Download as PDF, PPTX


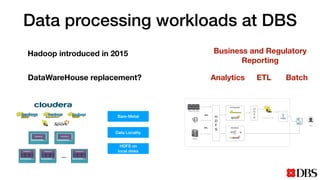



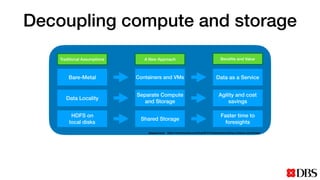
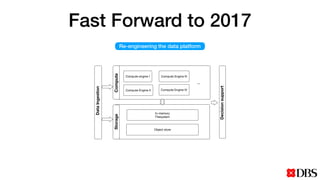
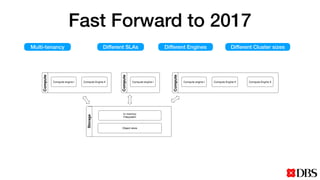

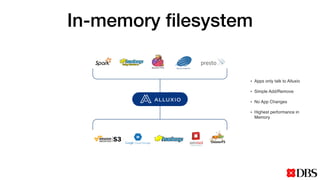
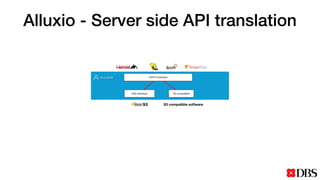
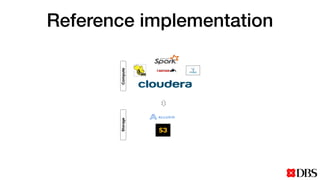



The document discusses the challenges of scaling compute and storage in data processing workloads, particularly in relation to Hadoop at DBS. It proposes decoupling compute and storage to improve flexibility, performance, and cost-effectiveness through technologies such as Alluxio and object stores. Current implementation status includes development with virtual machines and performance benchmarks using Cloudera and S3-compatible environments.
































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








