Download as PDF, PPTX




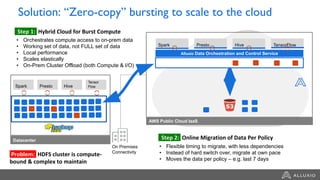


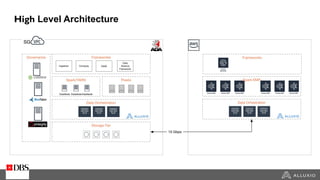
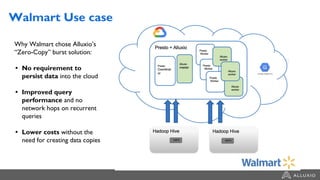



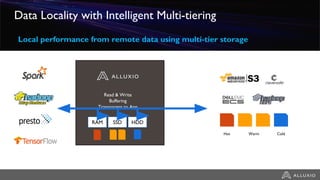

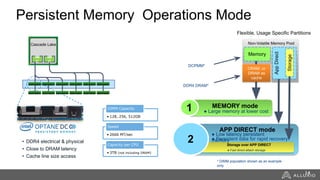


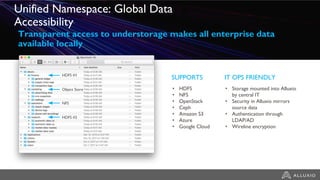
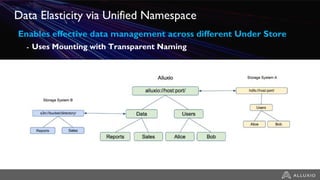
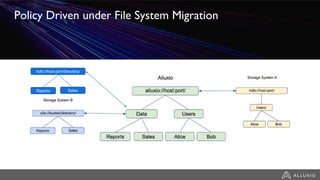
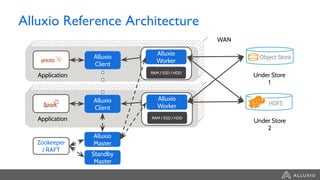




The document discusses the benefits and strategies for using hybrid cloud solutions to accelerate queries on cloud data lakes, emphasizing compute capacity expansion and reducing overload on existing infrastructure. It outlines challenges such as network latency, data copying difficulties, and the need for efficient data synchronization. The use of Alluxio's 'zero-copy' bursting solution is highlighted as a means to improve query performance and reduce costs by avoiding data persistence in the cloud.















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







