Download to read offline









![Demo: Bootstrapping Alluxio with AWS EMR
aws emr create-cluster
--release-label ${RELEASE_LABEL}
--instance-count ${NUM_INSTANCES}
--custom-ami-id ami-0a53794238d399ab6
--instance-type ${INSTANCE_TYPE}
--applications Name=Presto Name=Hive Name=Spark
--name "${CLUSTER_NAME}"
--bootstrap-actions
Path=${BOOTSTRAP_PATH},
Args=[${ROOT_UFS_URI},-p,${ADDITIONAL_PROPERTIES},-s,","]
--configurations
https://alluxio-public.s3.amazonaws.com/emr/2.0.1/alluxio-emr.json
--ec2-attributes KeyName=${KEY_PAIR}](https://image.slidesharecdn.com/webinar-alluxio-emr-s3-datalake-190912204934/85/Accelerating-Analytics-with-EMR-on-your-S3-Data-Lake-14-320.jpg)


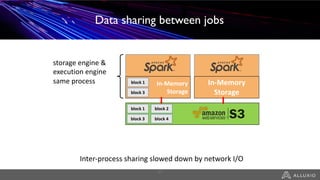
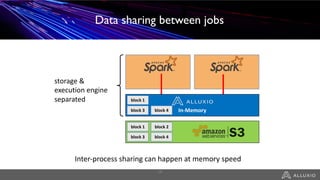


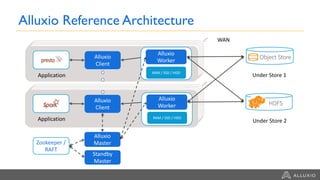
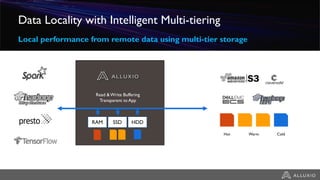

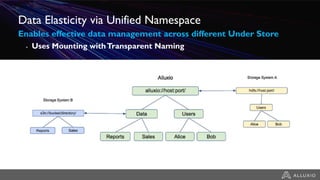
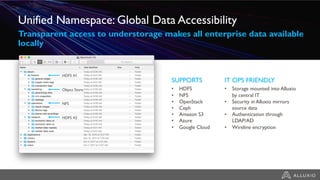



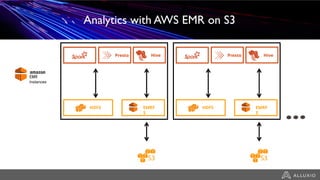
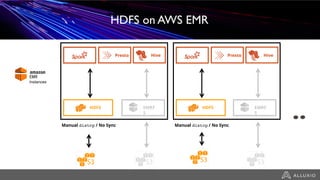
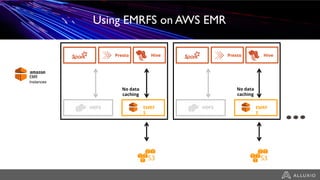
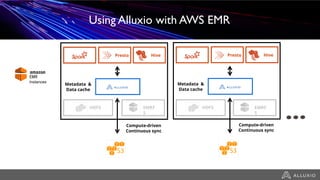
- Alluxio provides a data caching layer for analytics frameworks like Spark running on AWS EMR, addressing challenges of using S3 directly like inconsistent performance and expensive metadata operations. - It mounts S3 as a unified filesystem and caches frequently used data in memory across workers for faster queries while continuously syncing data to S3. - Alluxio's multi-tier storage enables data to be accessed locally from remote locations like S3 using intelligent policies to promote and demote data between memory, SSDs and disks.























































































