Download as PDF, PPTX












This document discusses the need for data orchestration across fragmented data environments. As more data is generated and stored across different storage systems and clouds, data silos have become inevitable. A data orchestration solution like Alluxio can abstract and orchestrate data across these silos, making data locally accessible to compute frameworks regardless of where the data is stored. Alluxio provides a unified view of data locations, enables data access from any application, and allows data to be burst elastically across clouds for compute. Many large companies are adopting data orchestration to improve data access, reduce costs, and gain more flexibility in their cloud environments.
Introduction to data orchestration for AI, big data, and cloud by Haoyuan Li from Alluxio.
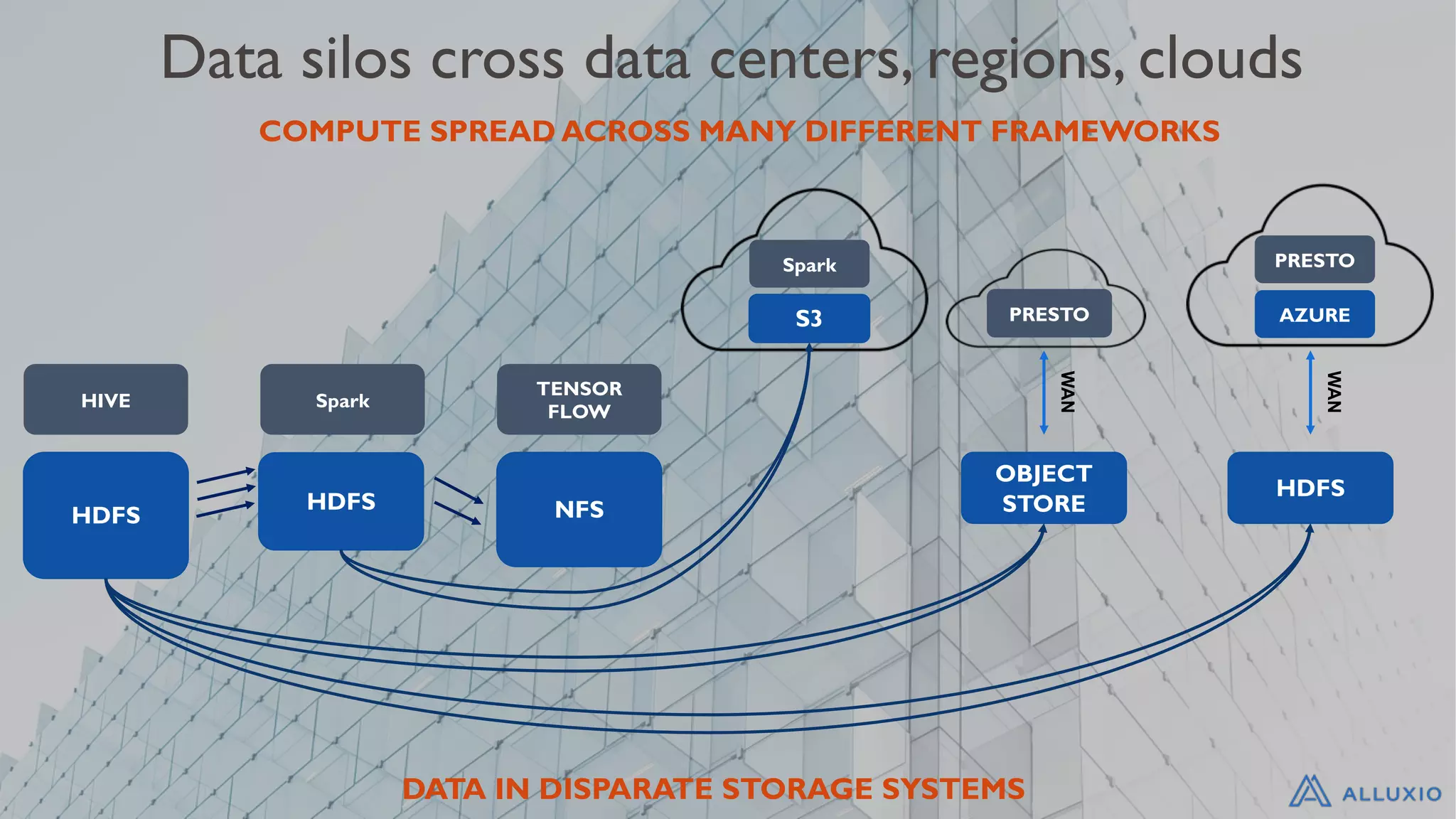
The increasing need for data access, generation, and evolving technologies lead to a fragmented data landscape.
Recognition that data silos are an inevitable challenge in managing modern data environments.
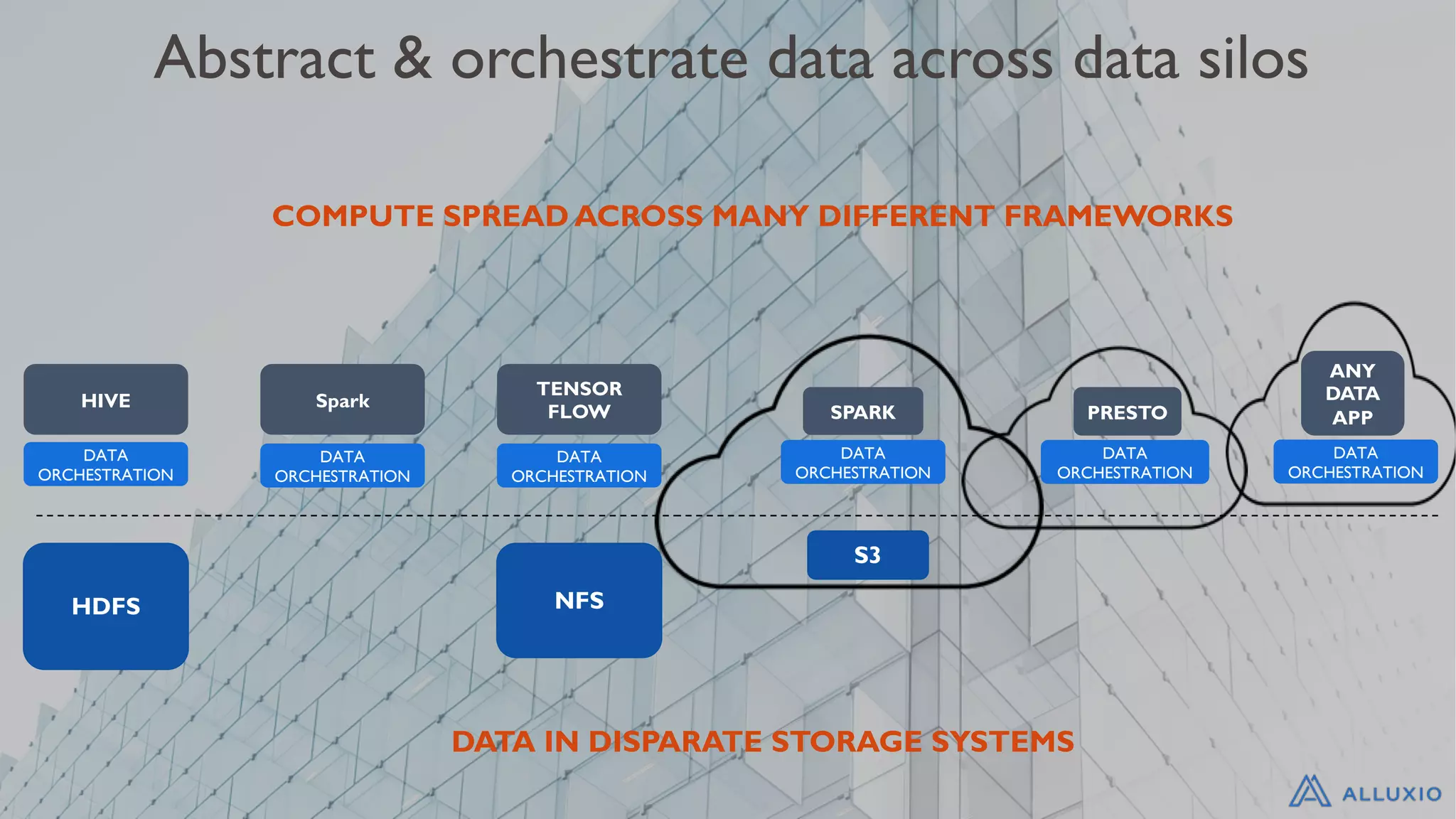
Discusses the limitations of managing data in a single data lake and the need for orchestration.
Illustrates the complexity of data silos across various data centers, clouds, and storage systems.
Highlights the need to abstract and orchestrate data across silos to enhance data workflows.
Benefits of orchestrating data in the cloud, including local data access and cost reduction.
Emphasizes the importance of data orchestration for AI, big data, and cloud environments.
Overview of various interfaces and drivers for data orchestration, enhancing compatibility.
Examines how data orchestration contributes to overall agility in data management.
Explains data orchestration strategies for compute bursting, particularly for financial institutions.
Details on open-source implementation of data orchestration and community involvement.
Highlights the trend of companies, including major internet firms, adopting data orchestration.
Encouragement to join the Alluxio open-source community and contribute to data orchestration.























































































