Download to read offline

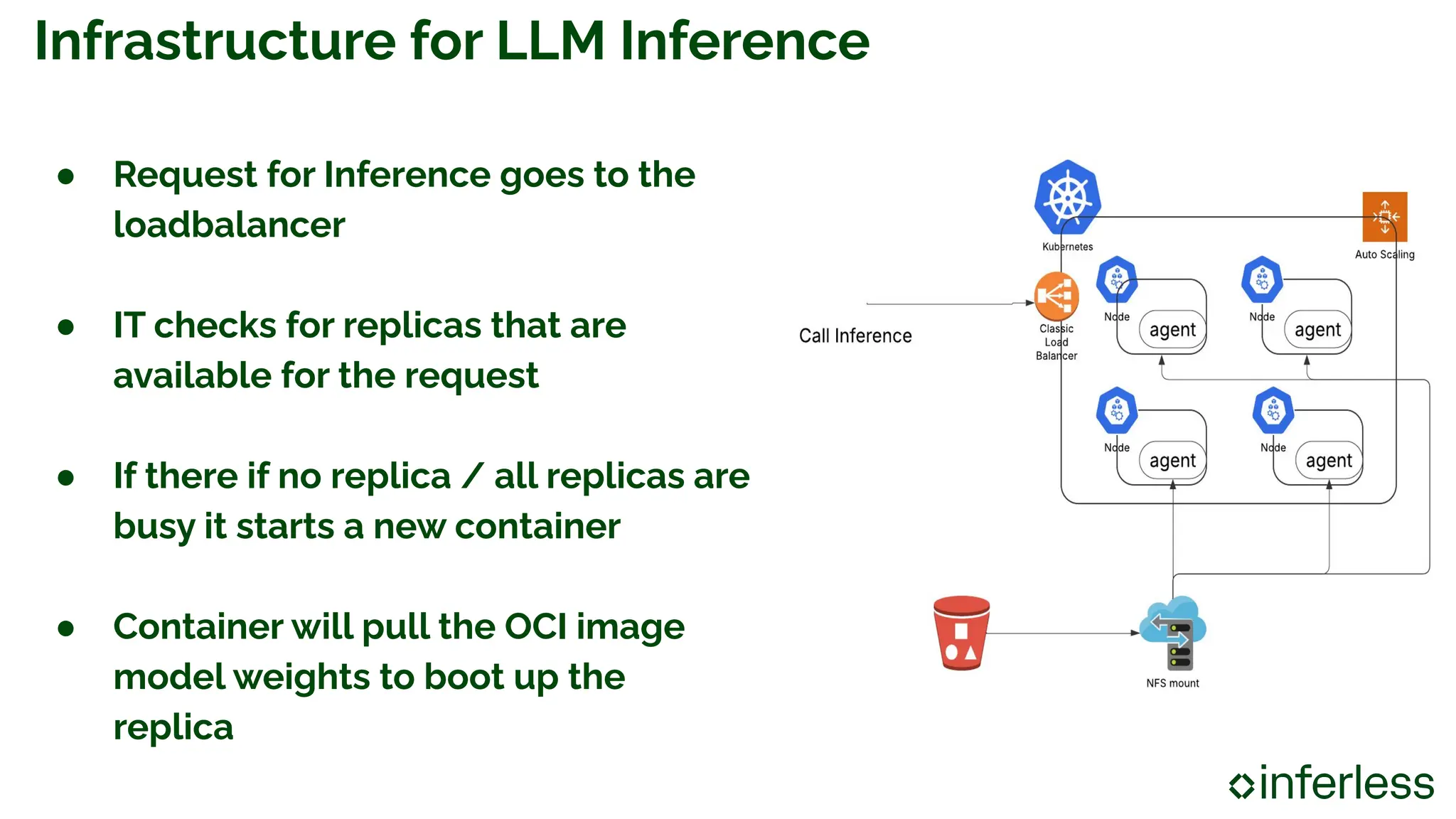

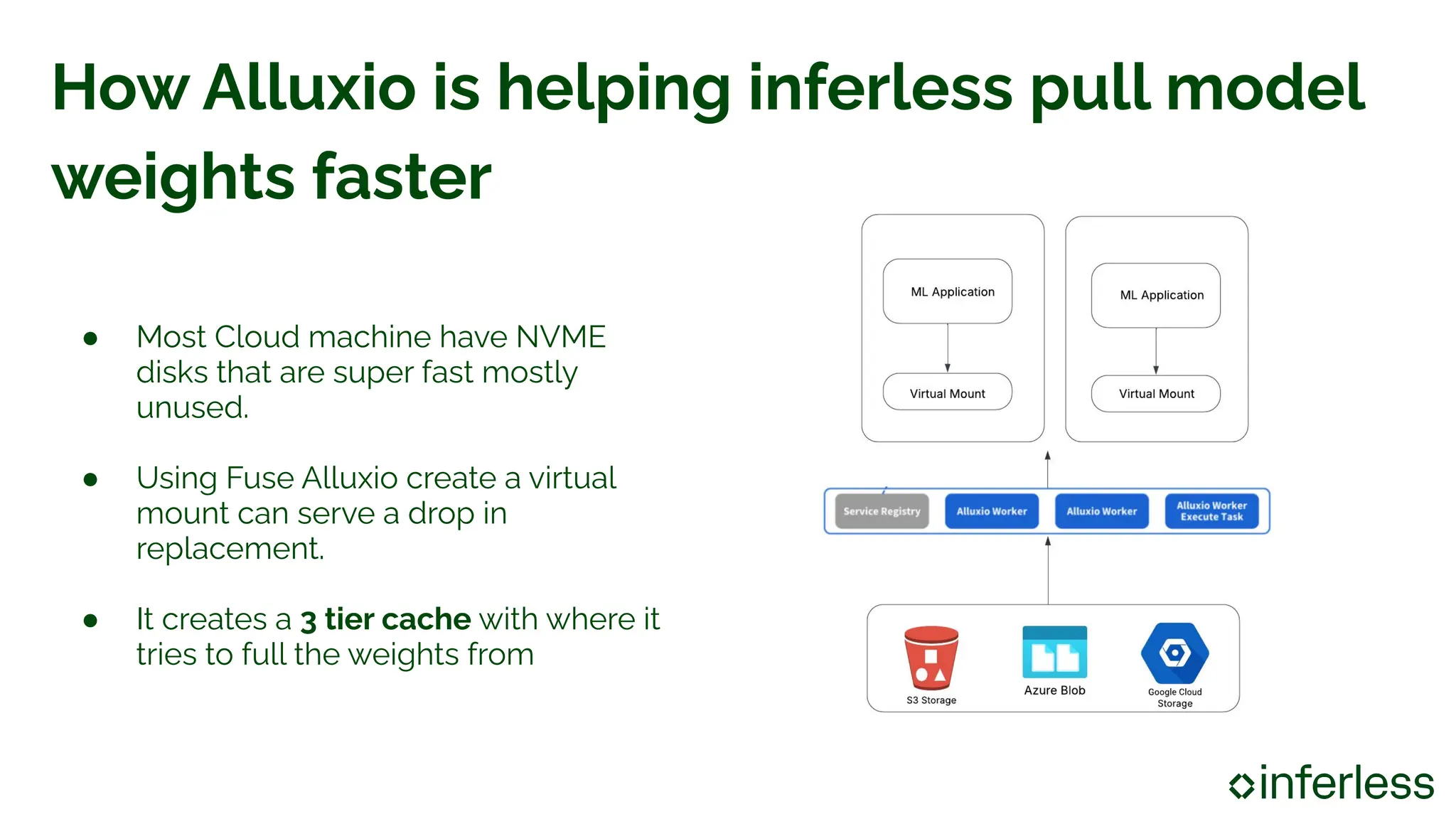




AI/ML Infra Meetup June 17, 2025 Organized by Alluxio For more Alluxio Events: https://www.alluxio.io/events/ Speaker: Nilesh Agarwal (Co-founder & CTO @ Inferless) Nilesh Agarwal, co-founder & CTO at Inferless, shares insights on accelerating LLM inference in the cloud using Alluxio, tackling key bottlenecks like slow model weight loading from S3 and lengthy container startup time. Inferless uses Alluxio as a three-tier cache system that dramatically cuts model load time by 10x.



































































