Download to read offline



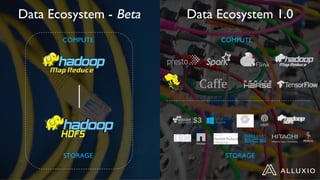
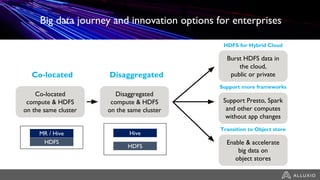


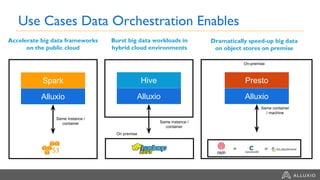
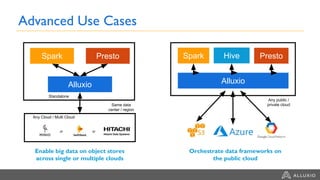

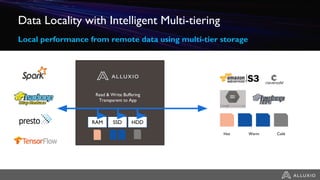

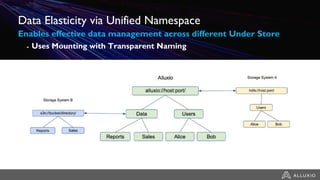
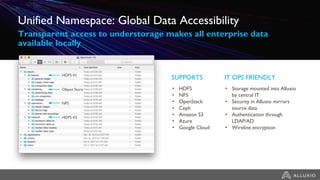







1) Alluxio provides a solution for accessing data across hybrid cloud environments by serving as an abstraction layer between applications and underlying storage systems. 2) It allows compute resources and data storage to be separated and scaled independently through its unified namespace and ability to access data locally through intelligent data tiering even when stored remotely. 3) Use cases include bursting big data workloads between on-premise and cloud environments, accelerating popular big data frameworks on object storage, and enabling data orchestration for agility across multiple clouds and storage systems.























































































