Downloaded 333 times








![Deep Dive content by Hortonworks, Inc. is licensed under a
Creative Commons Attribution-ShareAlike 3.0 Unported License.
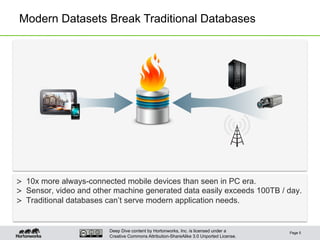
Apache Hadoop in Review
• Apache Hadoop Distributed Filesystem (HDFS)
– Distributed, fault-tolerant, throughput-optimized data storage
– Uses a filesystem analogy, not structured tables
– The Google File System, 2003, Ghemawat et al.
– http://research.google.com/archive/gfs.html
• Apache Hadoop MapReduce (MR)
– Distributed, fault-tolerant, batch-oriented data processing
– Line- or record-oriented processing of the entire dataset
– “[Application] schema on read”
– MapReduce: Simplified Data Processing on Large Clusters, 2004,
Dean and Ghemawat
– http://research.google.com/archive/mapreduce.html
Page 12
For more on writing MapReduce applications, see “MapReduce
Patterns, Algorithms, and Use Cases”
http://highlyscalable.wordpress.com/2012/02/01/mapreduce-patterns/](https://image.slidesharecdn.com/2013sept17thughbasetechnicalintroduction-130918071040-phpapp02/85/Sept-17-2013-THUG-HBase-a-Technical-Introduction-12-320.jpg)

![Deep Dive content by Hortonworks, Inc. is licensed under a
Creative Commons Attribution-ShareAlike 3.0 Unported License.
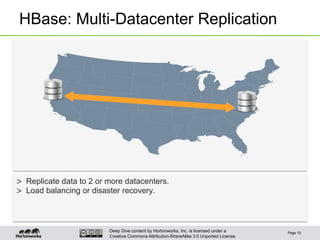
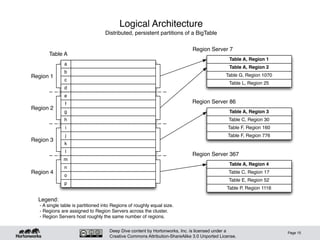
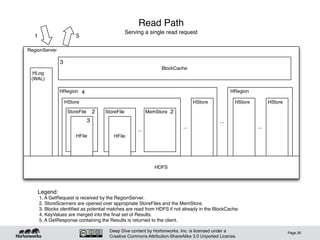
Logical Architecture
• [Big]Tables consist of billions of rows, millions of
columns
• Records ordered by rowkey
– Inserts require sort, write-side overhead
– Applications can take advantage of the sort
• Continuous sequences of rows partitioned into
Regions
– Regions partitioned at row boundary, according to size (bytes)
• Regions automatically split when they grow too large
• Regions automatically distributed around the cluster
– ”Hands-free" partition management (mostly)
Page 14](https://image.slidesharecdn.com/2013sept17thughbasetechnicalintroduction-130918071040-phpapp02/85/Sept-17-2013-THUG-HBase-a-Technical-Introduction-14-320.jpg)


![Deep Dive content by Hortonworks, Inc. is licensed under a
Creative Commons Attribution-ShareAlike 3.0 Unported License.
Page 19
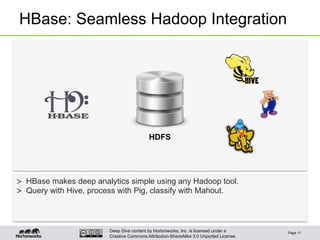
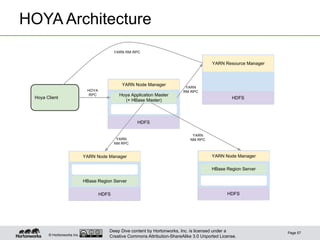
Logical Data Model
A sparse, multi-dimensional, sorted map
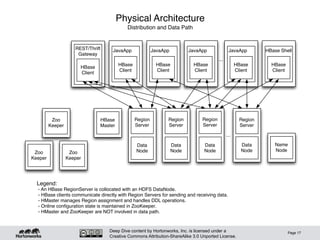
Legend:
- Rows are sorted by rowkey.
- Within a row, values are located by column family and qualifier.
- Values also carry a timestamp; there can me multiple versions of a value.
- Within a column family, data is schemaless. Qualifiers and values are treated as arbitrary bytes.
1368387247 [3.6 kb png data]"thumb"cf2b
a
cf1
1368394583 7
1368394261 "hello"
"bar"
1368394583 22
1368394925 13.6
1368393847 "world"
"foo"
cf2
1368387684 "almost the loneliest number"1.0001
1368396302 "fourth of July""2011-07-04"
Table A
rowkey
column
family
column
qualifier
timestamp value](https://image.slidesharecdn.com/2013sept17thughbasetechnicalintroduction-130918071040-phpapp02/85/Sept-17-2013-THUG-HBase-a-Technical-Introduction-19-320.jpg)

































The document is a technical deep dive into Apache HBase, outlining its architecture, key features, and use cases. It highlights how HBase serves as a database for big data by enabling low-latency access to large datasets and facilitating integration with the Hadoop ecosystem. Specific applications are provided, including real-time analysis in manufacturing and various other industries, demonstrating HBase's scalability and flexibility.










































































































