Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
masayukitakagi
2,057 views
Lisp Meet Up #19, cl-cuda: a library to use NVIDIA CUDA in Common Lisp
introduce cl-cuda which is a library to use NVIDIA CUDA in Common Lisp
Software
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 13 times
1
/ 19
2
/ 19
3
/ 19
4
/ 19
5
/ 19
6
/ 19
7
/ 19
8
/ 19
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PDF
1075: .NETからCUDAを使うひとつの方法
by
NVIDIA Japan
PDF
Pythonによる並列プログラミング -GPGPUも-
by
Yusaku Watanabe
PDF
C#, C/CLI と CUDAによる画像処理ことはじめ
by
NVIDIA Japan
DOC
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
PDF
GPUをJavaで使う話(Java Casual Talks #1)
by
なおき きしだ
PDF
[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...
by
Insight Technology, Inc.
PDF
NetBSD on Google Compute Engine
by
Ryo ONODERA
PDF
C/C++プログラマのための開発ツール
by
MITSUNARI Shigeo
1075: .NETからCUDAを使うひとつの方法
by
NVIDIA Japan
Pythonによる並列プログラミング -GPGPUも-
by
Yusaku Watanabe
C#, C/CLI と CUDAによる画像処理ことはじめ
by
NVIDIA Japan
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
GPUをJavaで使う話(Java Casual Talks #1)
by
なおき きしだ
[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...
by
Insight Technology, Inc.
NetBSD on Google Compute Engine
by
Ryo ONODERA
C/C++プログラマのための開発ツール
by
MITSUNARI Shigeo
What's hot
PDF
㉞cocos2d-xの開発環境をインストールしてみよう
by
Nishida Kansuke
PDF
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
PDF
もしCloudStackのKVMホストでPCIパススルーできるようになったら
by
Takuma Nakajima
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
Linux KVM環境におけるGPGPU活用最新動向
by
Taira Hajime
PDF
V6read#4
by
magoroku Yamamoto
PDF
Fight Against Citadel in Japan by 中津留 勇
by
CODE BLUE
PDF
[Azure Antenna] クラウドで HPC ~ HPC on Azure ~
by
Shuichi Gojuki
PDF
[Cyber HPC Symposium 2019] Microsoft Azureによる、クラウド時代のハイパフォーマンスコンピューティング High...
by
Shuichi Gojuki
PDF
KVM+cgroup
by
(^-^) togakushi
PDF
“bcache”を使ってSSDの速さと HDDの大容量のいいとこどり 2015-12-12
by
Nobuto Murata
ODP
DRBD/Heartbeat/Pacemakerで作るKVM仮想化クラスタ
by
株式会社サードウェア
PPTX
RHEL on Azure、初めの一歩
by
Ryo Fujita
PDF
[Azure Antenna] HPCだけじゃないDeep Learningでも使える ハイパフォーマンスAzureインフラ ~ Azureハイパフォーマ...
by
Shuichi Gojuki
PDF
Ubuntuとコンテナ技術 What is LXD? and Why? 2015-12-08
by
Nobuto Murata
PDF
PEZY-SC2上における倍々精度Rgemmの実装と評価
by
Toshiaki Hishinuma
PDF
仮想記憶入門 BSD-4.3を例題に
by
magoroku Yamamoto
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
by
Computational Materials Science Initiative
PDF
20170726 py data.tokyo
by
ManaMurakami1
PPTX
20150630_MySQL勉強会
by
masayoshi shiraishi
㉞cocos2d-xの開発環境をインストールしてみよう
by
Nishida Kansuke
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
もしCloudStackのKVMホストでPCIパススルーできるようになったら
by
Takuma Nakajima
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
Linux KVM環境におけるGPGPU活用最新動向
by
Taira Hajime
V6read#4
by
magoroku Yamamoto
Fight Against Citadel in Japan by 中津留 勇
by
CODE BLUE
[Azure Antenna] クラウドで HPC ~ HPC on Azure ~
by
Shuichi Gojuki
[Cyber HPC Symposium 2019] Microsoft Azureによる、クラウド時代のハイパフォーマンスコンピューティング High...
by
Shuichi Gojuki
KVM+cgroup
by
(^-^) togakushi
“bcache”を使ってSSDの速さと HDDの大容量のいいとこどり 2015-12-12
by
Nobuto Murata
DRBD/Heartbeat/Pacemakerで作るKVM仮想化クラスタ
by
株式会社サードウェア
RHEL on Azure、初めの一歩
by
Ryo Fujita
[Azure Antenna] HPCだけじゃないDeep Learningでも使える ハイパフォーマンスAzureインフラ ~ Azureハイパフォーマ...
by
Shuichi Gojuki
Ubuntuとコンテナ技術 What is LXD? and Why? 2015-12-08
by
Nobuto Murata
PEZY-SC2上における倍々精度Rgemmの実装と評価
by
Toshiaki Hishinuma
仮想記憶入門 BSD-4.3を例題に
by
magoroku Yamamoto
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
by
Computational Materials Science Initiative
20170726 py data.tokyo
by
ManaMurakami1
20150630_MySQL勉強会
by
masayoshi shiraishi
Similar to Lisp Meet Up #19, cl-cuda: a library to use NVIDIA CUDA in Common Lisp
KEY
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
KEY
GTC2011 Japan
by
Takuro Iizuka
KEY
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
PDF
CUDA1日(?)体験会
by
RinKuriyama
PDF
Cuda
by
Shumpei Hozumi
PDF
Hello, DirectCompute
by
dasyprocta
PDF
2015年度GPGPU実践プログラミング 第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
by
智啓 出川
PDF
CUDAプログラミング入門
by
NVIDIA Japan
PDF
CUDA1日(?)体験会 (再アップロード)
by
RinKuriyama
KEY
CUDAを利用したPIV解析の高速化
by
翔新 史
PDF
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
PDF
2015年度GPGPU実践基礎工学 第3回 GPUクラスタ上でのプログラミング(CUDA)
by
智啓 出川
PDF
丁寧に学ぶCUDA C(GPU計算) from IT入門チャンネルaki@youtube
by
IT channel aki
PDF
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
PDF
2015年度GPGPU実践基礎工学 第14回 GPGPU組込開発環境
by
智啓 出川
PDF
1070: CUDA プログラミング入門
by
NVIDIA Japan
KEY
関東GPGPU勉強会 LLVM meets GPU
by
Takuro Iizuka
PDF
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
PDF
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10)
by
Ryuuta Tsunashima
PDF
OHS#2 GREでディープラーニング学習REST APIを作る
by
ManaMurakami1
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
GTC2011 Japan
by
Takuro Iizuka
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
CUDA1日(?)体験会
by
RinKuriyama
Cuda
by
Shumpei Hozumi
Hello, DirectCompute
by
dasyprocta
2015年度GPGPU実践プログラミング 第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
by
智啓 出川
CUDAプログラミング入門
by
NVIDIA Japan
CUDA1日(?)体験会 (再アップロード)
by
RinKuriyama
CUDAを利用したPIV解析の高速化
by
翔新 史
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
2015年度GPGPU実践基礎工学 第3回 GPUクラスタ上でのプログラミング(CUDA)
by
智啓 出川
丁寧に学ぶCUDA C(GPU計算) from IT入門チャンネルaki@youtube
by
IT channel aki
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
2015年度GPGPU実践基礎工学 第14回 GPGPU組込開発環境
by
智啓 出川
1070: CUDA プログラミング入門
by
NVIDIA Japan
関東GPGPU勉強会 LLVM meets GPU
by
Takuro Iizuka
機械学習とこれを支える並列計算: ディープラーニング・スーパーコンピューターの応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10)
by
Ryuuta Tsunashima
OHS#2 GREでディープラーニング学習REST APIを作る
by
ManaMurakami1
Lisp Meet Up #19, cl-cuda: a library to use NVIDIA CUDA in Common Lisp
1.
cl-cuda : a
library to use NVIDIA CUDA in Common Lisp 2014.7.29 Masayuki Takagi Lisp Meet Up presented by Shibuya.lisp #19 1.GPGPU 1.1.GPGPU(General Purpose GPU) とは? 1.2.GPU の歴史 1.3.スパコンへの浸透 3.cl-cuda ライブラリ 3.1.cl-cuda の特徴 3.2.使い方 3.3.内部設計 3.4.カーネル関数を起動するまでの流れ 3.5.デモ 3.6.パフォーマンス比較 3.7.レポジトリ 2.NVIDIA CUDA 2.1.CUDA とは? 2.2.プロセッサ・アーキテクチャ 2.3.メモリ・アーキテクチャ 2.4.プログラミング・モデル 目次:
2.
1.GPGPU
3.
© 2014 Masayuki
Takagi-2- 1.1.GPGPU(General Purpose GPU) とは? GPU の計算資源を、画像処理以外の目的に応用する技術
4.
© 2014 Masayuki
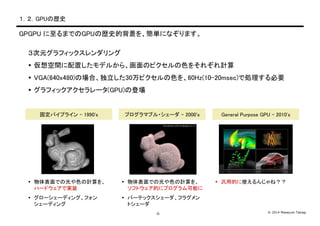
Takagi-3- 1.2.GPUの歴史 3次元グラフィックスレンダリング 仮想空間に配置したモデルから、画面のピクセルの色をそれぞれ計算 VGA(640x480)の場合、独立した30万ピクセルの色を、60Hz(10-20msec)で処理する必要 グラフィックアクセラレータ(GPU)の登場 GPGPU に至るまでのGPUの歴史的背景を、簡単になぞります。 固定パイプライン - 1990's 物体表面での光や色の計算を、 ハードウェアで実装 グローシェーディング、フォン シェーディング プログラマブル・シェーダ - 2000's 物体表面での光や色の計算を、 ソフトウェア的にプログラム可能に バーテックスシェーダ、フラグメン トシェーダ General Purpose GPU - 2010's 汎用的に使えるんじゃね??
5.
© 2014 Masayuki
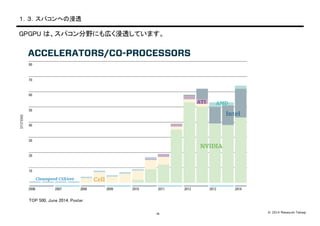
Takagi-4- 1.3.スパコンへの浸透 GPGPU は、スパコン分野にも広く浸透しています。 TOP 500, June 2014, Poster
6.
2.NVIDIA CUDA
7.
© 2014 Masayuki
Takagi-6- 2.1.CUDA とは? NVIDIA が提供する、並列計算アーキテクチャ。NVIDIA 製 GPU にて動作 GPUを利用したコプロセッシングによって、データ並列の計算処理能力を大幅に向上 C ベースの言語(CUDA C)、コンパイラ、デバッガ、プロファイラといった、ソフトウェア開 発環境も包括的に提供 Kepler GK110 のチップ写真
8.
© 2014 Masayuki
Takagi-7- 2.2.プロセッサ・アーキテクチャ CUDAでは、大量のプロセッサ・コアを、以下のような階層構造をとることで管理しています。 1つの GPU チップは、複数のストリーミング・マルチプロセッサ(SMX)からなる 1つのストリーミング・マルチプロセッサは、192 個の CUDA コアと1組のフロー・コント ローラ、 L1 キャッシュからなる 複数のスレッドをまとめたスレッドブロックごとに、ストリーミング・マルチプロセッサで処 理する GTX 680 ブロック図(一部省略)
9.
© 2014 Masayuki
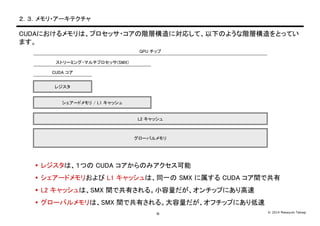
Takagi-8- 2.3.メモリ・アーキテクチャ CUDAにおけるメモリは、プロセッサ・コアの階層構造に対応して、以下のような階層構造をとってい ます。 レジスタは、1つの CUDA コアからのみアクセス可能 シェアードメモリおよび L1 キャッシュは、同一の SMX に属する CUDA コア間で共有 L2 キャッシュは、SMX 間で共有される。小容量だが、オンチップにあり高速 グローバルメモリは、SMX 間で共有される。大容量だが、オフチップにあり低速 グローバルメモリ L2 キャッシュ シェアードメモリ / L1 キャッシュ レジスタ CUDA コア ストリーミング・マルチプロセッサ(SMX) GPU チップ
10.
© 2014 Masayuki
Takagi-9- 2.4.プログラミング・モデル CUDA のプログラミング・モデルは、ハードウェアのアーキテクチャに対応した階層構造となっていま す。 C を拡張した CUDA C によって、カーネル関数を定義。CUDA スレッドを構成し、1つ のCUDA コアで実行される。 スレッド数の指定とともに、カーネル関数を起動。スレッドブロックを構成し、1つのスト リーミング・マルチプロセッサ(SMX)で実行される。 並列度が高く1つのスレッドブロックに収まらない場合、複数のスレッドブロックをまとめ たグリッドを使い、複数の SMX で実行する。
11.
3.cl-cuda ライブラリ
12.
© 2014 Masayuki
Takagi-11- 3.1.cl-cuda の特徴的な機能 cl-cuda は、Common Lisp から NVIDIA CUDA を使用するためのライブラリです。以下の機能を提 供します。 カーネル関数の定義 カーネル記述言語 カーネルマクロの定義 カーネルモジュールの遅延コンパイル及び遅延ロード CUDA コンテキストの管理 ホストメモリ及びデバイスメモリの管理 ホスト=デバイス間のメモリ転送 OpenGL 相互運用
13.
© 2014 Masayuki
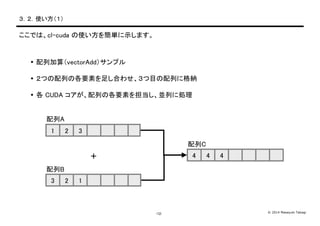
Takagi-12- 3.2.使い方(1) ここでは、cl-cuda の使い方を簡単に示します。 配列加算(vectorAdd)サンプル 2つの配列の各要素を足し合わせ、3つ目の配列に格納 各 CUDA コアが、配列の各要素を担当し、並列に処理 配列A 配列B 配列C 1 2 3 3 2 1 4 4 4+
14.
© 2014 Masayuki
Takagi-13- 3.2.使い方(2) 以下のようなコードで、Common Lisp から CUDA を使用できます。 (defkernel vec-‐add-‐kernel (void ((a float*) (b float*) (c float*) (n int))) (let ((i (+ (* block-‐dim-‐x block-‐idx-‐x) thread-‐idx-‐x))) (if (< i n) (set (aref c i) (+ (aref a i) (aref b i)))))) (defun main () (let* ((dev-‐id 0) (n 1024) (threads-‐per-‐block 256) (blocks-‐per-‐grid (/ n threads-‐per-‐block))) (with-‐cuda (dev-‐id) (with-‐memory-‐blocks ((a 'float n) (b 'float n) (c 'float n)) (random-‐init a n) (random-‐init b n) (sync-‐memory-‐block a :host-‐to-‐device) (sync-‐memory-‐block b :host-‐to-‐device) (vec-‐add-‐kernel a b c n :grid-‐dim (list blocks-‐per-‐grid 1 1) :block-‐dim (list threads-‐per-‐block 1 1)) (sync-‐memory-‐block c :device-‐to-‐host) (verify-‐result a b c n))))) カーネル関数を定義 CUDA コンテキストを生成 ホストとデバイスに、メモリ領域を確保 ホストメモリからデバイスメモリへデータ を転送 定義したカーネル関数を起動 デバイスメモリからホストメモリへデータ を転送
15.
© 2014 Masayuki
Takagi-14- 3.3.内部設計 cl-cuda は、以下の3つのコンポーネントから構成されます。 cl-cuda.api 実際にユーザが利用するインターフェ イスを提供。defkernel マクロ、カーネ ルマネージャ、CUDA コンテキスト、メ モリブロック、タイマ。 cl-cuda.lang カーネル記述言語と、そのコンパイラ を提供。コンパイラは、カーネル記述 言語を CUDA C へ変換する。CUDA C から PTX ファイルへの変換は、cl- cuda.api のカーネルマネージャが管 理する。 cl-cuda.driver-api CUDA ドライバ API への FFI(Foreign Function Interface)を提供。
16.
© 2014 Masayuki
Takagi-15- 3.4.カーネル関数を起動するまでの流れ 定義したカーネル関数を起動するまでの処理の流れは、以下のようになります。これらの処理は、 カーネルマネージャによって管理され、コンパイルやロードは、必要なタイミングまで遅延して実行さ れます。 1. カーネル関数を定義 defkenrel マクロを使用して、カーネル関数を定義しま す。 2. カーネル記述言語をコンパイル cl-cuda.lang のコンパイラを用いて、カーネル記述言語 を CUDA C へコンパイルします。 3. CUDA C をコンパイル NVIDIA の提供する NVCC (NVIDIA CUDA Compiler) を呼び出し、CUDA C のコードをカーネルモジュール (PTX ファイル)へコンパイルします。 4. カーネルモジュールをロード CUDA ドライバ API を使用して、カーネルモジュールを ロードします。 5. カーネル関数をロード CUDA ドライバ API を使用して、起動したいカーネル 関数をロードします。 6. 引数として渡す値を配列に格納 引数として GPU に渡す値を格納した配列を用意しま す。 7. カーネル関数を起動 CUDA ドライバ API を使用して、カーネル関数を起動 します。
17.
© 2014 Masayuki
Takagi-16- 3.5.デモ Nbody シミュレーション (:ql :cl-‐cuda-‐interop-‐examples) (cl-‐cuda-‐interop-‐examples.nbody:main :gpu t :interop t)
18.
© 2014 Masayuki
Takagi-17- 3.6.パフォーマンス比較 GPU を利用して並列計算することで、CPU での逐次処理に対し、40倍近い性能向上が得られまし た。 x37.5 Amazon EC2 インスタンス プロセッサ コア数 g2.2xlarge g2.2xlarge Xeon E5-2670 2.6GHz NVIDIA GRID K520 1 コア (シングルスレッド、SIMD命令使用せず、gcc -O3相当) 1,536 コア 4.86[sec] 182.2[sec] SPH(Smoothed Particle Hydrodynamics) による流体シミュレーション 11,774粒子
19.
© 2014 Masayuki
Takagi-18- 3.7.レポジトリ cl-cuda は、GitHub から入手できます。Quicklispは、そのテストポリシーの都合上、登録不可でした。 https://github.com/takagi/cl-cuda/
Download














![© 2014 Masayuki Takagi-17-
3.6.パフォーマンス比較
GPU を利用して並列計算することで、CPU での逐次処理に対し、40倍近い性能向上が得られまし
た。
x37.5
Amazon EC2 インスタンス
プロセッサ
コア数
g2.2xlarge g2.2xlarge
Xeon E5-2670 2.6GHz NVIDIA GRID K520
1 コア
(シングルスレッド、SIMD命令使用せず、gcc -O3相当)
1,536 コア
4.86[sec]
182.2[sec]
SPH(Smoothed Particle Hydrodynamics) による流体シミュレーション 11,774粒子](https://image.slidesharecdn.com/2014-07-18-140804070219-phpapp01/85/Lisp-Meet-Up-19-cl-cuda-a-library-to-use-NVIDIA-CUDA-in-Common-Lisp-18-320.jpg)






![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Azure Antenna] クラウドで HPC ~ HPC on Azure ~](https://cdn.slidesharecdn.com/ss_thumbnails/hpconazure111282017-171206080933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cyber HPC Symposium 2019] Microsoft Azureによる、クラウド時代のハイパフォーマンスコンピューティング High...](https://cdn.slidesharecdn.com/ss_thumbnails/cyberhpcsymposium2019msgojuki-190314032607-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Azure Antenna] HPCだけじゃないDeep Learningでも使える ハイパフォーマンスAzureインフラ ~ Azureハイパフォーマ...](https://cdn.slidesharecdn.com/ss_thumbnails/hpconazure2-2-180320015607-thumbnail.jpg?width=640&height=640&fit=bounds)

























