










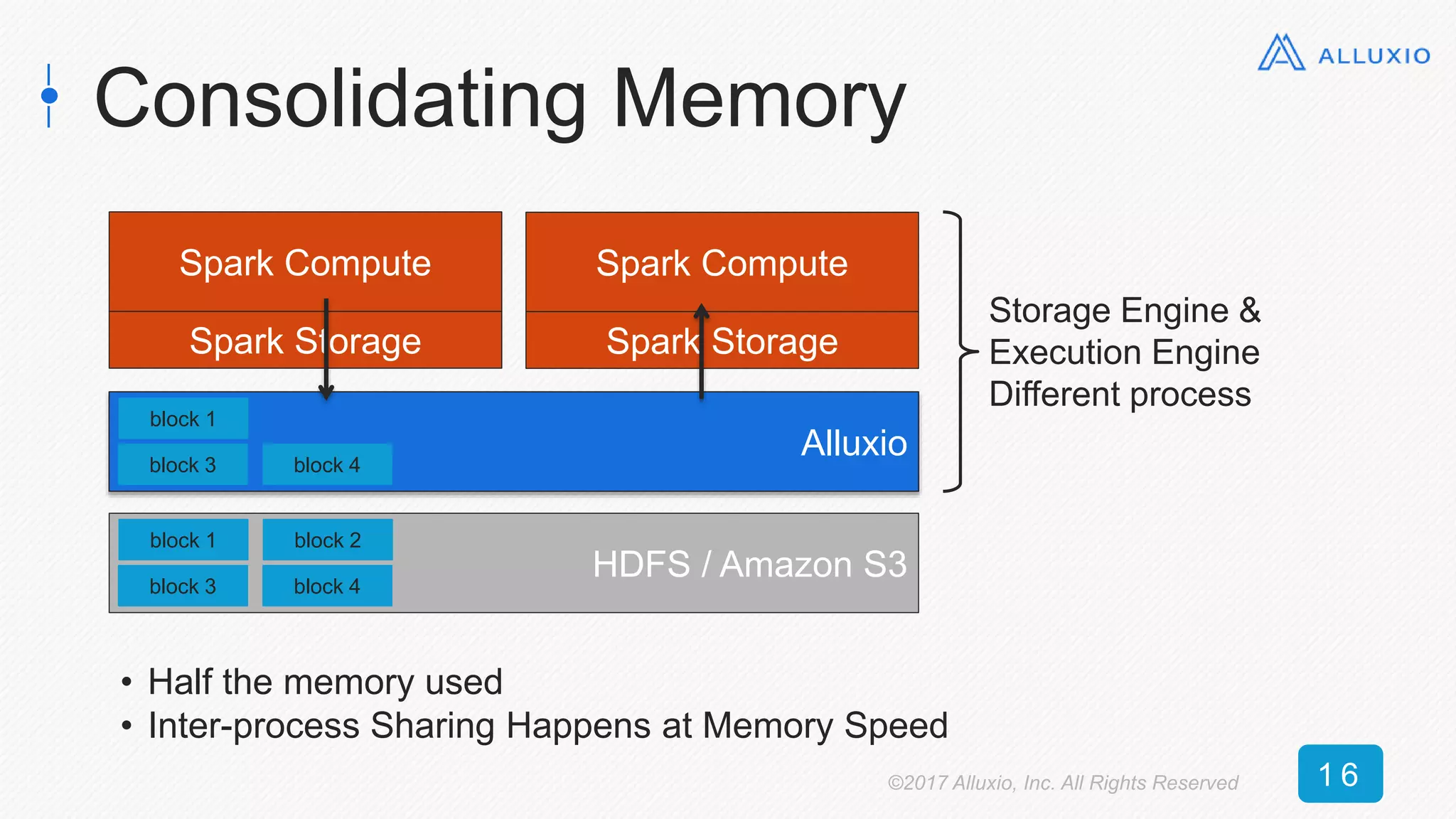







![0
50
100
150
200
250
0 5 10 15 20 25 30 35 40 45 50
Time[seconds]
RDD Size [GB]
Alluxio (textFile) Alluxio (objectFile) DISK_ONLY
MEMORY_ONLY_SER MEMORY_ONLY
Reading Cached RDD
©2017 Alluxio, Inc. All Rights Reserved 2 7](https://image.slidesharecdn.com/2017-08-05usingalluxiowithspark-171011211447/75/Spark-Pipelines-in-the-Cloud-with-Alluxio-by-Bin-Fan-27-2048.jpg)
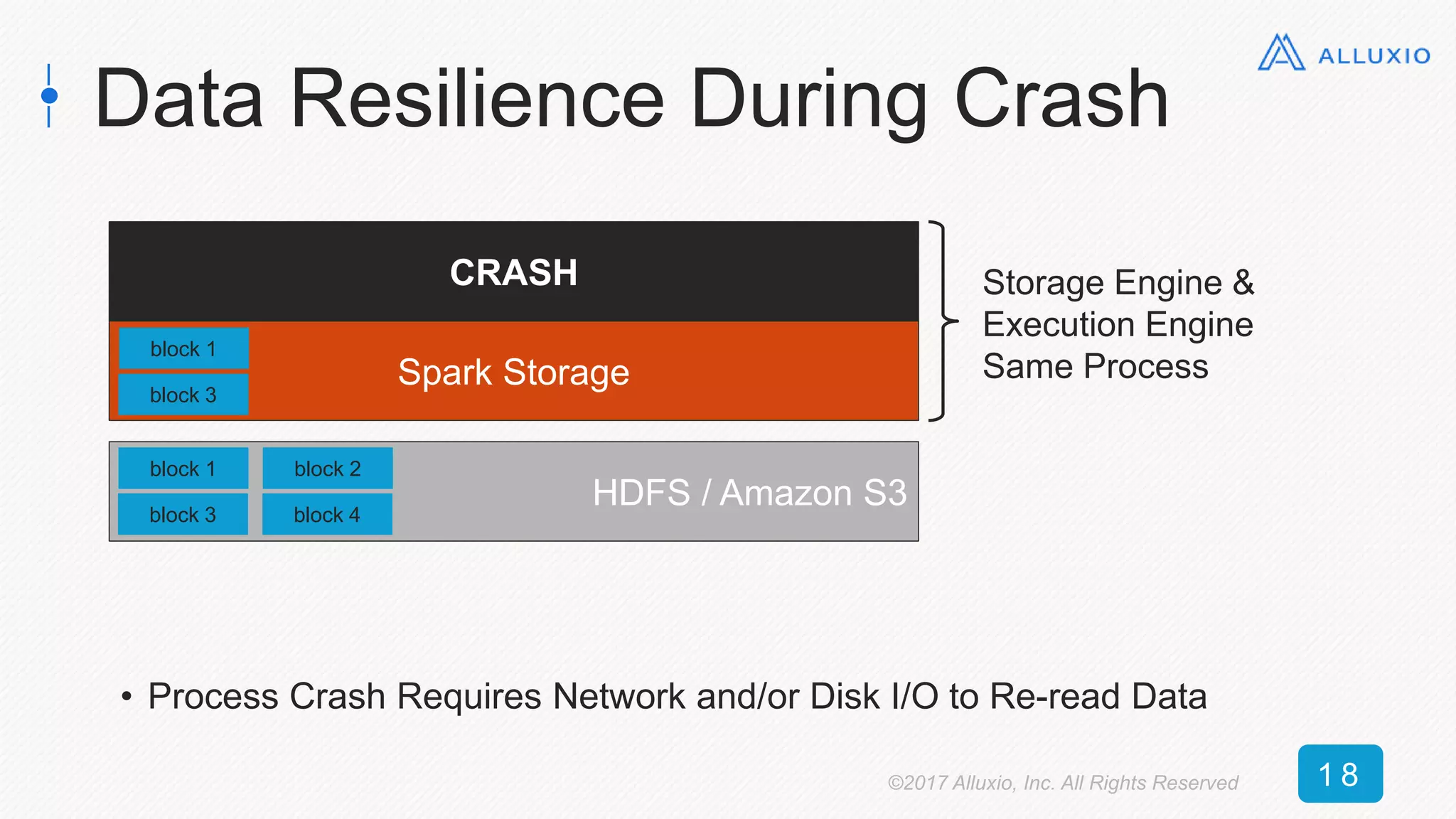
![0 100 200 300 400 500 600 700 800
Alluxio
(textFile)
Alluxio
(objectFile)
No Alluxio
Time [seconds]
7x speedup
16x speedup
New Context: Read 50 GB RDD
(S3)
©2017 Alluxio, Inc. All Rights Reserved 2 8](https://image.slidesharecdn.com/2017-08-05usingalluxiowithspark-171011211447/75/Spark-Pipelines-in-the-Cloud-with-Alluxio-by-Bin-Fan-28-2048.jpg)
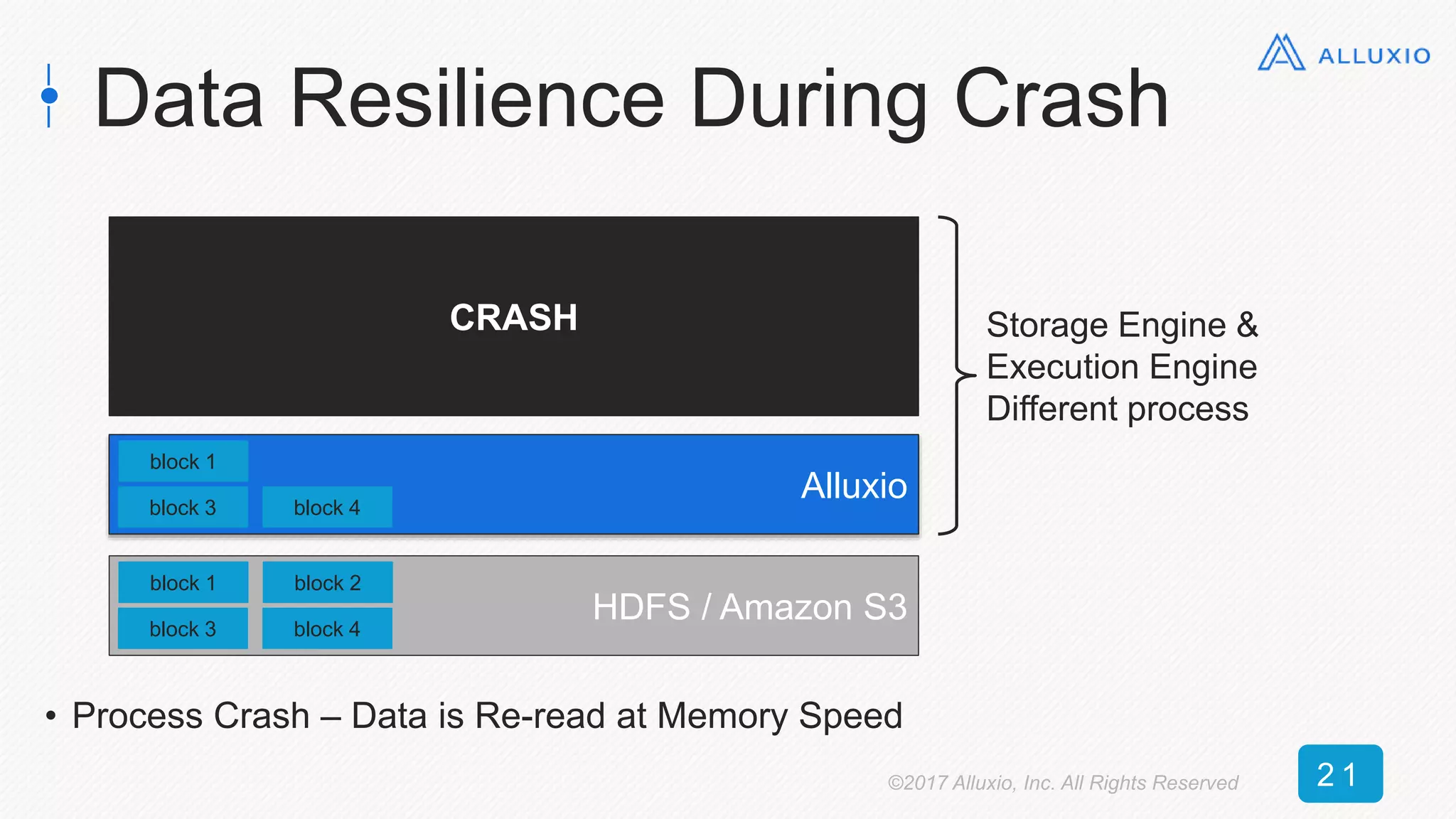
![Reading Cached DataFrame
(parquet)
0
50
100
150
200
250
0 5 10 15 20 25 30 35 40 45 50
Time[seconds]
DataFrame Size [GB]
Alluxio (textFile) MEMORY_ONLY_SER MEMORY_ONLY
©2017 Alluxio, Inc. All Rights Reserved 2 9](https://image.slidesharecdn.com/2017-08-05usingalluxiowithspark-171011211447/75/Spark-Pipelines-in-the-Cloud-with-Alluxio-by-Bin-Fan-29-2048.jpg)
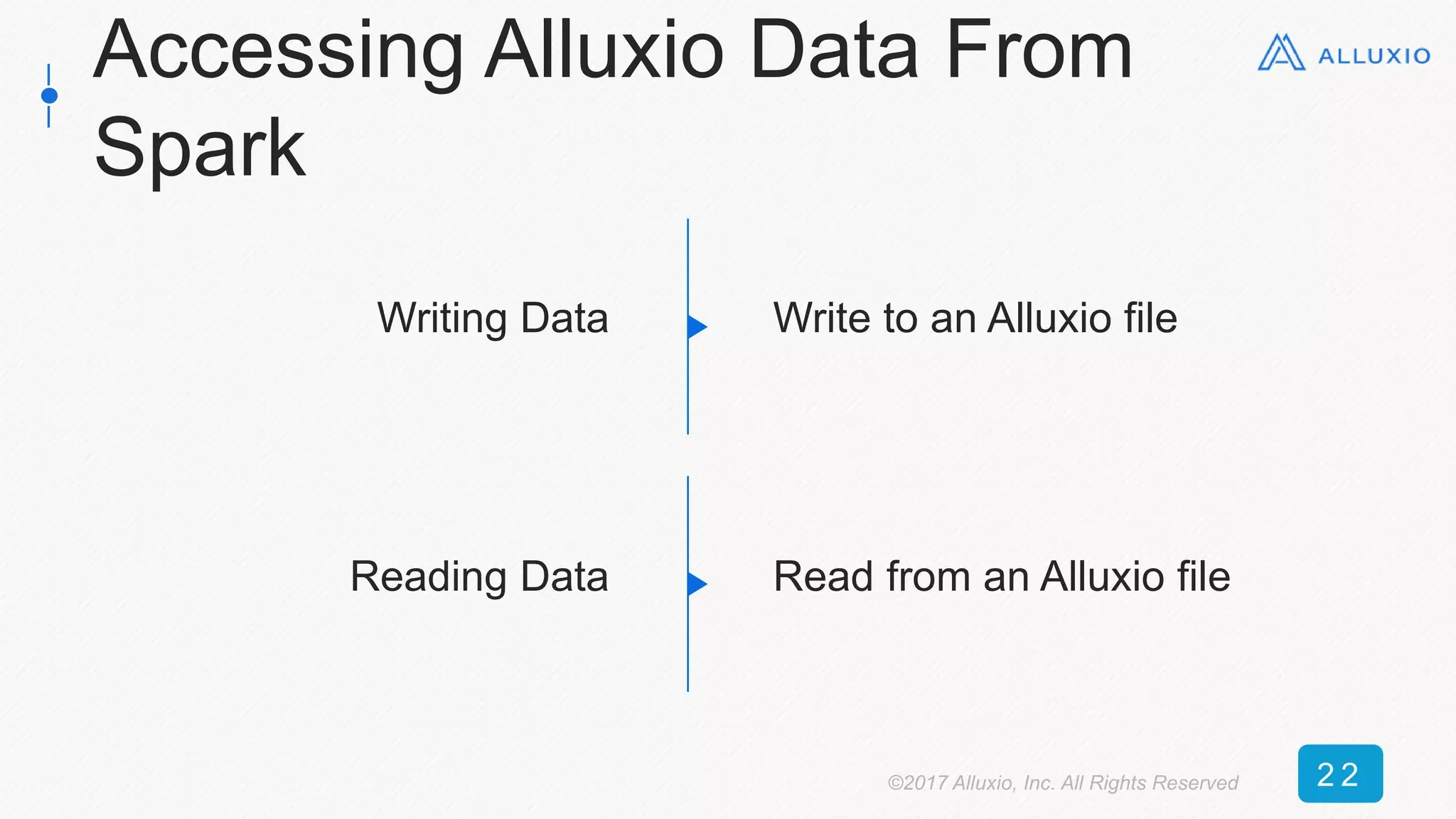
![New Context: Read 50 GB DataFrame
(S3)
0 250 500 750 1000 1250 1500 1750
Alluxio
No Alluxio
Time [seconds]
10x average speedup, 17x peak speedup
©2017 Alluxio, Inc. All Rights Reserved 3 0](https://image.slidesharecdn.com/2017-08-05usingalluxiowithspark-171011211447/75/Spark-Pipelines-in-the-Cloud-with-Alluxio-by-Bin-Fan-30-2048.jpg)

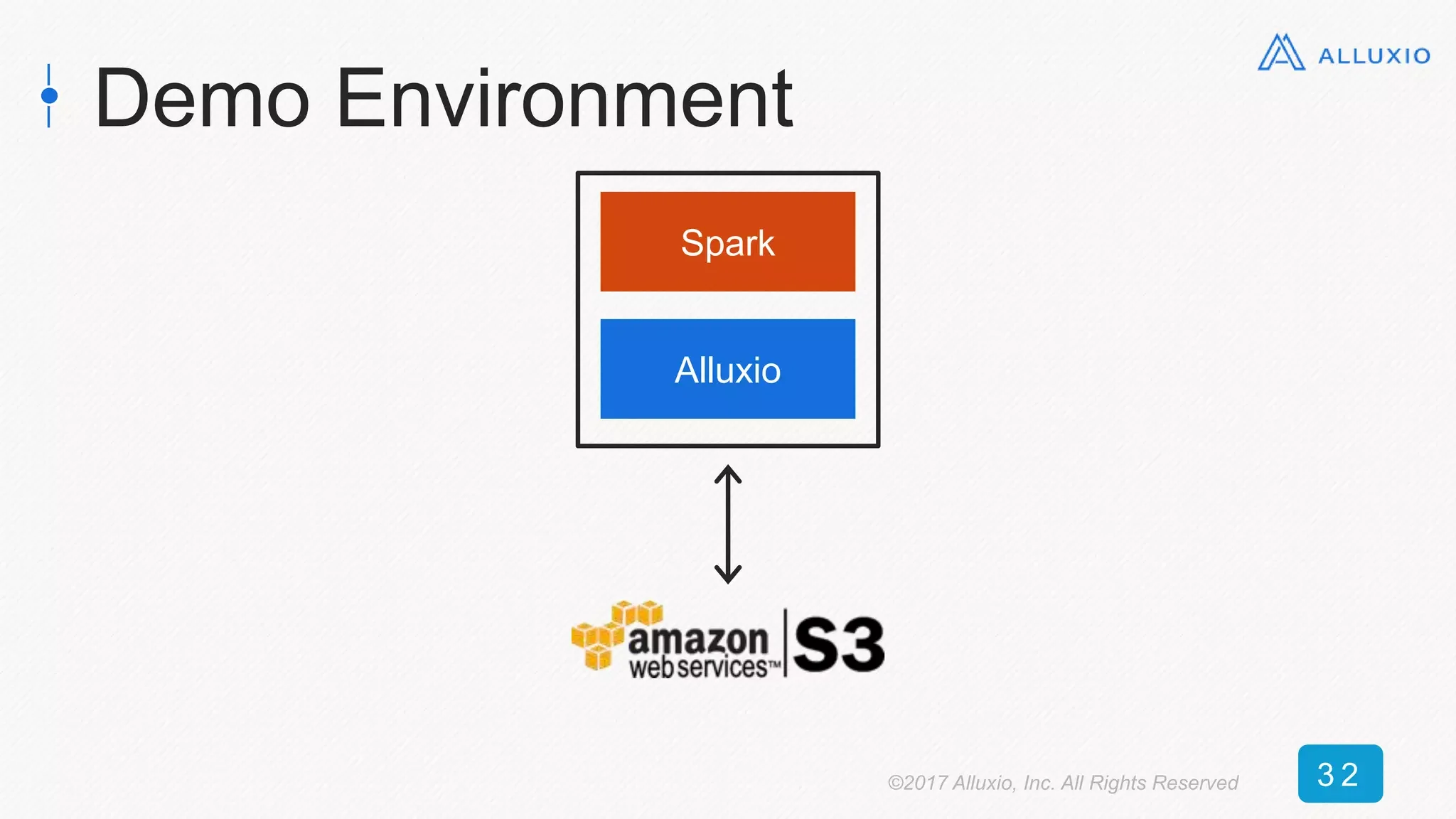



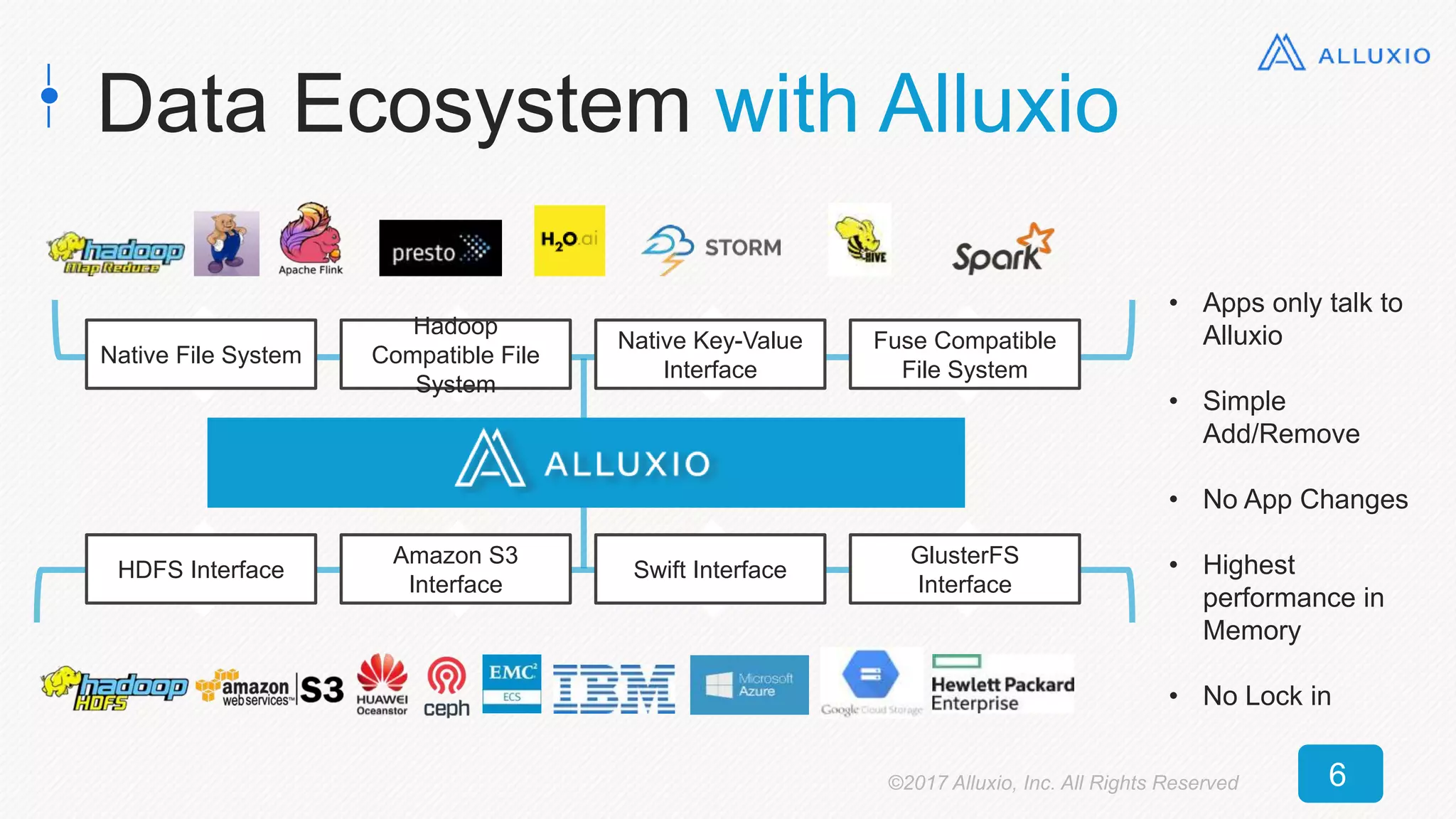
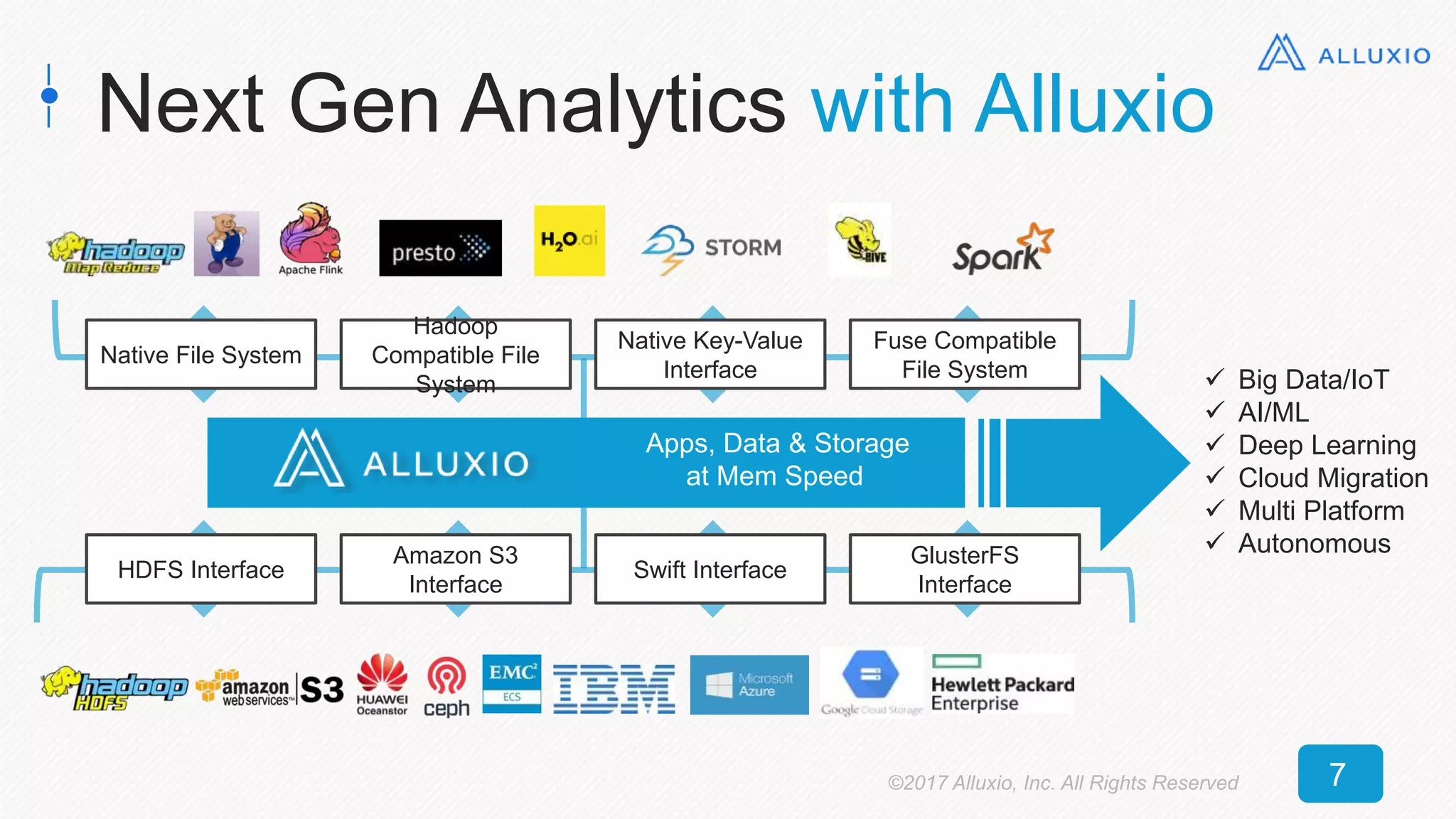
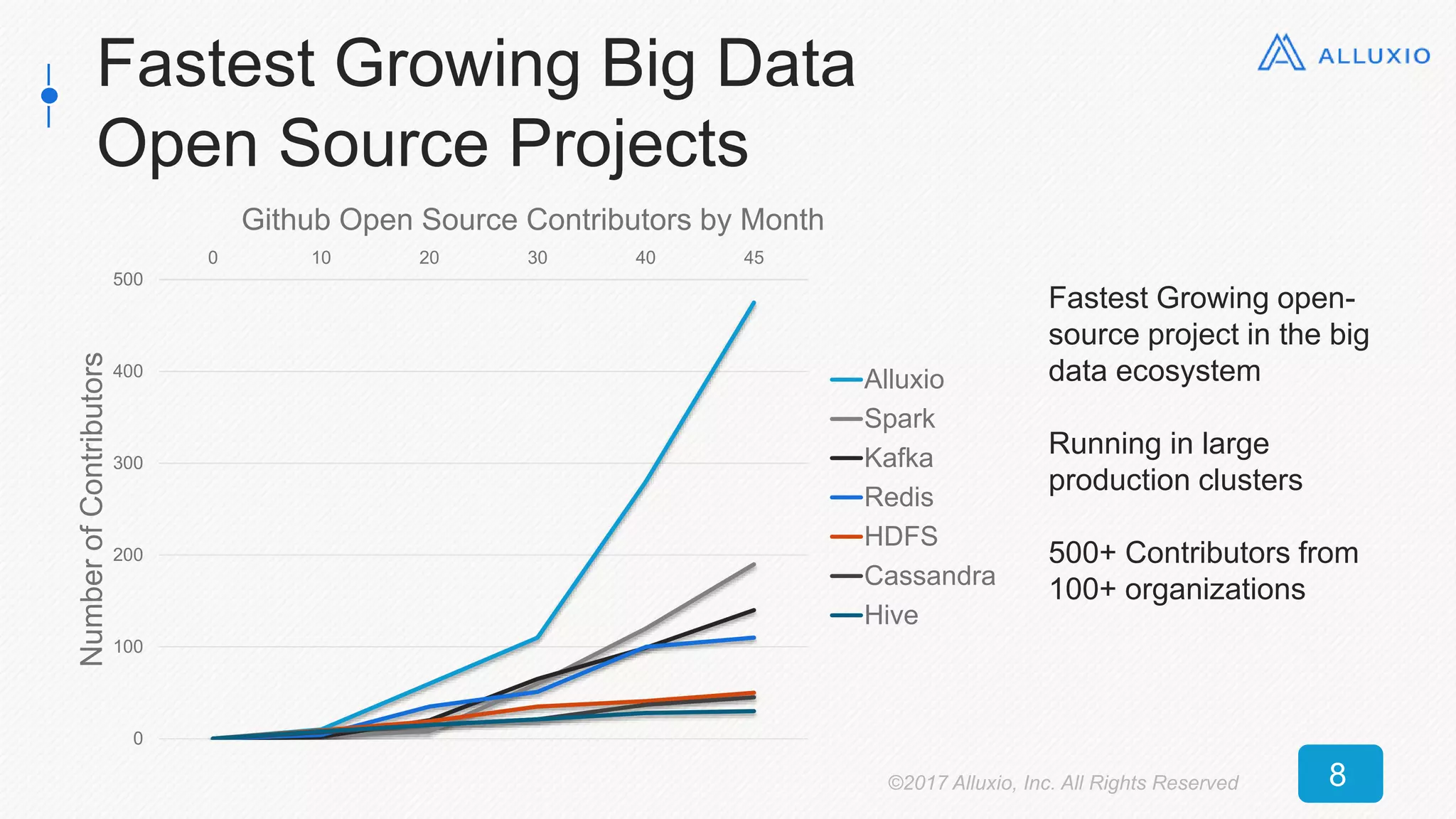
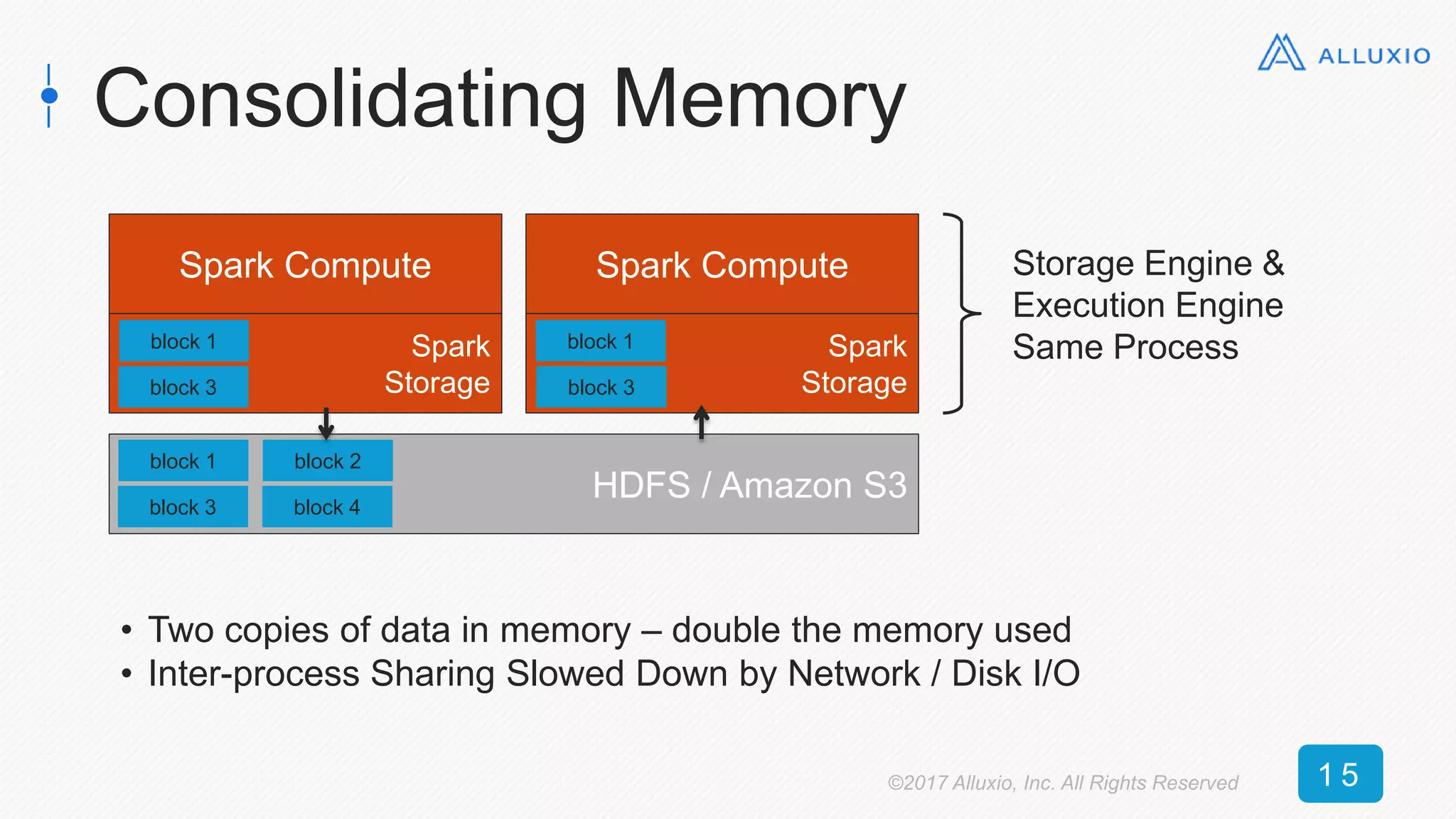
The document presents an overview of Alluxio, a storage solution that enhances performance when used alongside Spark in big data ecosystems. It outlines various use cases, including improvements in operational efficiency and speed of data queries, showcasing case studies that demonstrate significant performance gains with Alluxio. The conclusion emphasizes Alluxio's ease of use, predictable performance, and compatibility with various storage systems.








































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












