Downloaded 23 times


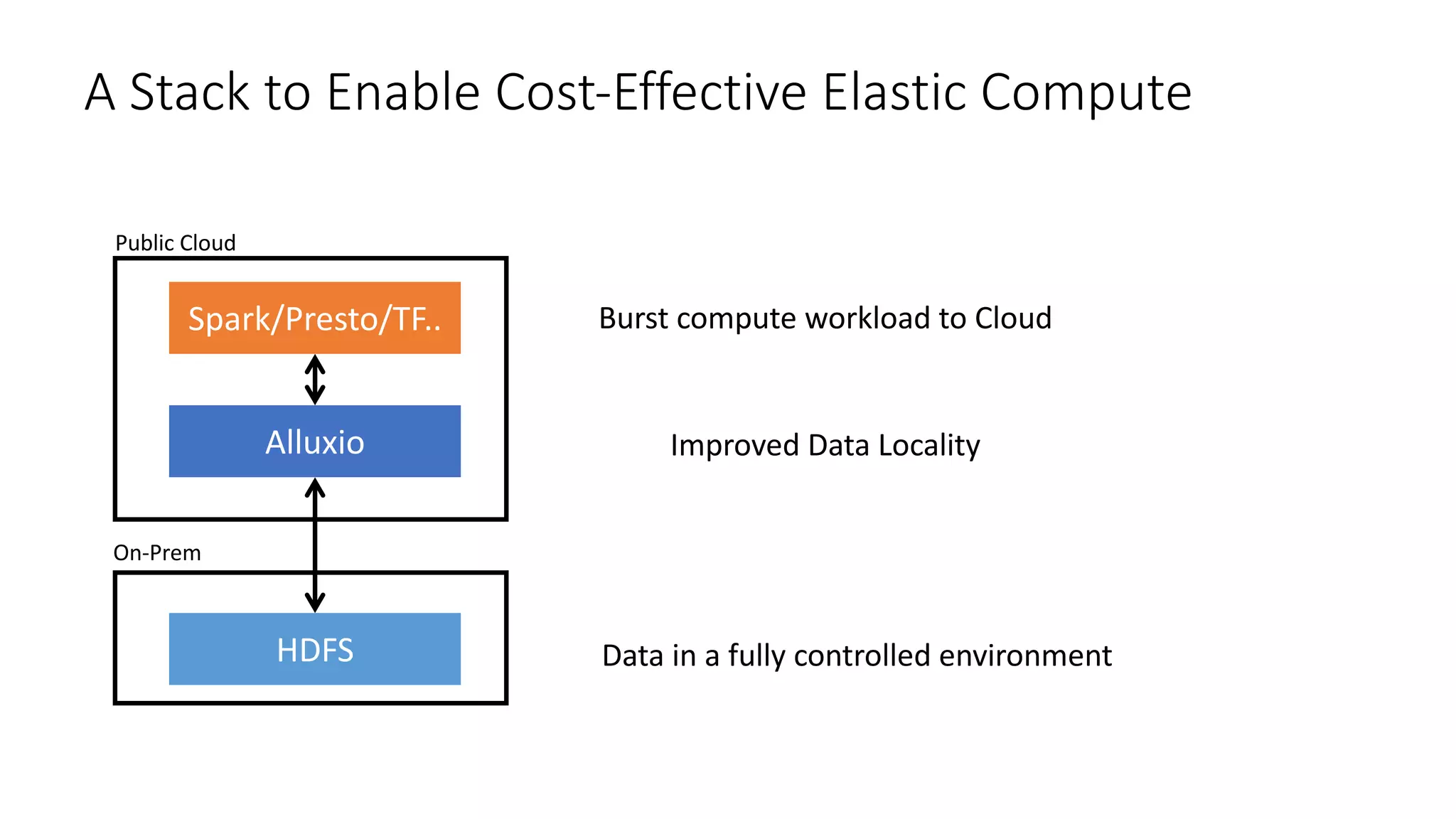

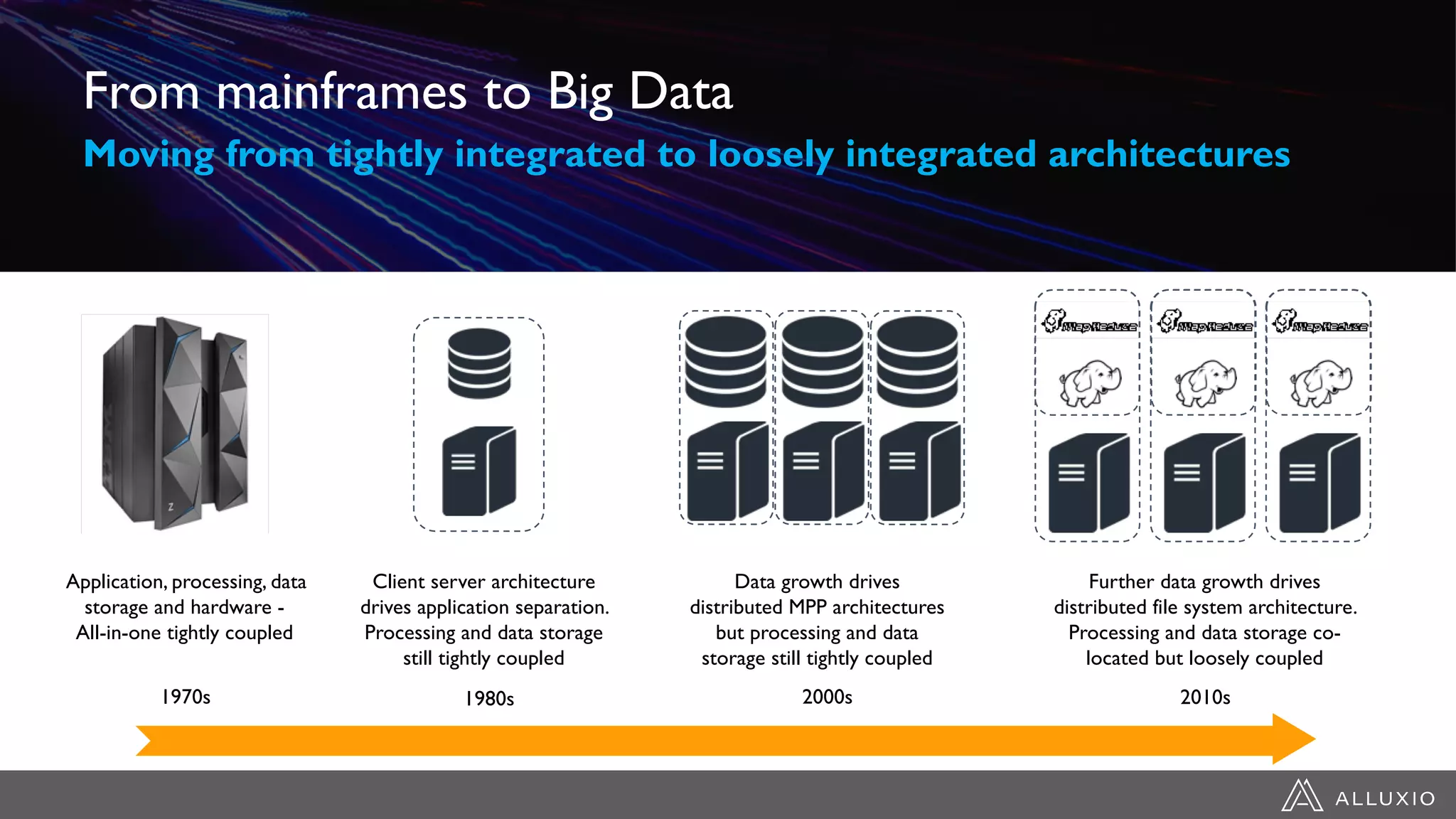

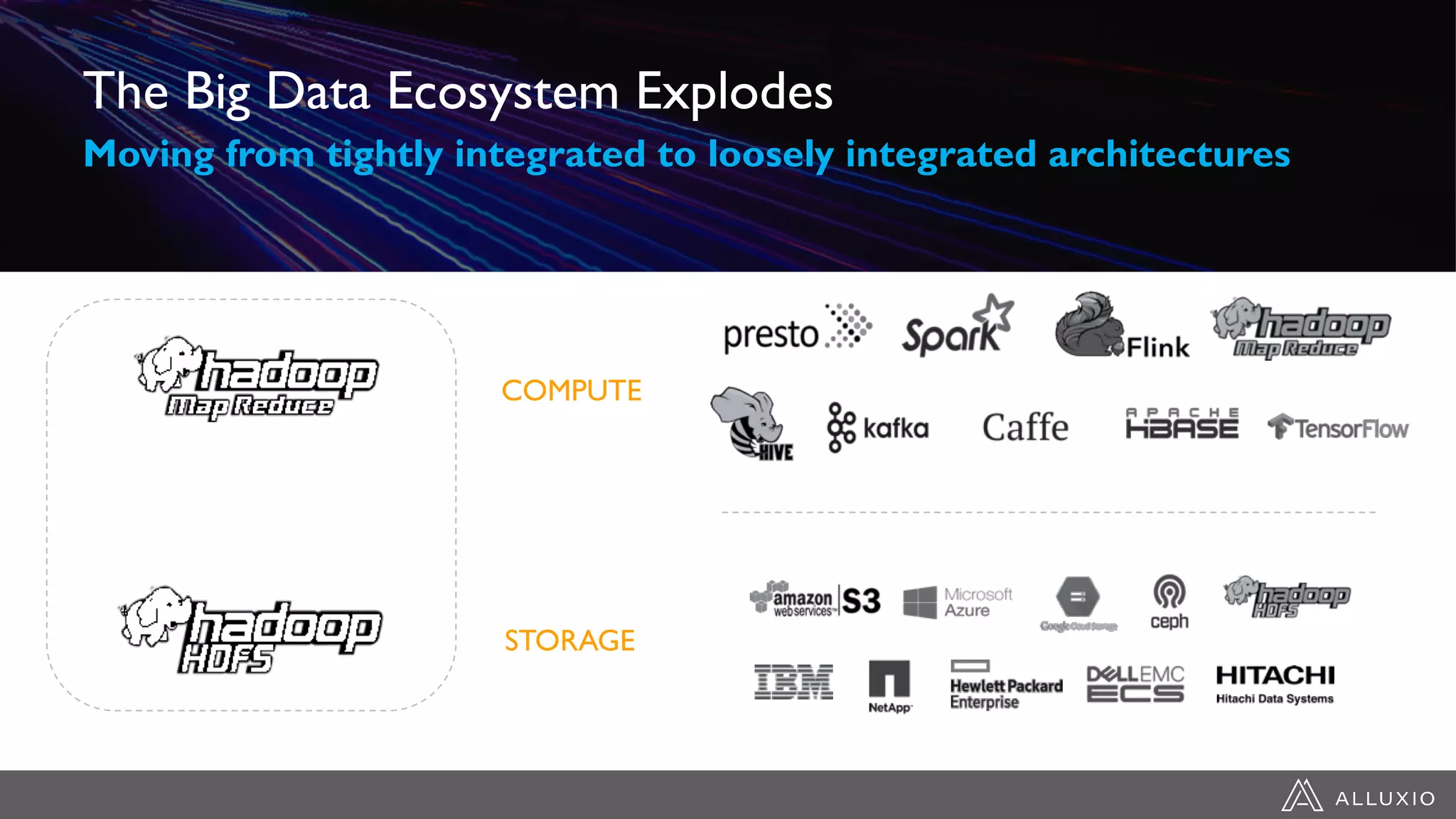

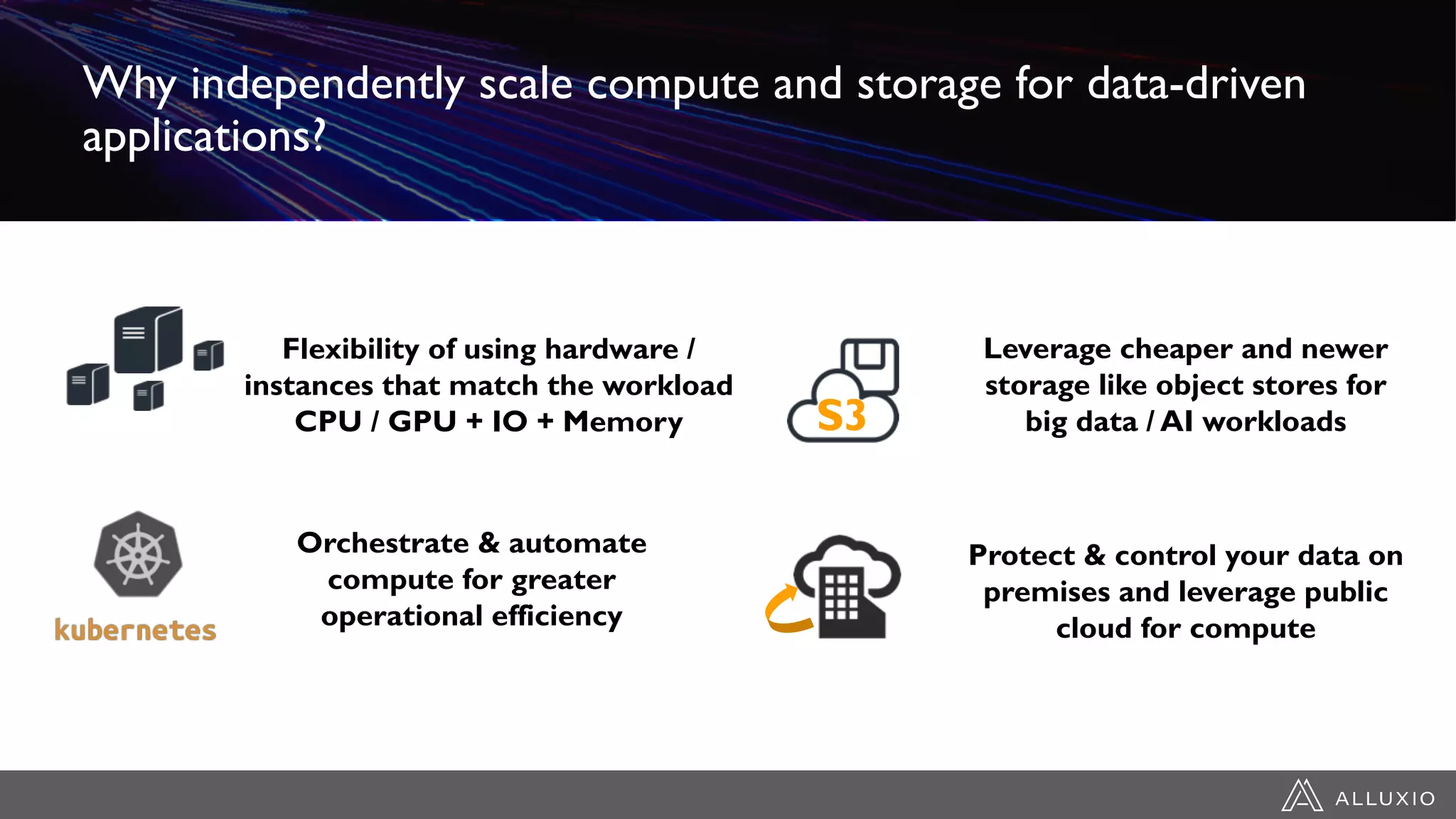



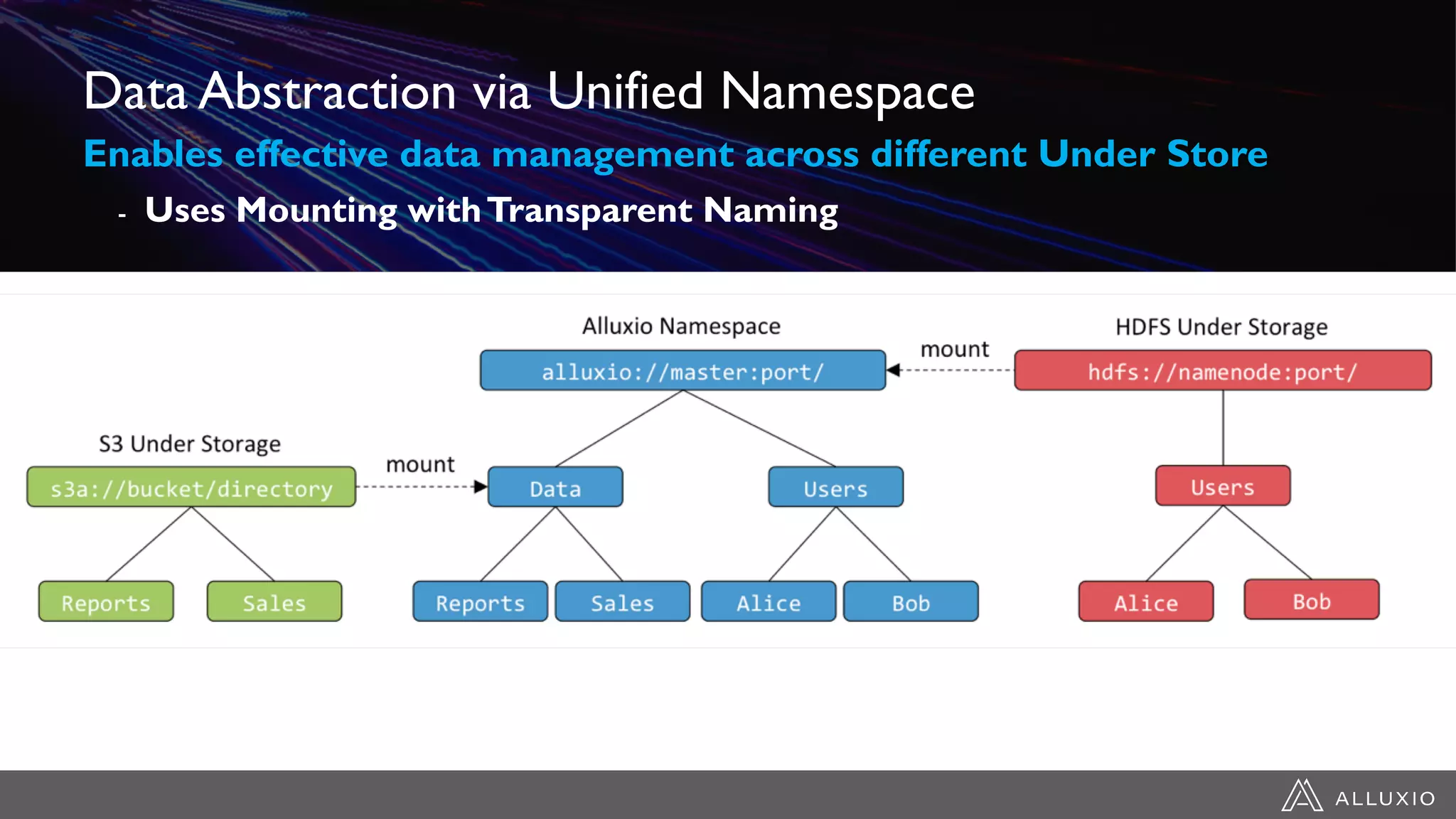

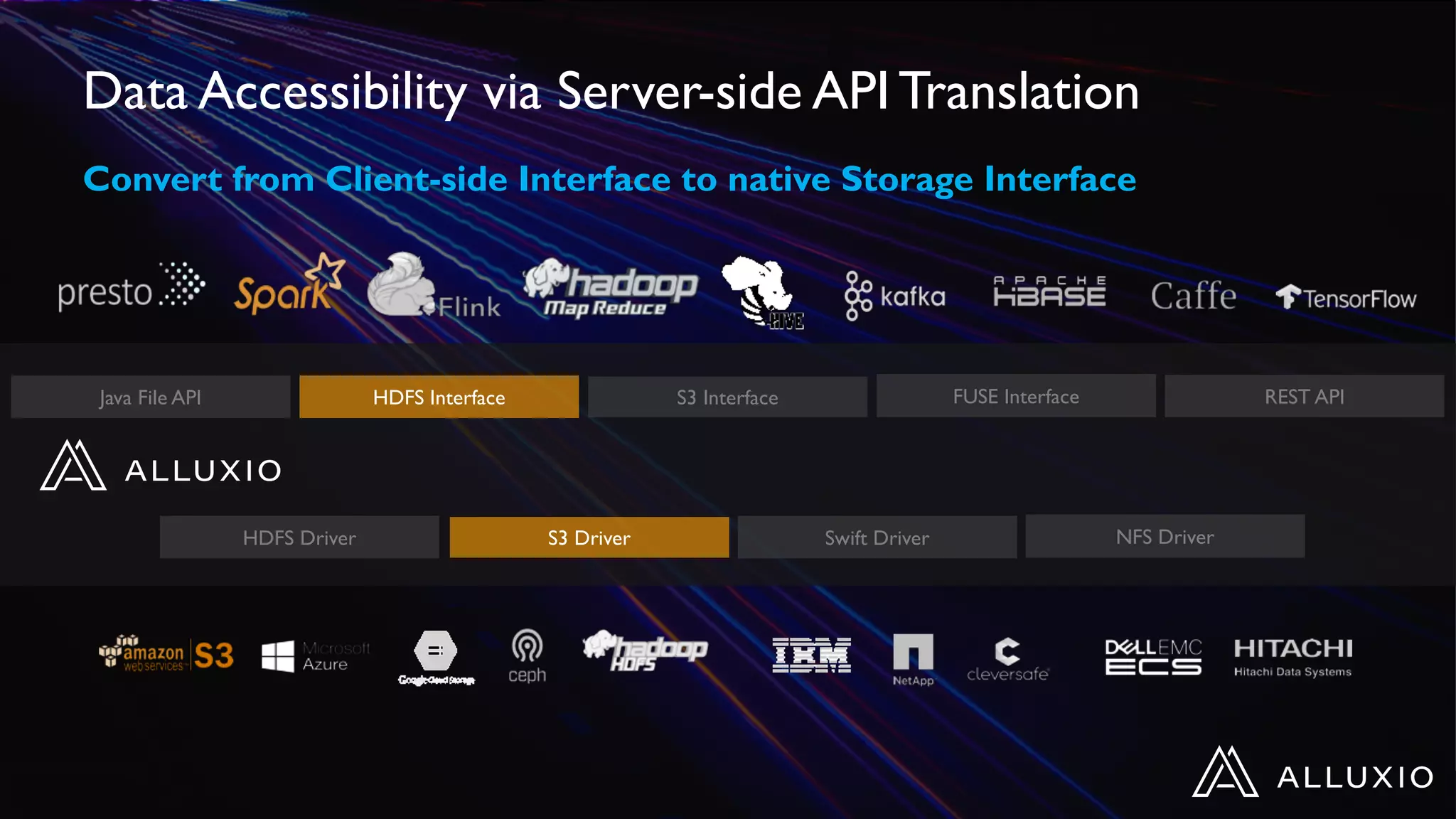

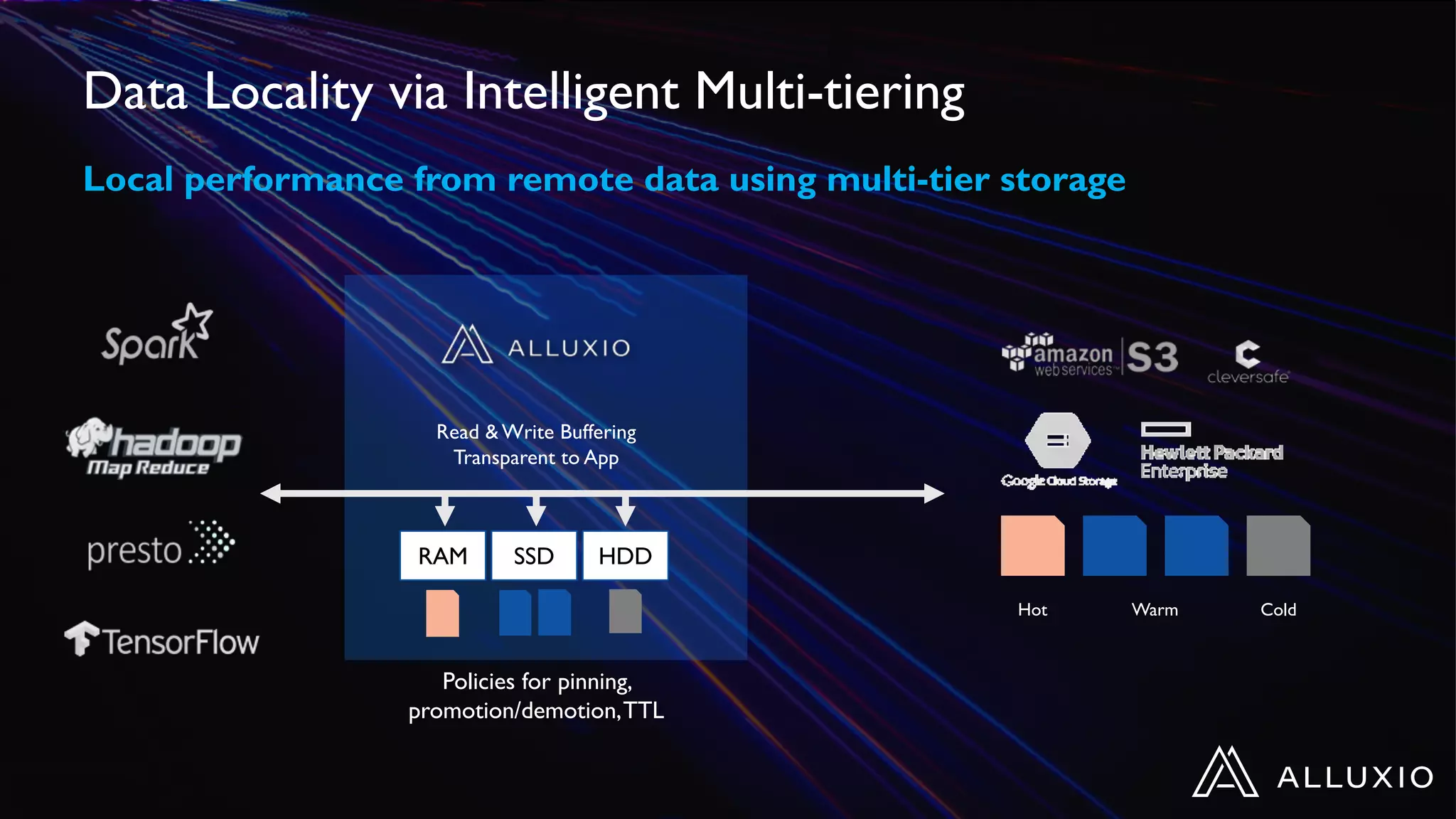


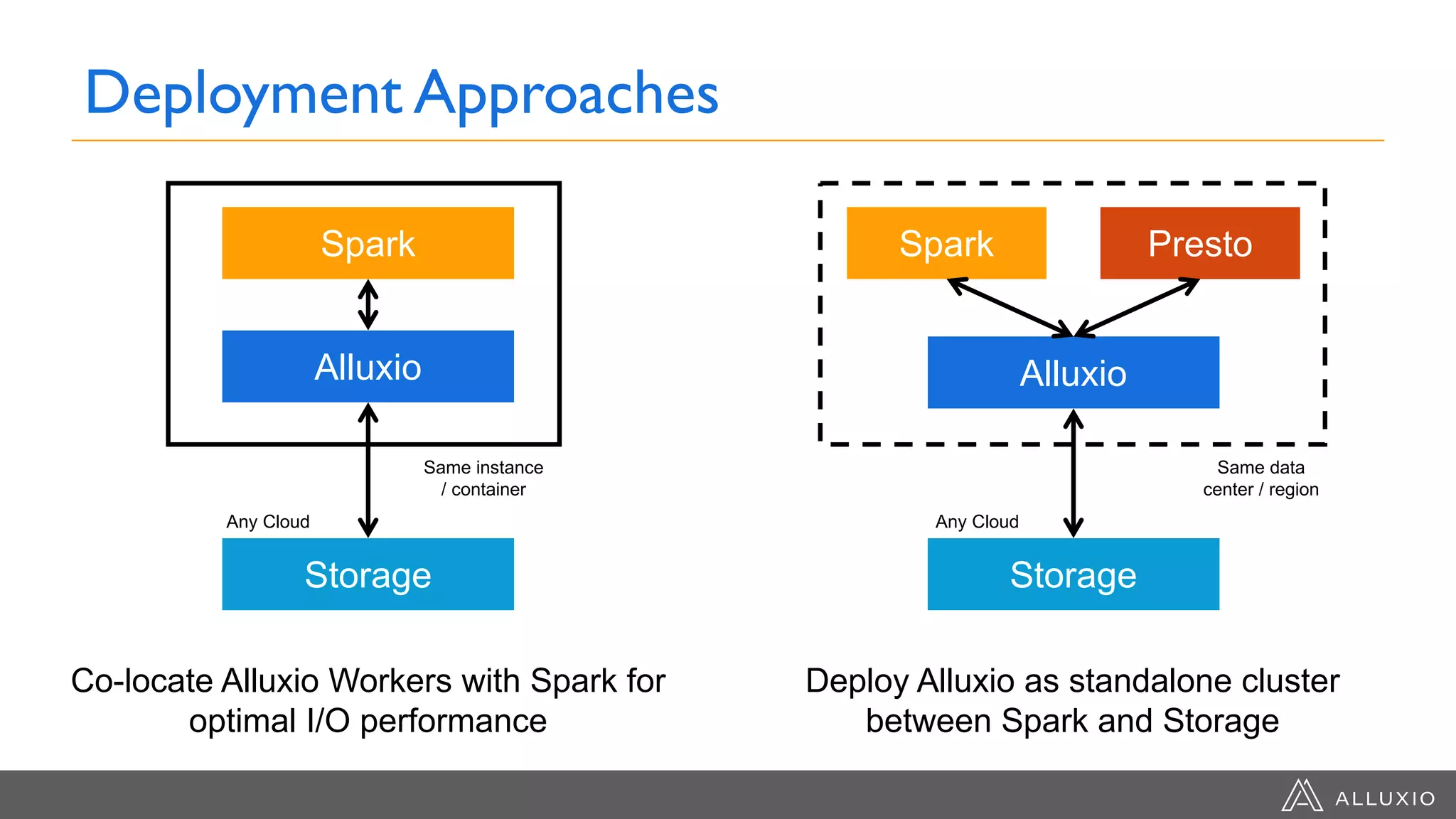
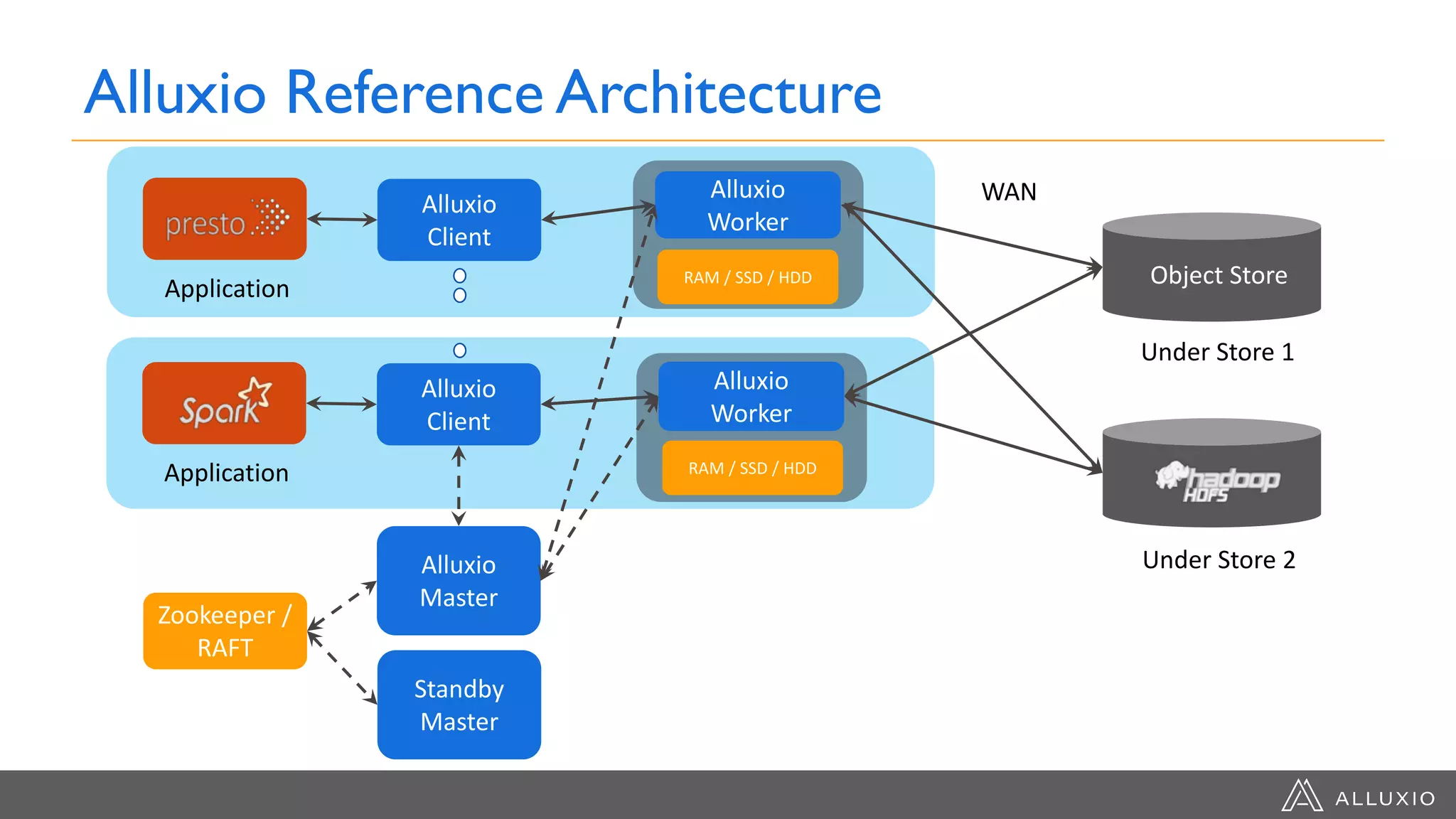
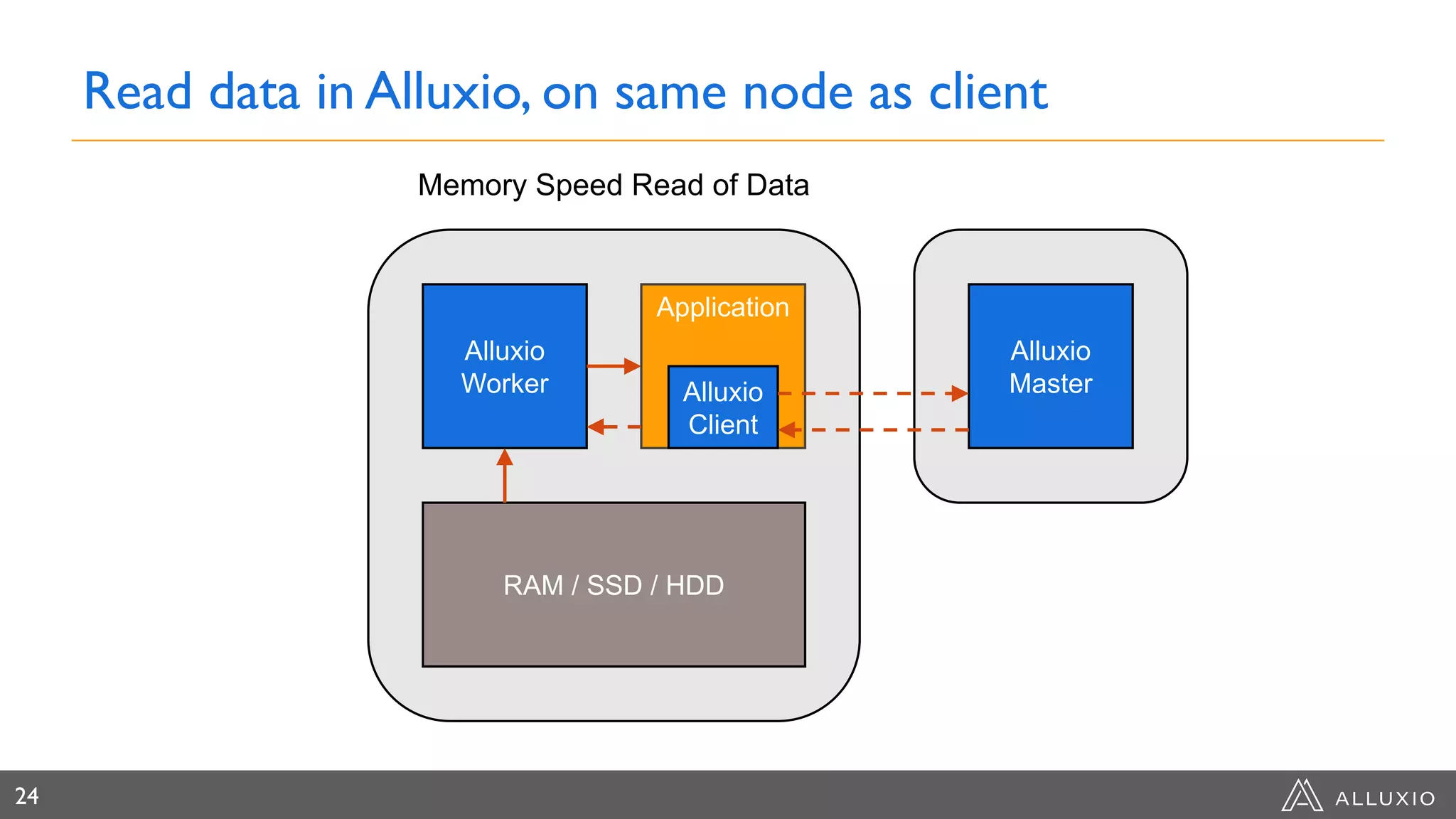







Alluxio provides a unified interface to access data across multiple storage systems, allowing compute and storage to scale independently for data-driven applications. It uses a virtual unified file system with a global namespace and server-side API translation to abstract data location and access. Alluxio intelligently manages data placement across memory, SSDs and HDDs using multi-tier caching for local performance on remote data. This allows flexible deployment of compute like Spark on any cloud while keeping data fully controlled on-premises. Alluxio is seeing wide adoption with many large production deployments handling thousands of nodes. Upcoming features include POSIX API support and preview of version 2.0.























































































