











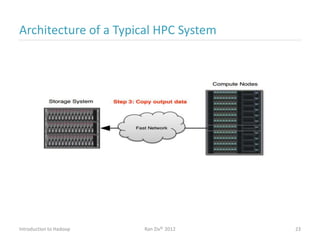

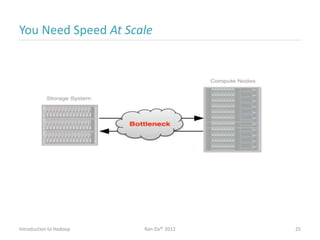

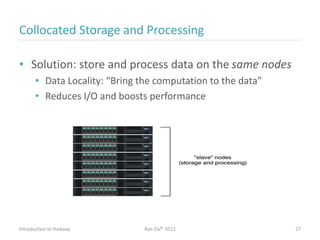



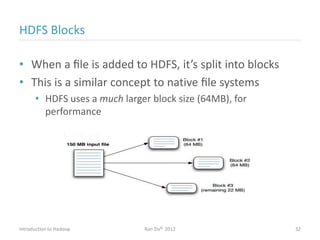

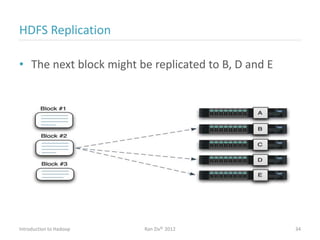
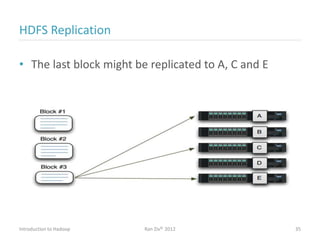











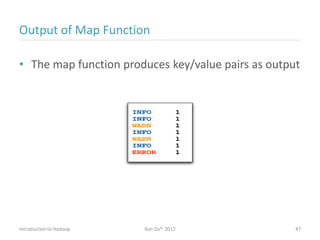




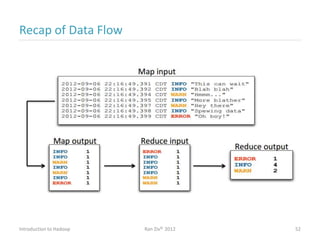
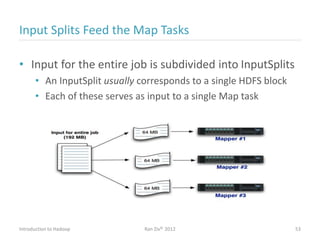
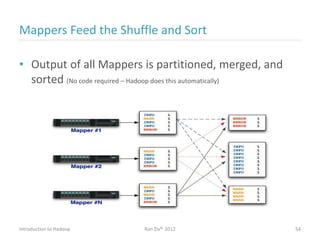
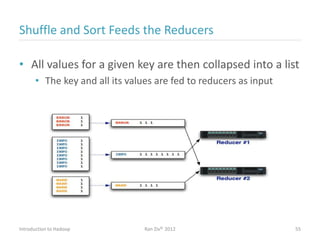


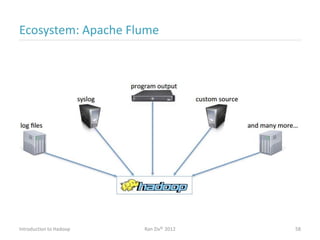
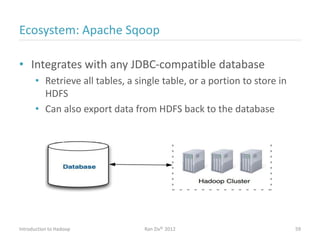





Ran Ziv introduces Apache Hadoop, an open-source software platform for distributed storage and processing of large datasets across clusters of computers. Hadoop consists of HDFS for storage and MapReduce for processing. HDFS stores data across clusters as blocks and provides high throughput even when hardware fails, while MapReduce allows parallel processing of data using "map" and "reduce" functions. A large ecosystem of projects has been built around Hadoop's core to support additional functionality such as data integration, querying, databases and scheduling. Hadoop works best for large datasets, batch processing and jobs where data can be distributed across nodes.



































































