Download as PDF, PPTX









![Demo: Bootstrapping Alluxio with AWS EMR
aws emr create-cluster
--release-label ${RELEASE_LABEL}
--instance-count ${NUM_INSTANCES}
--instance-type ${INSTANCE_TYPE}
--applications Name=Presto Name=Hive Name=Spark
--name "${CLUSTER_NAME}"
--bootstrap-actions
Path=${BOOTSTRAP_PATH},Args=[${ALLUXIO_DOWNLOAD_URL},${ROOT_UFS_
URI}, ${ADDITIONAL_PROPERTIES}]
--configurations
file:///Users/diptiborkar/Downloads/alluxio-emr.json
--ec2-attributes KeyName=${KEY_PAIR}](https://image.slidesharecdn.com/alluxio-accelerating-spark-s3-190913233215/75/Accelerate-Spark-Workloads-on-S3-30-2048.jpg)





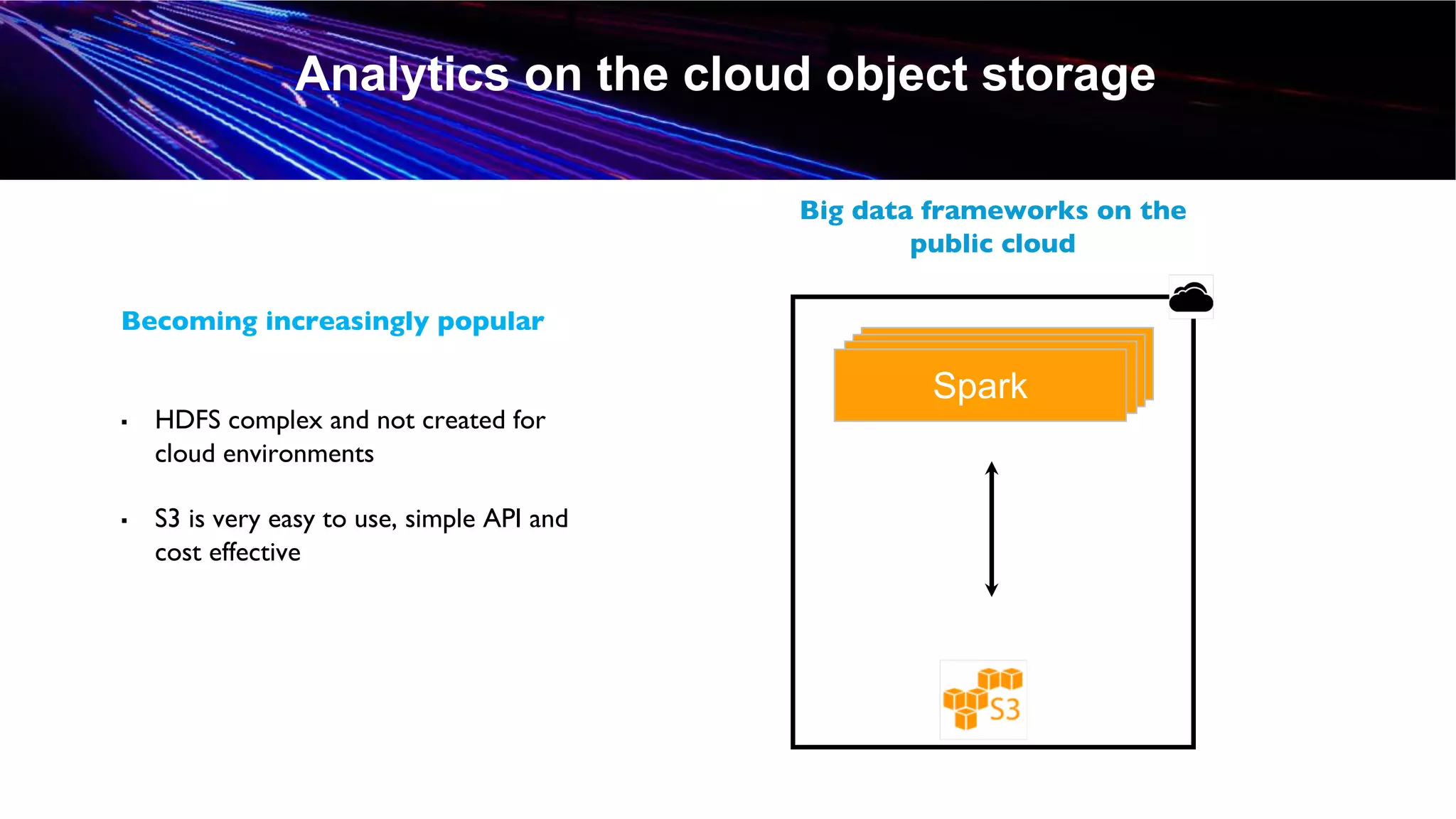
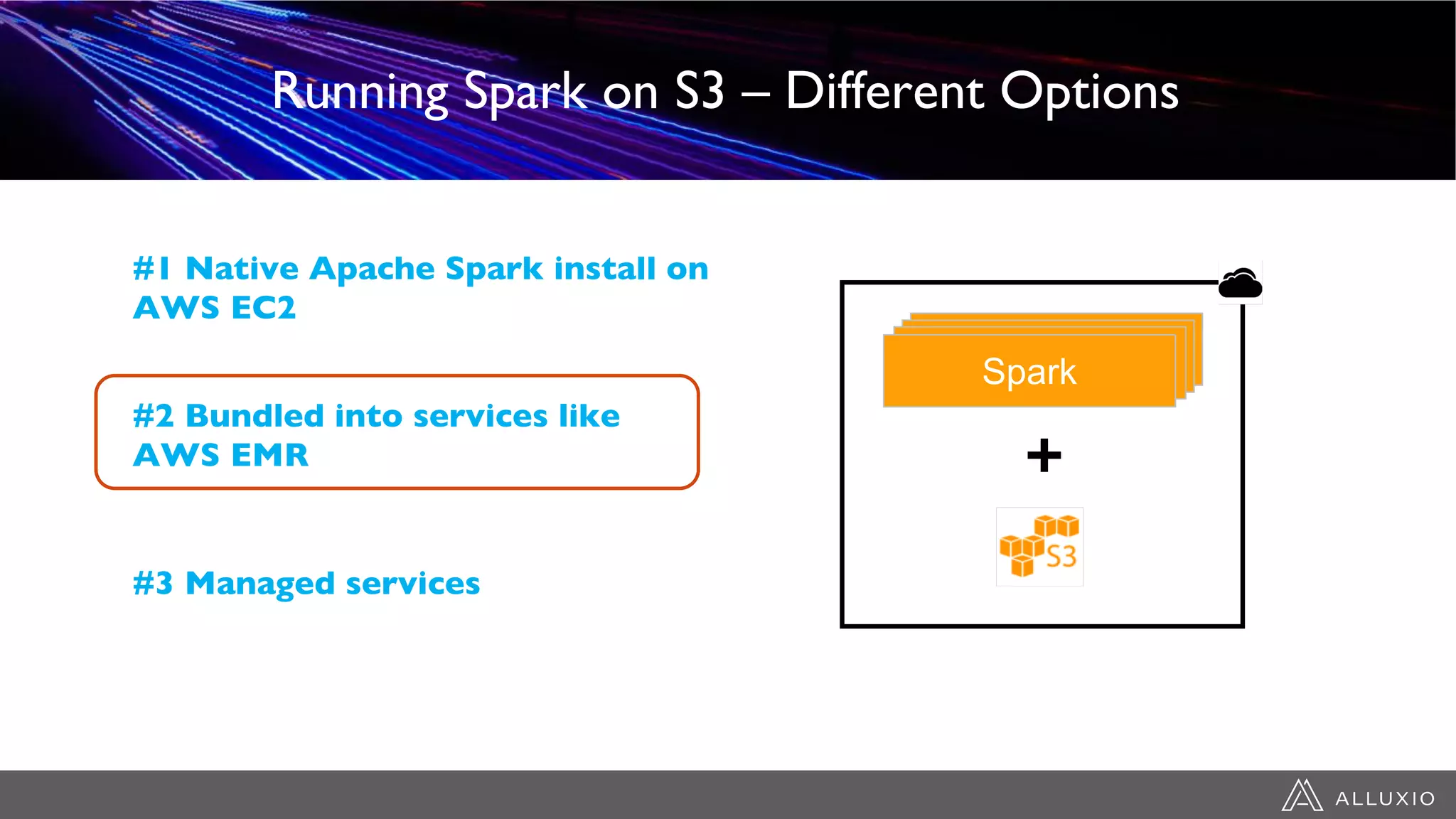
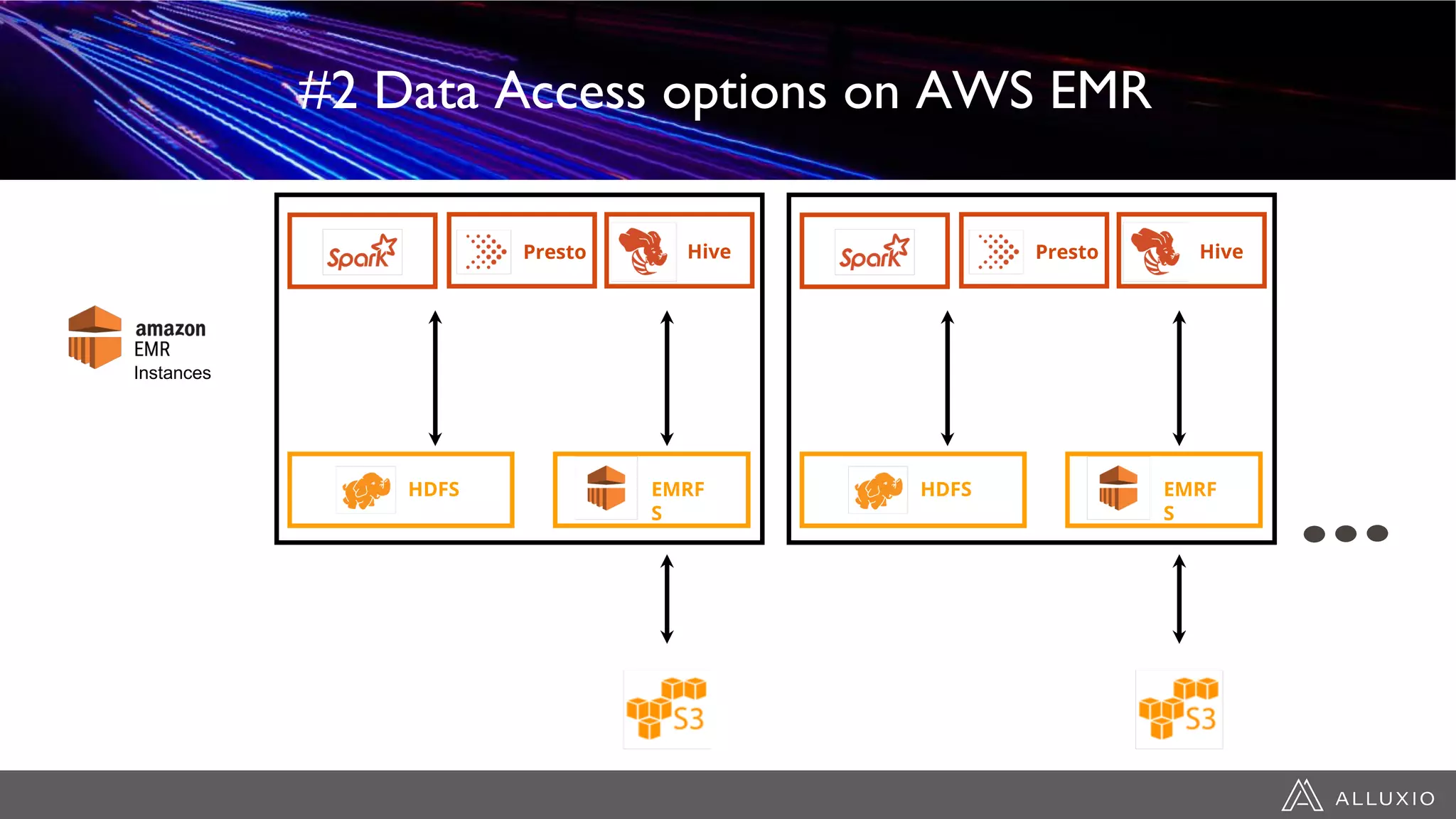
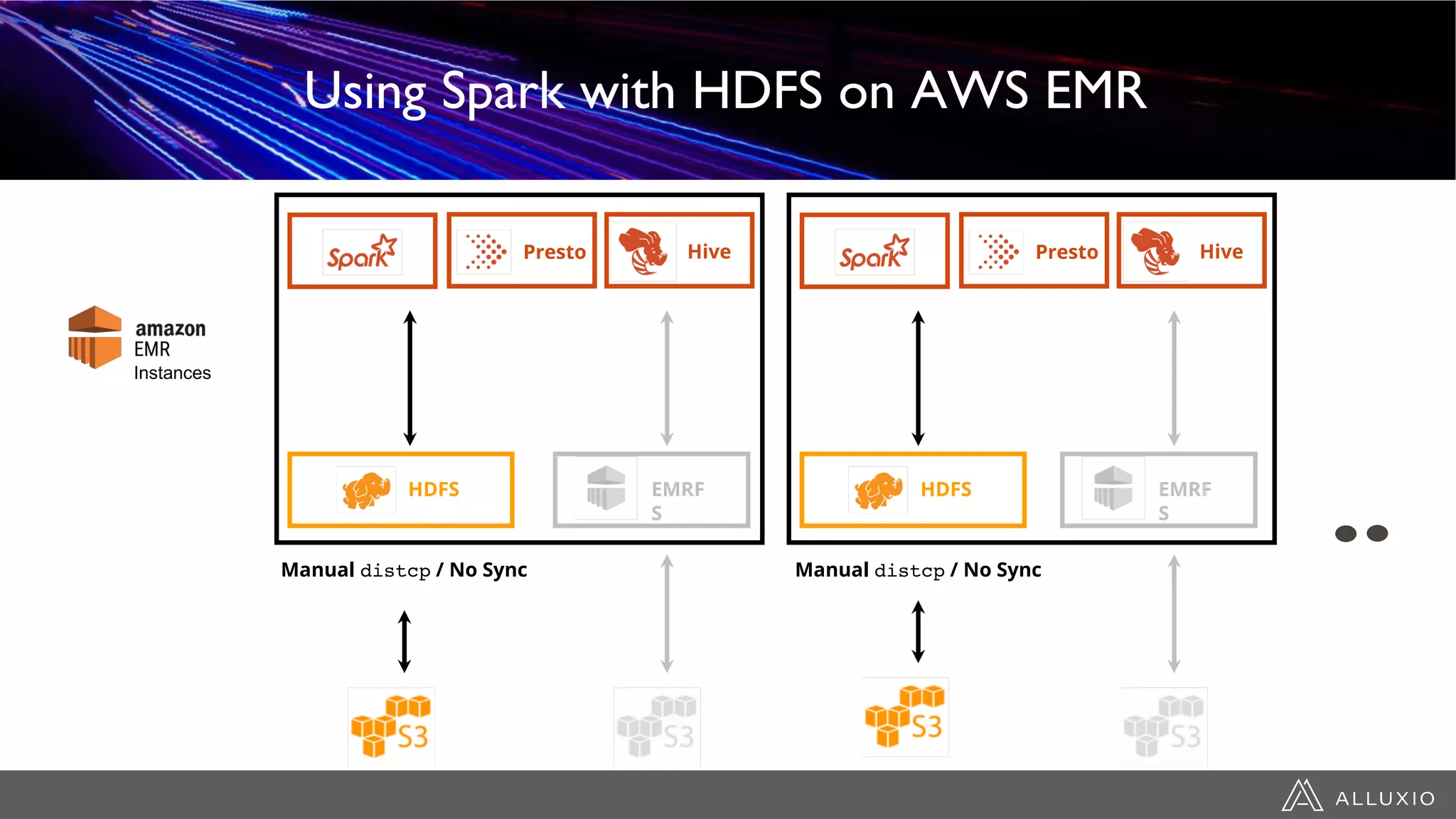
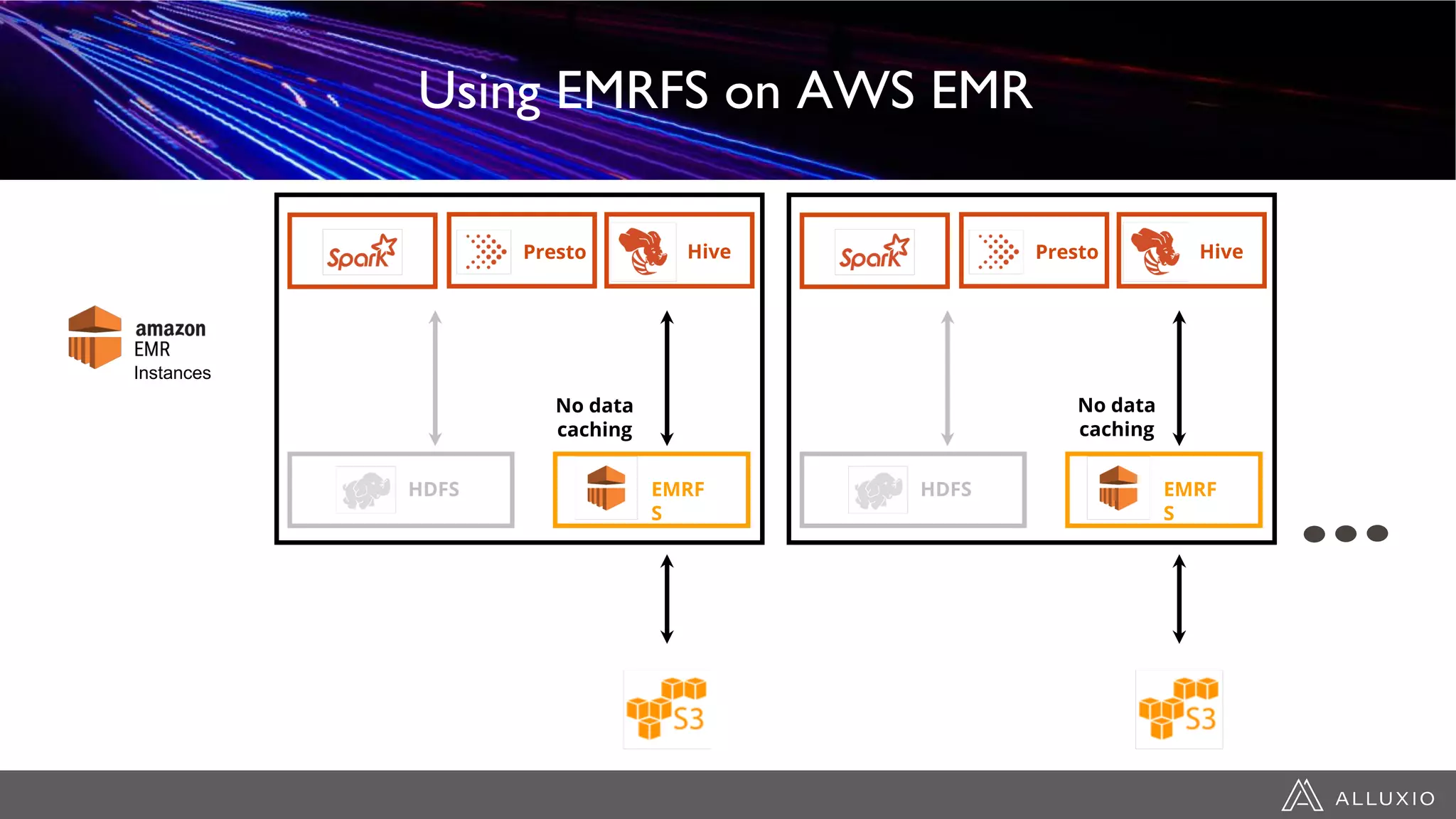
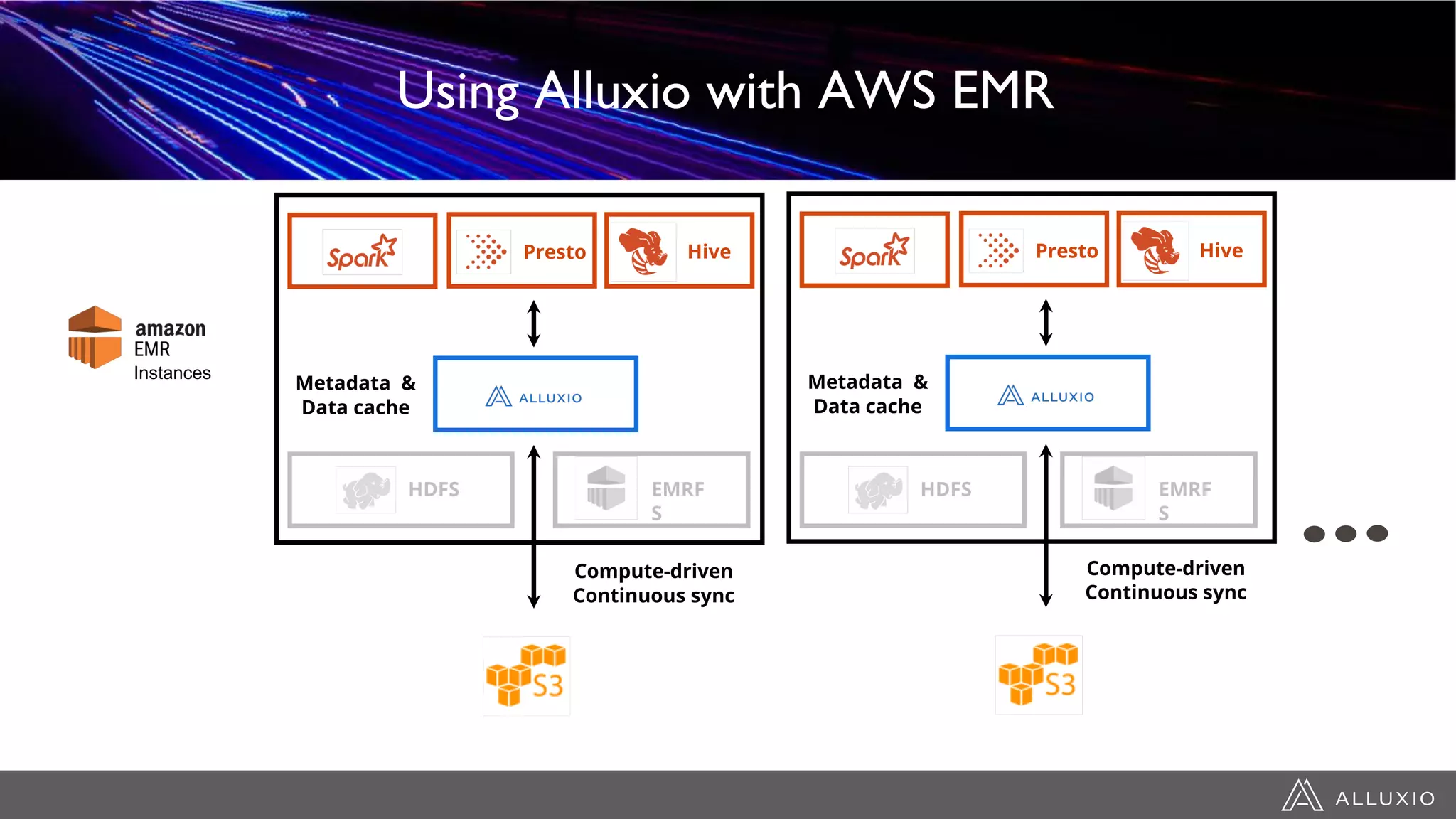
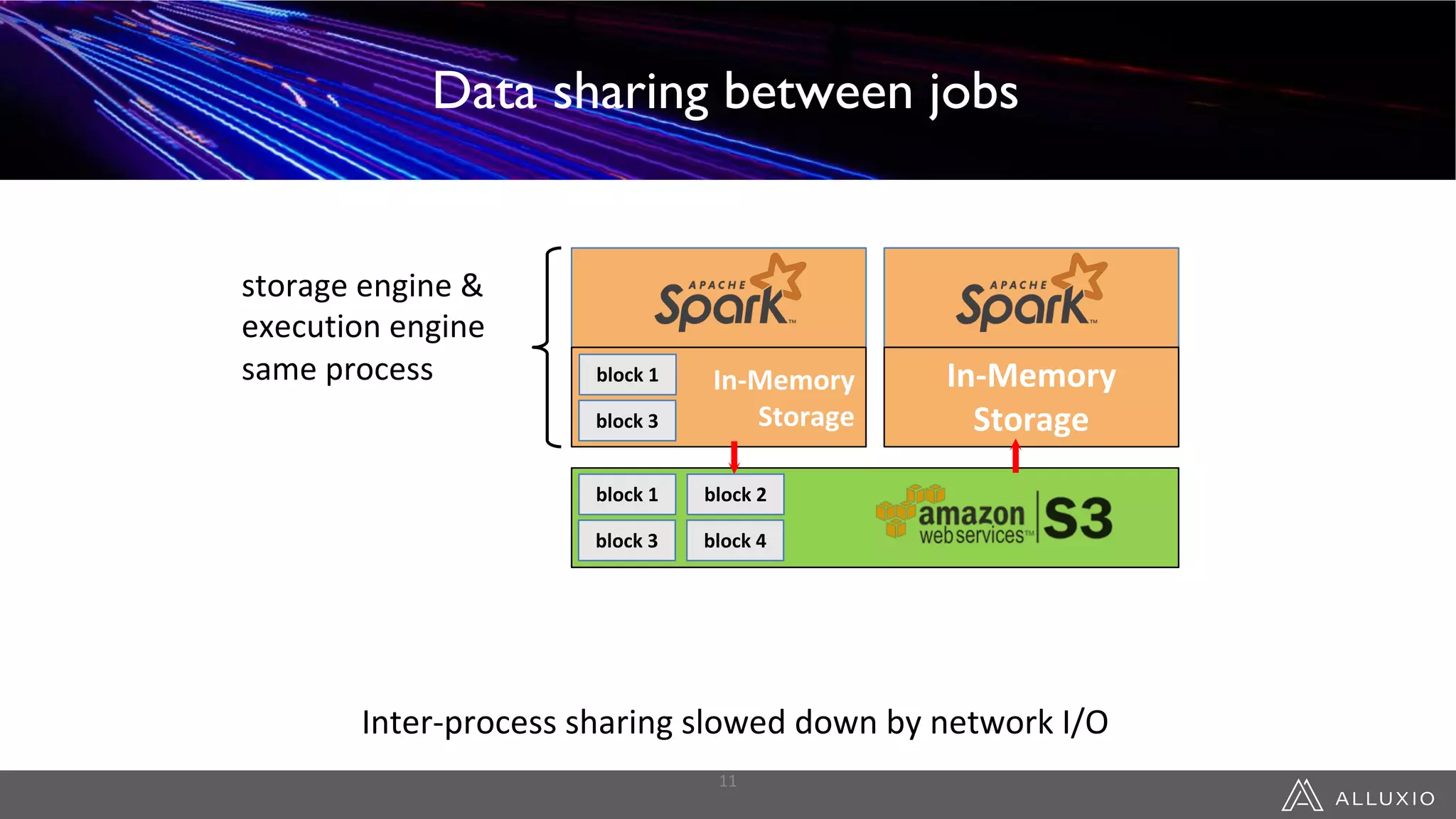
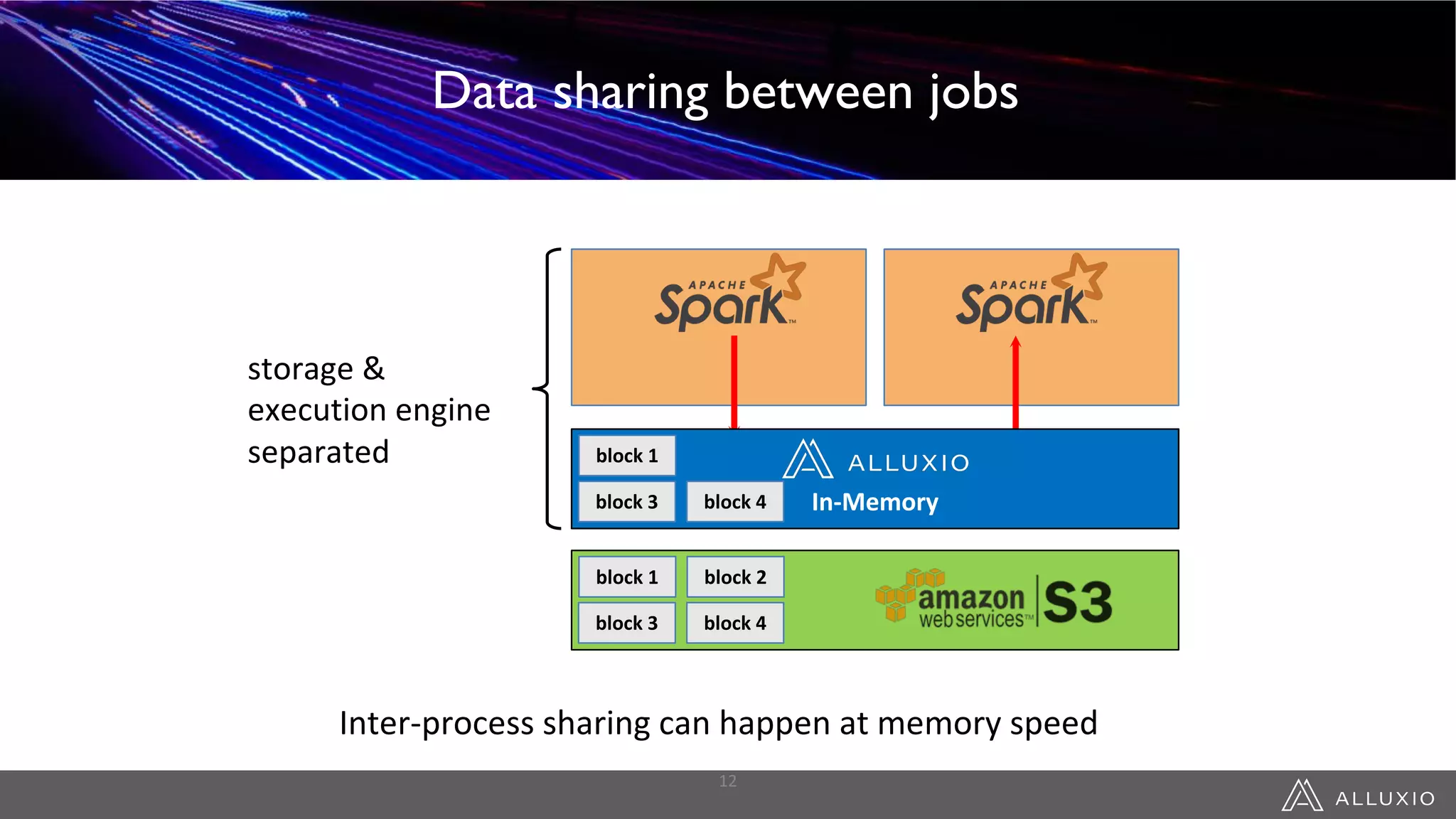
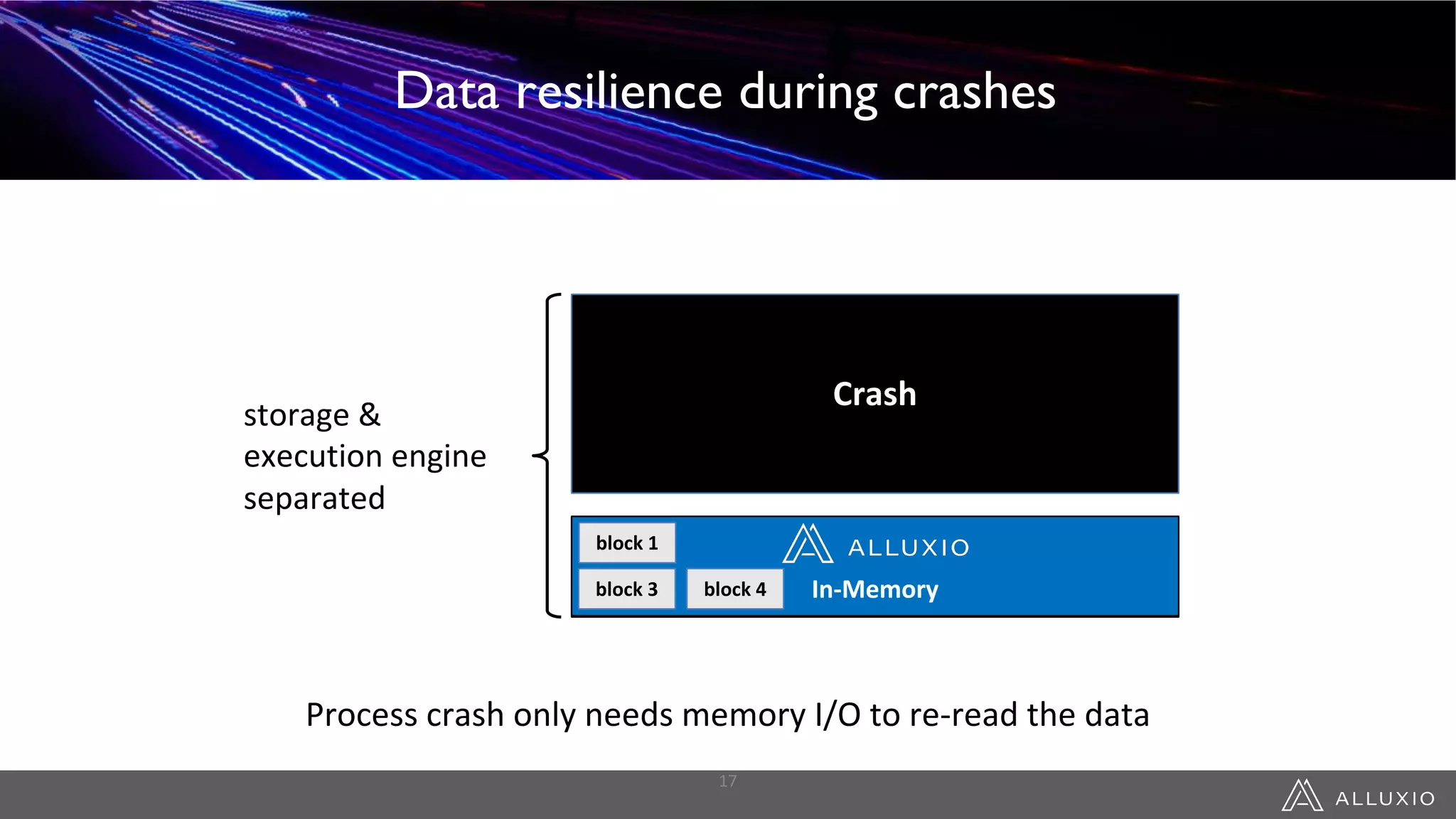
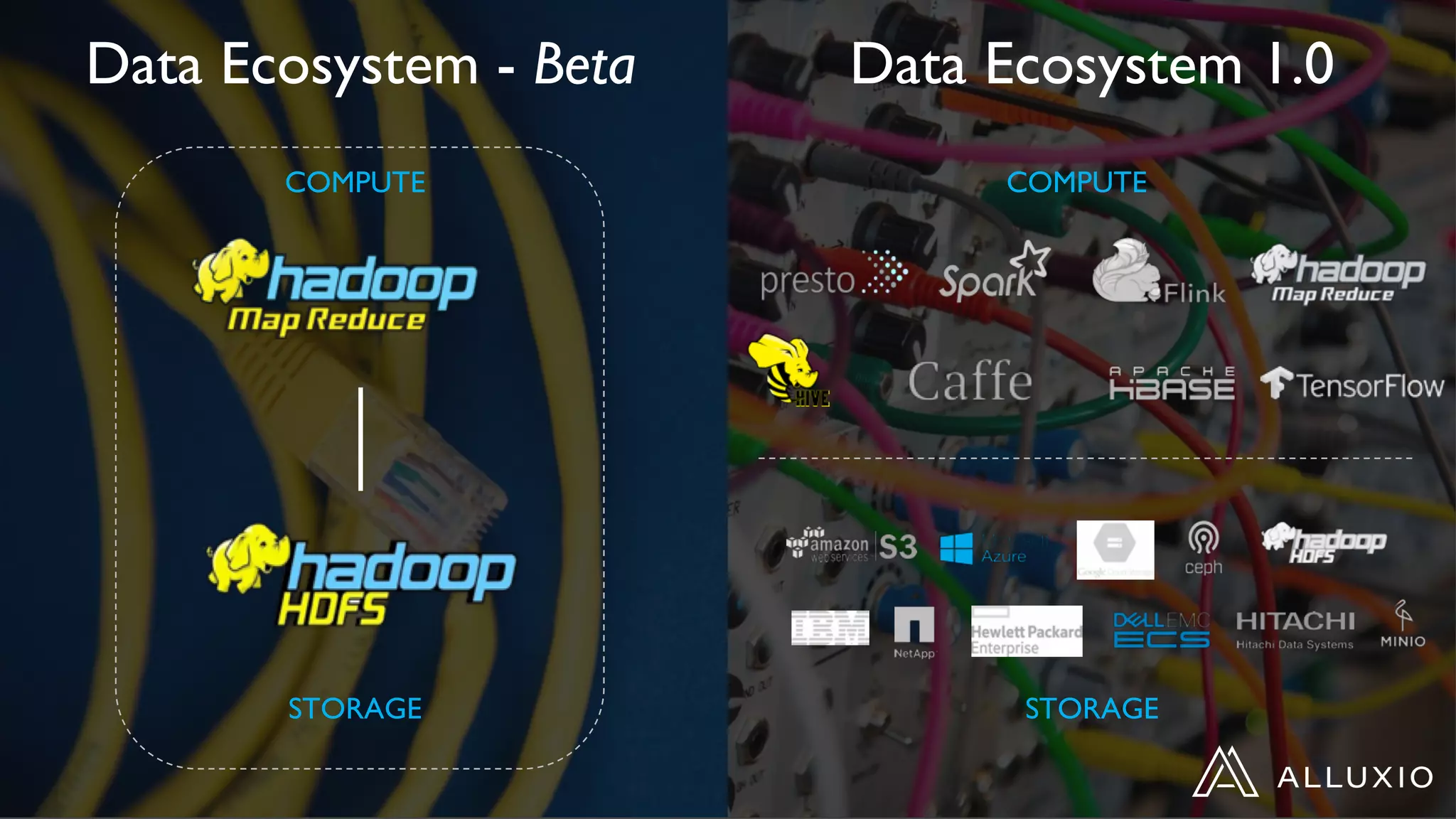
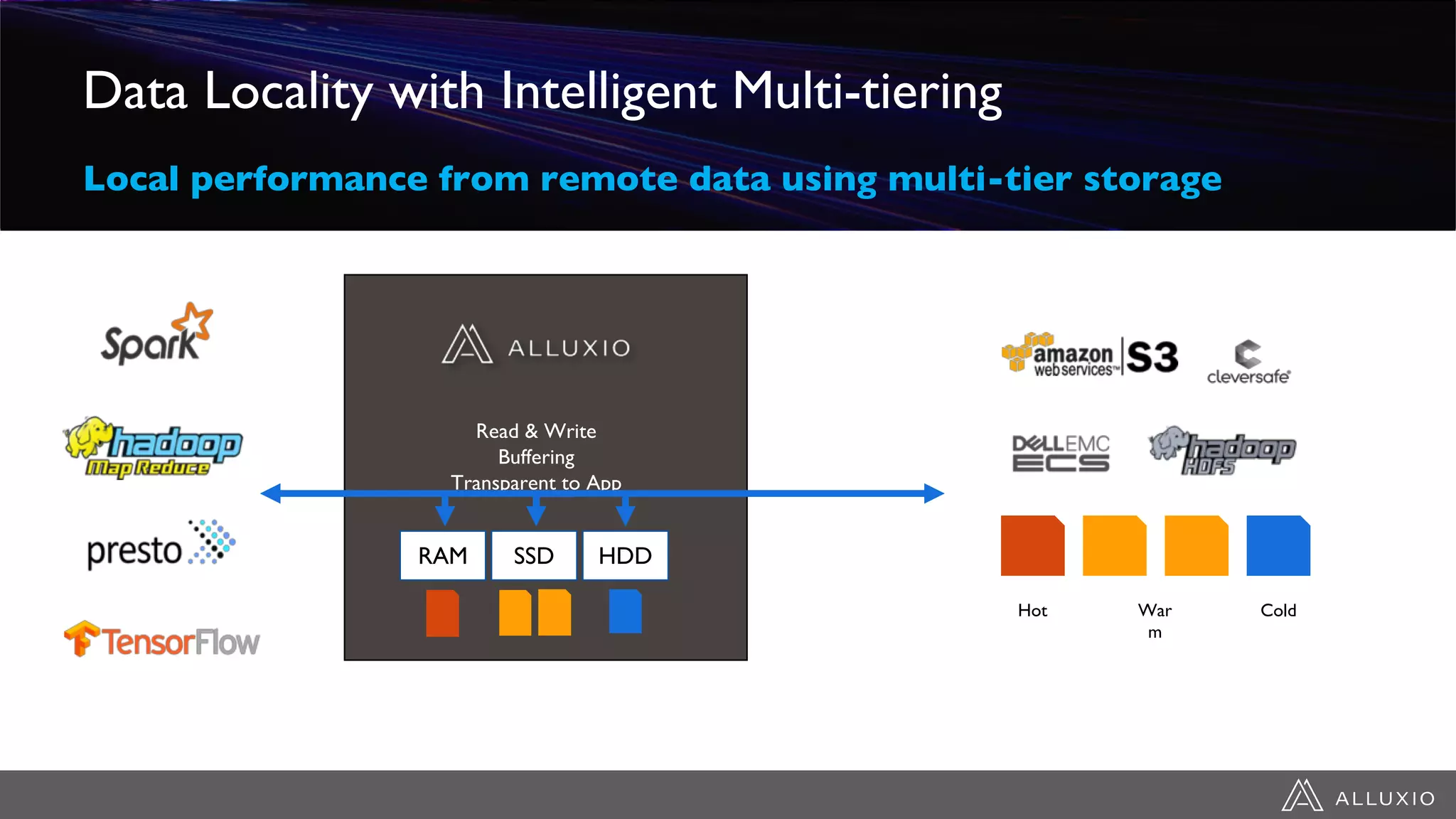
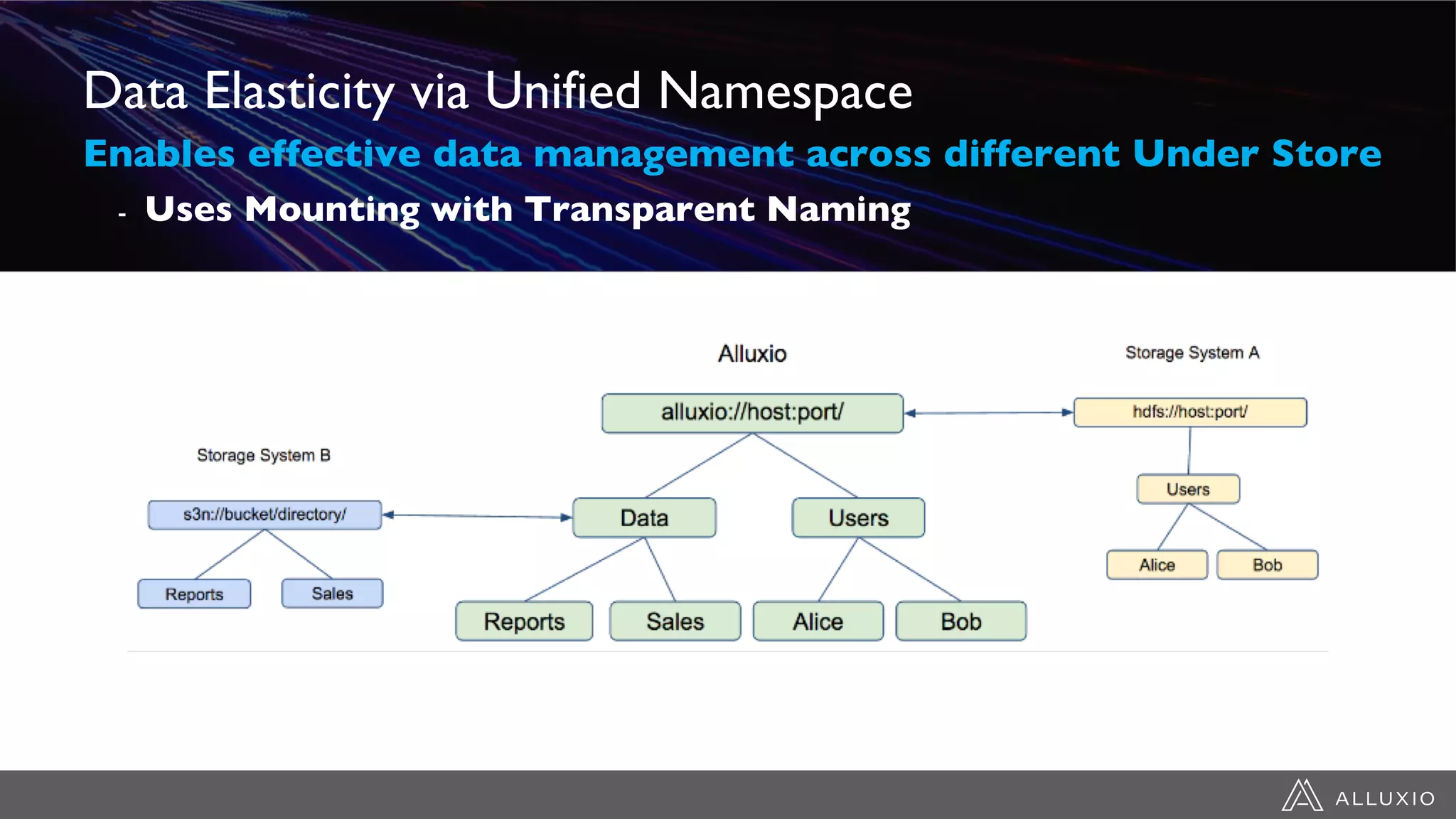
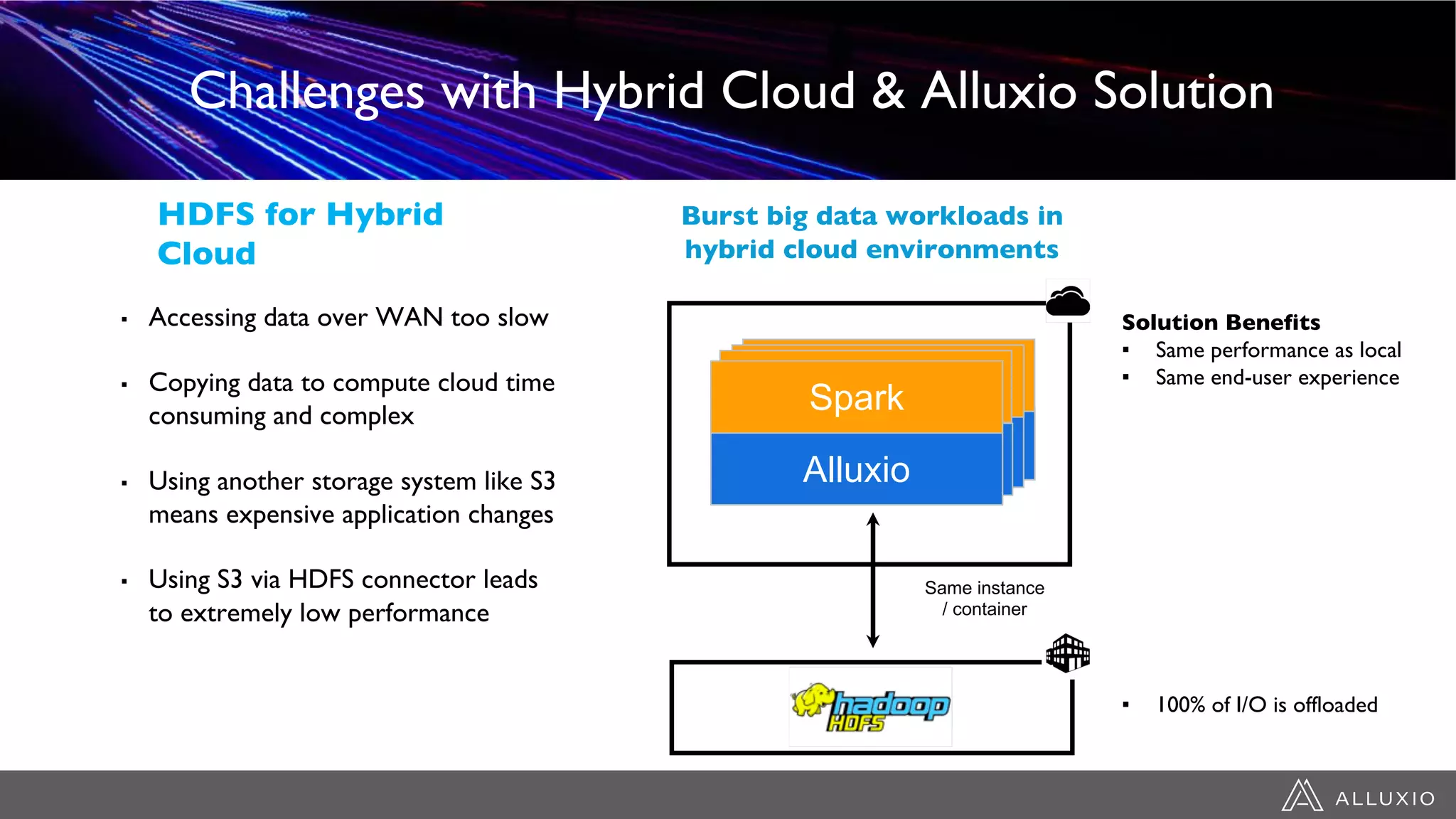
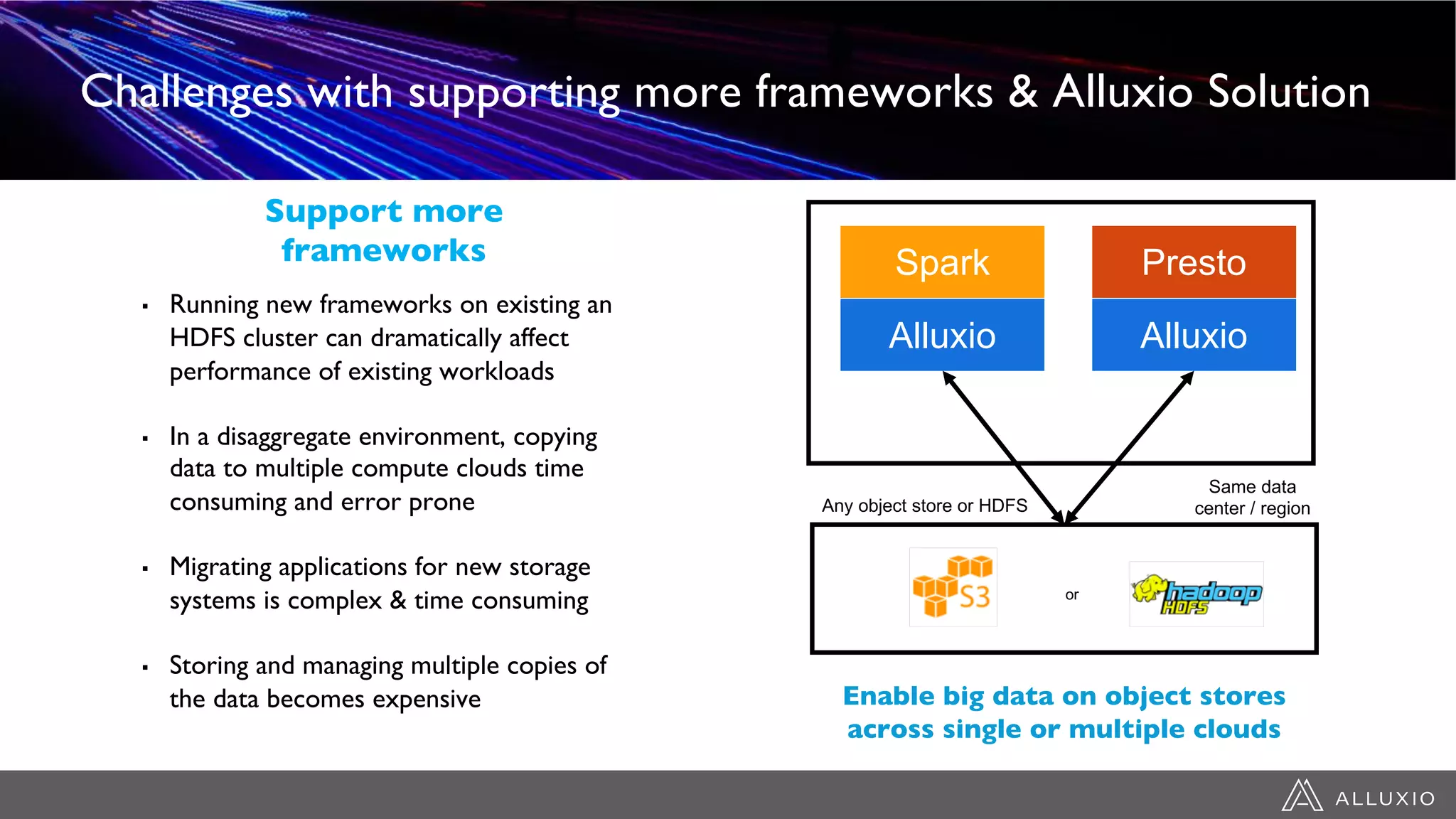
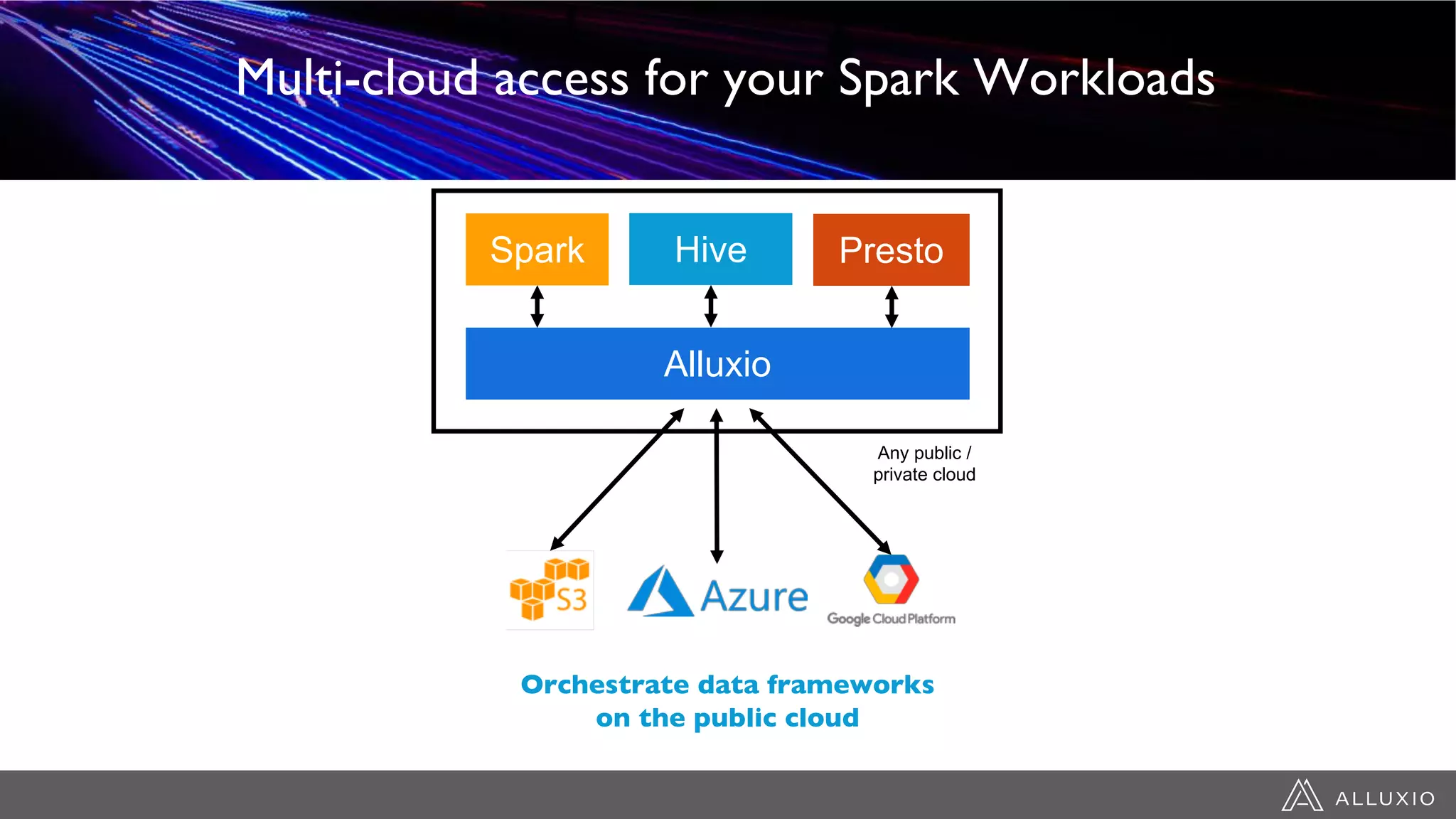
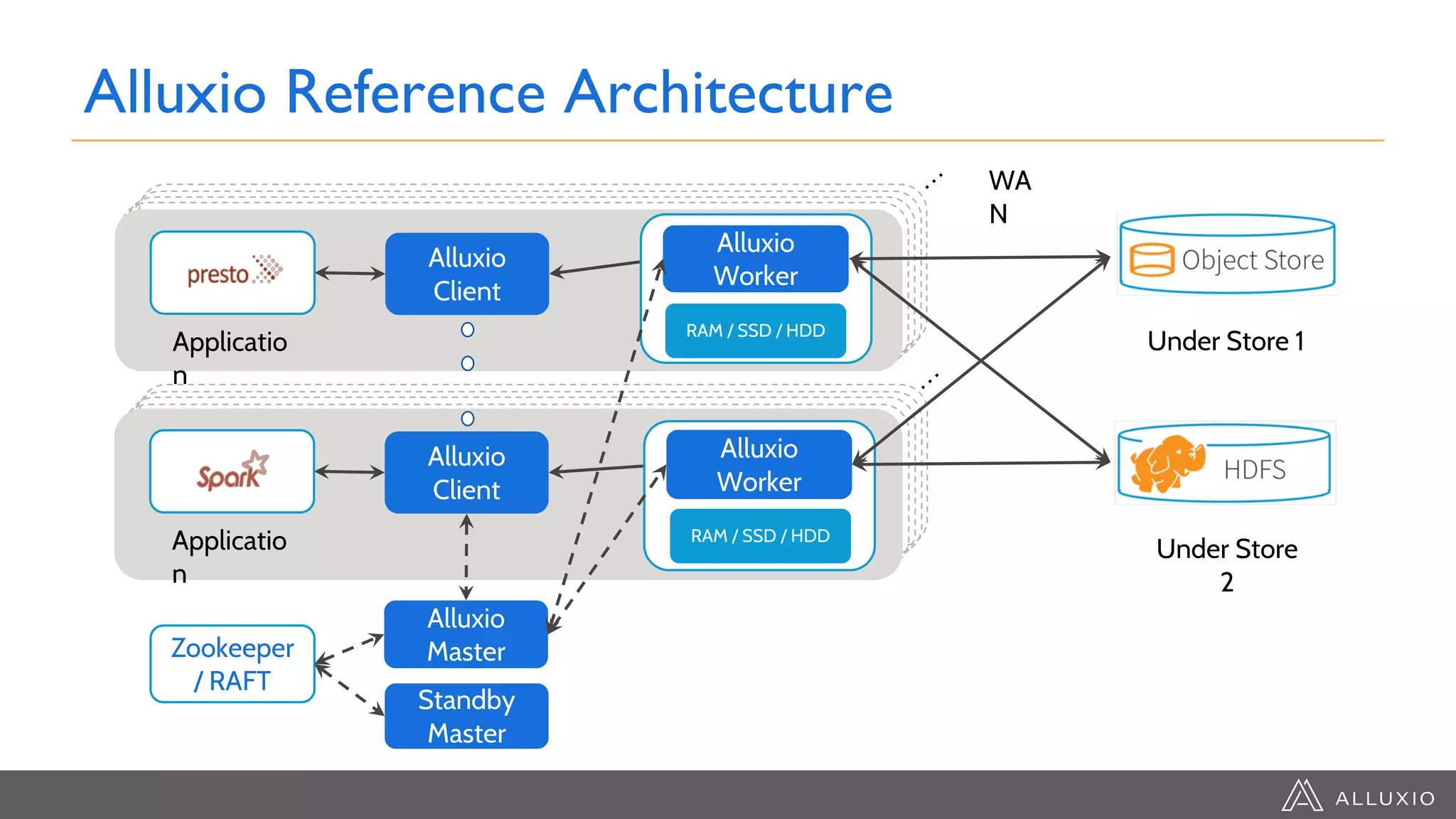
This document discusses accelerating Spark workloads on Amazon S3 using Alluxio. It describes the challenges of running Spark interactively on S3 due to its eventual consistency and expensive metadata operations. Alluxio provides a data caching layer that offers strong consistency, faster performance, and API compatibility with HDFS and S3. It also allows data outside of S3 to be analyzed. The document demonstrates how to bootstrap Alluxio on an AWS EMR cluster to accelerate Spark workloads running on S3.























































































