Download to read offline


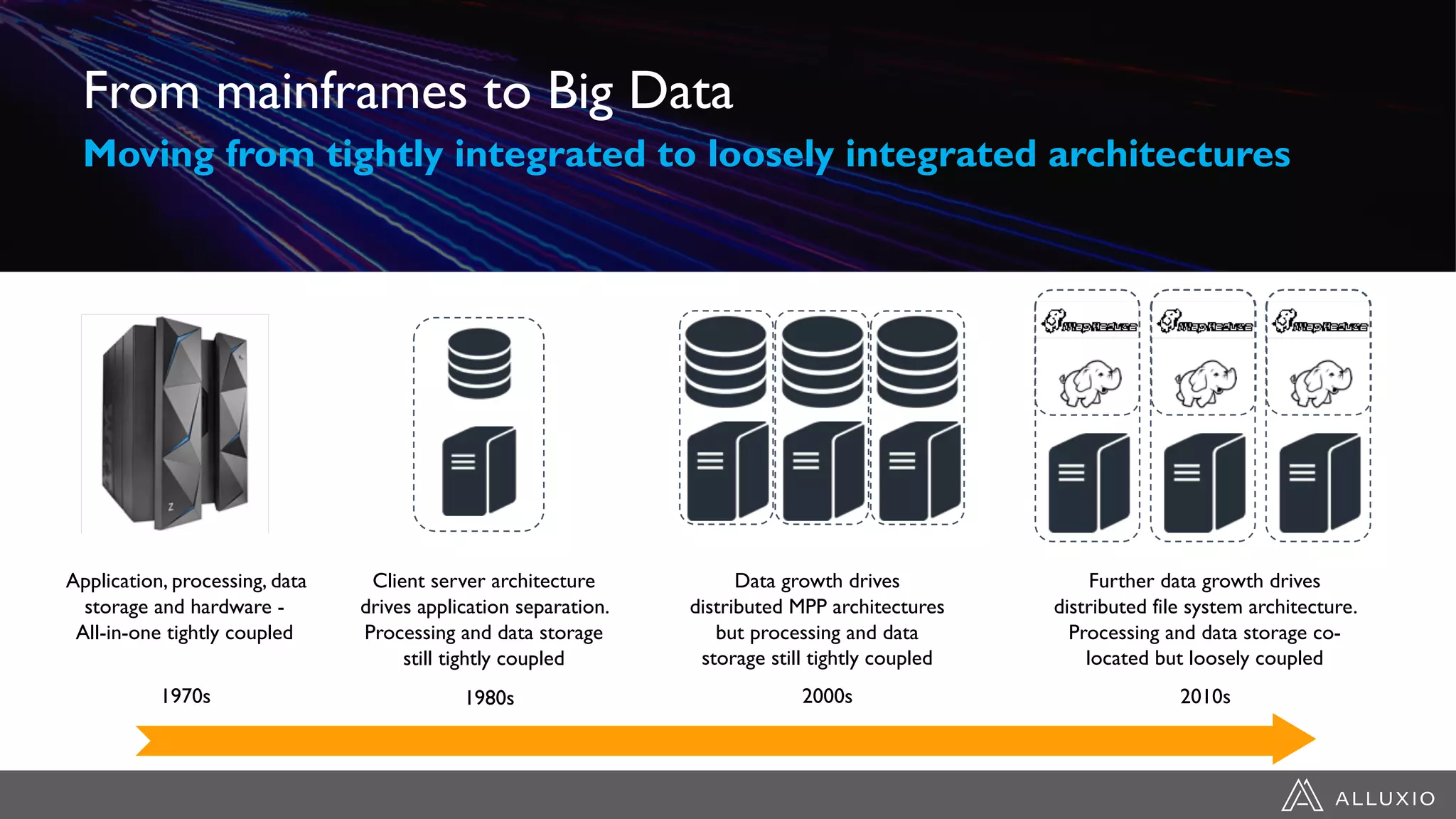
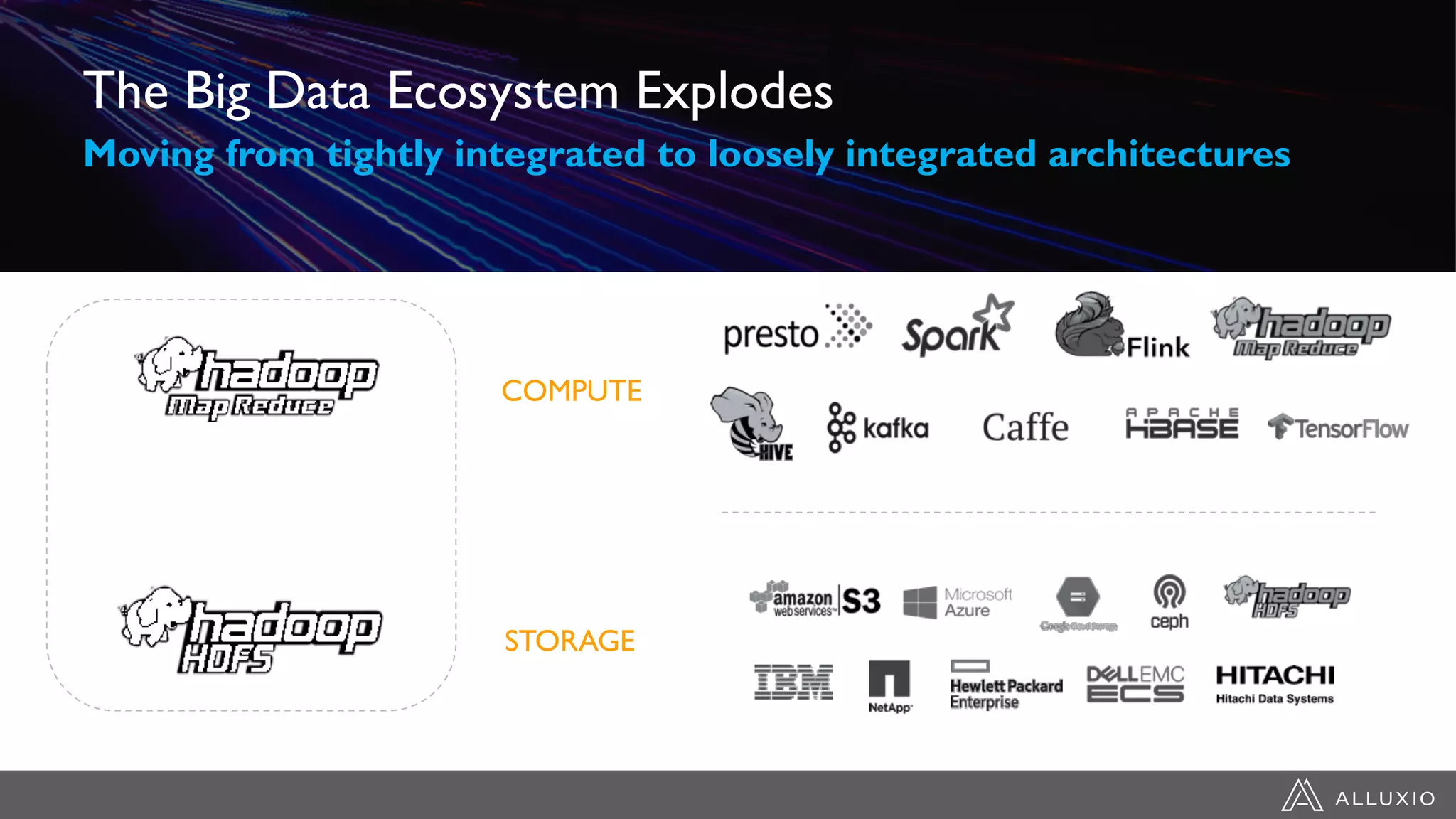








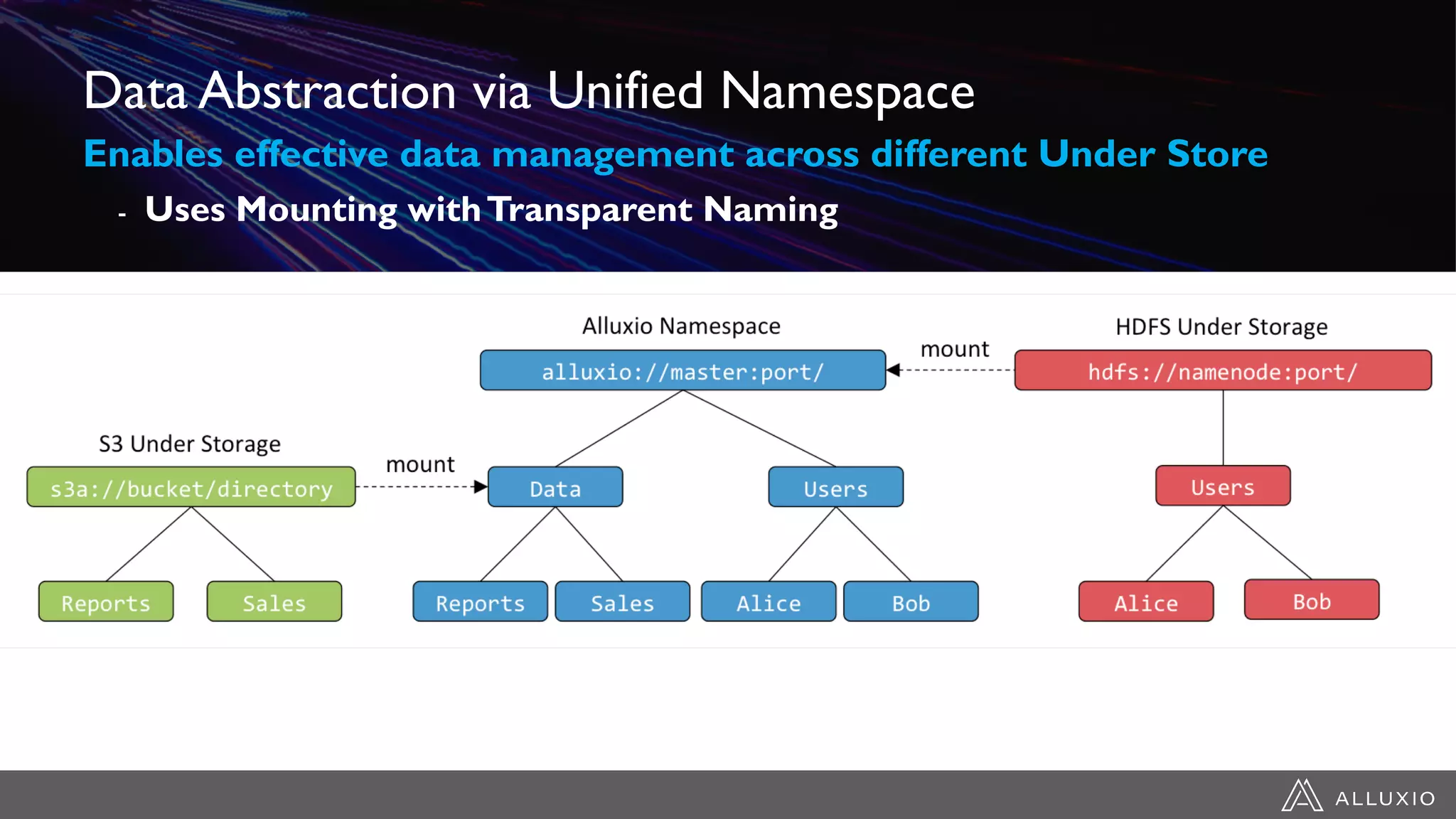


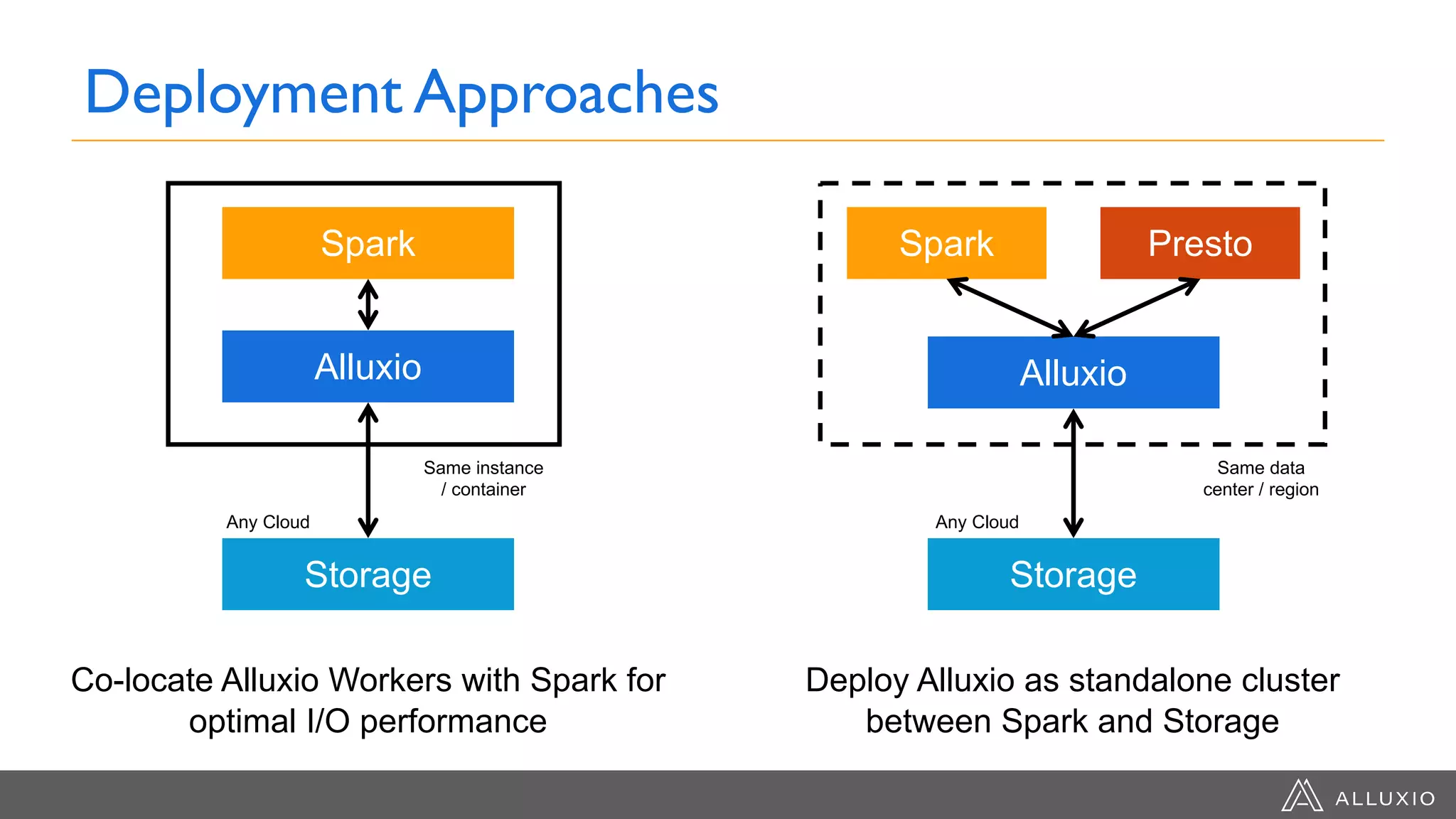
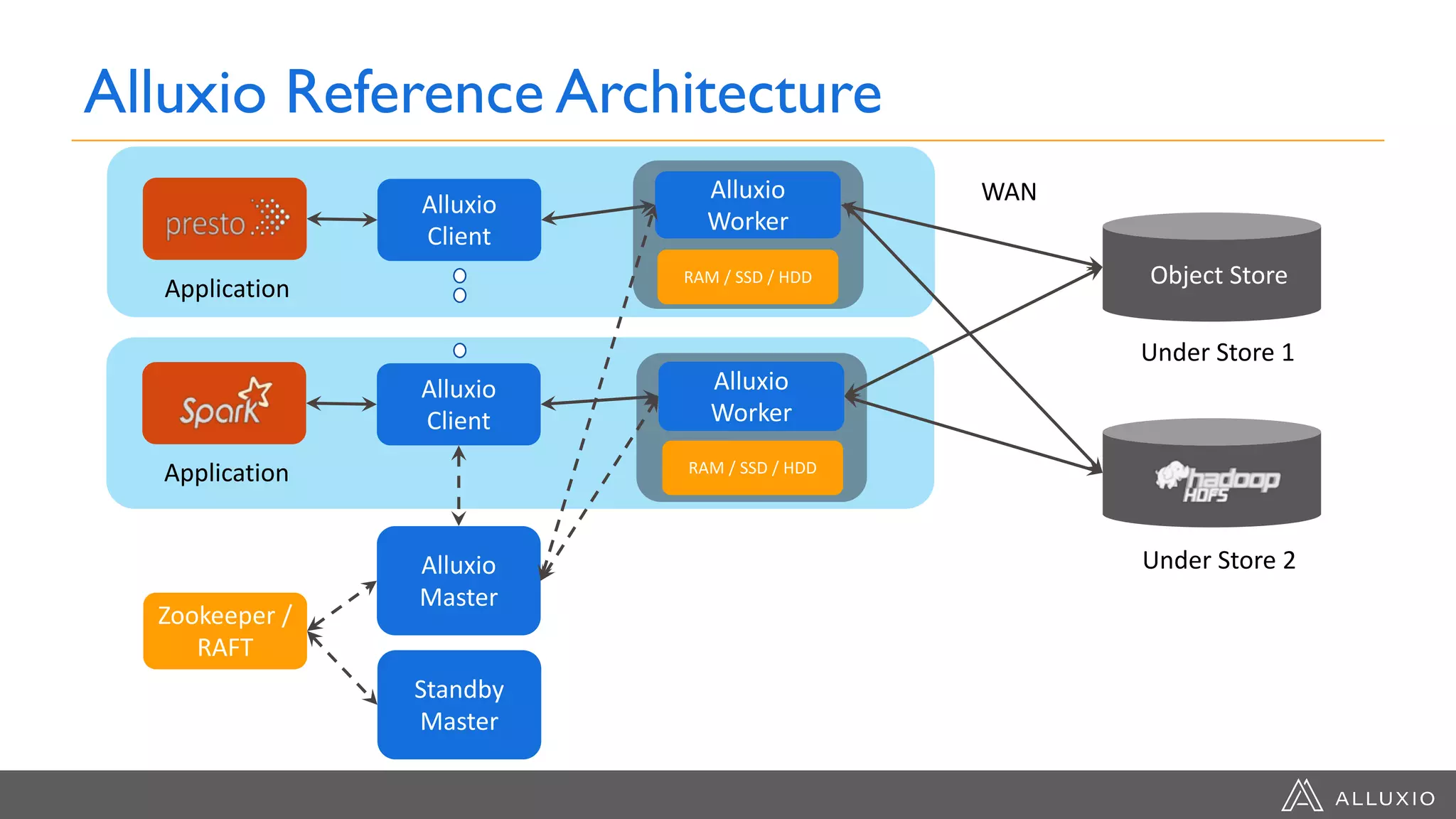








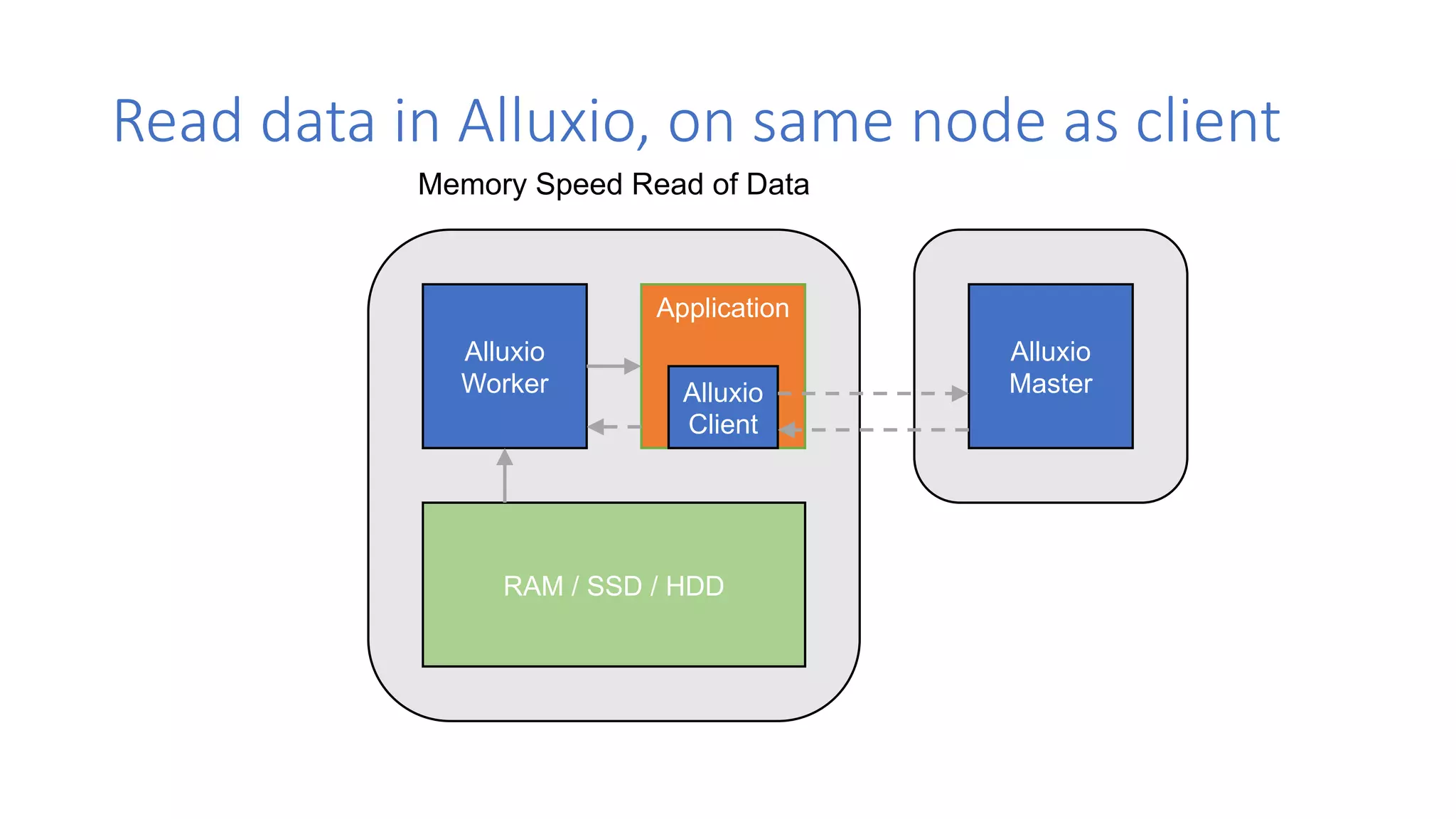
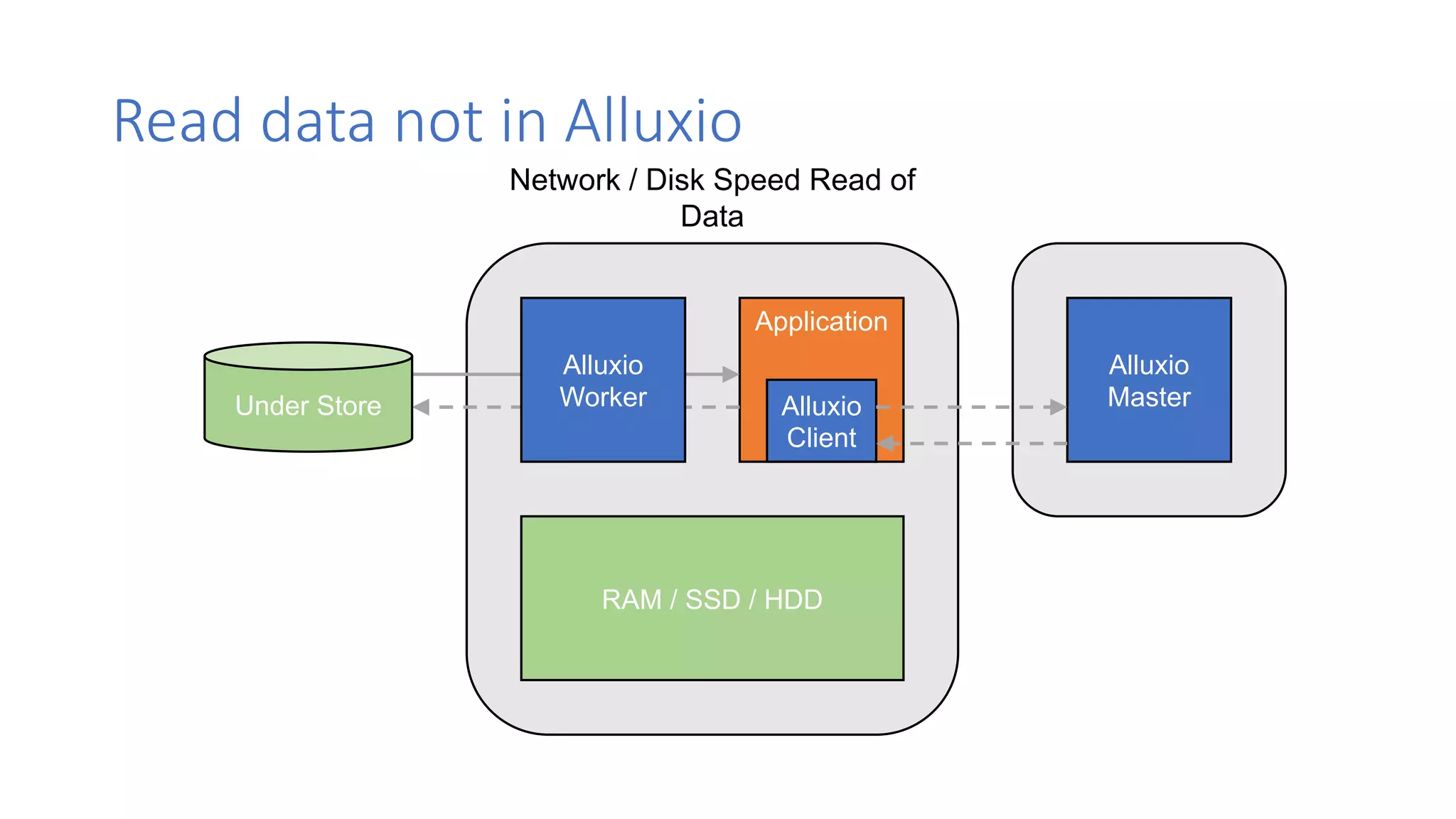

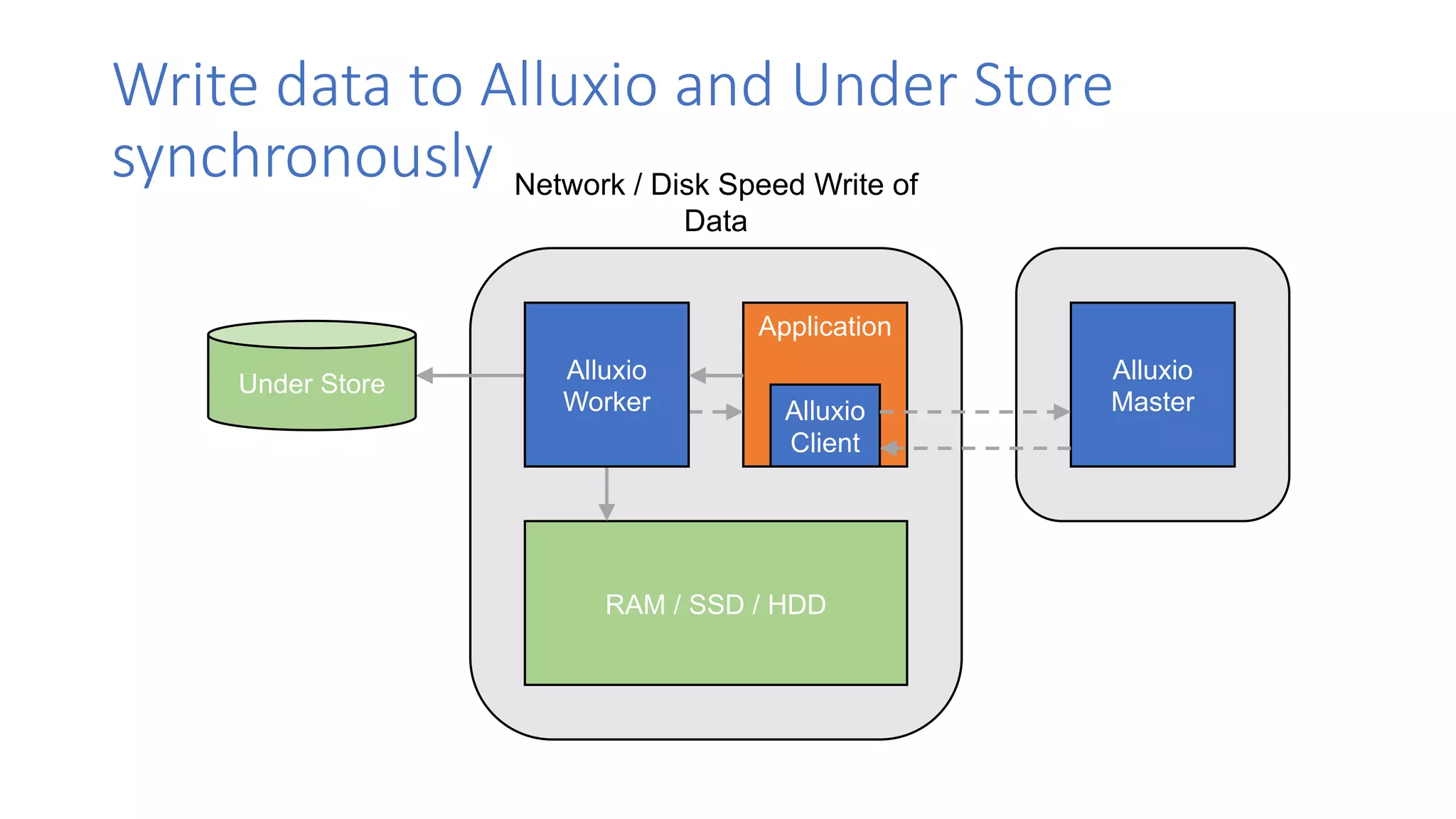






The document discusses the evolution of data architecture moving from tightly coupled systems to loosely integrated architectures, emphasizing the importance of storage-independent compute. It highlights Alluxio's innovations like a unified namespace and intelligent multi-tiering to improve data accessibility and performance across various storage systems. Real-world use cases demonstrate Alluxio's effectiveness in enhancing data access speed and operational efficiency in big data and machine learning environments.






















































































