Download to read offline






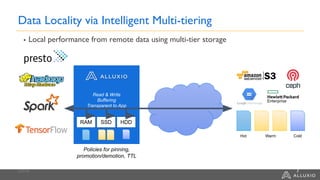

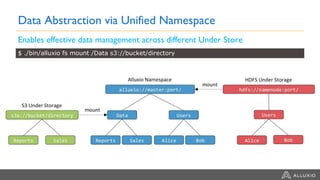
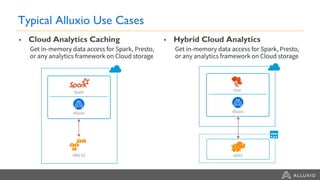
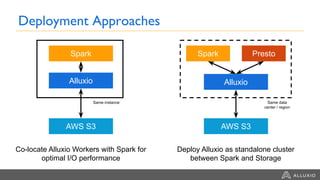



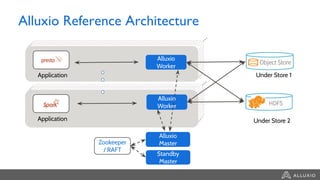
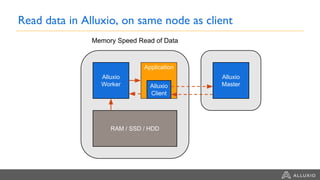
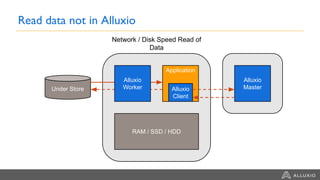
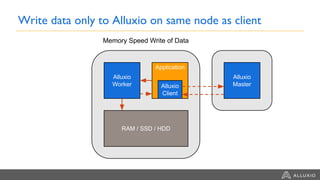
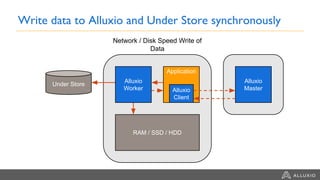



This document summarizes a presentation about building a cloud native stack with EMR Spark, Alluxio, and S3. It discusses using Alluxio to provide better performance than S3 by adding a caching tier and keeping data local to applications like Spark. Alluxio provides familiar file system semantics and can mount multiple data sources. The document demonstrates Alluxio's architecture and how it provides memory speed access to data. It also covers integrating Alluxio with EMR using bootstrap actions and upcoming features in Alluxio 2.0 and 2.1.























































































