Downloaded 151 times






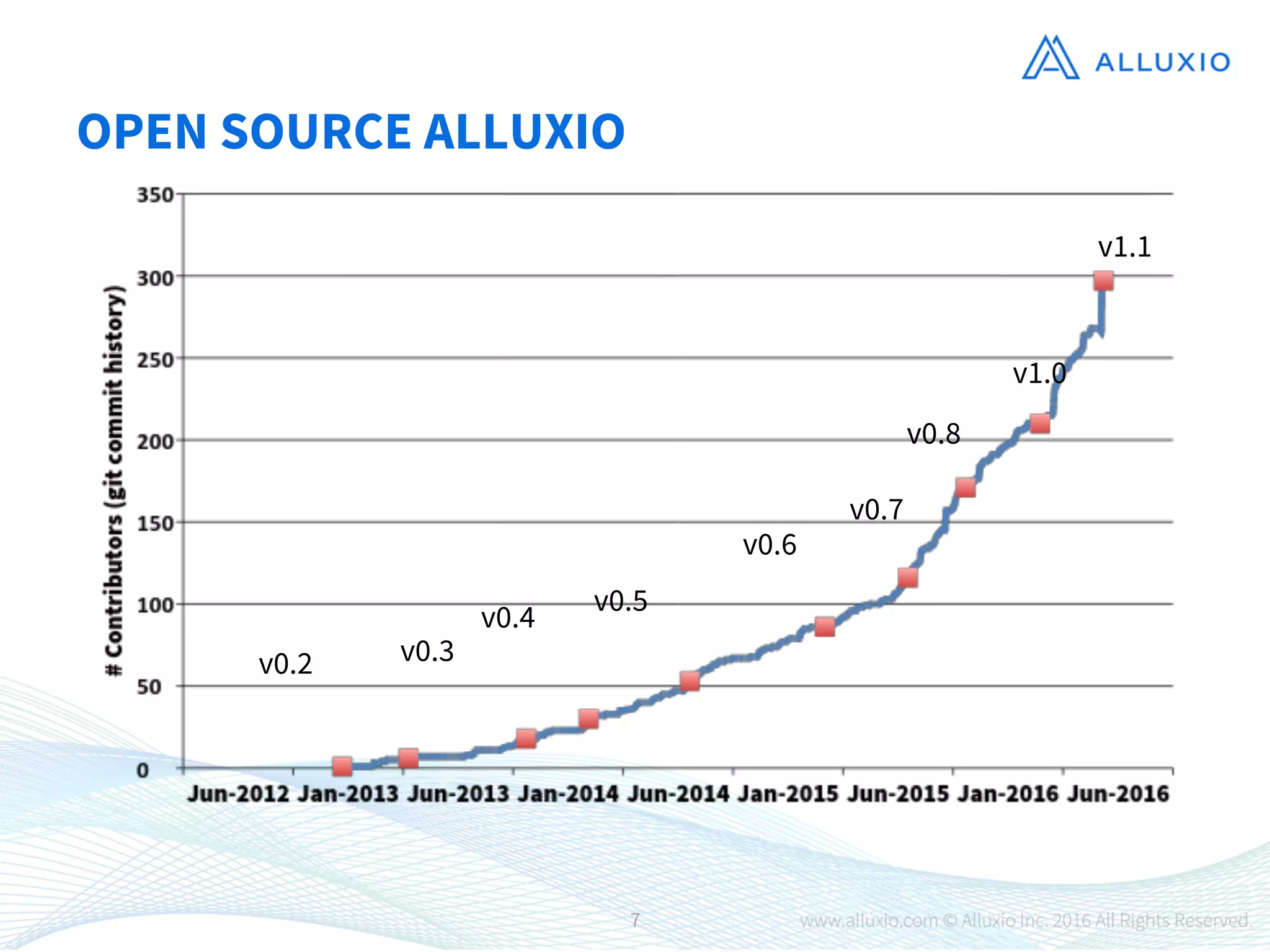















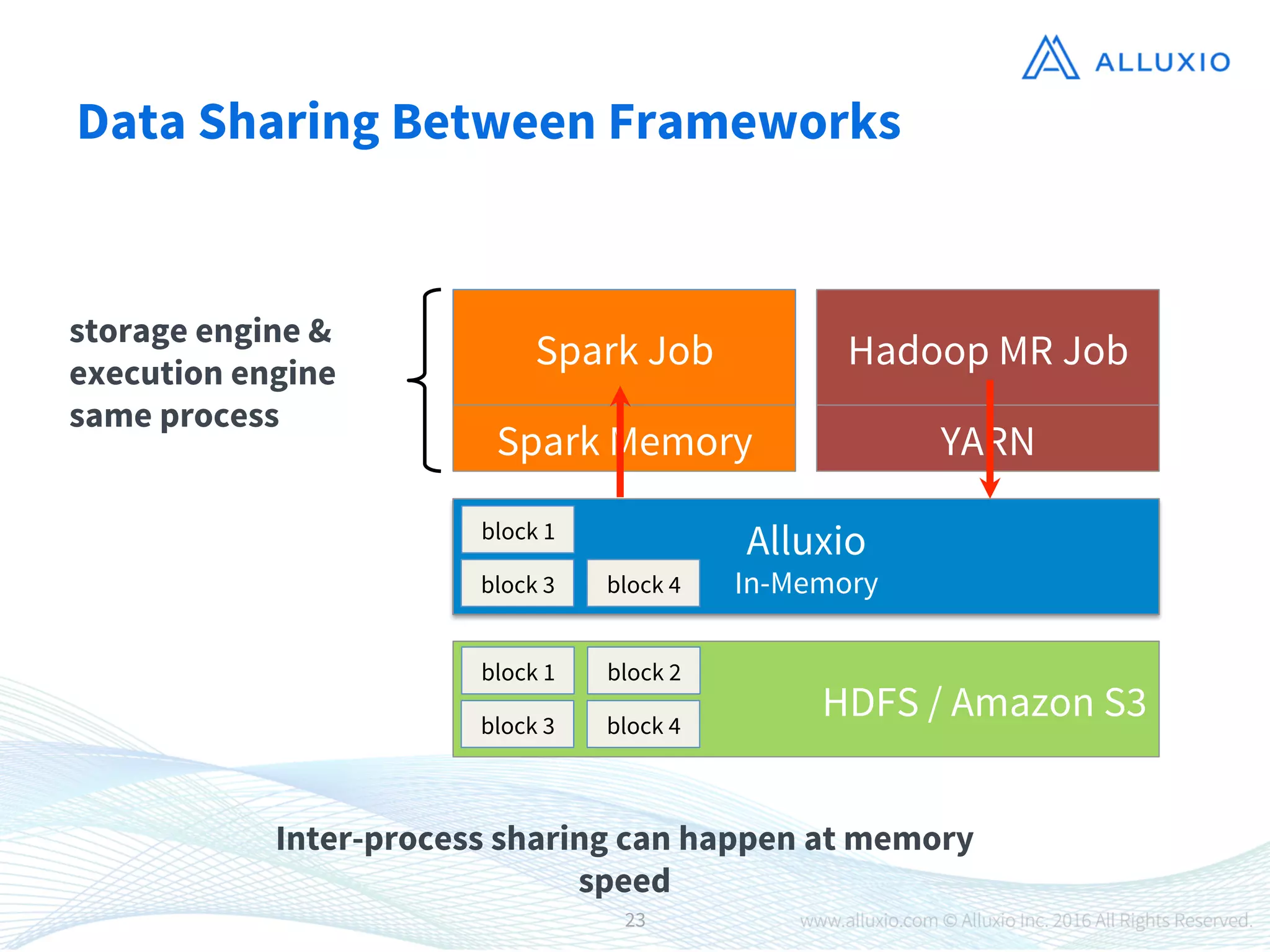









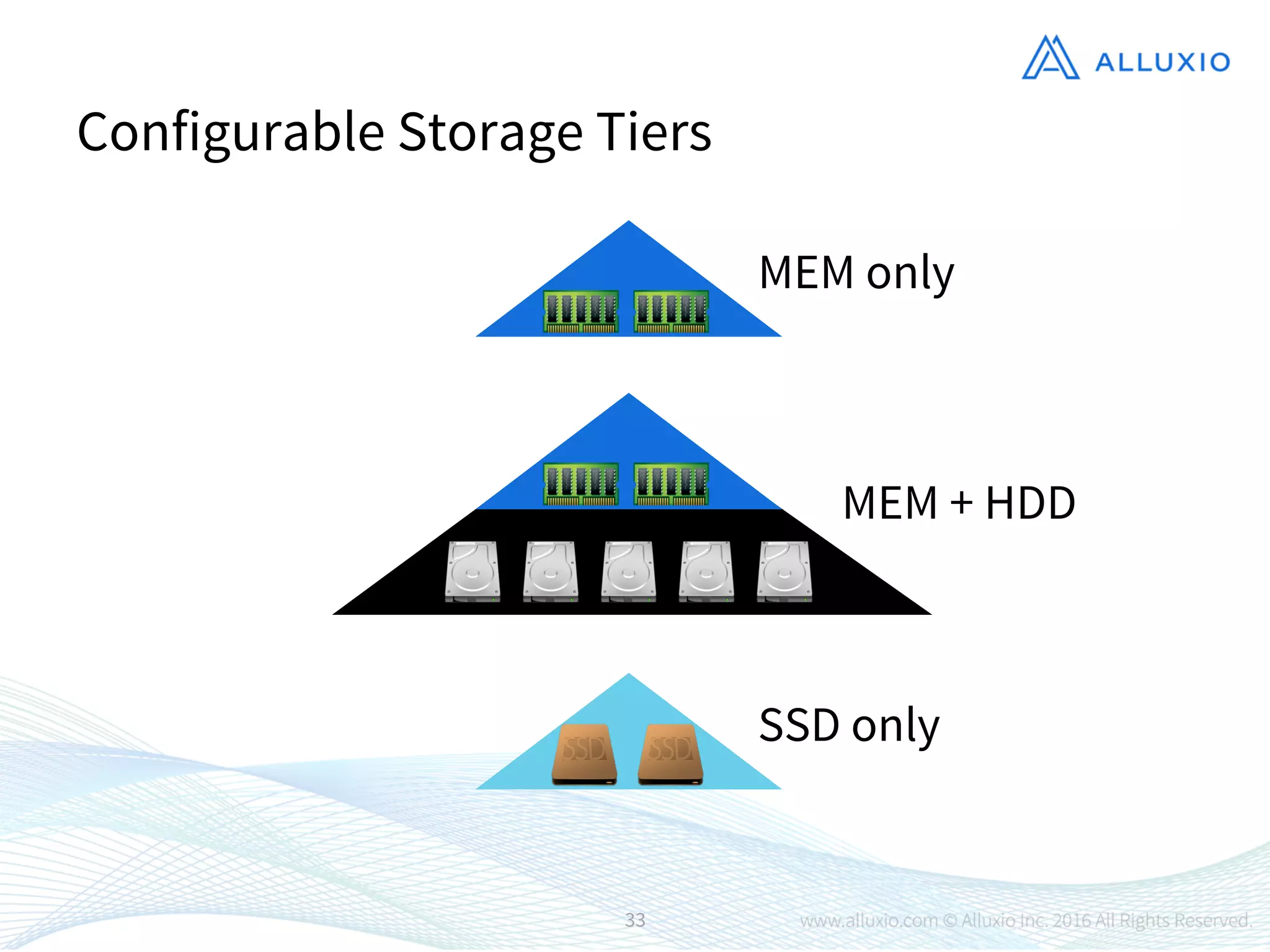






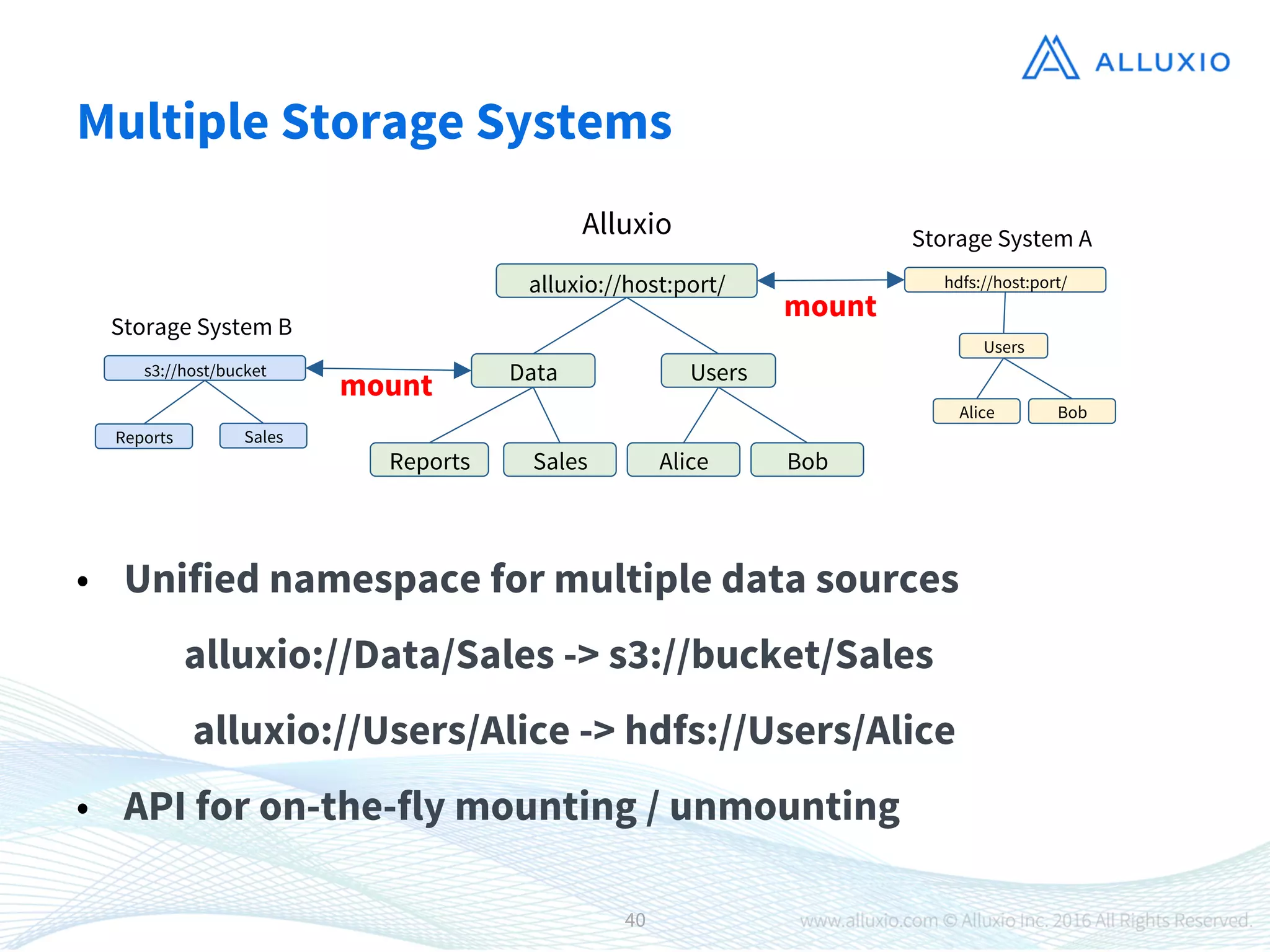









1) Alluxio is an open-source virtual distributed storage system that provides memory-speed access to data across various storage platforms including HDFS, S3, and Swift. 2) Alluxio was presented as having four main use cases - using off-heap memory to alleviate resource pressure, enabling fast data sharing between jobs, accelerating access to remote storage, and providing a unified namespace across different storage systems. 3) Case studies demonstrated that Alluxio improved performance and enabled new workflows, with speedups of 15-300x reported for different customers including Barclays, Qunar, and Baidu.
































































































