Download to read offline



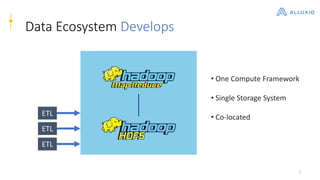

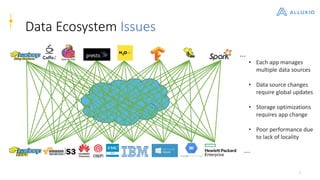

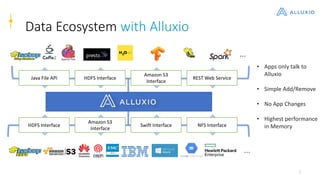


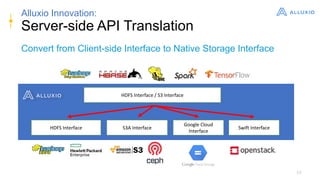
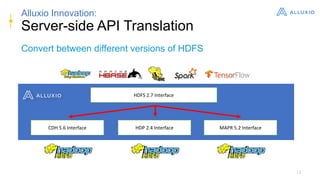
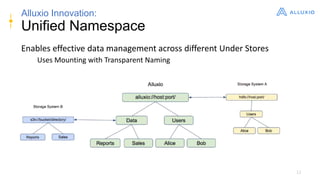

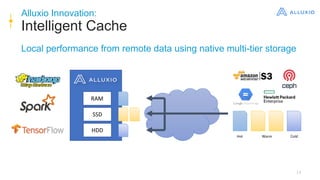
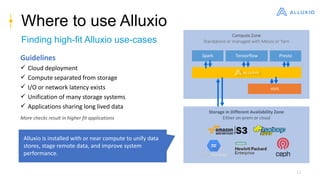




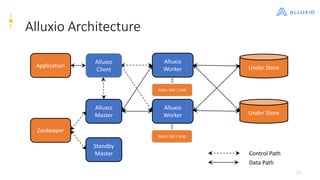
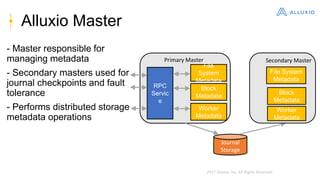
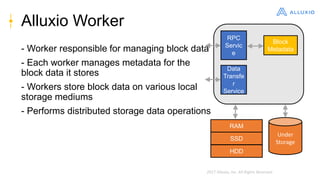

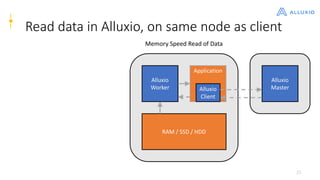
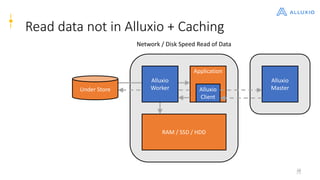
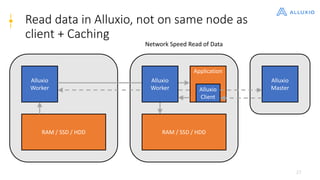
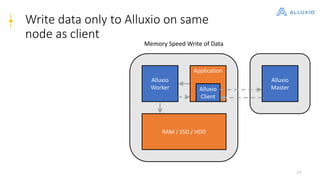
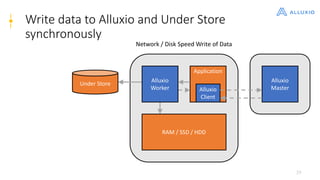


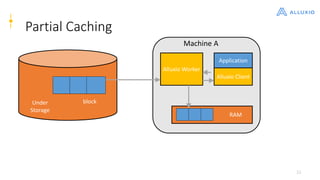
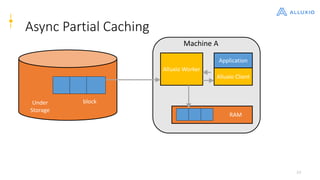

Alluxio is a data orchestration platform that unifies data access at memory speed across multiple storage systems. It provides a unified namespace and intelligent caching to enable fast access to remote data. Alluxio's architecture includes a master that manages metadata, workers that manage block data on local storage, and clients that access data. New features in version 1.7.0 include asynchronous caching, Kubernetes integration, tiered locality, under store synchronization, and FUSE improvements.














































































