Download to read offline













![1. Solving Storage Latency / Bandwidth
[Alluxio enters the chat]
● Cache files on NVME drives for low latency
● Bandwidth now constrained by EC2 instance types (how does
10GB/s sound?)
● High Availability + Maintains S3 durability
● Scales linearly
● Lots of tuning options depending on workload](https://image.slidesharecdn.com/1achievingdouble-digitmillisecondofflinefeaturestoreswithalluxio-251002200638-22c82ce0/85/AI-ML-Infra-Meetup-Achieving-Double-Digit-Millisecond-Offline-Feature-Stores-with-Alluxio-18-320.jpg)



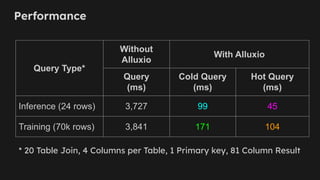



AI/ML Infra Meetup Sep. 30, 2025 Organized by Alluxio For more Alluxio Events: https://www.alluxio.io/events/ Speaker: - Greg Lindstrom, (VP ML Trading @ Blackout Power Trading) Greg Lindstrom shared how they achieved double-digit millisecond offline feature store performance using Alluxio, a game-changer for real-time power trading where every millisecond counts. The 60x latency reduction for inference queries was particularly impressive.



































































