Downloaded 80 times





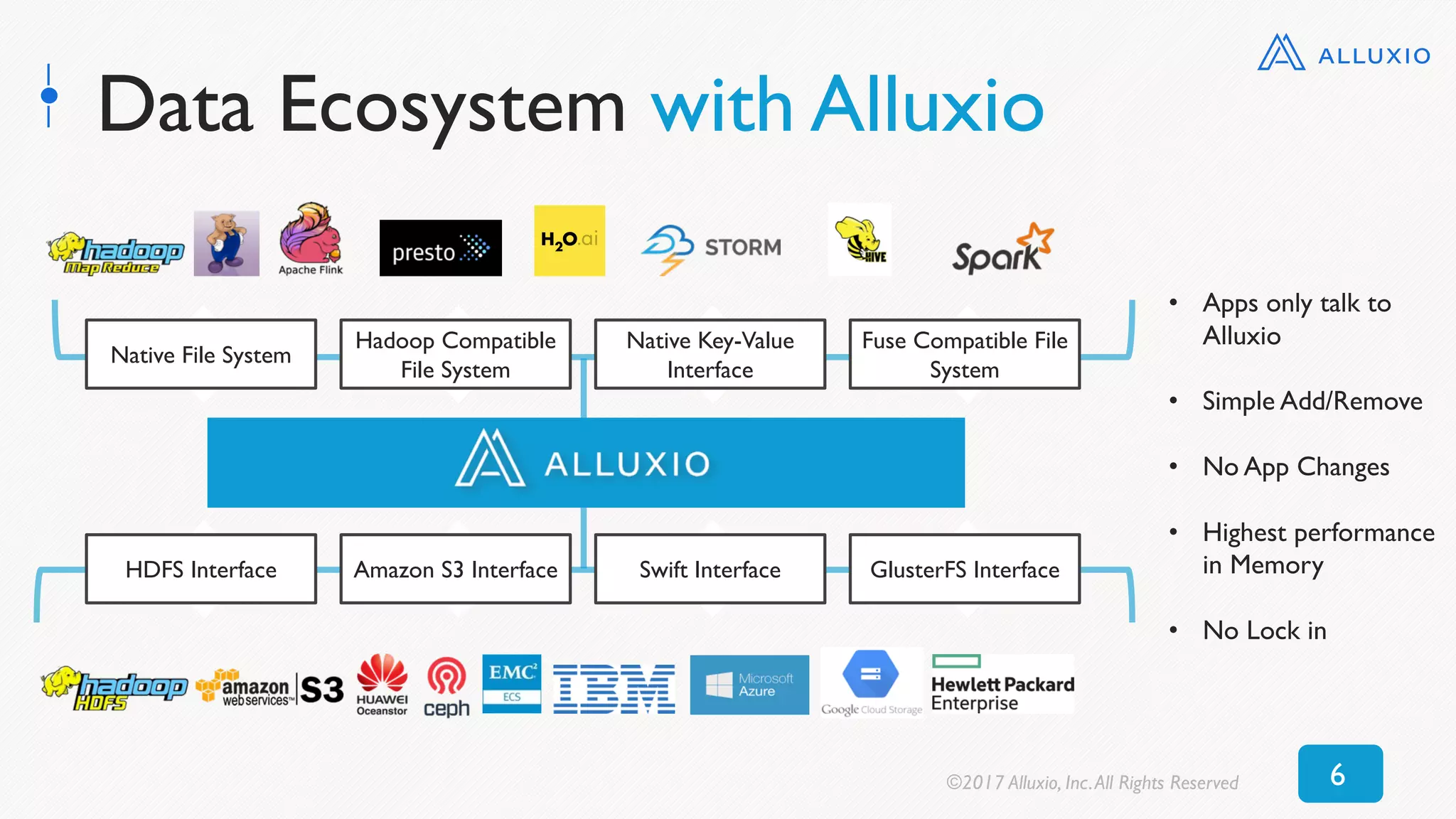






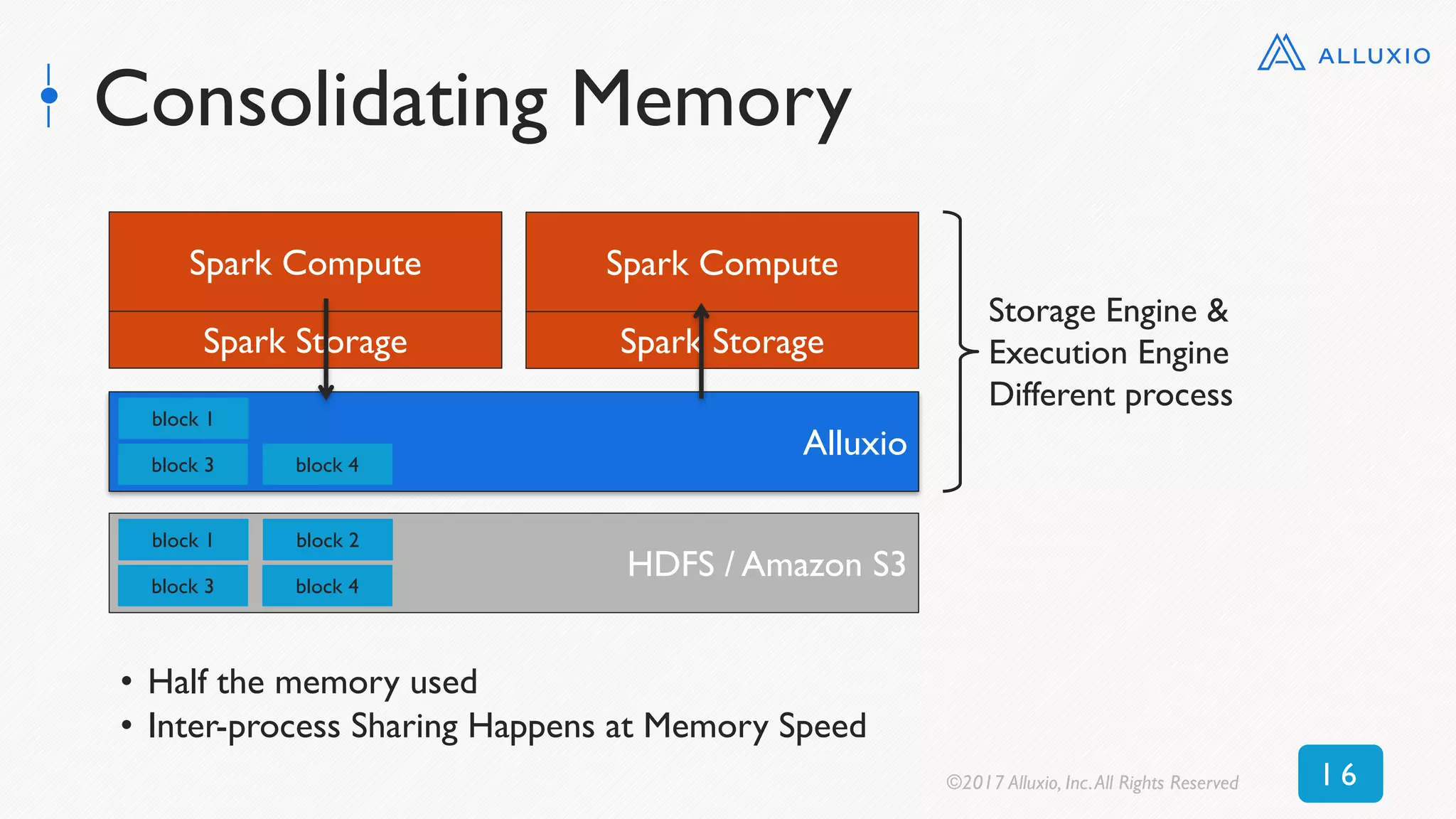






![0
50
100
150
200
250
0 5 10 15 20 25 30 35 40 45 50
Time[seconds]
RDD Size [GB]
Alluxio (textFile) Alluxio (objectFile) DISK_ONLY MEMORY_ONLY_SER MEMORY_ONLY
Reading Cached RDD
©2017 Alluxio, Inc.All Rights Reserved 2 7](https://image.slidesharecdn.com/075changli-170616204305/75/Best-Practices-for-Using-Alluxio-with-Apache-Spark-with-Cheng-Chang-and-Haoyuan-Li-27-2048.jpg)
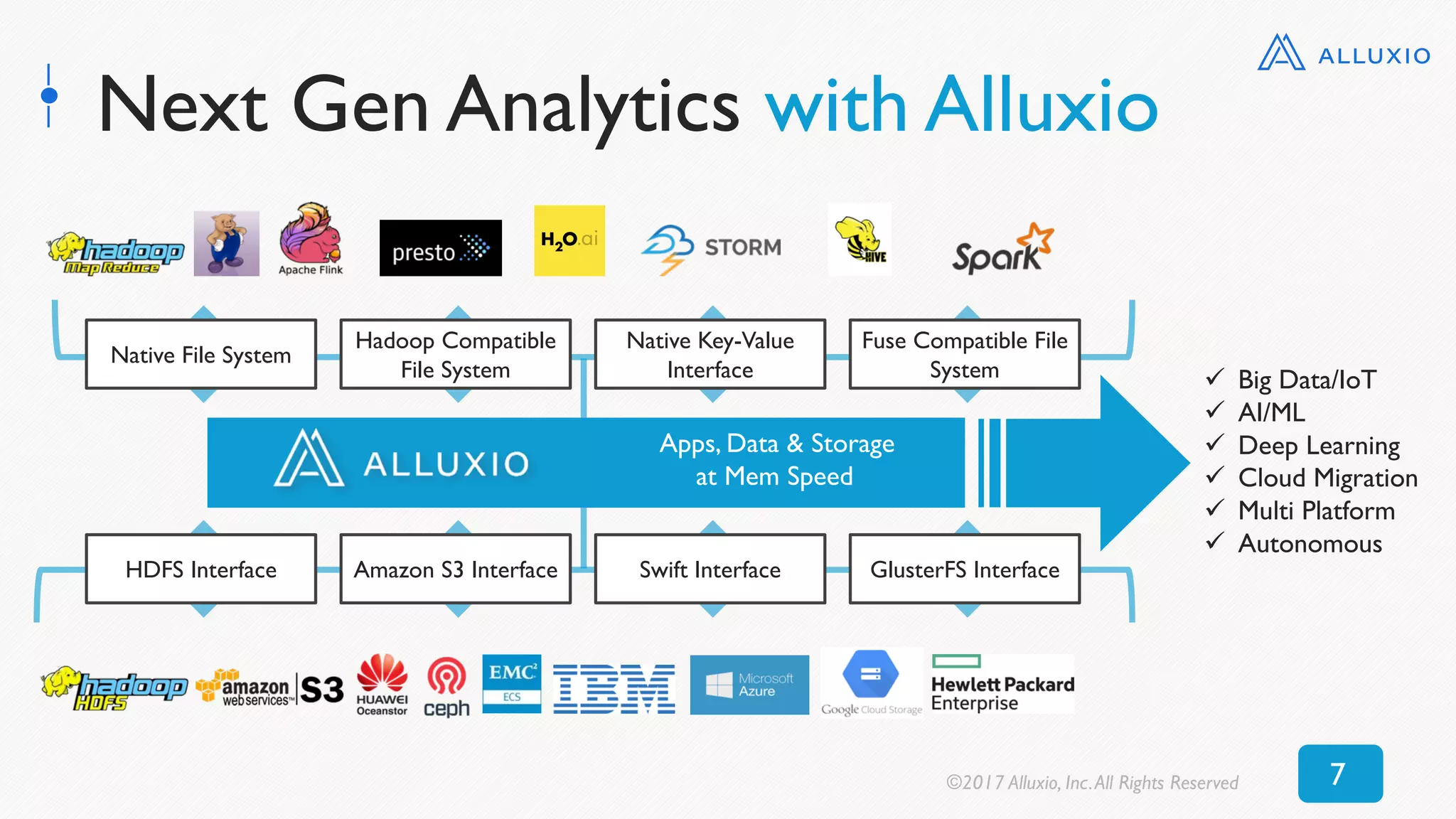
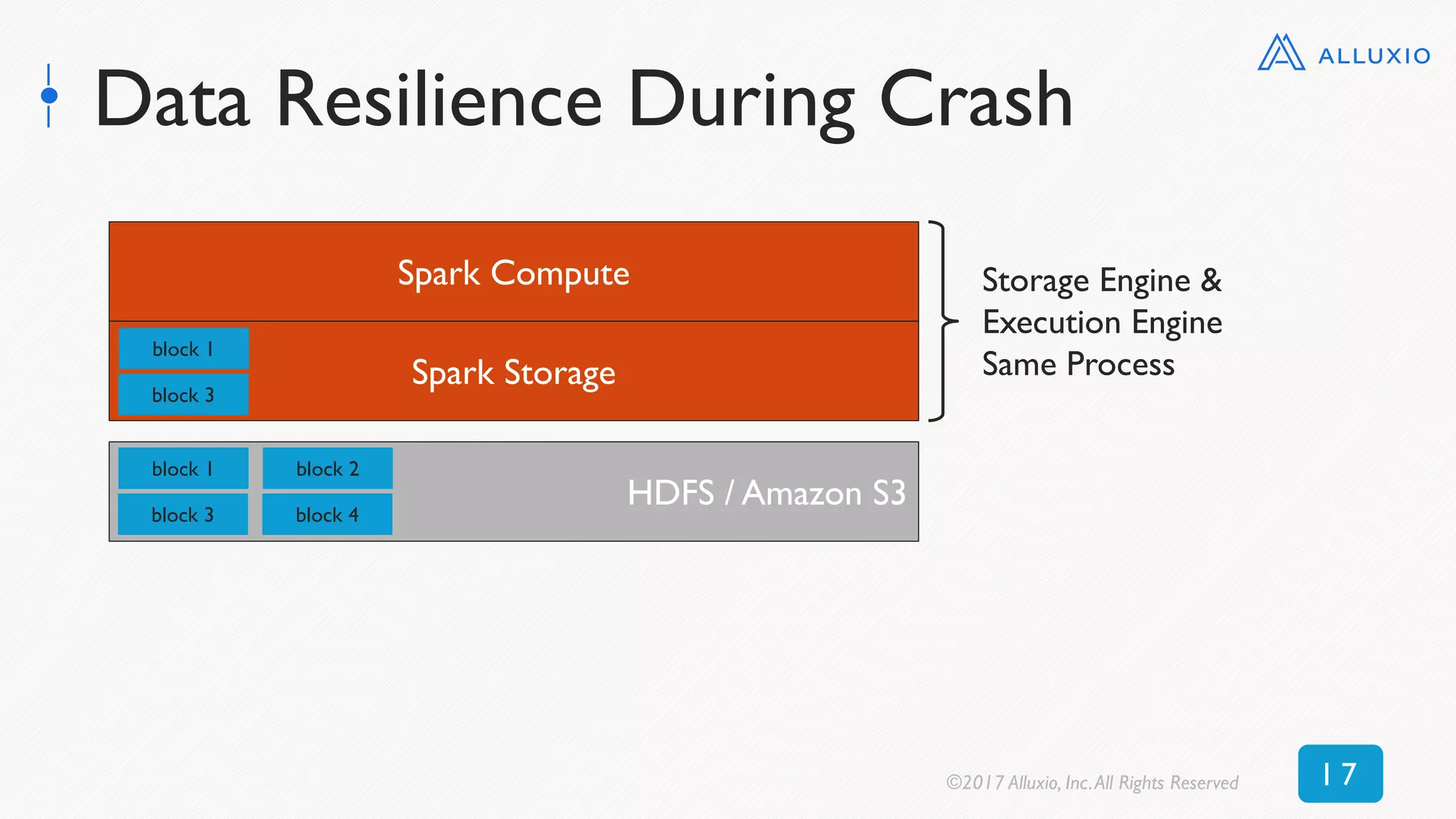
![0 100 200 300 400 500 600 700 800
Alluxio
(textFile)
Alluxio
(objectFile)
No Alluxio
Time [seconds]
7x$speedup
16x$speedup
New Context: Read 50 GB RDD (S3)
©2017 Alluxio, Inc.All Rights Reserved 2 8](https://image.slidesharecdn.com/075changli-170616204305/75/Best-Practices-for-Using-Alluxio-with-Apache-Spark-with-Cheng-Chang-and-Haoyuan-Li-28-2048.jpg)
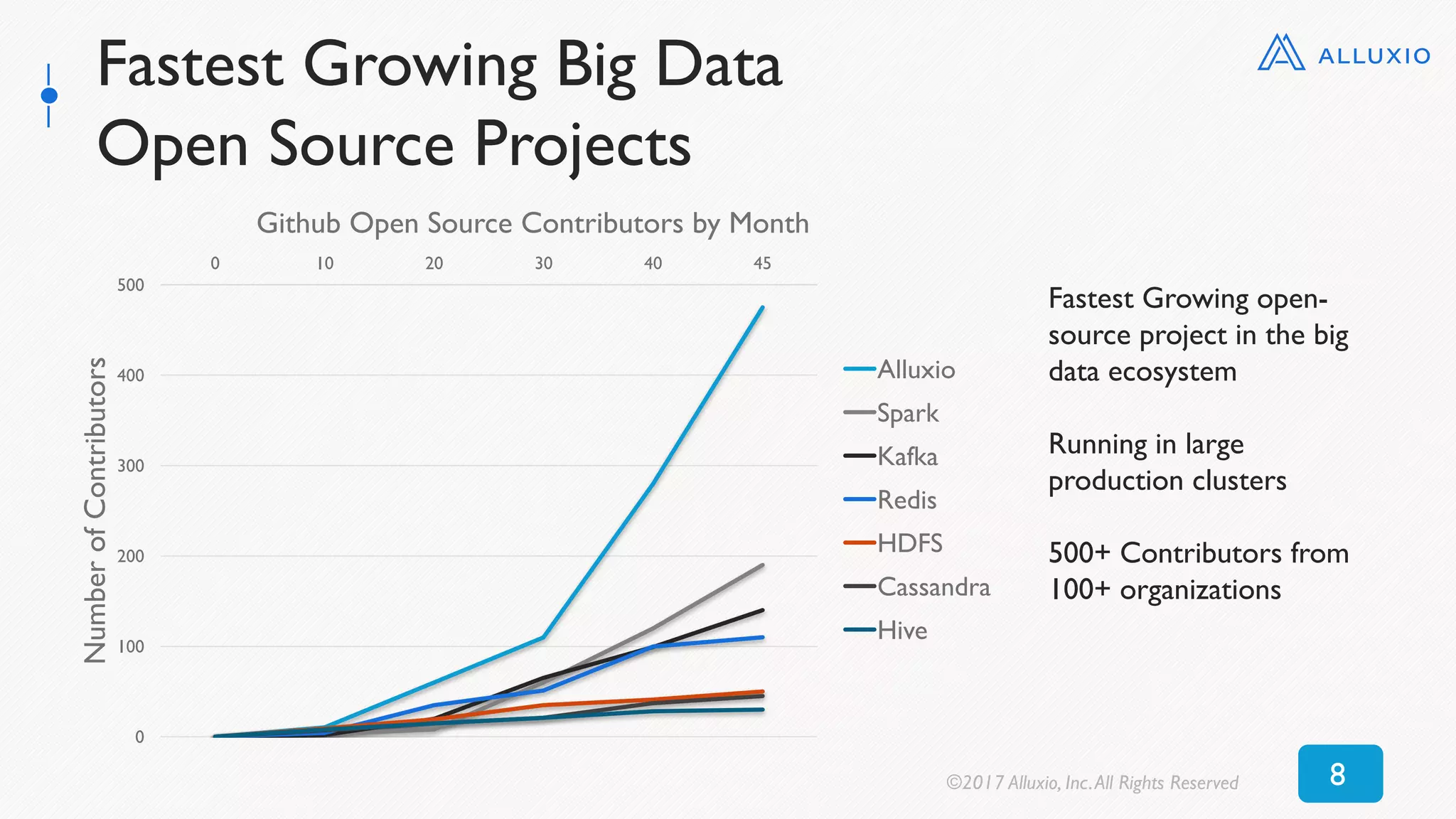
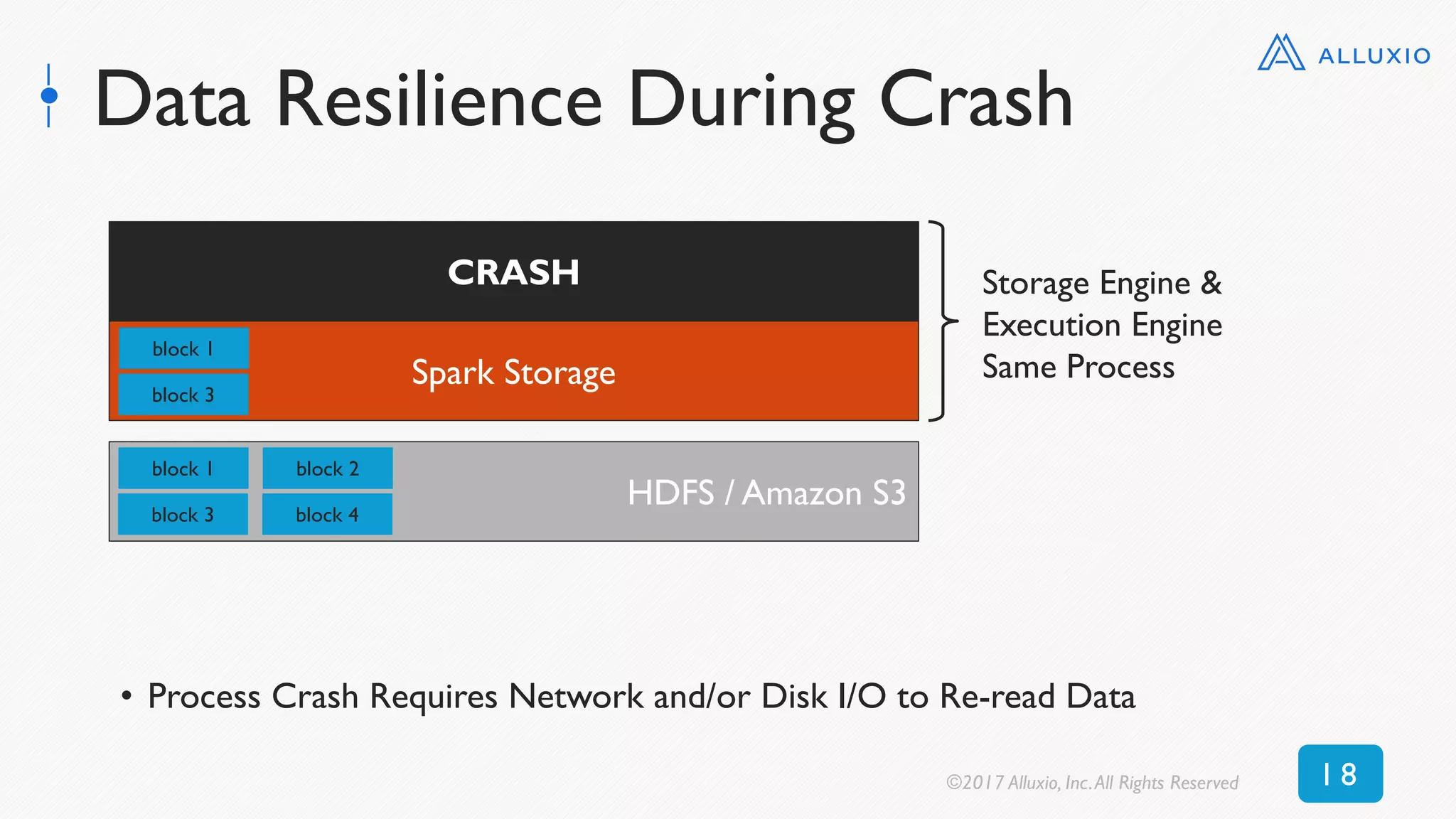
![Reading Cached DataFrame (parquet)
0
50
100
150
200
250
0 5 10 15 20 25 30 35 40 45 50
Time[seconds]
DataFrame Size [GB]
Alluxio (textFile) MEMORY_ONLY_SER MEMORY_ONLY
©2017 Alluxio, Inc.All Rights Reserved 2 9](https://image.slidesharecdn.com/075changli-170616204305/75/Best-Practices-for-Using-Alluxio-with-Apache-Spark-with-Cheng-Chang-and-Haoyuan-Li-29-2048.jpg)
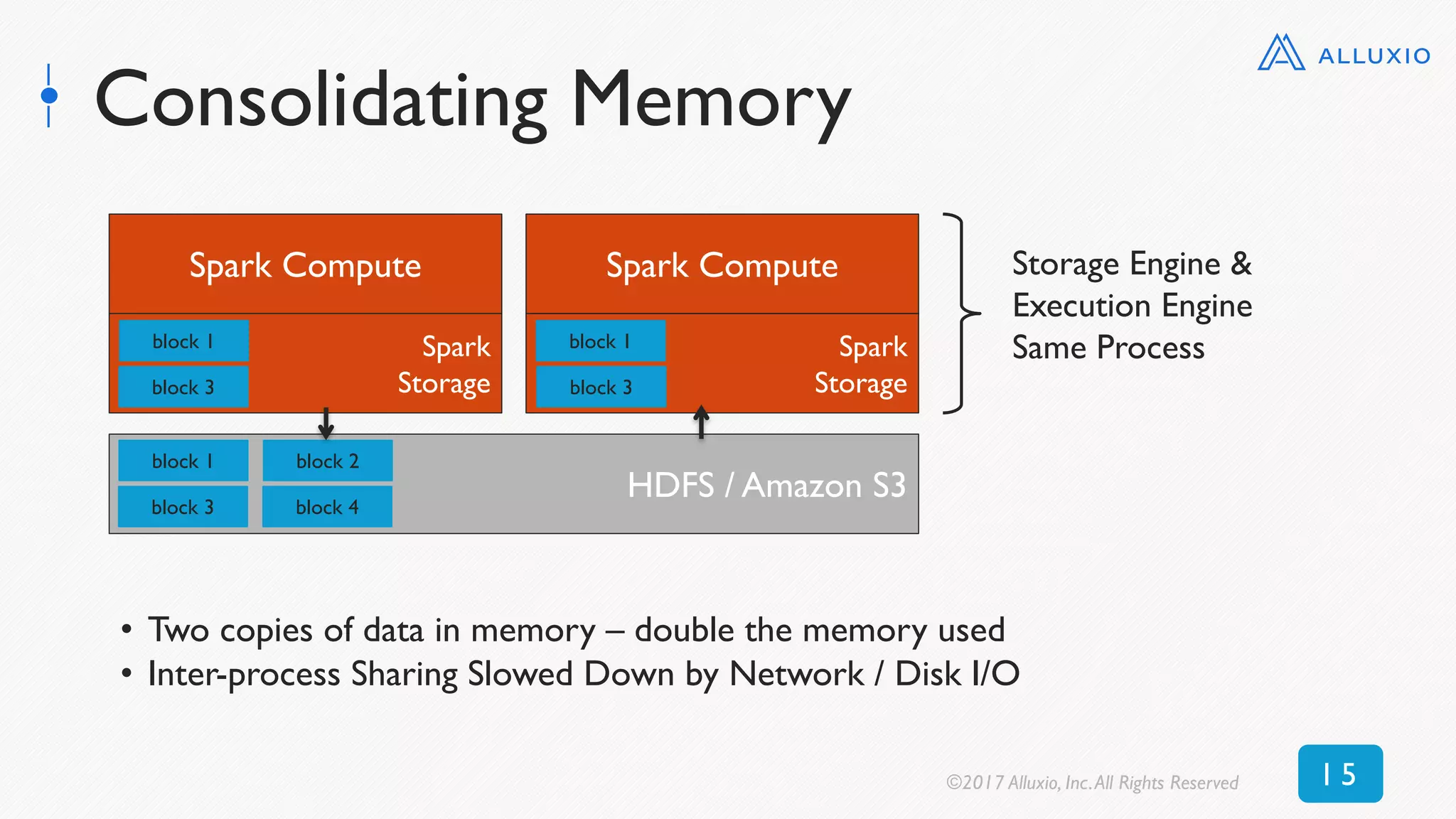
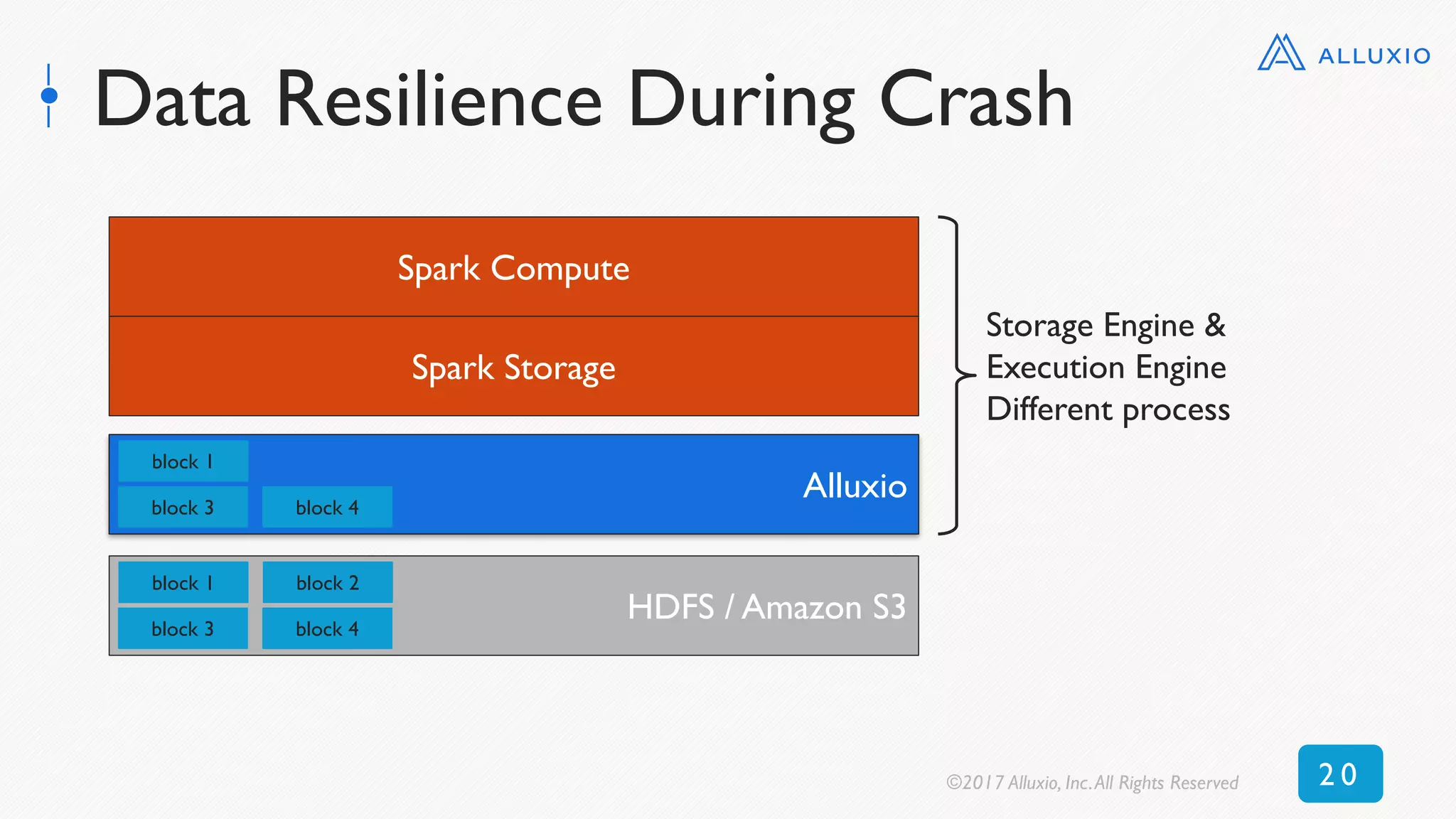
![New Context: Read 50 GB DataFrame
(S3)
0 250 500 750 1000 1250 1500 1750
Alluxio
No Alluxio
Time [seconds]
10x average speedup, 17x peak speedup
©2017 Alluxio, Inc.All Rights Reserved 3 0](https://image.slidesharecdn.com/075changli-170616204305/75/Best-Practices-for-Using-Alluxio-with-Apache-Spark-with-Cheng-Chang-and-Haoyuan-Li-30-2048.jpg)




The document outlines best practices for using Alluxio with Spark, emphasizing improved performance and flexibility in dealing with diverse data sources. It presents several case studies demonstrating significant speed improvements and operational efficiencies achieved through the integration of Alluxio and Spark. The conclusion highlights the ease of use and predictable performance enhancements when connecting to various storage systems using Alluxio.























































































