Download to read offline



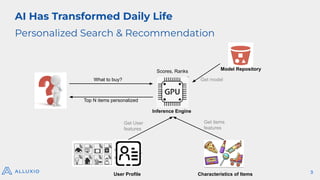
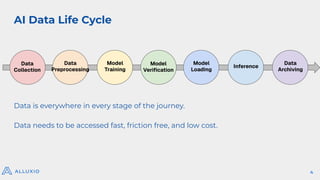


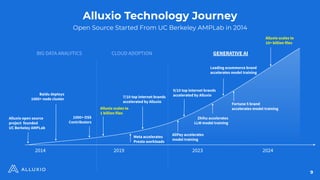




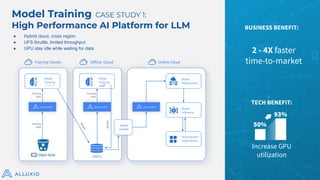







AI/ML Infra Meetup June 17, 2025 Organized by Alluxio For more Alluxio Events: https://www.alluxio.io/events/ Speaker: Jingwen Ouyang (Sr. Product Manager @ Alluxio) In this talk, Jingwen Ouyang, Senior Product Manager at Alluxio, will share how Alluxio make it easy to share and manage data from any storage to any compute engine in any environment with high performance and low cost for your model training, model inference, and model distribution workload.



































































