Download as PDF, PPTX



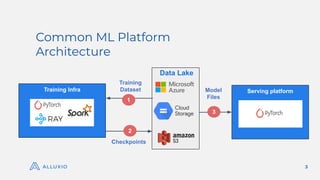
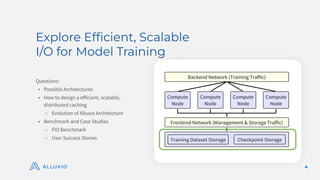


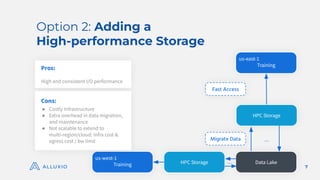
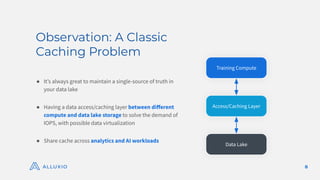


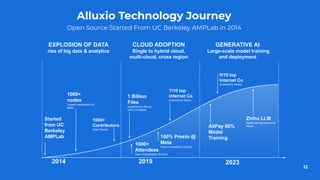


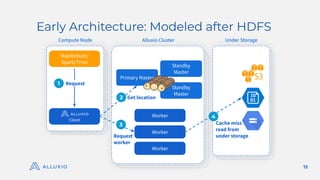

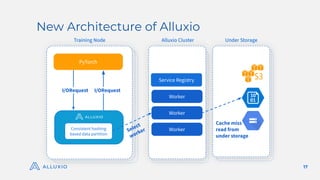






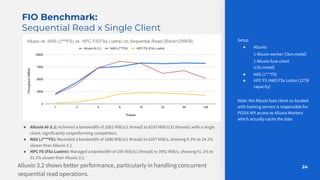
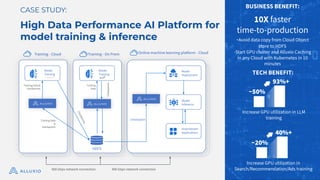




The document discusses optimizing model training with Alluxio's GPU efficiency strategies, emphasizing the importance of a distributed caching layer for I/O intensive workloads. It explores various architectural options, including direct cloud storage connections and high-performance caching to enhance data access and reduce costs. Additionally, it highlights Alluxio's technological evolution and performance benchmarks, showcasing significant improvements in GPU utilization and data processing for machine learning tasks.



































































