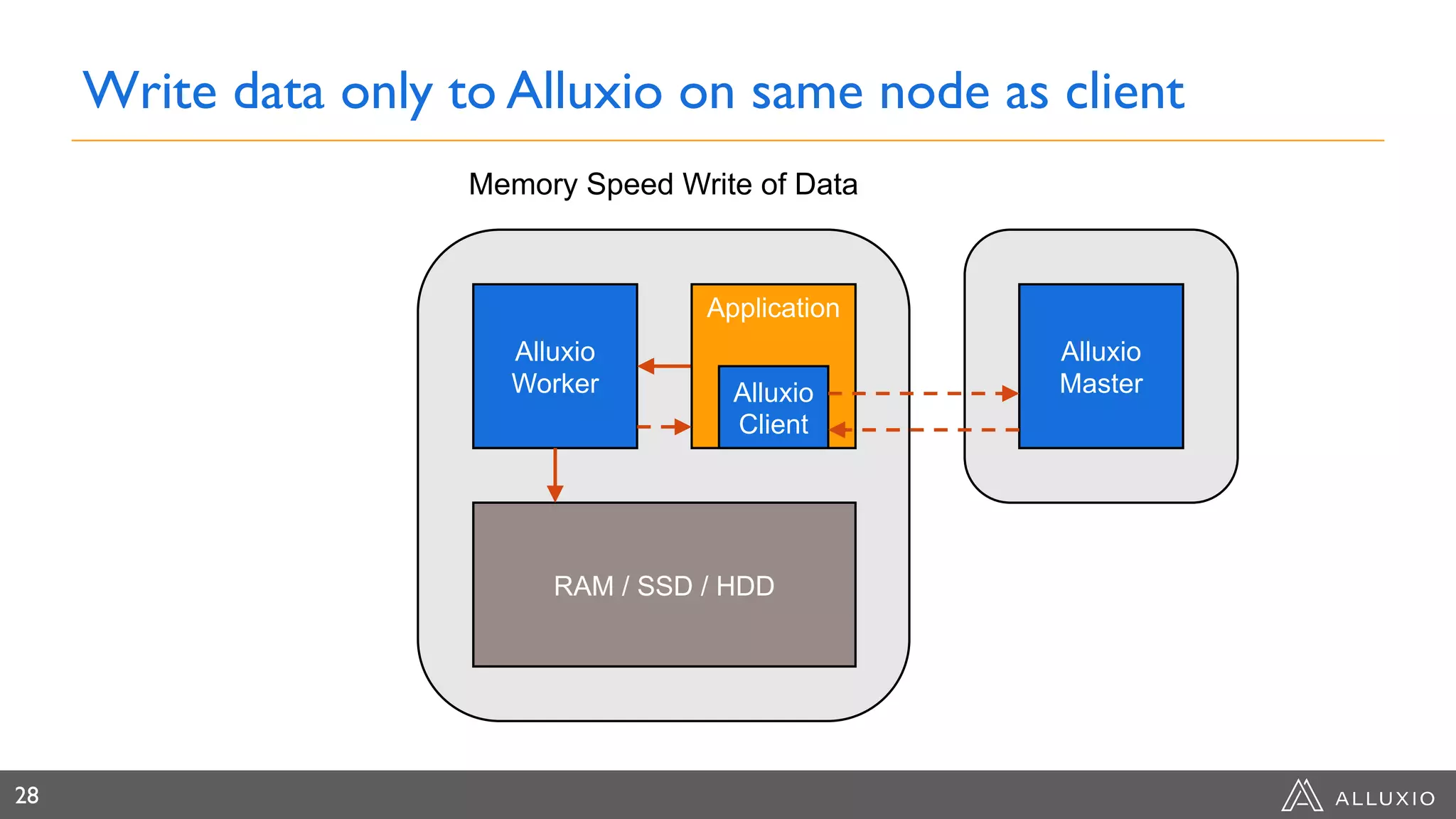
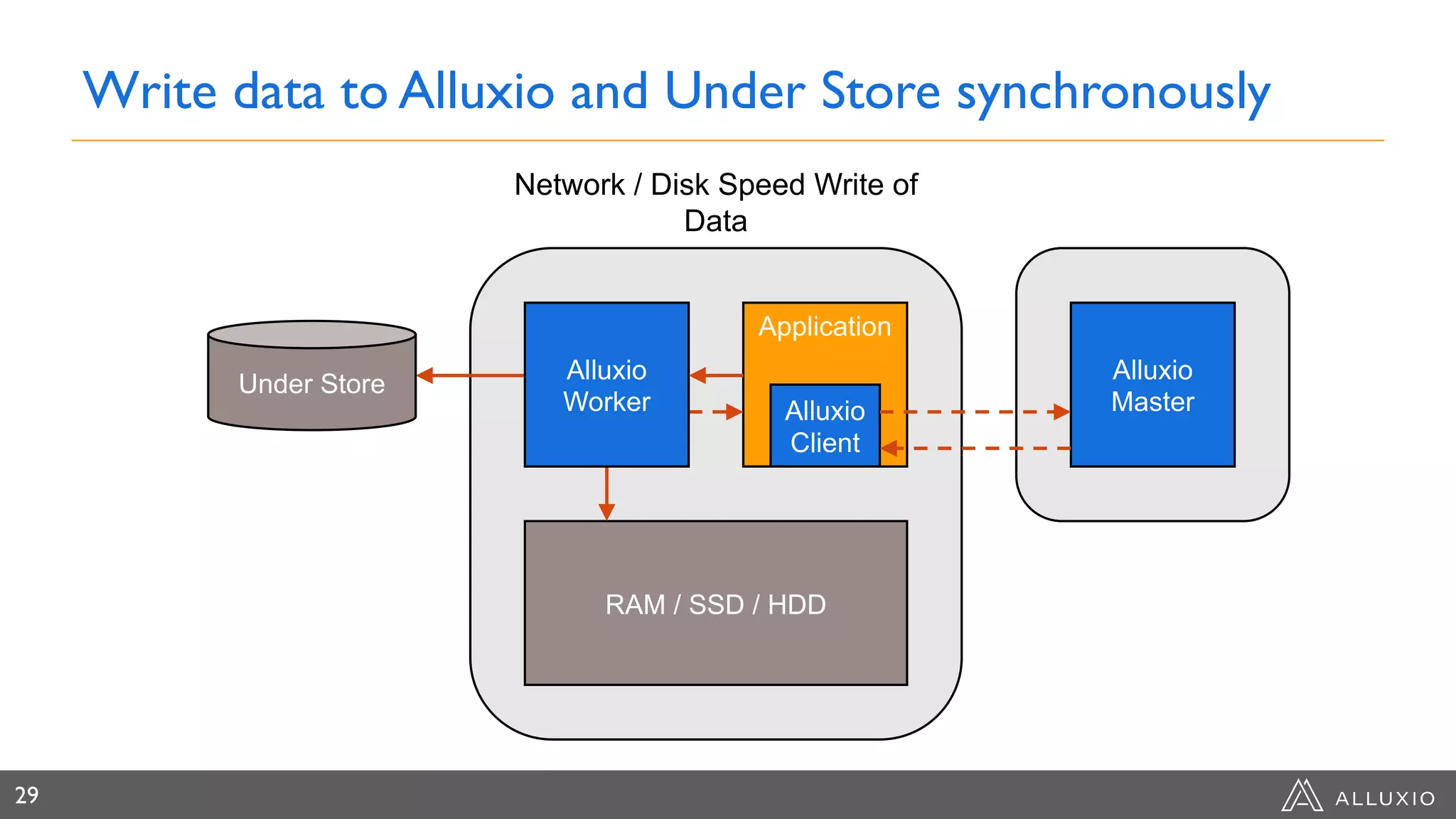




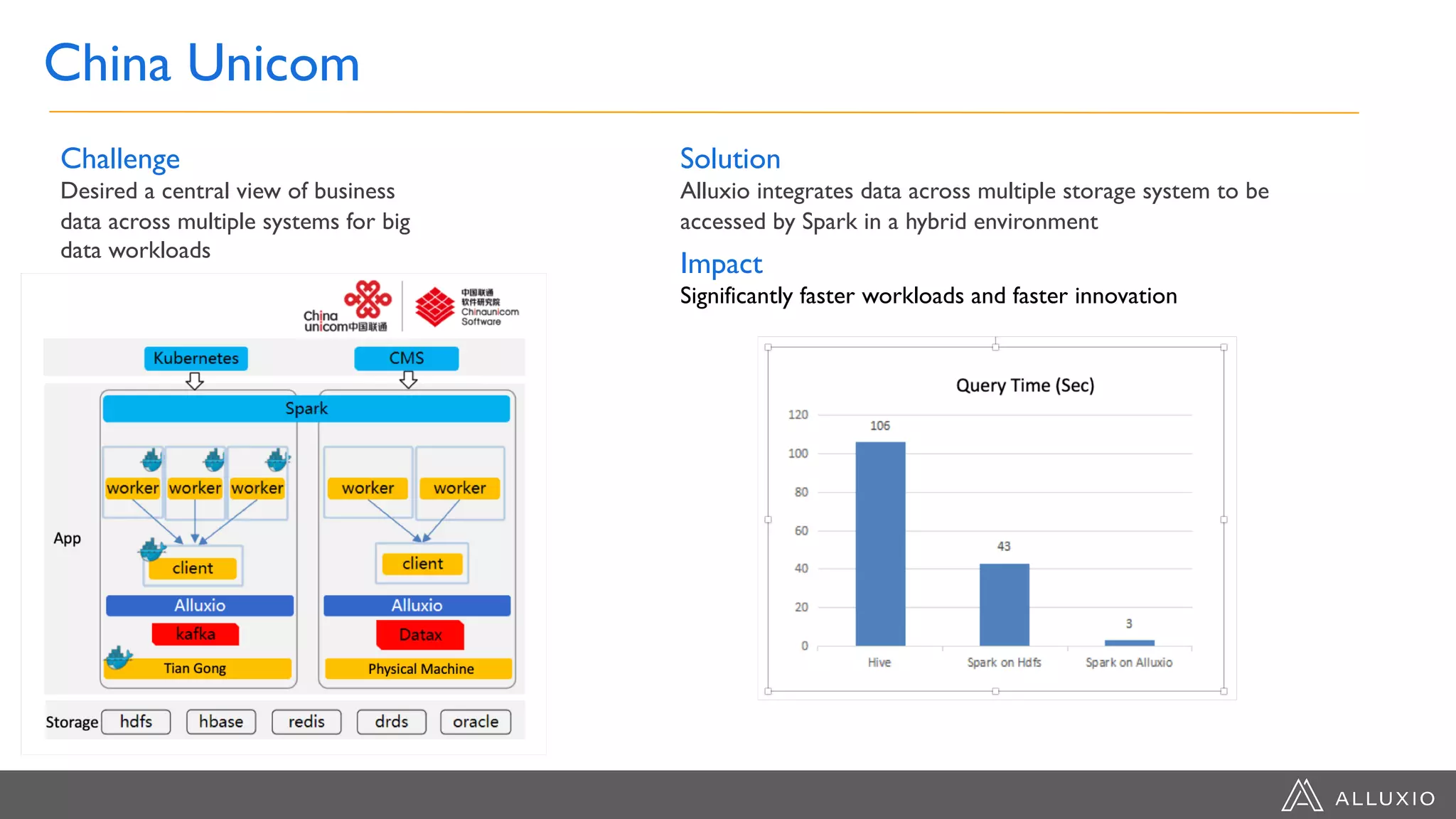





Dipti Borkar, VP of Product at Alluxio, discusses the benefits of independent scalability of compute and storage in data-driven applications, highlighting the evolution from tightly integrated to loosely coupled architectures. Alluxio's technology, which includes a unified namespace and multi-tier storage solutions, presents real-world use cases demonstrating efficiencies in big data analytics and machine learning. Key challenges addressed include data locality and accessibility, with a focus on maximizing performance and enabling flexible data management across diverse storage systems.























































































