




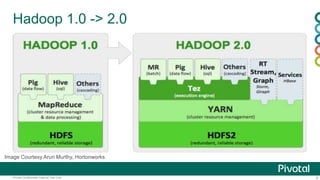
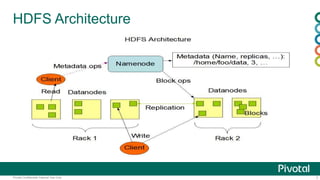
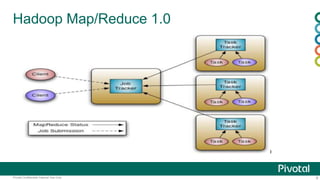
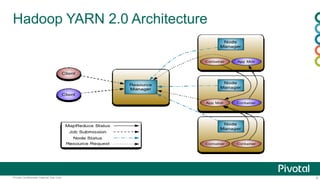












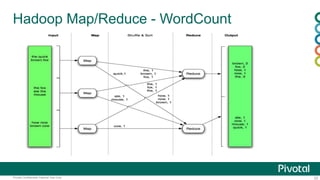












This document provides an agenda and overview for a presentation on Hadoop 2.x configuration and MapReduce performance tuning. The presentation covers hardware selection and capacity planning for Hadoop clusters, key configuration parameters for operating systems, HDFS, and YARN, and performance tuning techniques for MapReduce applications. It also demonstrates the Hadoop Vaidya performance diagnostic tool.



































































