Download as PDF, PPTX











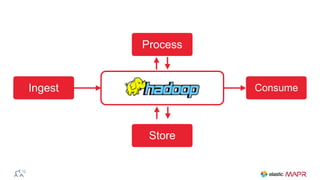

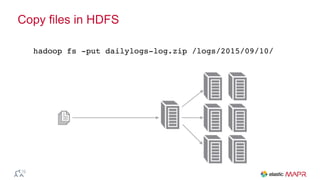
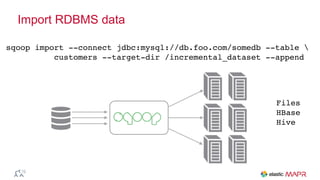
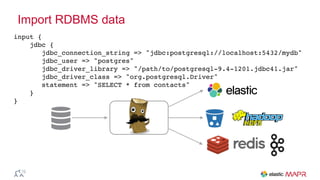


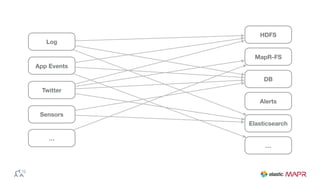
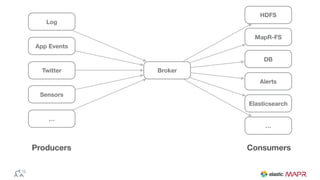
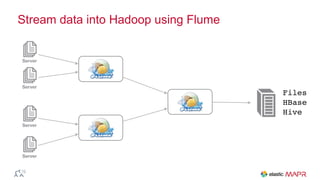
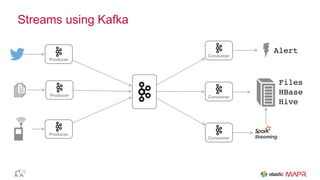
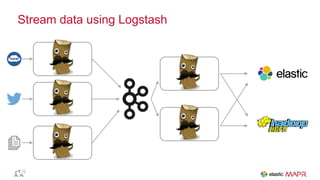




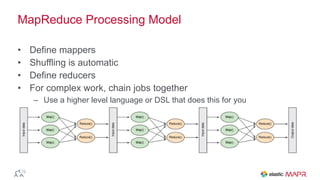

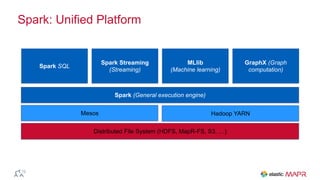





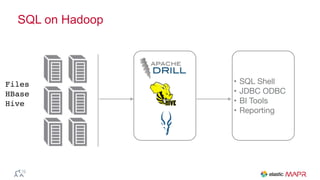

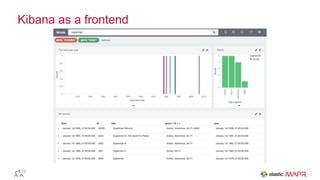

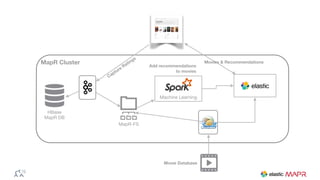



The document outlines the big data journey using Hadoop and MapR, highlighting tools for data ingestion, storage, processing, and consumption. It discusses batch and streaming data processing methods, featuring technologies like Spark, Flume, Kafka, and Elasticsearch. The presentation also touches on data visualization and the use of SQL for querying data in a big data environment.











































































































