Downloaded 25 times




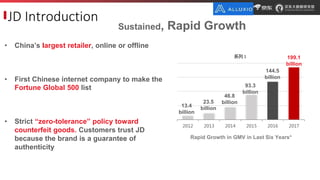

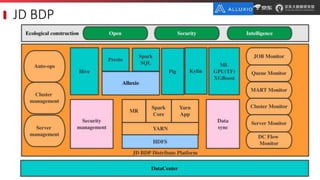

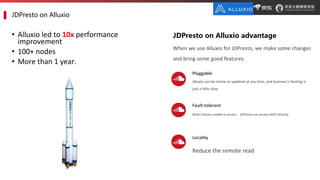
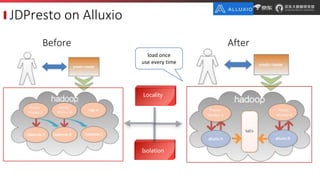
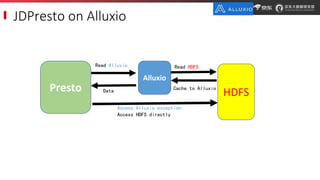
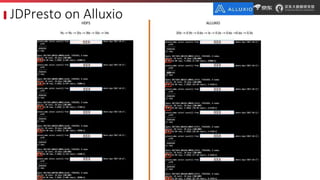
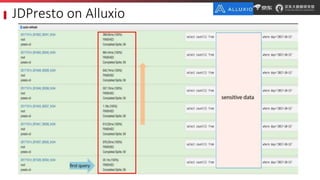
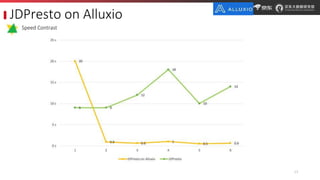
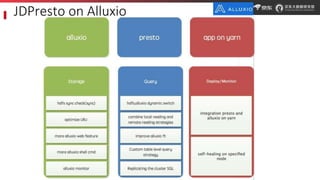

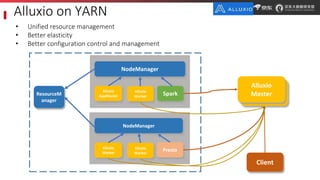

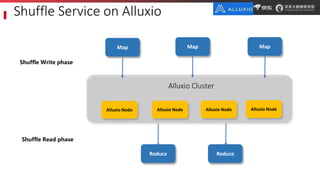
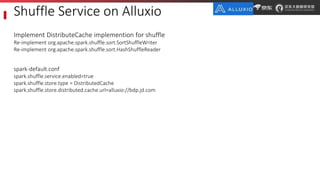
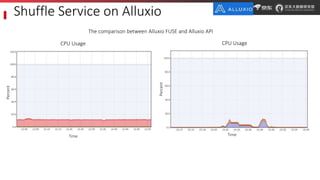
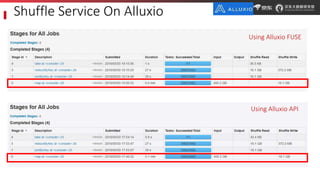
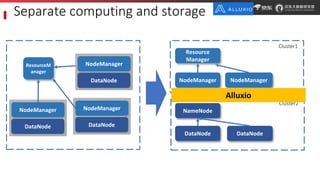
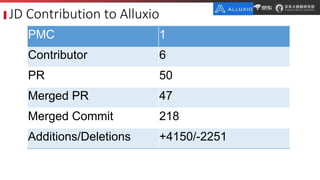
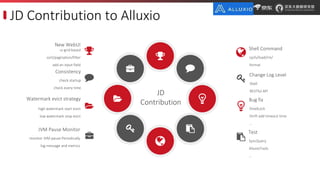


JD.com is China's largest retailer that uses Alluxio as a fault-tolerant optimization component in its computation frameworks. Alluxio improves JDPresto performance by 10x on 100+ nodes by enabling data caching and reducing remote reads. Ongoing exploration includes running Alluxio on YARN for resource management, using Alluxio as a shuffle service to address disk I/O bottlenecks, and separating computing and storage across clusters for further optimization. JD has also contributed various features and fixes to Alluxio, including a new WebUI, eviction strategies, JVM monitoring, shell commands, and tests.















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







