Download as PDF, PPTX







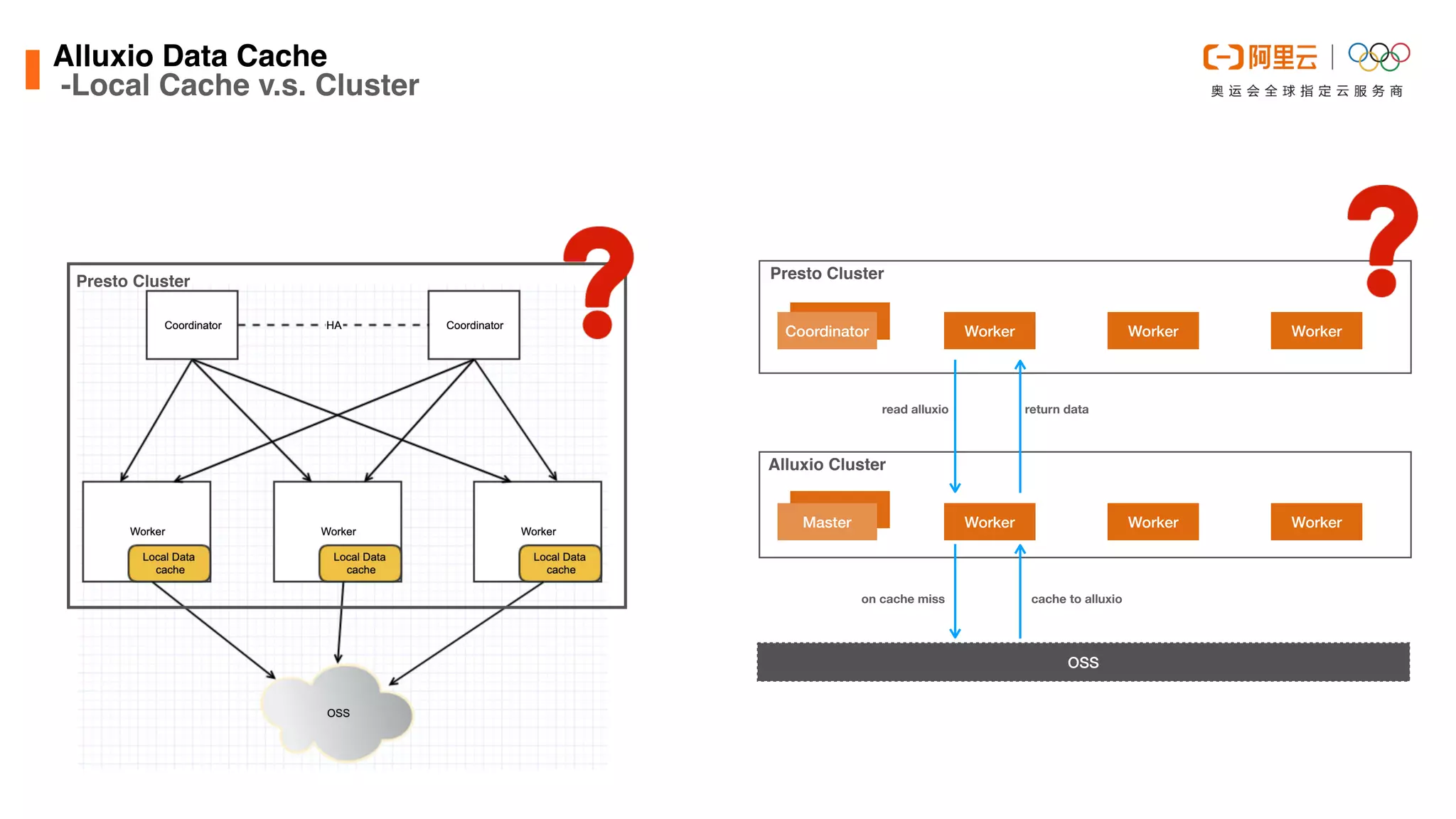
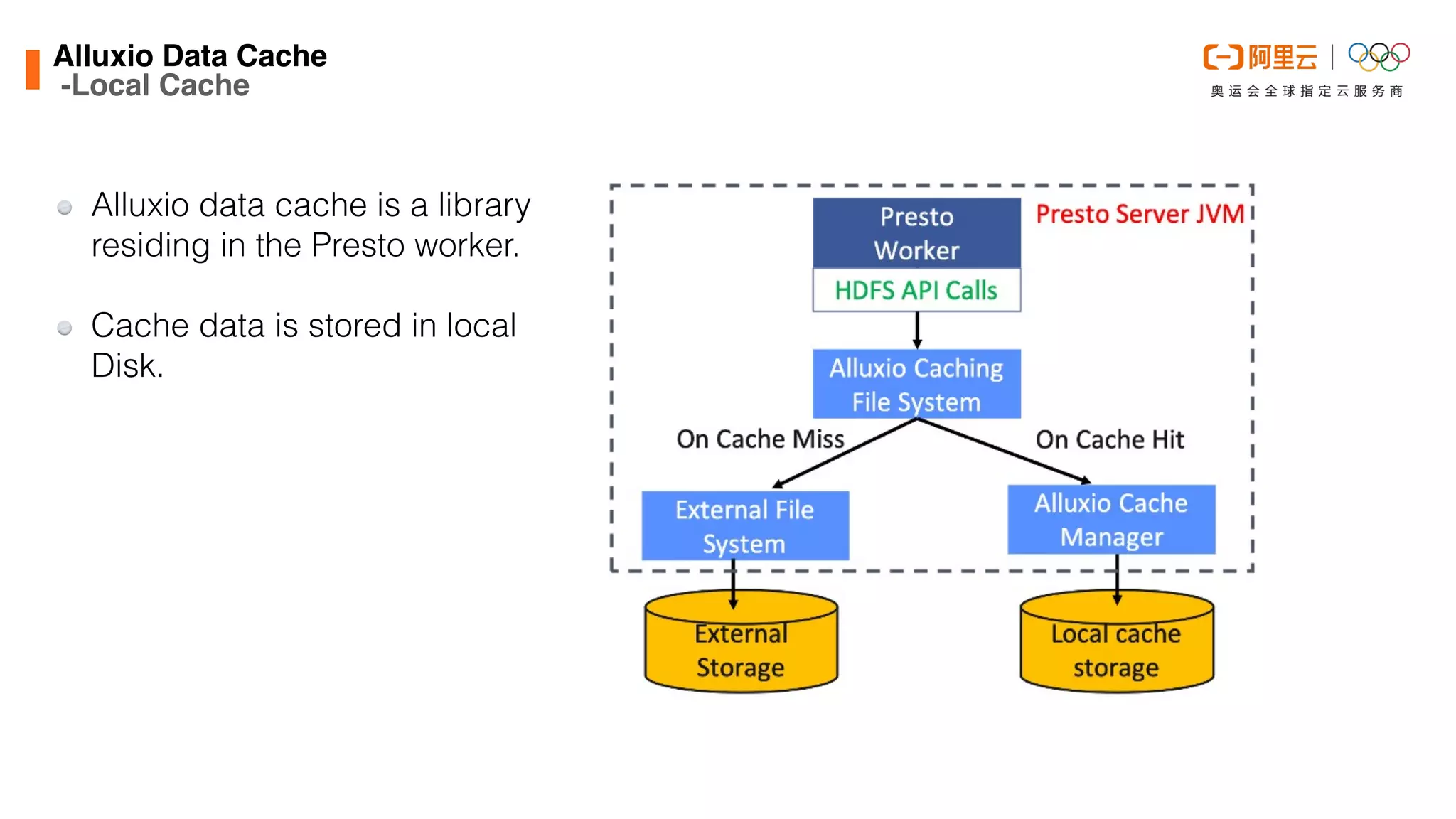



![Alluxio Data Cach
e
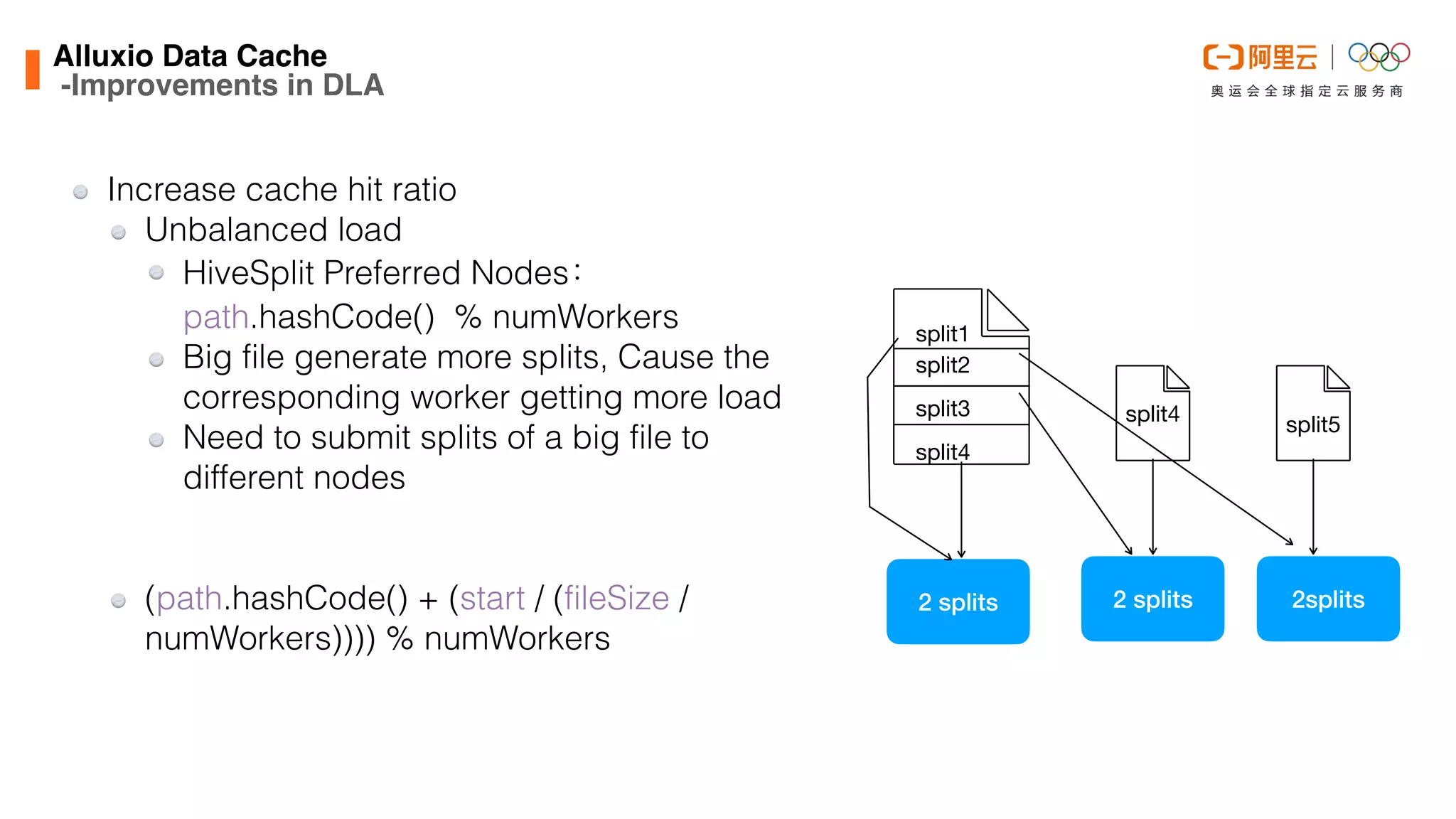
-Improvements in DLA
Improve disk throughput
20GB Ultra disk throughput:
Write109MB/s Read 108MB/s
Multiple disks
6 ultra disks performance: 600MB/s read/write
Implement
page.path = $root/$page_path
=>
page.path = $roots[page.hash % roots.size]/$page_path](https://image.slidesharecdn.com/buildingahigh-performancedatalakeanalyticsengineatalibabacloudwithprestoalluxio-210426225933/75/Building-a-high-performance-data-lake-analytics-engine-at-Alibaba-Cloud-with-Presto-Alluxio-31-2048.jpg)

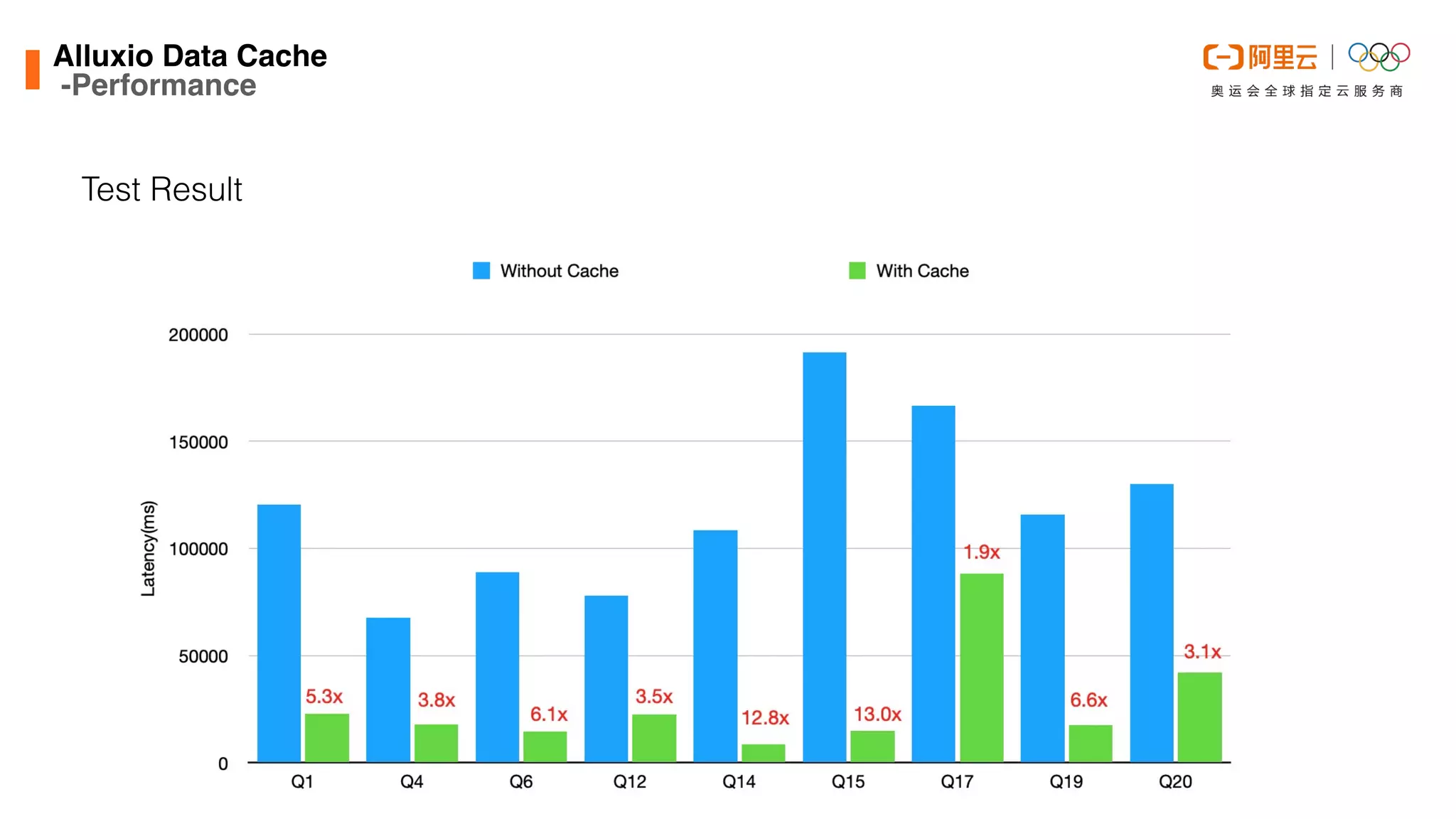



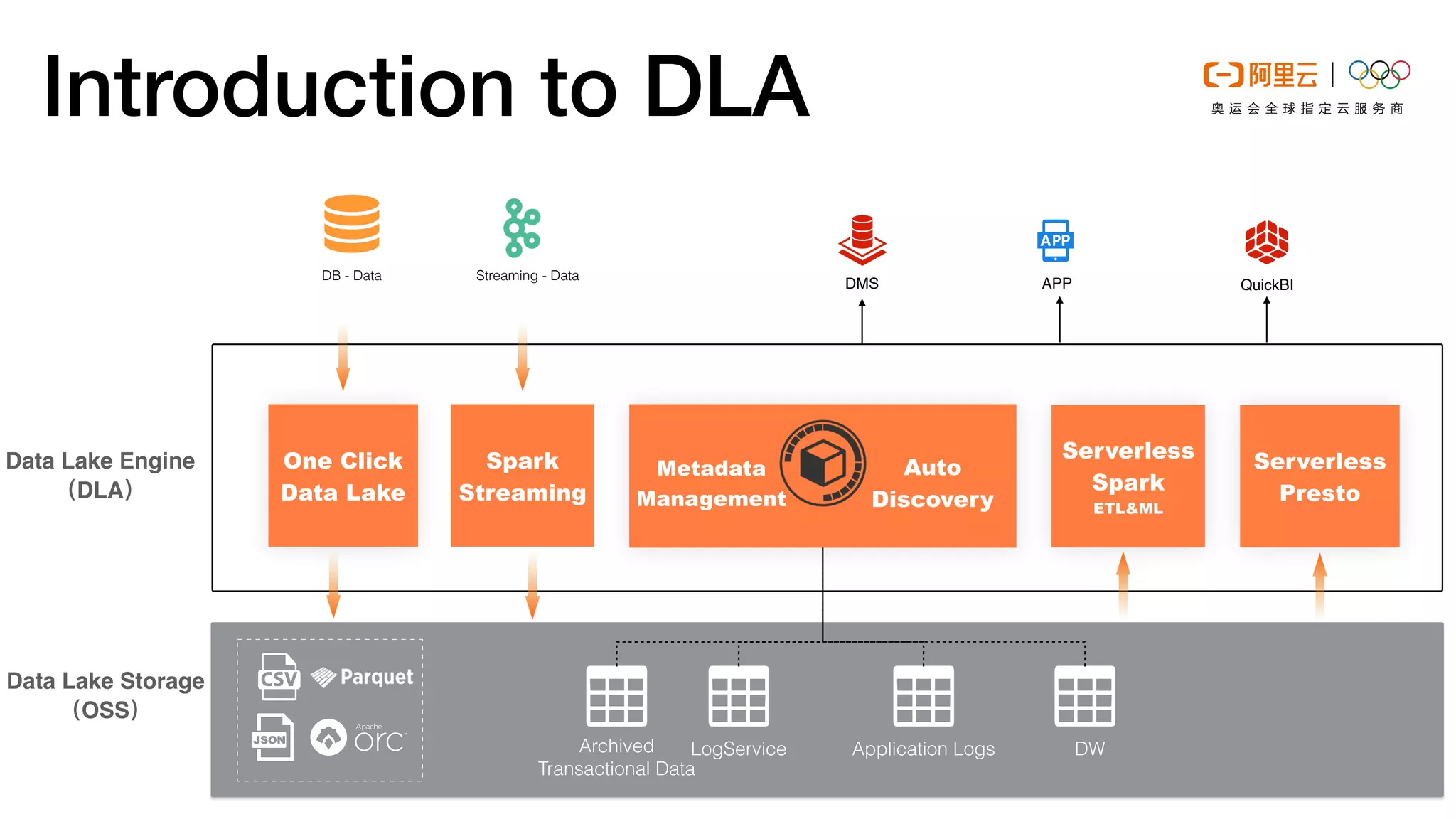
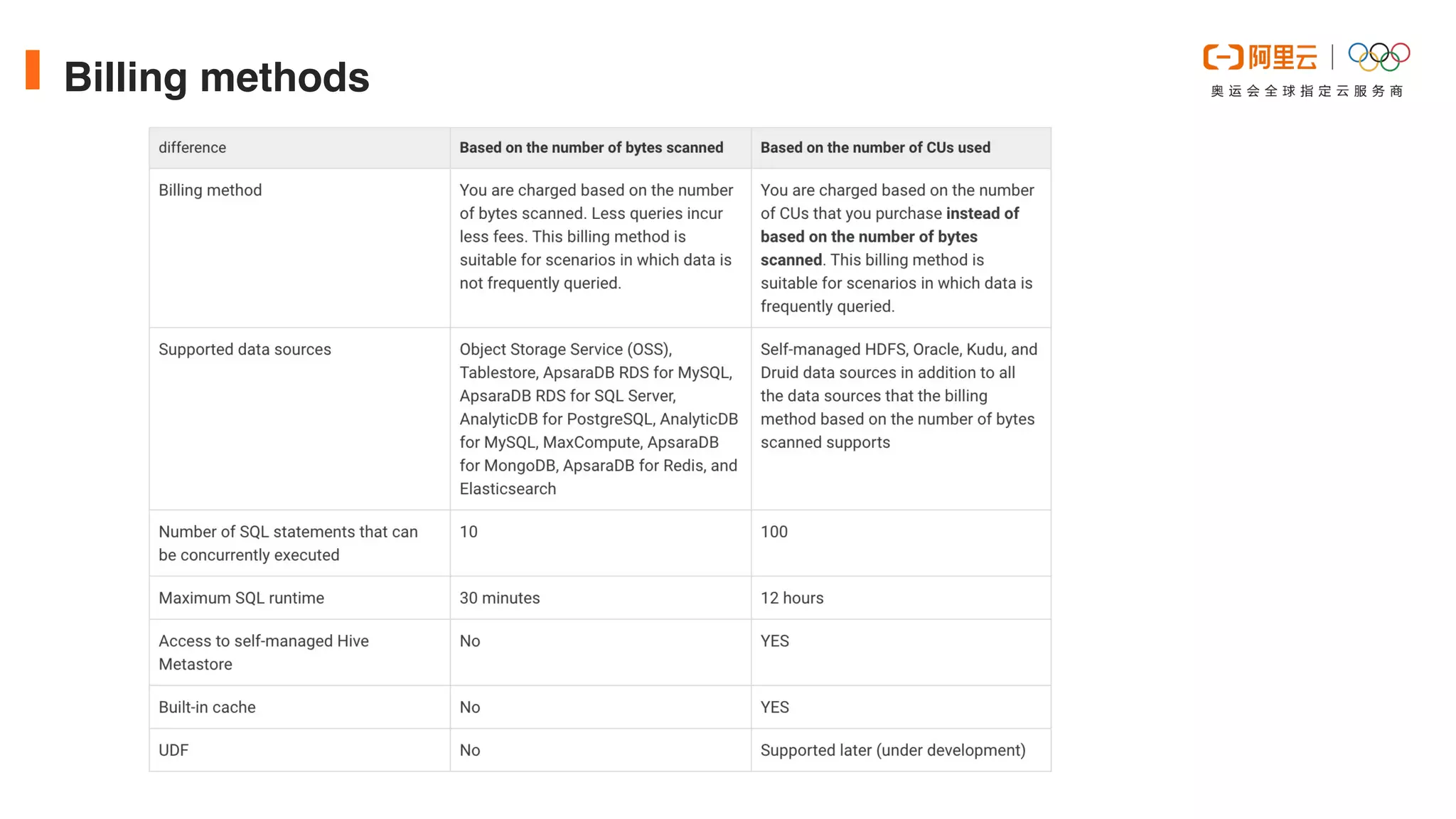
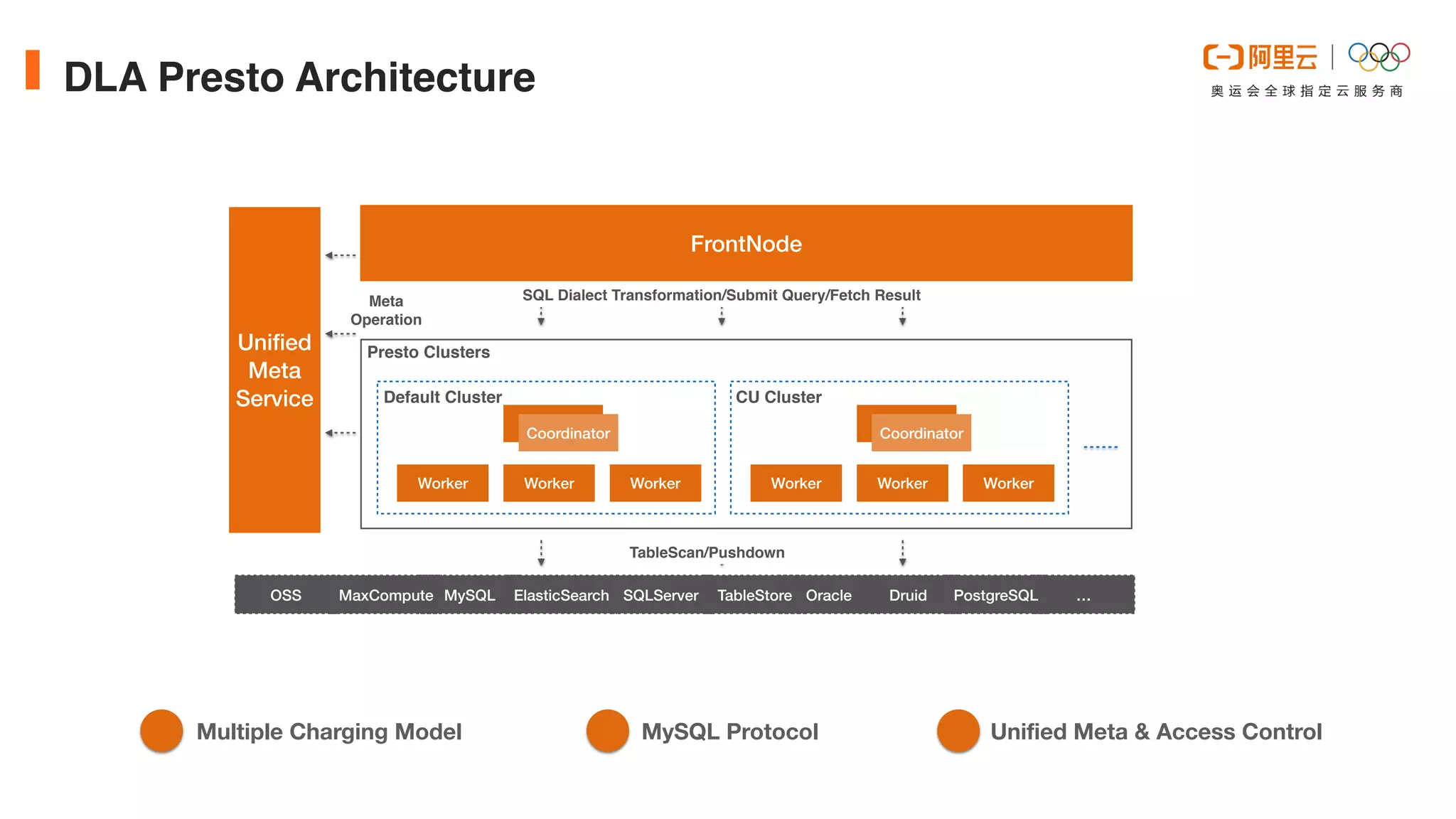
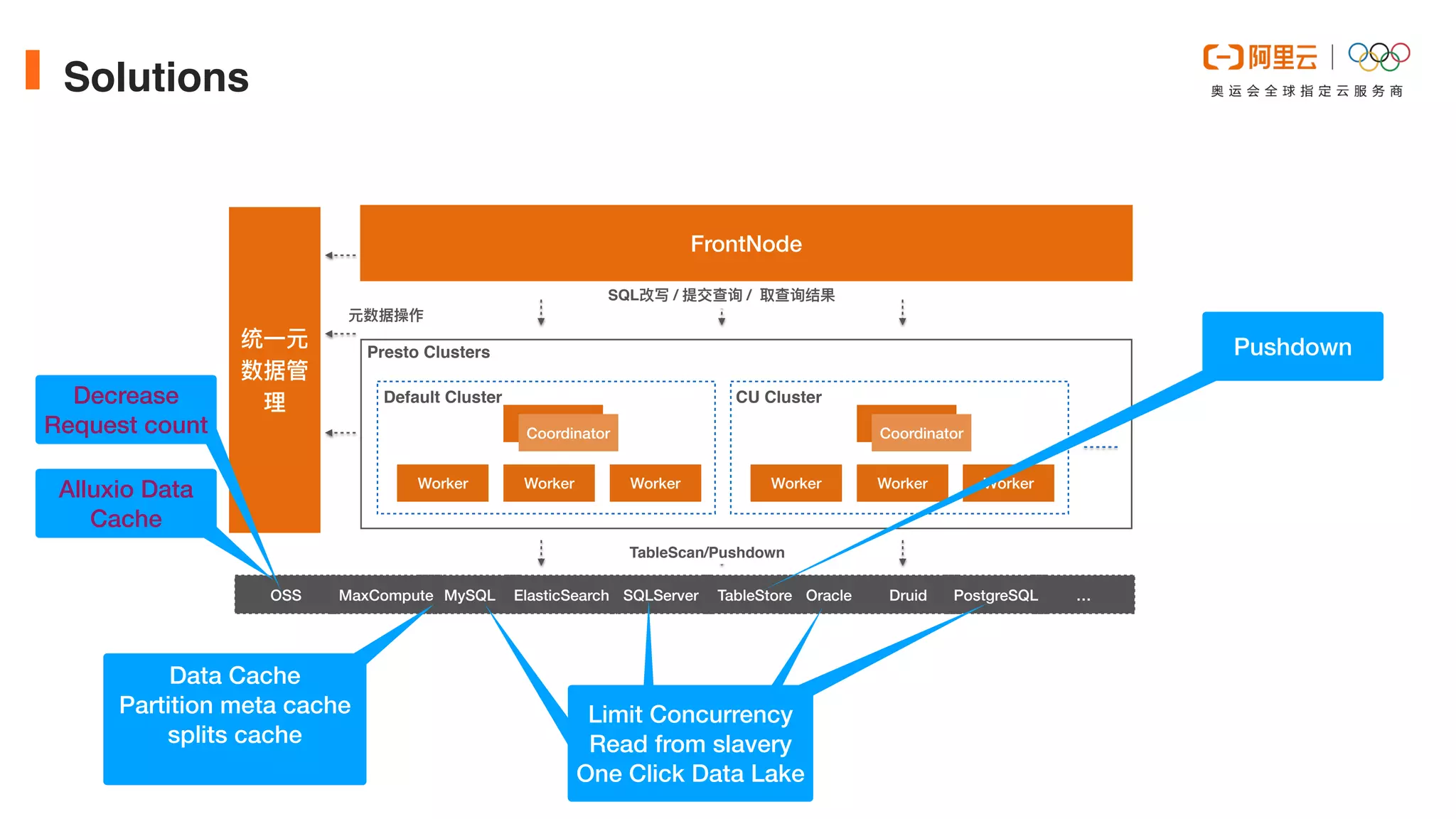
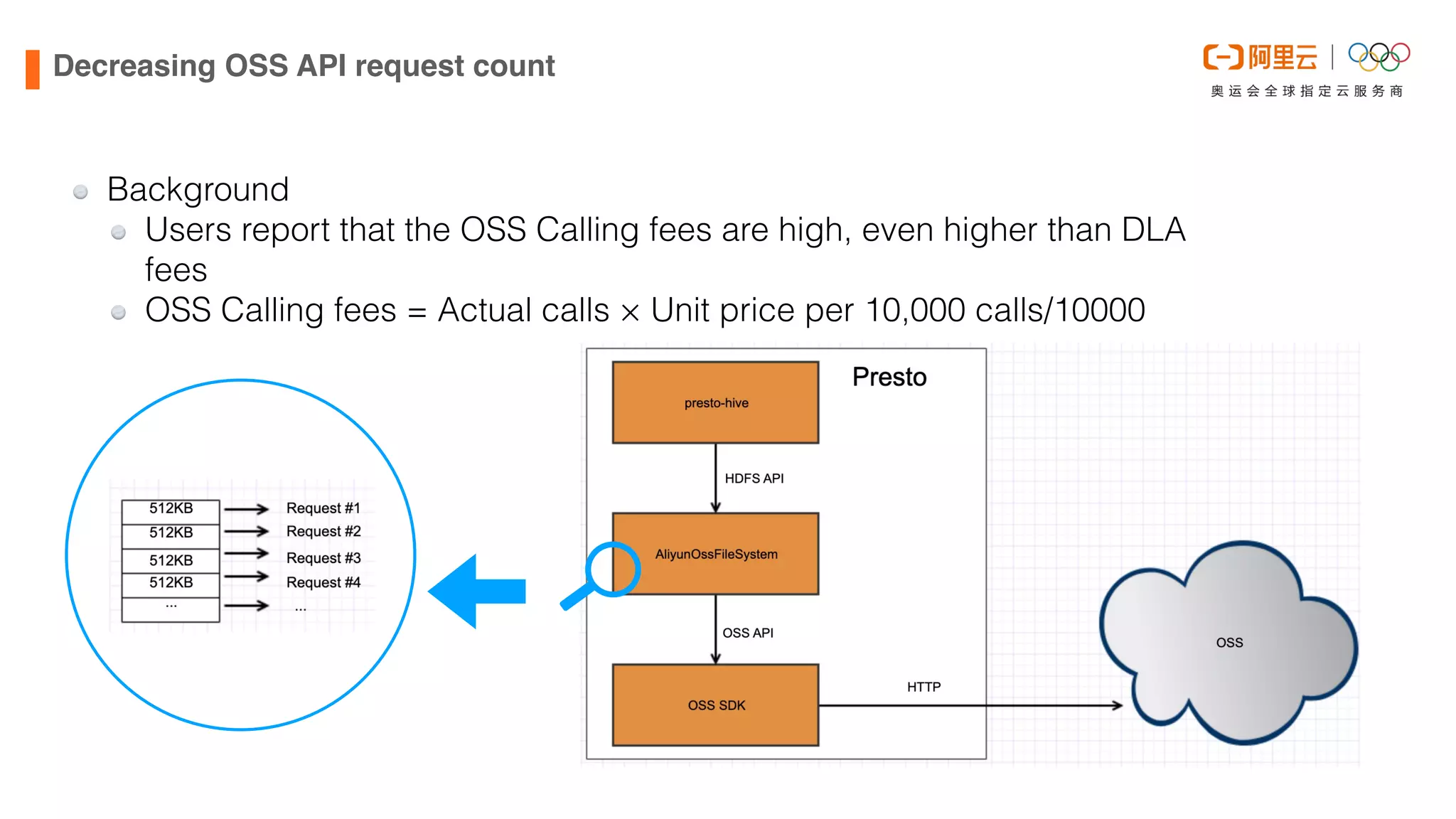
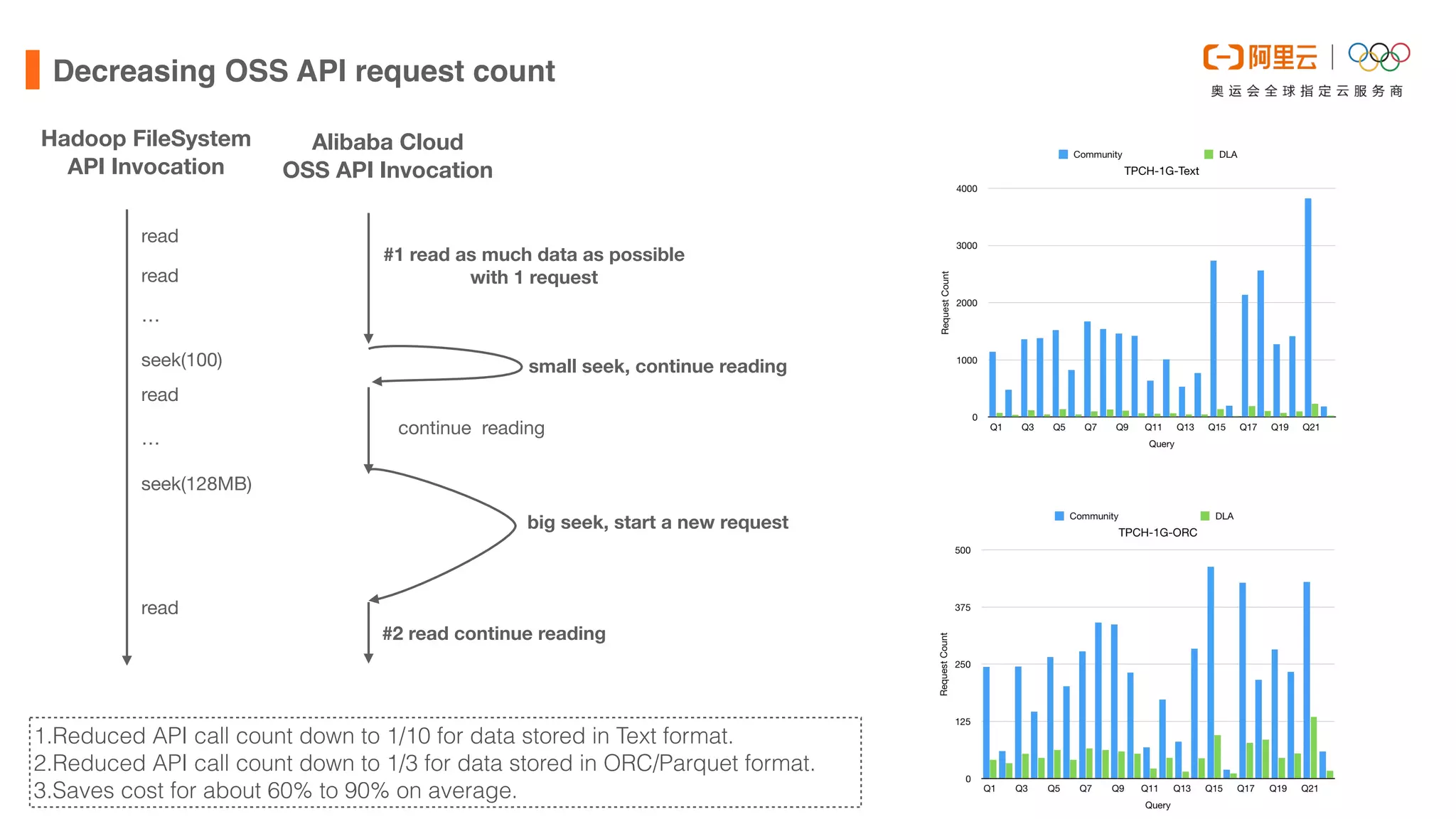
This document discusses optimizations made to Alibaba Cloud's Data Lake Analytics (DLA) engine, which uses Presto, to improve performance when querying data stored in Object Storage Service (OSS). The optimizations included decreasing OSS API request counts, implementing an Alluxio data cache using local disks on Presto workers, and improving disk throughput by utilizing multiple ultra disks. These changes increased cache hit ratios and query performance for workloads involving large scans of data stored in OSS. Future plans include supporting an Alluxio cluster shared by multiple users and additional caching techniques.























































































