Download to read offline







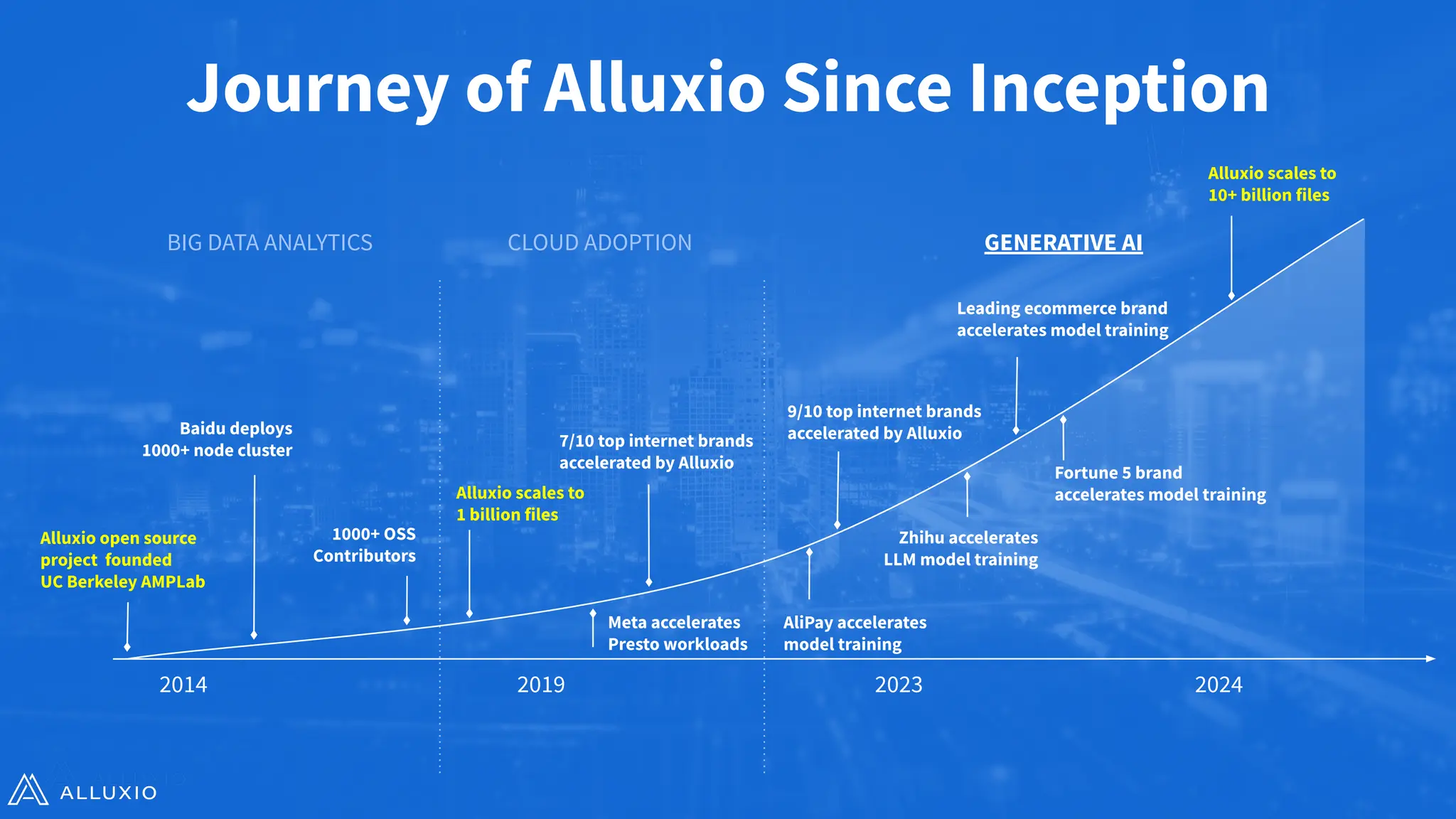
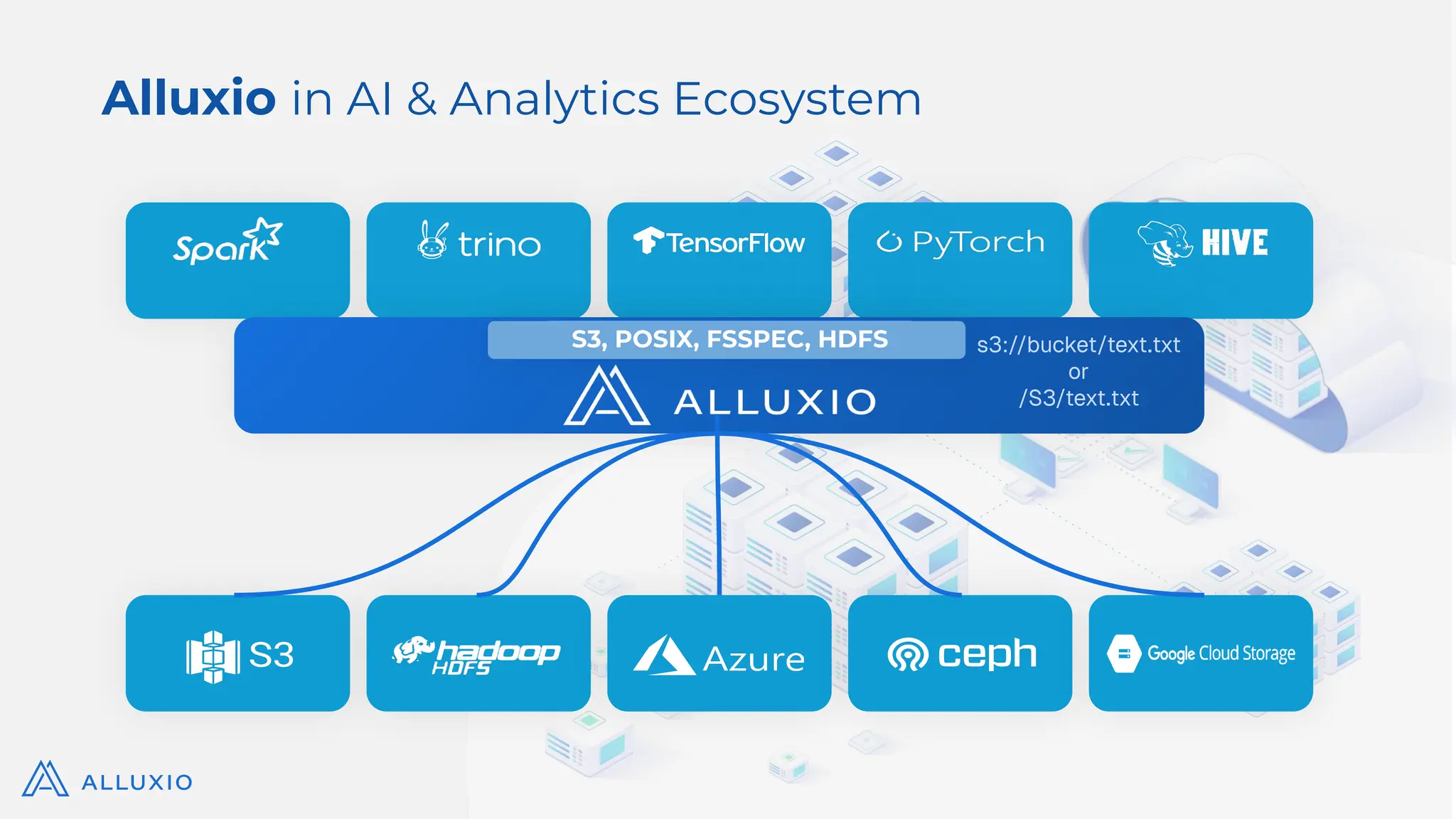

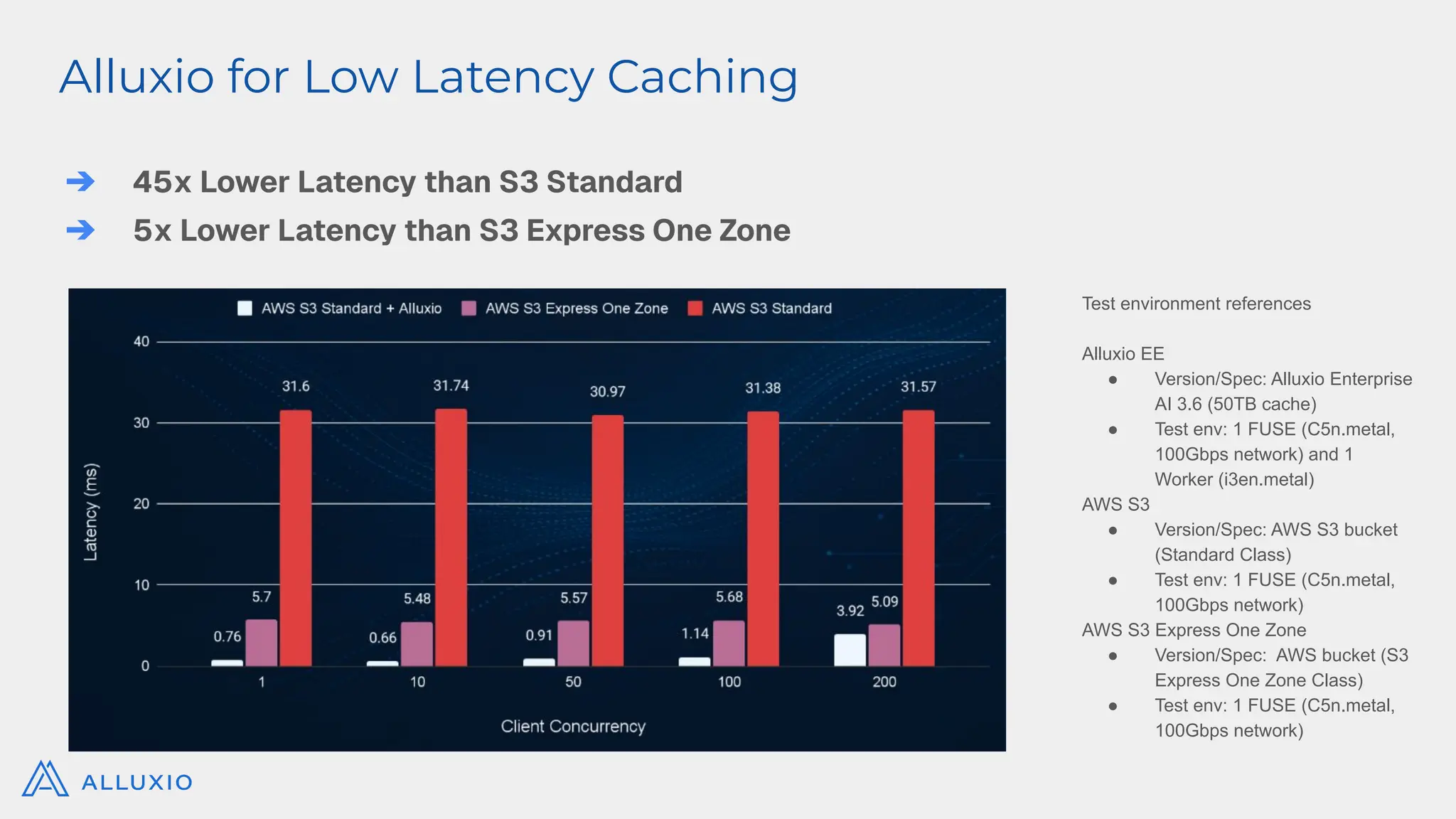
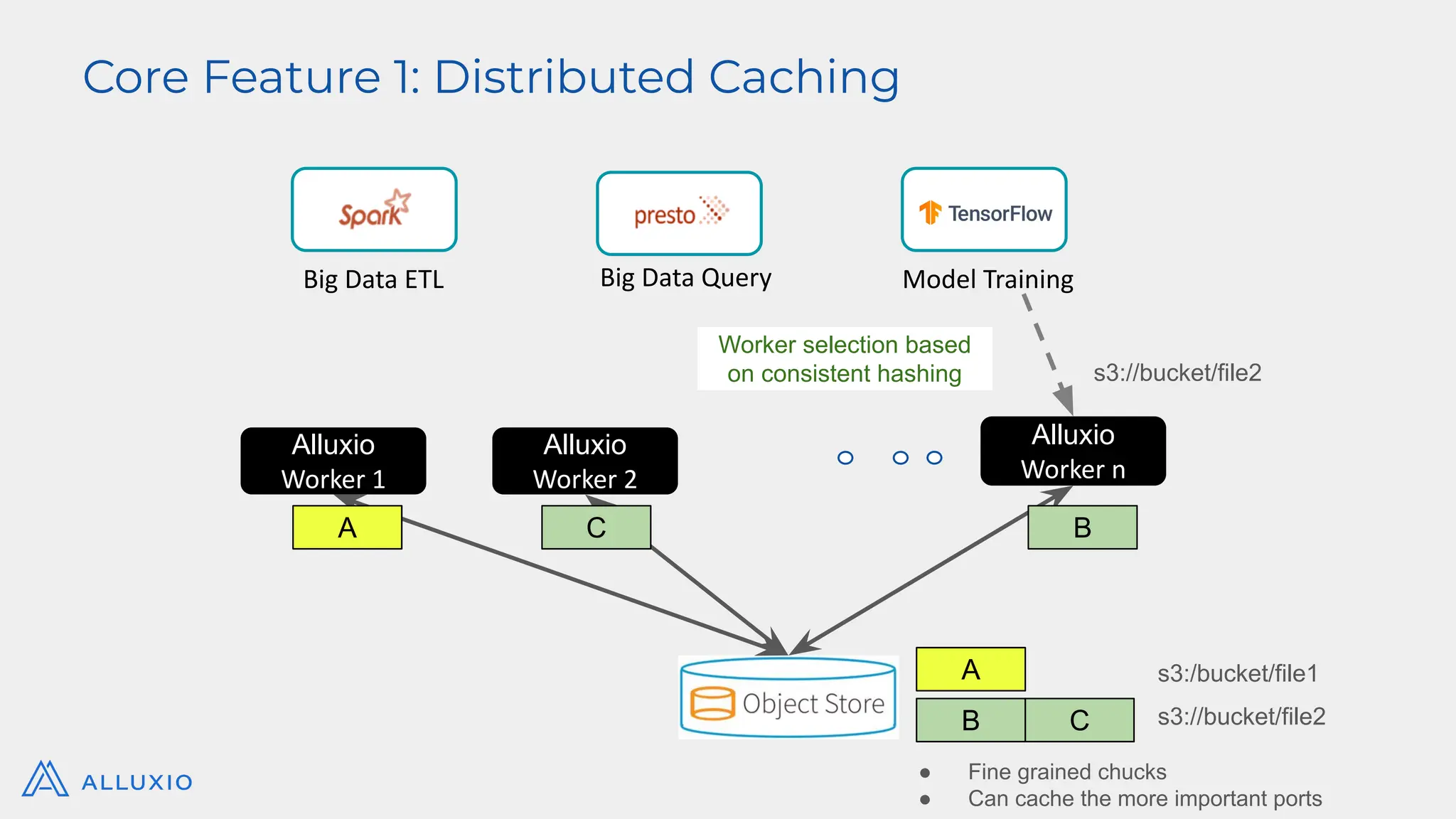
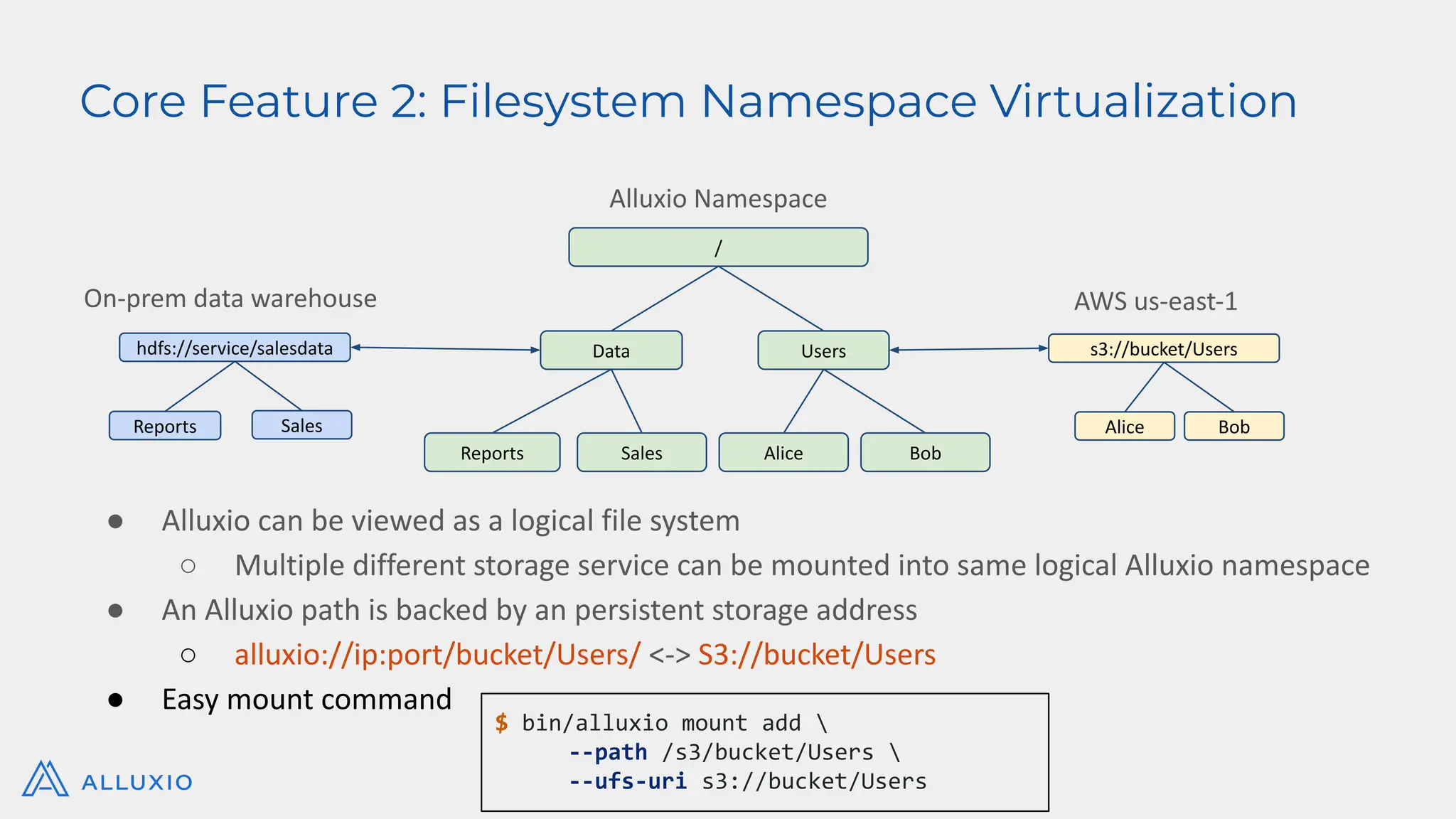
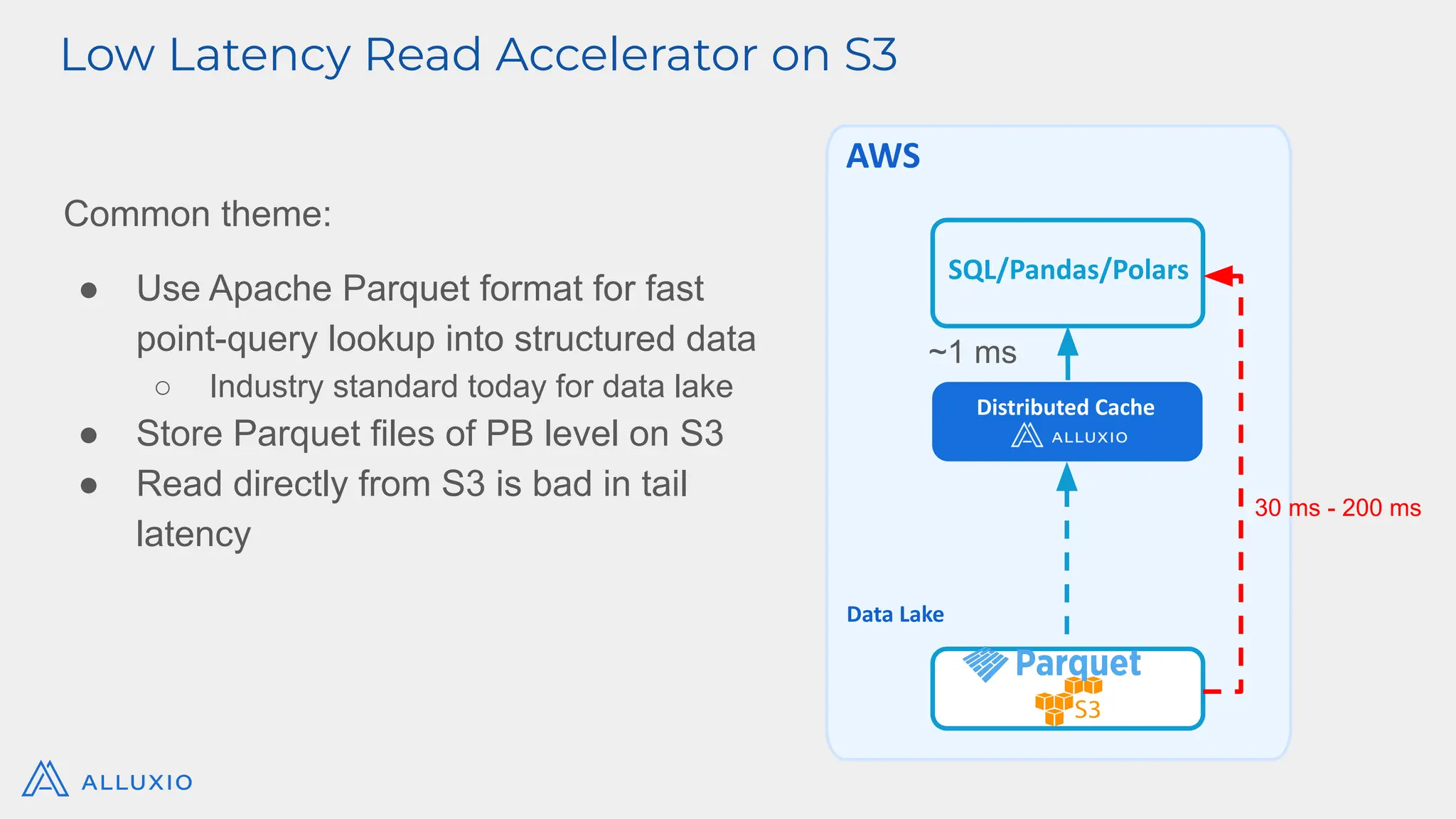
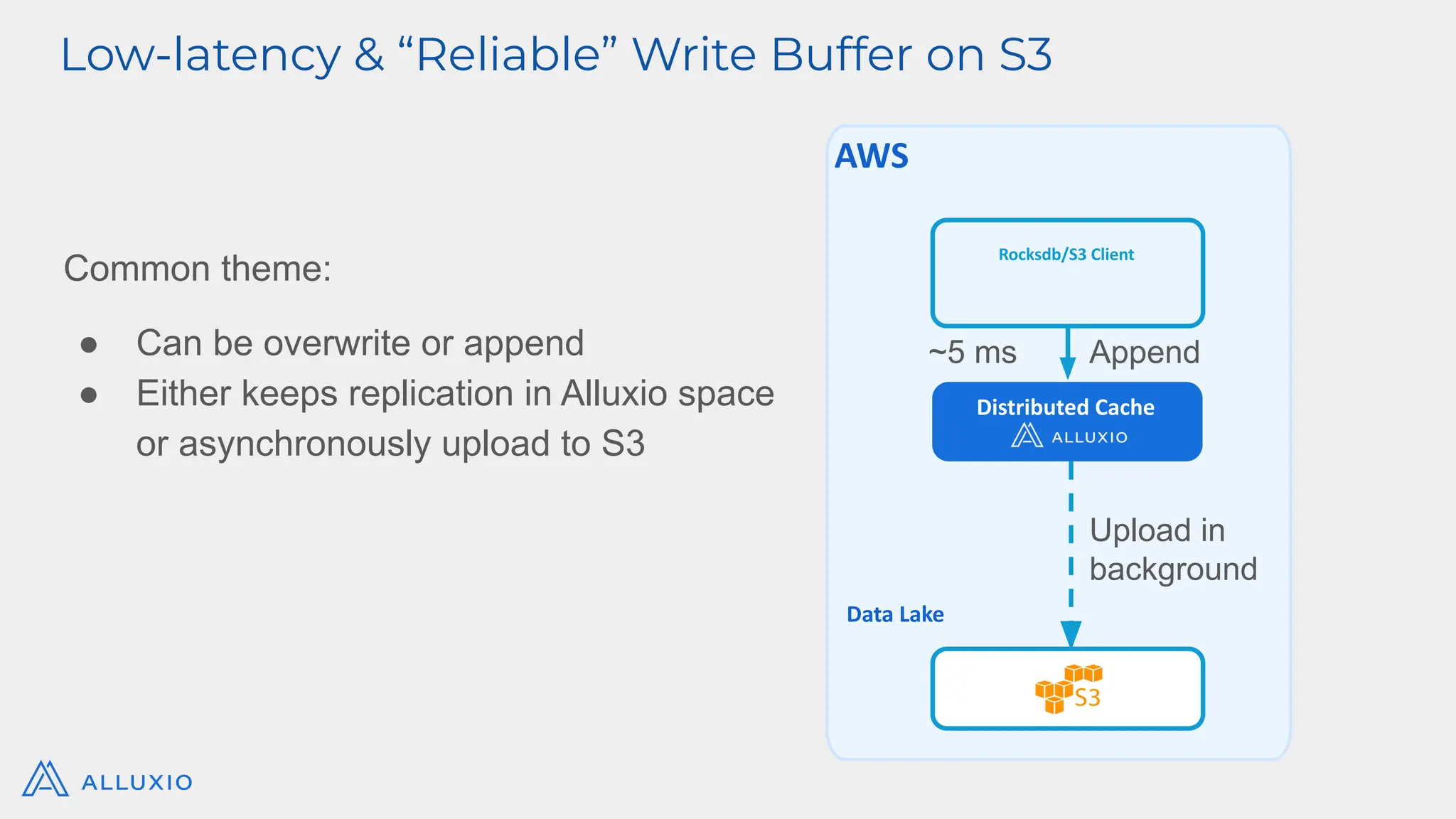
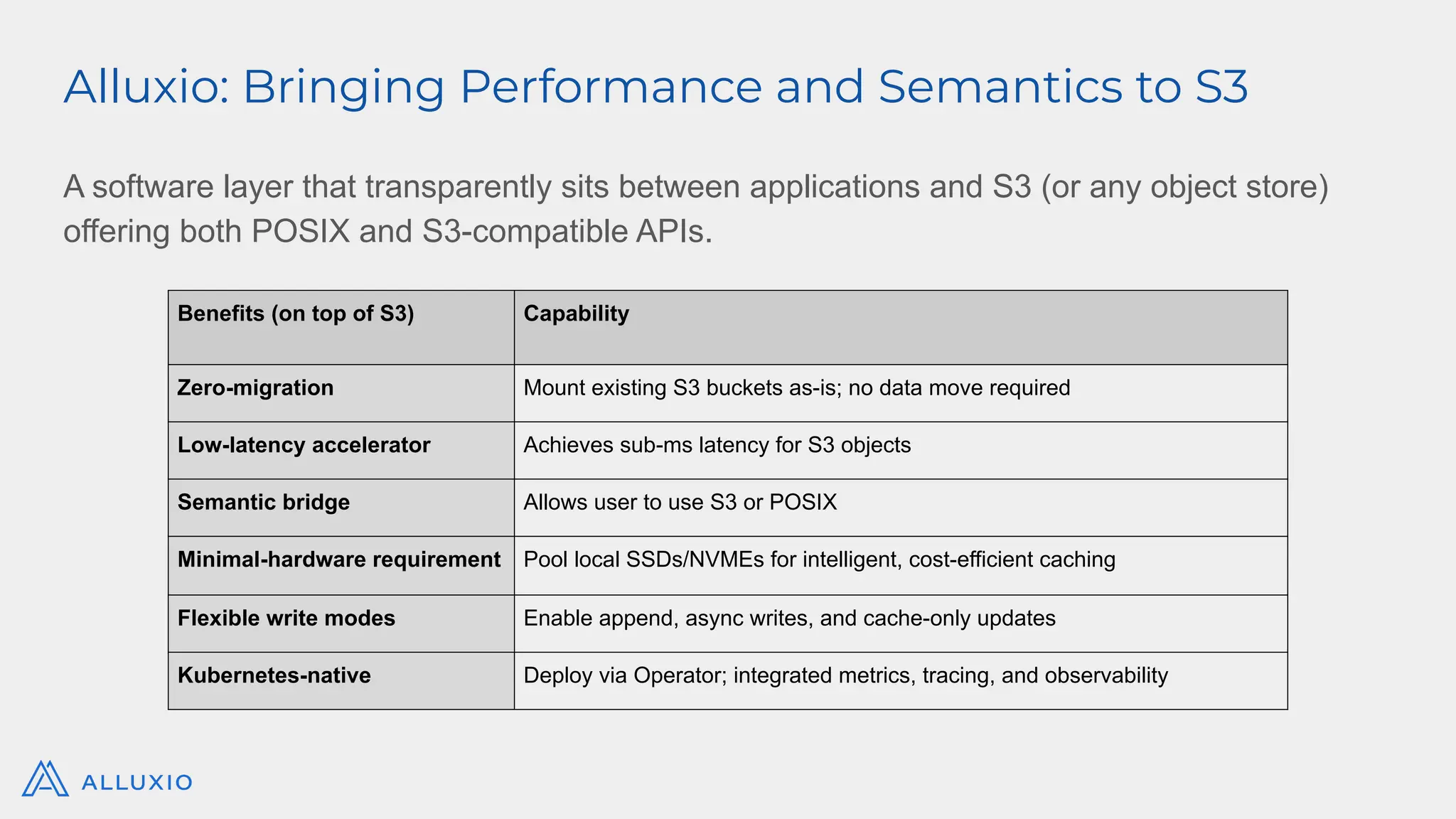








Alluxio Webinar Oct 28, 2025 For more Alluxio Events: https://www.alluxio.io/events/ Speaker: Jingwen Ouyang (Senior Product Manager @ Alluxio) Amazon S3 and other cloud object stores have become the de facto storage system for organizations large and small. And it’s no wonder why. Cloud object stores deliver unprecedented flexibility with unlimited capacity that scales on demand and ensures data durability out-of-the-box at unbeatable prices. Yet as workloads shift toward real-time AI, inference, feature stores, and agentic memory systems, S3’s latency and limited semantics begin to show their limits. In this webinar, you’ll learn how to augment — rather than replace — S3 with a tiered architecture that restores sub-millisecond performance, richer semantics, and high throughput — all while preserving S3’s advantages of low-cost capacity, durability, and operational simplicity. We’ll walk through: - The key challenges posed by latency-sensitive, semantically rich workloads (e.g. feature stores, RAG pipelines, write-ahead logs) - Why “just upgrading storage” isn’t sufficient — the bottlenecks in metadata, object access latency, and write semantics - How Alluxio transparently layers on top of S3 to provide ultra-low latency caching, append semantics, and zero data migration with both FSx-style POSIX access and S3 API access. - Real-world results: achieving sub-ms TTFB, >90% GPU utilization in ML training, 80X faster feature store query response times, and dramatic cost savings from reduced S3 operations - Trade-offs, deployment patterns, and best practices for integrating this tiered approach in your AI/analytics stack



































































